對應資料流程中的彙總轉換
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用 (部分機器翻譯)!
Azure Data Factory 和 Azure Synapse Pipelines 中均可使用資料流。 本文適用於對應資料流。 如果您不熟悉轉換,請參閱簡介文章使用對應資料流程轉換資料。
彙總轉換會定義資料流中的資料行彙總。 使用運算式產生器可以定義不同類型的彙總,例如依現有或計算資料行分組的 SUM、MIN、MAX 和 COUNT。
選取現有的資料行,或建立新的計算資料行,以作為彙總的群組依據子句。 若要使用現有的資料行,請從下拉式清單中加以選取。 若要建立新的計算資料行,請將滑鼠暫留在子句上方,然後按一下 [計算資料行]。 這會開啟資料流程運算式產生器。 建立計算資料行之後,請在 [命名為] 欄位底下輸入輸出資料行名稱。 如果您想要新增其他群組依據子句,請將滑鼠暫留在現有的子句上方,然後按一下加號圖示。
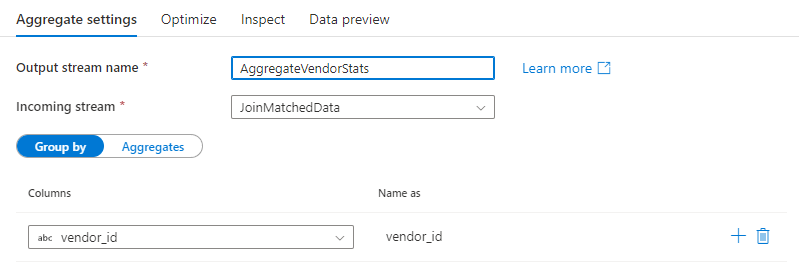
群組依據子句在彙總轉換中是選擇性的。
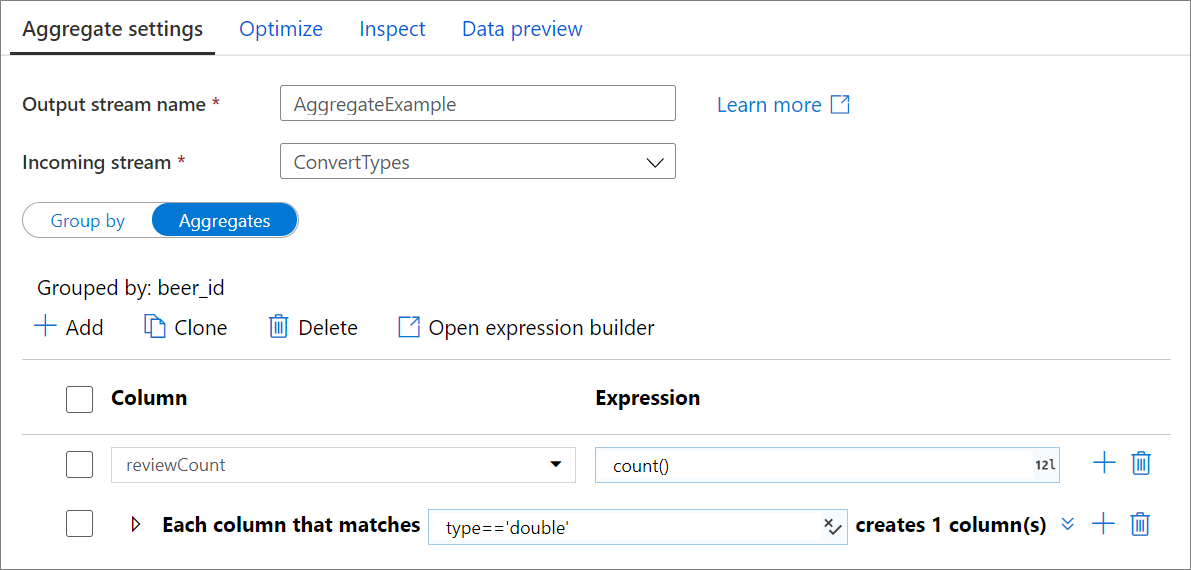
移至 [彙總] 索引標籤以建置彙總運算式。 您可以使用彙總來覆寫現有的資料行,或以新名稱建立新的欄位。 在資料行名稱選取器旁邊的右側方塊中,會輸入彙總運算式。 若要編輯運算式,請按一下文字方塊,然後開啟運算式產生器。 若要新增更多彙總資料行,請按一下資料行清單上方的 [新增],或按一下現有彙總資料行旁邊的加號圖示。 選擇 [新增資料行] 或 [新增資料行模式]。 每個彙總運算式至少須包含一個彙總函式。
注意
在偵錯模式中,運算式產生器無法使用彙總函式產生資料預覽。 若要檢視彙總轉換的資料預覽,請關閉運算式產生器,然後透過 [資料預覽] 索引標籤來檢視資料。
使用資料行模式,將相同的彙總套用至一組資料行。 如果您想要保存輸入結構描述中的許多資料行 (依預設會將其卸除),此功能將有其效用。 使用啟發學習法 (例如 first()),透過彙總保存輸入資料行。
彙總轉換與 SQL 彙總 select 查詢類似。 未包含在群組依據子句或彙總函式中的資料行,不會流向彙總轉換的輸出。 如果您想要在彙總輸出中包含其他資料行,請執行下列其中一種方法:
- 使用
last()或first()之類的彙總函式,包含該額外的資料行。 - 使用自我聯結模式,將資料行重新聯結至您的輸出資料流。
彙總轉換的常見用途是移除或識別來源資料中的重複項目。 此程序稱為重複資料刪除。 根據一組群組依據索引鍵,使用您選擇的啟發學習法來判斷要保留的重複資料列。 常見的啟發學習法包括 first()、last()、max() 和 min()。 使用資料行模式將規則套用至每個資料行,但群組依據資料行除外。
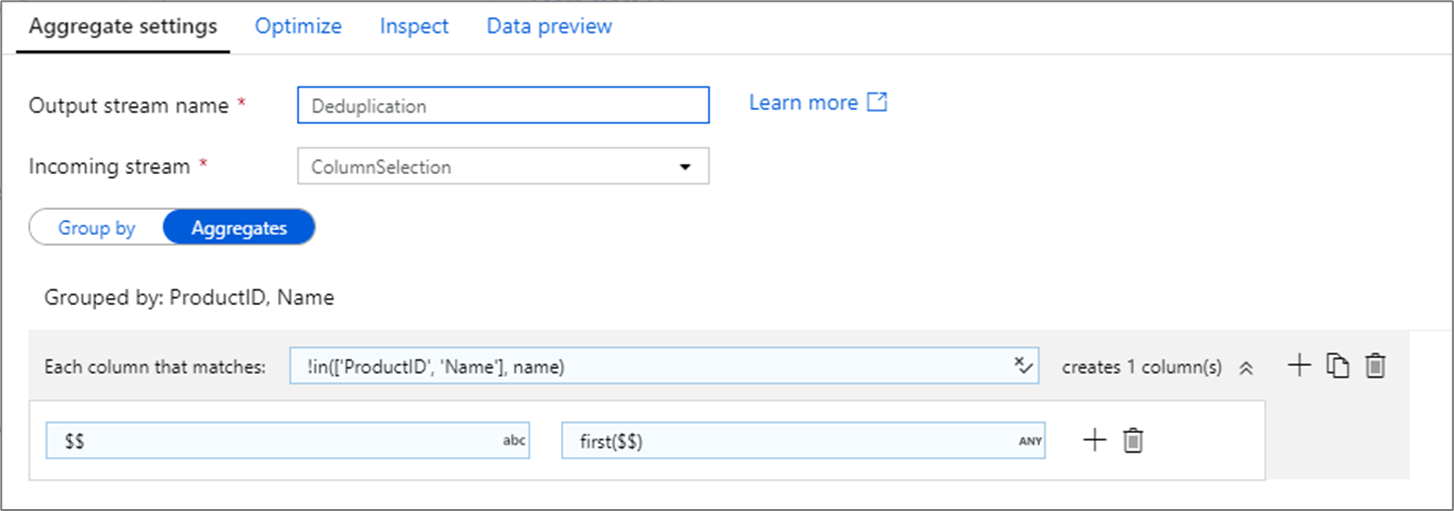
在上述範例中,資料行 ProductID 和 Name 正用於群組。 如果這兩個資料行的兩個資料列有相同的值,就會被視為重複。 在此彙總轉換中,將會保留第一個相符資料列的值,並捨棄所有其他資料列的值。 使用資料行模式語法時,名稱不是 ProductID 和 Name 的所有資料行都會對應至其現有的資料行名稱,並獲得第一個相符資料列的值。 輸出結構描述與輸入結構描述相同。
在資料驗證案例中,count() 函式可用來計算有多少重複項目。
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
下列範例會取用傳入資料流 MoviesYear,並依資料行 year 將資料列分組。 轉換會建立一個彙總資料行 avgrating,而該資料行會評估為資料行 Rating 的平均值。 此彙總轉換名為 AvgComedyRatingsByYear。
在 UI 中,這項轉換看起來如下圖所示:
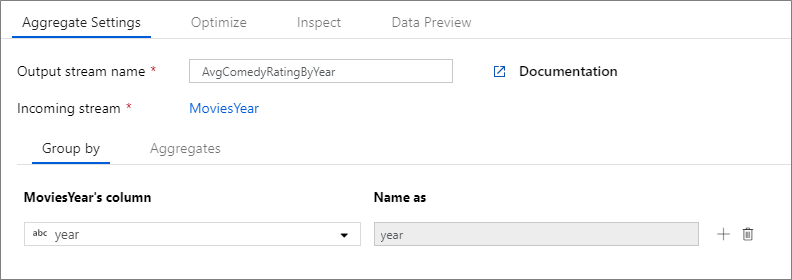
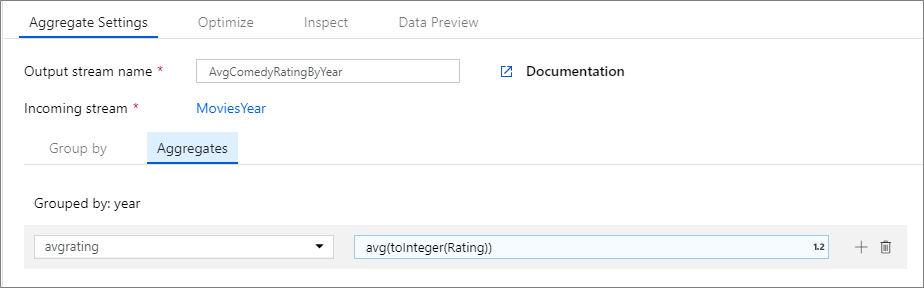
此轉換的資料流程指令碼位於下列程式碼片段中。
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
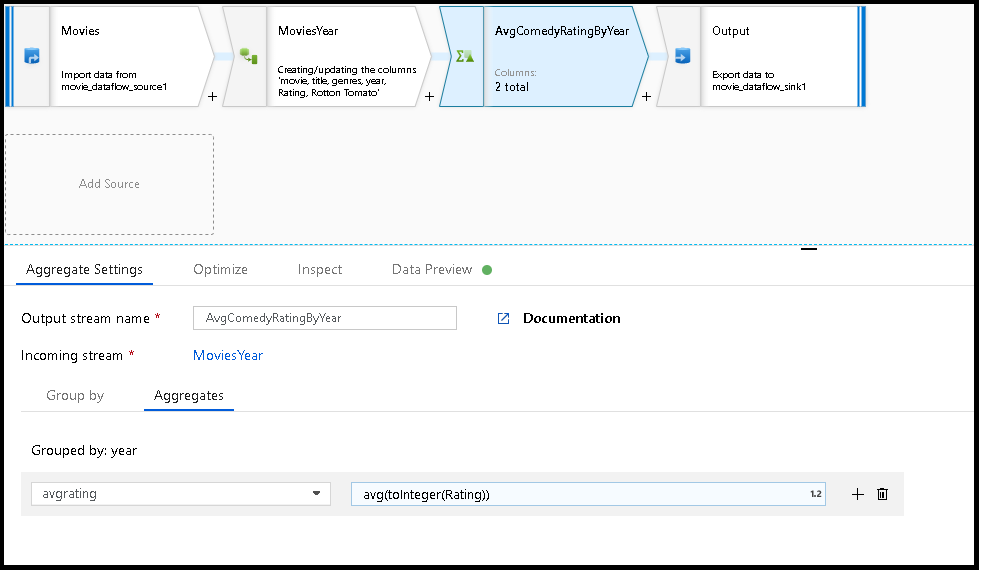
MoviesYear:定義年份和標題資料行的衍生資料行。AvgComedyRatingByYear:依年份分組的喜劇平均收視率的彙總轉換。avgrating:要建立用以保存彙總值的新資料行名稱
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
- 使用時段轉換定義以時段為基礎的彙總