Azure Data Factory 和 Azure Synapse Analytics 中的 Parquet 格式
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
當您想要剖析 Parquet 檔案或將資料寫入 Parquet 格式時,請遵循本文內容來進行作業。
下列連接器支援 Parquet 格式:
- Amazon S3
- Amazon S3 相容儲存體
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2 \(部分機器翻譯\)
- Azure 檔案
- 檔案系統
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle 雲端儲存空間
- SFTP
如需所有可用連接器的支援功能清單,請造訪連接器概觀一文。
使用自我裝載整合執行階段
重要
針對由自我裝載 Integration Runtime 所授權的複製 (例如,在內部部署與雲端資料存放區之間),如果您不會依原樣複製 Parquet 檔案,就需要在 IR 機器上安裝 64 位元的 JRE 8 (Java Runtime Environment) 或 OpenJDK。 如需更多詳細資料,請參閱接下來的段落。
針對在自我裝載 IR 上搭配 Parquet 檔案序列化/還原序列化來執行的複製,服務會找出 JAVA 執行階段,方法是先檢查登錄 (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome)是否有 JRE,如果找不到,就接著檢查系統變數JAVA_HOME是否有 OpenJDK。
- 若要使用 JRE:64 位元 IR 需要 64 位元 JRE。 您可以從這裡找到該程式。
- 使用 OpenJDK:自 IR 3.13 版開始便可支援。 請將 jvm.dll 與所有其他必要的 OpenJDK 組件一起封裝至自我裝載 IR 機器,然後相應地設定 JAVA_HOME 系統環境變數,然後重新啟動自我裝載 IR 以立即生效。
提示
如果您使用自我裝載 Integration Runtime 將資料複製到 Parquet 格式 (或從該格式複製資料),而且遇到錯誤顯示 [叫用 Java 時發生錯誤。訊息: java.lang.OutOfMemoryError:Java heap space],您可以在裝載自我裝載 IR 的機器中新增環境變數 _JAVA_OPTIONS,以調整 JVM 的堆積大小下限/上限,使系統能執行這樣的複製,然後重新執行管線。
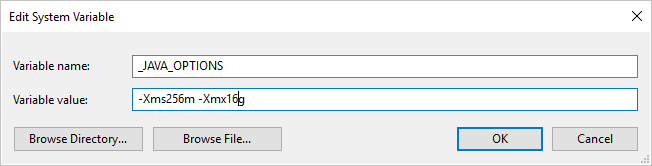
範例:將變數 _JAVA_OPTIONS 的值設定為 -Xms256m -Xmx16g。 旗標 Xms 指定 JAVA 虛擬機器 (JVM) 的初始記憶體配置集區,而 Xmx 指定記憶體配置集區的最大值。 這表示 JVM 啟動時有 Xms 數量的記憶體,且最多可以使用 Xmx 數量的記憶體。 根據預設,服務的使用量下限為 64MB,上限為1G。
資料集屬性
如需可用來定義資料集的區段和屬性完整清單,請參閱資料集一文。 本節提供 Parquet 資料集所支援的屬性清單。
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 資料集的類型屬性必須設為 Parquet。 | Yes |
| location | 檔案的位置設定。 每個檔案型連接器都包含專屬的位置類型,並支援 location 下的屬性。 請參閱連接器文章 -> 資料集屬性一節中的詳細資料。 |
Yes |
| compressionCodec | 寫入 Parquet 檔案時所用的壓縮轉碼器。 從 Parquet 檔案進行讀取作業時,Data Factory 會根據檔案的中繼資料,自動判斷壓縮轉碼器。 支援的類型為 "none"、"gzip"、"snappy" (預設) 和 "lzo"。 請注意,複製活動目前無法在進行讀取/寫入 Parquet 檔案時支援 LZO 類型。 |
No |
注意
Parquet 檔案不支援資料行名稱中的空白字元。
以下是 Azure Blob 儲存體上的 Parquet 資料集範例:
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
複製活動屬性
如需可用來定義活動的區段和屬性完整清單,請參閱管線一文。 本節提供 Parquet 來源和接收器支援的屬性清單。
Parquet 作為來源
複製活動的 [來源] 區段支援下列屬性。
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 複製活動來源的 type 屬性必須設定為 ParquetSource。 | Yes |
| storeSettings | 屬性群組,可決定從資料存放區讀取資料的方式。 在 storeSettings 下,每個檔案型連接器都包含專屬的支援讀取設定。 請參閱連接器文章 -> 複製活動屬性一節中的詳細資料。 |
No |
Parquet 作為接收器
複製活動的 [接收] 區段支援下列屬性。
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 複製活動接收器的 type 屬性必須設定為 ParquetSink。 | Yes |
| formatSettings | 屬性群組。 請參閱下方 Parquet 寫入設定資料表。 | No |
| storeSettings | 屬性群組,可決定將資料寫入資料存放區的方式。 每個以檔案為基礎的連接器在 storeSettings 底下皆具有自身的支援寫入設定。 請參閱連接器文章 -> 複製活動屬性一節中的詳細資料。 |
No |
formatSettings 底下支援的 Parquet 寫入設定:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | formatSettings 的 type 必須設定為 ParquetWriteSettings。 | Yes |
| maxRowsPerFile | 當您將資料寫入資料夾時,可以選擇寫入多個檔案,並指定每個檔案的資料列上限。 | No |
| fileNamePrefix | 當 maxRowsPerFile 完成設定時適用。當您將資料寫入多個檔案時,請指定檔案名稱前置詞,使系統進行此模式: <fileNamePrefix>_00000.<fileExtension>。 如果未指定,系統會自動產生檔案名稱前置詞。 當來源是以檔案為基礎的存放區,或啟用資料分割選項的資料存放區時,系統不會套用此屬性。 |
No |
對應資料流程屬性
在對應資料流程中,您可以在下列資料存放區讀取和寫入 parquet 格式:Azure Blob 儲存體、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2 和 SFTP,且您可以在 Amazon S3 中讀取 parquet 格式。
來源屬性
下表列出 parquet 來源所支援的屬性。 您可以在 [來源選項] 索引標籤中編輯這些屬性。
| 名稱 | 描述 | 必要 | 允許的值 | 資料流程指令碼屬性 |
|---|---|---|---|---|
| 格式 | 格式必須是 parquet |
是 | parquet |
format |
| 萬用字元路徑 | 系統會處理符合萬用字元路徑的所有檔案。 覆寫資料集的資料夾和檔案路徑集合。 | 否 | String[] | wildcardPaths |
| 分割區根路徑 | 如果是分割的檔案資料,您可以輸入分割區根路徑,讀取作為資料行的分割資料夾 | 否 | String | partitionRootPath |
| 檔案清單 | 您的來源是否指向列出待處理檔案的文字檔 | 否 | true 或 false |
fileList |
| 儲存檔案名稱的資料行 | 使用來源檔案名稱和路徑,建立新的資料行 | 否 | String | rowUrlColumn |
| 完成後 | 處理後刪除或移動檔案。 從容器根開始的檔案路徑 | 否 | 刪除:true 或 false 移動: [<from>, <to>] |
purgeFiles moveFiles |
| 依上次修改日期來篩選 | 根據上次變更檔案的時間,選擇篩選的檔案 | 否 | 時間戳記 | modifiedAfter modifiedBefore |
| 允許找不到檔案 | 如果為 true,找不到檔案時不會擲回錯誤 | 否 | true 或 false |
ignoreNoFilesFound |
來源範例
下圖是在對應資料流中 parquet 來源設定的範例。

相關的資料流程指令碼:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
接收屬性
下表列出 parquet 接收器所支援的屬性。 您可以在 [設定] 索引標籤中編輯這些屬性。
| 名稱 | 描述 | 必要 | 允許的值 | 資料流程指令碼屬性 |
|---|---|---|---|---|
| 格式 | 格式必須是 parquet |
是 | parquet |
format |
| 清除資料夾 | 如果在進行寫入之前清除目的地資料夾 | 否 | true 或 false |
truncate |
| 檔案名稱選項 | 已寫入資料的命名格式。 依預設,每個分割區的一個檔案會是 part-#####-tid-<guid> 格式 |
否 | 模式:String 每個分割區:String[] 作為資料行中的資料:String 輸出至單一檔案: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
接收器範例
下圖是在對應資料流中 parquet 接收器設定的範例。

相關的資料流程指令碼:
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
資料類型支援
目前僅資料流程可支援 Parquet 複雜資料類型 (例如 MAP、LIST、STRUCT),複製活動則不支援。 若要在資料流程中使用複雜類型,請勿在資料集中匯入檔案結構描述,並在資料集中將結構描述留白。 然後,在 [來源] 轉換中匯入投影。