適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
Data Factory in Microsoft Fabric 是下一代的 Azure Data Factory,擁有更簡單的架構、內建 AI 及新功能。 如果你是資料整合新手,建議先從 Fabric Data Factory 開始。 現有的 ADF 工作負載可升級至 Fabric,以存取資料科學、即時分析與報告等新能力。
- 開始Fabric免費試用。
從 Azure Data Factory 升級到 Microsoft Fabric
本文強調如何利用三角洲格式,將資料從儲存在
對應資料流程屬性
此連接器可做為對應資料流程做為來源和接收器的內嵌資料集。
來源屬性
下表列出差異來源所支援的屬性。 您可以在 [來源選項] 索引標籤中編輯這些屬性。
| 名稱 | 描述 | 必要 | 允許的值 | 資料流程指令碼屬性 |
|---|---|---|---|---|
| 格式 | 格式必須是 delta |
是 | delta |
format |
| 檔案系統 | Delta Lake 的容器/檔案系統 | 是 | String | fileSystem |
| 資料夾路徑 | Delta Lake 的目錄 | 是 | String | folderPath |
| 壓縮類型 | Delta 資料表的壓縮類型 | 否 | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| 壓縮等級 | 選擇壓縮是否儘快完成,或是否應該以最佳方式壓縮產生的檔案。 | 如果指定 compressedType,則為必要。 |
Optimal 或 Fastest |
compressionLevel |
| 時間移動 | 選擇是否要查詢 Delta 資料表的較舊快照集 | 否 | 依時間戳記查詢:時間戳記 依版本查詢:整數 |
timestampAsOf versionAsOf |
| 允許找不到任何檔案 | 如果為 true,找不到任何檔案時不會擲回錯誤 | 否 |
true 或 false |
ignoreNoFilesFound |
匯入結構描述
差異只能做為內嵌資料集使用,而且根據預設,沒有相關聯的結構描述。 若要取得資料行中繼資料,請按一下 [投影] 索引標籤中的 [匯入結構描述] 按鈕。這可讓您參考主體所指定的資料行名稱和資料類型。 若要匯入結構描述,資料流程偵錯工作階段必須是作用中,而且您必須有要指向的現有 CDM 實體定義檔。
差異來源指令碼範例
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
接收屬性
下表列出差異接收器所支援的屬性。 您可以在 [設定] 索引標籤中編輯這些屬性。
| 名稱 | 描述 | 必要 | 允許的值 | 資料流程指令碼屬性 |
|---|---|---|---|---|
| 格式 | 格式必須是 delta |
是 | delta |
format |
| 檔案系統 | Delta Lake 的容器/檔案系統 | 是 | String | fileSystem |
| 資料夾路徑 | Delta Lake 的目錄 | 是 | String | folderPath |
| 壓縮類型 | Delta 資料表的壓縮類型 | 否 | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| 壓縮等級 | 選擇壓縮是否儘快完成,或是否應該以最佳方式壓縮產生的檔案。 | 如果指定 compressedType,則為必要。 |
Optimal 或 Fastest |
compressionLevel |
| 真空 | 刪除比指定持續時間更早的檔案,其持續時間與目前資料表版本不再相關。 指定 0 或更小的值時,不會執行真空作業。 | 是 | 整數 | 真空 |
| 資料表動作 | 向 ADF 提供對接收器中目標 Delta 資料表執行的動作。 您可以保持原狀並附加新的資料列、以新的中繼資料和資料覆寫現有的資料表定義和資料,或保留現有的資料表結構,但先截斷所有資料列,然後插入新的資料列。 | 否 | 無、截斷、覆寫 | deltaTruncate、覆寫 |
| 更新方法 | 當您單獨選取 [允許插入] 或寫入新的差異資料表時,目標會接收所有傳入的資料列,而不論設定的資料列原則為何。 如果您的資料包含其他資料列原則的資料列,則必須使用先前的篩選轉換加以排除。 選取所有更新方法時,系統會執行合併,其中資料列會根據使用先前更改資料列轉換所設定的資料列原則進行插入/刪除/upsert/更新。 |
是 |
true 或 false |
insertable deletable upsertable updateable |
| 最佳化寫入 | 透過最佳化 Spark 執行程式中的內部隨機顯示,提高寫入作業的輸送量。 因此,您可能會注意到分割區較少和檔案大小較大 | 否 |
true 或 false |
optimizedWrite:true |
| 自動壓縮 | 在任何寫入作業完成之後,Spark 會自動執行 OPTIMIZE 命令來重新群組織資料,視需要產生更多分割區,藉以在未來提升讀取效能 |
否 |
true 或 false |
autoCompact:true |
差異接收器指令碼範例
相關的資料流程指令碼:
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
具有分割區剪除的差異接收器
使用上述更新方法下的此選項 (也就是 update/upsert/delete),您可以限制檢查的分割區數目。 只會從目標存放區擷取滿足此條件的分割區。 您可以指定分割區資料行可能接受的固定值集。
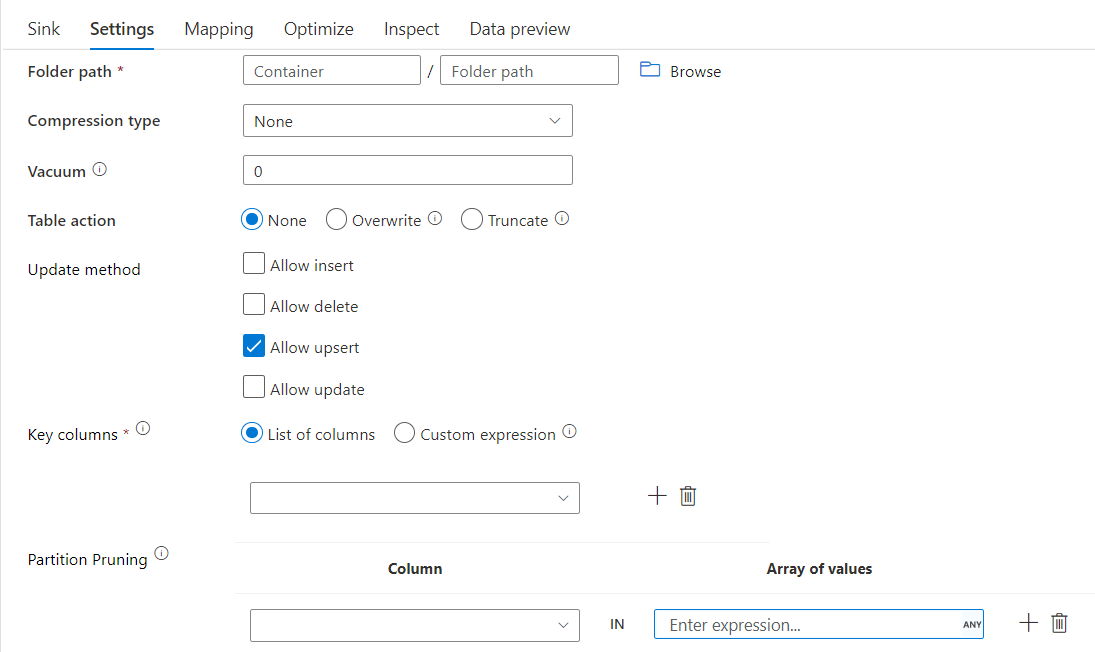
具有分割區剪除的差異接收器指令碼範例
已如下提供樣本指令碼。
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
差異只會讀取 2 個分割區,其中 part_col == 5 和 8 來自目標差異存放區,而不是所有分割區。 part_col 是目標差異資料分割依據的資料行。 其不需要出現在來源資料中。
差異接收器最佳化選項
在 [設定] 索引標籤中,您會找到三個選項來最佳化差異接收器轉換。
啟用 [合併結構描述] 選項時,其允許結構描述演進,也就是說目前在傳入資料流中,但未出現在目標差異資料表中的任何資料行,都會自動新增至其結構描述。 所有更新方法都支援此選項。
啟用自動壓縮時,請在個別寫入後,轉換檢查檔案是否可進一步壓縮,並執行快速 OPTIMIZE 作業 (使用 128 MB 檔案大小而非 1GB),進一步為小型檔案數量最多的分割區壓縮檔案。 自動壓縮有助於將大量小型檔案聯合成較少數量的大型檔案。 自動壓縮只會在至少有 50 個檔案時啟動。 執行壓縮作業之後,其會建立新版本的資料表,並寫入新的檔案,其中包含壓縮格式中數個先前檔案的資料。
啟用最佳化寫入時,接收轉換會嘗試為每個資料表分割區寫出 128 MB 檔案,根據實際資料動態最佳化分割區大小。 這是大約的大小,而且可能會根據資料集特性而有所不同。 最佳化寫入可改善寫入和後續讀取的整體效率。 其會組織分割區,讓後續讀取的效能得以改善。
提示
最佳化寫入程序會降低整體 ETL 作業的速度,因為接收會在資料受到處理之後發出 Spark Delta Lake Optimize 命令。 建議您盡量不要使用最佳化寫入。 例如,如果您有每小時的資料管線,那麼請每天執行具有最佳化寫入的資料流程。
已知的限制
寫入至差異接收器時,已知限制是寫入的資料列數目不會在監視輸出中顯示。