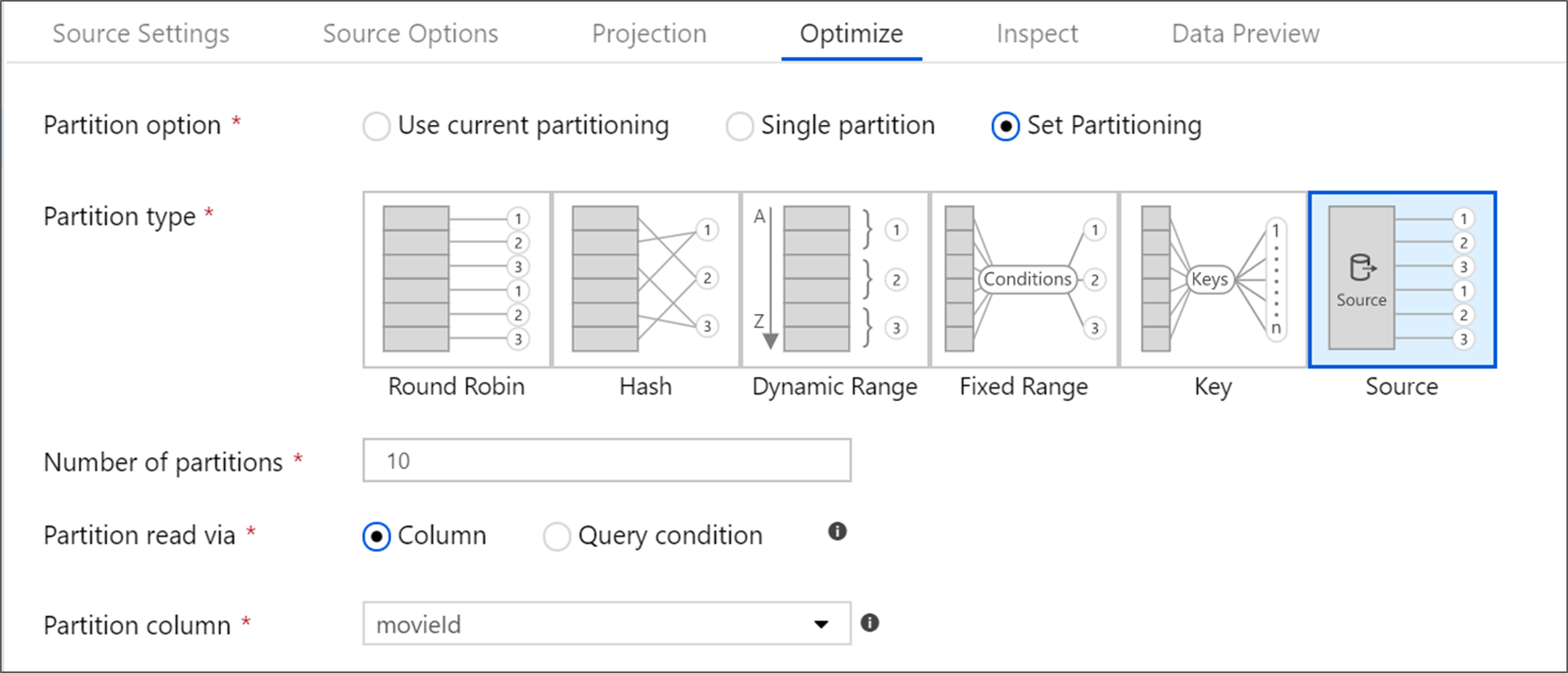
將來源最佳化
針對 Azure SQL Database 以外的每個來源,建議您保留 [使用目前的資料分割] 作為選取的值。 當您要從所有其他來源系統進行讀取時,資料流程會根據資料的大小來自動平均分割資料。 系統會針對大約每 128 MB 的資料建立一個新的分割區。 隨著資料大小增加,分割區數目也會增加。
任何自訂資料分割都會在 Spark 讀取資料「之後」發生,而且會對資料流程效能造成負面影響。 因為會在讀取時平均分割資料,所以除非您先了解資料的圖形和基數,否則不建議這麼做。
注意
讀取速度可能會受限於來源系統的輸送量。
Azure SQL Database 來源
Azure SQL Database 具有具有一種獨特的資料分割選項,稱為「來源」資料分割。 啟用來源資料分割可以在來源系統上啟用平行連線,以從 Azure SQL Database 改善您的讀取時間。 指定分割區數目,以及如何分割您的資料。 選擇具有高基數的資料分割資料行。 您也可以輸入符合來源資料表的資料分割配置的查詢。
提示
對於來源資料分割,SQL Server 的 I/O 是瓶頸。 新增太多分割區可能會讓源資料庫飽和。 使用此選項時,四或五個分割區通常是理想的選擇。
隔離等級
Azure SQL 來源系統上的讀取隔離等級會影響效能。 選擇 [讀取未認可] 會提供最快的效能,並防止任何資料庫鎖定。 若要深入了解 SQL 隔離等級,請參閱了解隔離等級。
使用查詢來讀取
您可以使用資料表或 SQL 查詢,從 Azure SQL Database 讀取。 如果您正在執行 SQL 查詢,則必須先完成查詢,才能開始轉換。 SQL 查詢有助於向下推送作業以加快執行速度,並減少 SELECT、WHERE 和 JOIN 這類陳述式從 SQL Server 讀取的資料量。 在向下推送作業時,您會失去在資料進入資料流程前追蹤資料譜系和效能的能力。
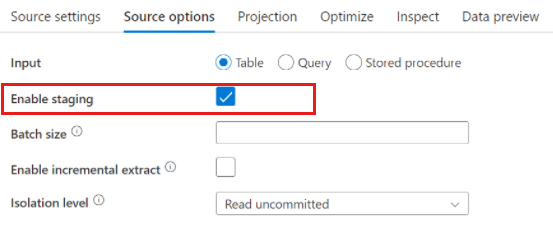
Azure Synapse Analytics 來源
使用 Azure Synapse Analytics 時,來源選項中有一項名為 [啟用暫存] 的設定。 這可讓服務使用 Staging 從 Synapse 進行讀取,而其使用最高效能的大量載入功能 (例如 CETAS 和 COPY 命令) 大幅改善讀取效能。 您需要在資料流程活動設定中指定 Azure Blob 儲存體或 Azure Data Lake Storage gen2 暫存位置,才能啟動 Staging。
檔案型來源
Parquet 與分隔符號文字
雖然資料流程支援各種檔案類型,但建議使用 Spark 原生 Parquet 格式,以獲得最佳讀取和寫入時間。
如果您在一組檔案上執行相同的資料流程,建議您從資料夾讀取,使用萬用字元路徑或從檔案清單讀取。 單一資料流程活動執行可以批次處理所有檔案。 如需有關如何設定這些設定的詳細資訊,請參閱 Azure Blob 儲存體連接器文件的〈來源轉換〉一節。
請盡量避免使用 For-Each 活動來執行一組檔案上的資料流程。 這會導致 for-each 的每個反覆運算啟動自己的 Spark 叢集,這通常非必要且成本高昂。
內嵌資料集與共用資料集
ADF 和 Synapse 資料集是處理站和工作區中的共用資源。 不過,當您要讀取大量具有分隔符號文字和 JSON 來源的來源資料夾和檔案時,可以在 [投影] | [結構描述選項] 對話方塊內設定 [使用者投影的結構描述] 選項來改善資料流程檔案探索效能。 此選項會關閉 ADF 的預設結構描述自動探索,並大幅改善檔案探索的效能。 設定此選項之前,請務必匯入投影,讓 ADF 具有現有投影結構描述。 此選項不適用於結構描述漂移。
相關內容
請參閱其他與效能相關的資料流程文章: