適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
Data Factory in Microsoft Fabric 是下一代的 Azure Data Factory,擁有更簡單的架構、內建 AI 及新功能。 如果你是資料整合新手,建議先從 Fabric Data Factory 開始。 現有的 ADF 工作負載可升級至 Fabric,以存取資料科學、即時分析與報告等新能力。
資料流可同時在 Azure Data Factory 資料管線和 Azure Synapse Analytics 資料管線中使用。 本文適用於映射資料流。 如果您不熟悉轉換,請參閱 使用對應數據流轉換數據的簡介文章。
提示
關於 Dataflow Gen2 中的對等轉換 (取得資料),請參閱用於對應資料流程的 Dataflow Gen2 使用者指南。
來源轉換會設定資料流的資料來源。 當您設計資料流程時,第一個步驟一律是設定來源轉換。 若要新增來源,請選取資料流程畫布中的 [新增來源] 方塊。
每個資料流程至少需要一個來源轉換,但您可視需要新增多個來源來完成資料轉換。 您可以使用合併、查詢或聯集轉換,將這些來源結合在一起。
每個來源轉換都與一個資料集或連結服務相關聯。 資料集會針對您想寫入或讀取的資料,定義其圖形和位置。 如果您使用檔案型資料集,可以在來源中使用萬用字元和檔案清單,一次使用多個檔案。
內嵌資料集
建立來源轉換時,您首先會決定來源資訊是定義在資料集物件中,或是定義在來源轉換內。 大部分的格式只能用於上述其中一個項目中。 若要了解如何使用特定連接器,請參閱適當的連接器文件。
當某種格式同時支援內嵌和資料集物件時,兩者各有其優點。 資料集物件是可重複使用的實體,可用於其他資料流程和活動,例如複製活動。 當您使用經過強化的架構時,這些可重複使用的實體非常有用。 資料集不是以 Spark 為基礎。 您有時可能需要在來源轉換中,覆寫特定設定或結構描述投影。
當您使用彈性結構描述、一次性來源執行個體,或參數化來源時,建議您使用內嵌資料集。 如果您的來源已大量參數化,內嵌資料集可讓您不需建立「虛擬」物件。 內嵌資料集是以 Spark 為基礎,其屬性是資料流程的原生屬性。
若要使用內嵌資料集,請在 [來源類型] 選取器中選取想要的格式。 您不需要選取來源資料集,只需要選取要連線的連結服務。
模式選項
由於內嵌數據集是在數據流內定義,因此沒有與內嵌數據集相關聯的已定義架構。 在 [投影] 索引標籤上,您可以匯入來源資料結構描述,並將該結構描述儲存為來源投影。 在此索引標籤上,您會找到 [架構選項] 按鈕,可讓您定義 ADF 架構探索服務的行為。
- 使用投影架構:當您有大量 ADF 掃描為來源的來源檔案時,此選項很有用。 ADF 的預設行為是探索每個來源檔案的結構描述。 但是,如果您有預先定義的投影已儲存在來源轉換中,您可以將此設置為 true,ADF 就會跳過對每個架構的自動探索。 此選項開啟時,來源轉換將可快速讀取所有檔案,將預先定義的結構描述套用至每個檔案。
- 允許架構漂移:開啟架構漂移,讓您的數據流允許尚未在來源架構中定義的新數據行。
- 驗證架構:如果投影中定義的任何數據行和類型不符合源數據的探索架構,設定此選項會導致數據流失敗。
- 推斷漂移數據行類型:當 ADF 識別新的漂移數據行時,這些新數據行會使用 ADF 的自動類型推斷轉換成適當的數據類型。
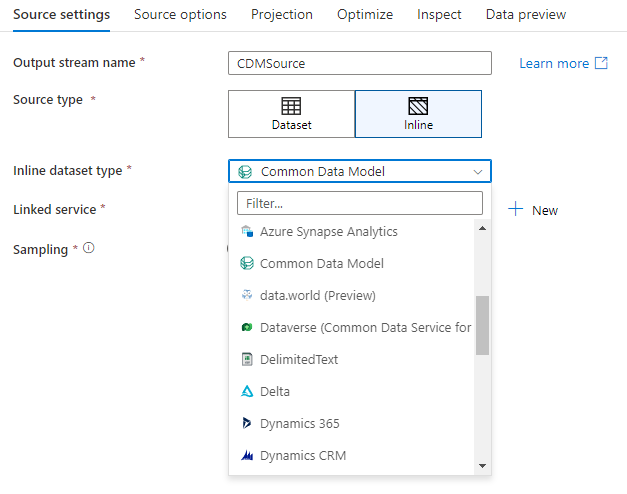
工作區 DB (僅限 Synapse 工作區)
在Azure Synapse工作區中,資料流來源轉換中還有一個稱為 Workspace DB 的額外選項。 這可讓您直接挑選任何可用類型的工作區資料庫作為源數據,而不需要額外的連結服務或數據集。 透過 Azure Synapse 資料庫範本建立的資料庫,也可在選擇 Workspace DB 時存取。
支援的來源類型
資料流程的映射採用擷取、載入與轉換(ELT)方法,適用於staging資料集,這些資料集皆處於Azure中。 下列資料集目前可用於來源轉換。
| 連接器 | 格式 | 資料集/內嵌 |
|---|---|---|
| Amazon S3 |
Avro 分隔符號文字 (部分內容可能是機器或 AI 翻譯) Delta Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Appfigures (預覽) | -/✓ | |
| Asana (預覽) | -/✓ | |
| Azure Blob 儲存體 |
Avro 分隔符號文字 (部分內容可能是機器或 AI 翻譯) Delta Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB(適用於 NoSQL) | ✓/- | |
| Azure Data Lake Storage Gen1 |
Avro 分隔符號文字 (部分內容可能是機器或 AI 翻譯) Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Data Lake Storage Gen2 |
Avro 通用數據模型 分隔符號文字 (部分內容可能是機器或 AI 翻譯) Delta Excel JSON ORC Parquet XML |
✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| 適用於 MySQL 的 Azure 資料庫 | ✓/✓ | |
| 適用於 PostgreSQL 的 Azure 資料庫 | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Azure SQL 受控執行個體 | ✓/✓ | |
| Azure Synapse Analytics | ✓/✓ | |
| data.world (預覽) | -/✓ | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Google 試算表 (預覽) | -/✓ | |
| Hive (部分內容可能是機器或 AI 翻譯) | -/✓ | |
| Quickbase (預覽) | -/✓ | |
| SFTP |
Avro 分隔符號文字 (部分內容可能是機器或 AI 翻譯) Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Smartsheet (預覽) | -/✓ | |
| Snowflake | ✓/✓ | |
| SQL 伺服器 | ✓/✓ | |
| REST | ✓/✓ | |
| TeamDesk (預覽) | -/✓ | |
| Twilio (預覽) | -/✓ | |
| Zendesk (預覽) | -/✓ |
這些連接器特有的設定位於 [來源選項] 索引標籤上。這些設定的相關資訊和資料流程指令碼範例位於連接器文件中。
Azure Data Factory 與 Synapse 管線可存取超過 90 個原生連接器。 若要納入資料流程中其他來源的資料,請使用 [複製活動] 將該資料載入其中一個受支援的暫存區域。
來源設定
新增來源之後,請透過 [來源設定] 索引標籤進行設定。您可以在此處挑選或建立來源點所在的資料集。 您也可以選取資料的結構描述和取樣選項。
資料集參數的開發值可以在偵錯設定中進行設定。 (必須開啟偵錯模式。)
![顯示 [來源設定] 索引標籤的螢幕快照。](media/data-flow/source-1.png)
輸出資料流名稱:來源轉換的名稱。
來源類型:選擇您要使用內嵌資料集或是現有的資料集物件。
測試連線:測試資料流程的 Spark 服務是否可以成功連線到來源資料集中所用的連結服務。 您必須先開啟偵錯模式,才能啟用這項功能。
Schema drift:Schema drift是指服務具有天然的能力,在資料流程中處理彈性結構描述,而無需明確定義欄位變更。
如果源數據行經常變更,請選取 [ 允許架構漂移 ] 複選框。 此設定允許所有的內送來源欄位透過轉換來傳送至接收器。
選取 [推斷漂移的資料行類型],針對探索到的每個新資料行,指示服務進行偵測並定義其資料類型。 關閉此功能后,所有漂移數據行都是字串類型。
驗證架構: 如果 選取 [驗證架構 ],如果傳入源數據不符合數據集的已定義架構,數據流將無法執行。
略過行數:[略過行數] 欄位會指定要在資料集開頭忽略的行數。
取樣: 啟用 [取樣] 功能,來限制來源的資料列數目。 當您從來源測試或取樣資料以進行偵錯時,請使用此設定。 當您從管線中以偵錯模式執行資料流時,此設定便可發揮功效。
若要驗證您的來源是否已正確設定,請開啟偵錯模式並擷取資料預覽。 如需詳細資訊,請參閱偵錯模式。
注意
開啟偵錯模式時,偵錯設定中的數據列限制組態會在數據預覽期間覆寫來源中的取樣設定。
來源選項
[來源選項] 索引標籤,包含所選連接器和格式的特定設定。 如需詳細資訊和範例,請參閱相關的連接器文件。 這包括對支援隔離等級的資料來源(如本地 SQL Server、Azure SQL 資料庫和 Azure SQL 管理實例)的詳細資訊,以及其他資料來源特定的設定。
投影
如同資料集中的結構描述,來源中的投影可定義來源資料的資料行、類型和格式。 對於大部分的數據集類型,例如 SQL 和 Parquet,來源中的投影是固定的,以反映數據集中定義的架構,這會根據來源而有所不同。 當來源檔案不屬於強式類型時 (例如一般的 .csv 檔案,而非 Parquet 檔案),您可以在來源轉換中定義每個欄位的資料類型。 下圖顯示範例投影:
![顯示 [投影] 索引標籤上設定的螢幕快照。](media/data-flow/source-3.png)
如果您的文字檔沒有定義的架構,請選取 [ 偵測數據類型 ],讓服務取樣並推斷數據類型。 選取 [定義預設格式],以自動偵測預設的資料格式。
重設結構描述,會將投影重設為參考資料集中定義的投影。
覆寫結構描述可讓您修改預計的資料類型 (在此為來源),進而覆寫結構描述定義的資料類型。 或者您可以修改下游衍生資料行轉換中的資料行資料類型。 使用選取的轉換來修改資料行名稱。
匯入結構描述
選取 [投影] 索引標籤上的 [匯入結構描述] 按鈕,使用作用中的偵錯叢集來建立結構描述投影。 其適用於每個來源類型。 在此處匯入的結構描述會覆寫資料集中定義的投影。 系統不會變更資料集物件。
匯入模式在像 Avro 和 Azure Cosmos DB 這類支援複雜資料結構且不需要模式定義的資料集中很有用。 針對內嵌資料集,匯入結構描述是在沒有結構描述漂移的情況下參考資料行中繼資料的唯一方法。
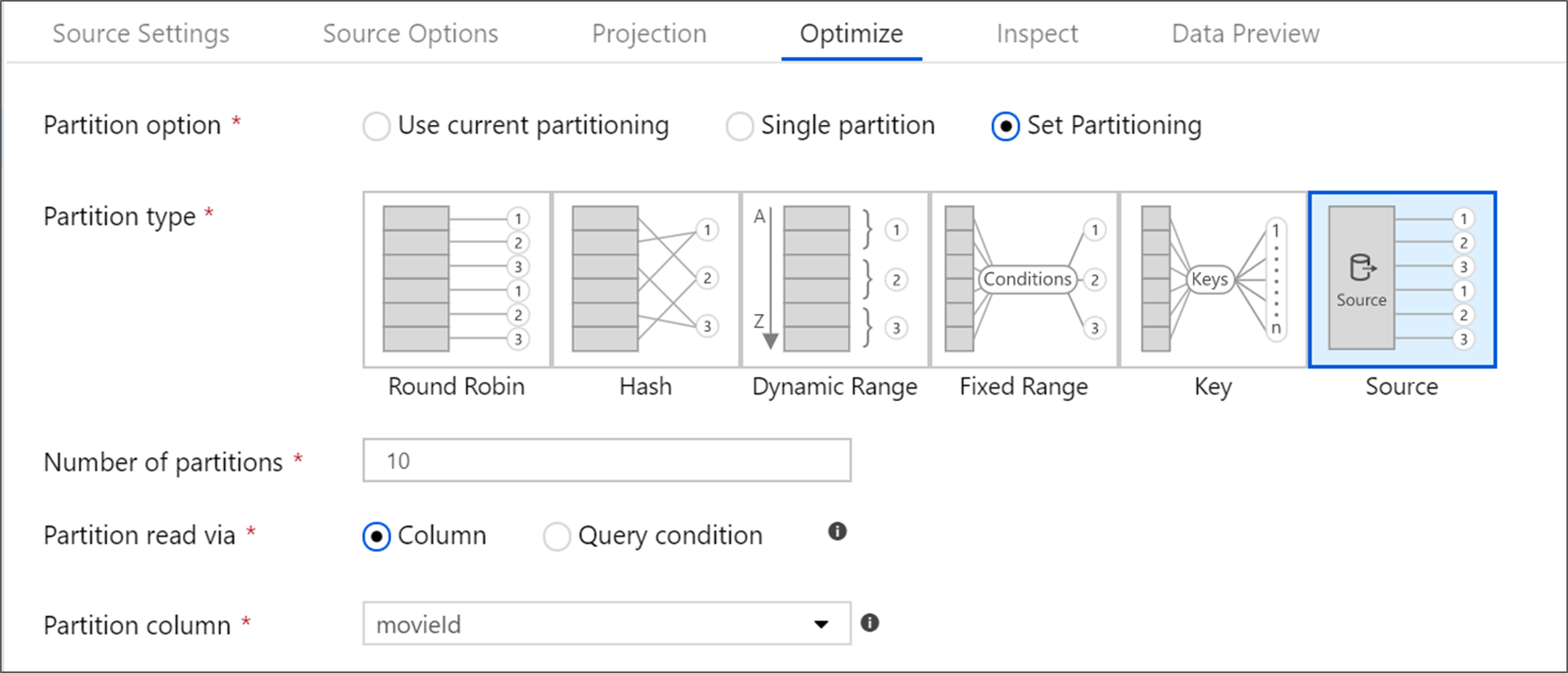
將來源轉換最佳化
[最佳化]頁籤 可讓您在每個轉換步驟編輯分割區資訊。 在大部分情況下,使用目前的資料分割會針對來源的理想資料分割結構進行最佳化。
如果你是從Azure SQL Database來源讀取資料,自訂的 Source分割通常讀取資料最快。 服務會藉由平行連線至資料庫,來讀取大型查詢。 您可以在資料行上進行來源分割,或使用查詢來執行分割。
如需對應資料流內最佳化的詳細資訊,請參閱 [最佳化] 索引標籤 (部分內容可能是機器或 AI 翻譯)。