適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
Data Factory in Microsoft Fabric 是下一代的 Azure Data Factory,擁有更簡單的架構、內建 AI 及新功能。 如果你是資料整合新手,建議先從 Fabric Data Factory 開始。 現有的 ADF 工作負載可升級至 Fabric,以存取資料科學、即時分析與報告等新能力。
- 開始Fabric免費試用。
從 Azure Data Factory 升級到 Microsoft Fabric
Data flows 可同時在 Azure Data Factory pipelines 和 Azure Synapse Analytics pipelines 中使用。 本文適用於對應資料流。 如果您不熟悉資料轉換,請參閱入門文章使用對應資料流程轉換資料。
提示
關於資料流第二世代中等效的轉換(排序),請參閱《 資料流第二世代指南》以映射資料流使用者。
排序轉換可讓您排序目前資料流的內送資料列。 您可以選擇個別資料行,並以遞增或遞減順序排序。
注意
映射資料流在分散資料於多個節點與分區的火花叢集上執行。 如果你選擇在後續轉換中重新分割資料,可能會因為資料重排而失去排序功能。 維護資料流程中排序順序的最佳方式,是在轉換的 [最佳化] 索引標籤中設定單一分割區,並讓「排序」轉換盡可能接近「接收」。
組態
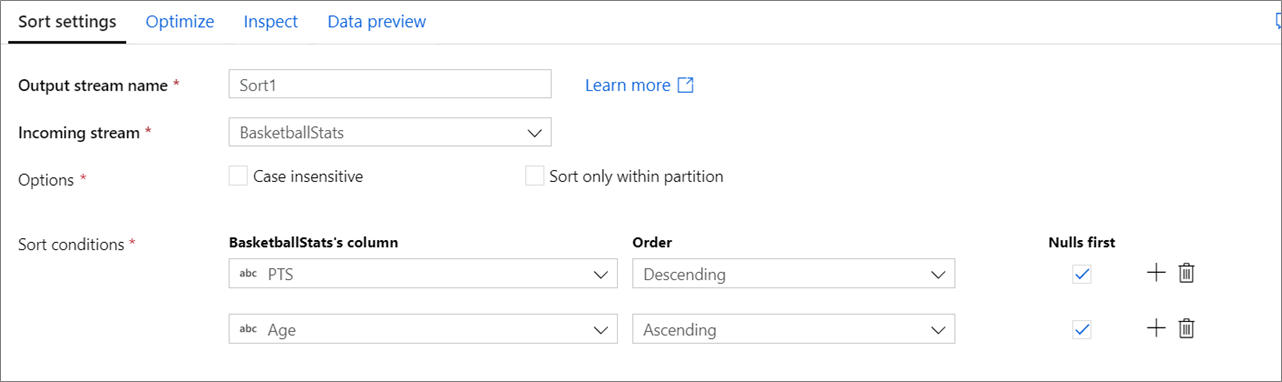
不區分大小寫:不論您在排序字串或文字欄位時是否要忽略大小寫
只在分割區內排序:當資料流程在 Spark 上執行時,每個資料流會分成不同的分割區。 此設定只會在傳入的分割區內排序資料,而不會排序整個資料流。
排序條件:選擇資料行的排序依據及排序的發生順序。 此順序會決定排序優先順序。 選擇空值是否出現在資料流的開始或結尾。
計算資料行
若要在套用排序之前修改或擷取資料行值,請將滑鼠停留在資料行上,然後選取 [計算資料行]。 在表達式建構器中,建立排序運算的表達式,而不是使用欄位值。
資料流程指令碼
語法
<incomingStream>
sort(
desc(<sortColumn1>, { true | false }),
asc(<sortColumn2>, { true | false }),
...
) ~> <sortTransformationName<>
範例
上述排序設定的資料流程指令碼位於下列程式碼片段中。
BasketballStats sort(desc(PTS, true),
asc(Age, true)) ~> Sort1
相關內容
排序後,你可能會想使用 Aggregate Transformation