將筆記本連結至叢集並運行一個或多個儲存格之後,您的筆記本會有狀態並顯示輸出。 本節說明如何管理筆記本狀態和輸出。
清除筆記本狀態和輸出
若要清除筆記本狀態和輸出,請選擇位於 [執行] 選單底部的其中一個 [清除] 選項。
| 功能表選項 | 描述 |
|---|---|
| 清除所有儲存格輸出 | 清除儲存格的所有輸出。 如果您共用筆記本並想要避免包含任何結果,這非常有用。 |
| 清除狀態 | 清除筆記本狀態,包括函式和變數定義、資料和匯入的程式庫。 |
| 清除狀態和輸出 | 清除儲存格輸出和筆記本狀態。 |
| 清除狀態並執行全部 | 清除筆記本狀態並啟動新的執行。 |
結果數據表
執行儲存格時,結果會顯示在結果數據表中。 使用結果資料表,您可以執行下列動作:
- 將數據行或其他表格式結果數據子集複製到剪貼簿。
- 對結果數據表執行文字搜尋。
- 排序和篩選資料。
- 使用鍵盤箭頭鍵在表格儲存格之間流覽。
- 選取資料行名稱或儲存格值的一部分,雙擊並拖曳以選取所需的文字。
- 使用 欄瀏覽器 來搜尋、顯示或隱藏、釘選和重新排列欄位。
若要檢視結果資料表的限制,請參閱 Notebook 結果資料表限制。
選取數據
若要在結果數據表中選取數據,請執行下列任一動作。
- 將資料或數據子集複製到剪貼簿。
- 按一下欄位或列標頭。
- 按兩下表格左上方的儲存格,以選取整個資料表。
- 將游標拖曳到任何一組單元格上,以選取它們。
- 要選取多欄,按住
Ctrl (Windows)或Cmd (macOS),並點擊其他欄位標題。 接著你可以使用  同時對所有選取的欄位套用複製、篩選、格式化和釘選。
同時對所有選取的欄位套用複製、篩選、格式化和釘選。
要開啟顯示選擇資訊的側窗格,請點擊右上角![]() panel icon搜尋框旁的窗格圖。
panel icon搜尋框旁的窗格圖。
![]()
將資料複製至剪貼板
若要將 CSV 格式的結果資料表複製到剪貼簿,請按下資料表標題索引標籤旁的向下箭號,然後按兩下 [將結果複製到剪貼簿。

或者,點擊表格左上角的方塊以選取整個表格,然後按下滑鼠右鍵,從下拉功能表中選擇 複製。
有數種方式可以複製選取的數據:
- 在 MacOS 按
Cmd + C,或在 Windows 按Ctrl + C,將結果以 CSV 格式複製到剪貼簿。 - 以滑鼠右鍵按下並選取 [複製],以 CSV 格式將結果複製到剪貼簿。
- 以滑鼠右鍵按下並選取 [複製為,以 CSV、TSV 或 Markdown 格式複製選取的數據。

排序結果
若要依數據行中的值排序結果數據表,請將游標暫留在數據行名稱上。 包含數據行名稱的圖示會出現在單元格右邊。 點擊箭頭以排序欄位。
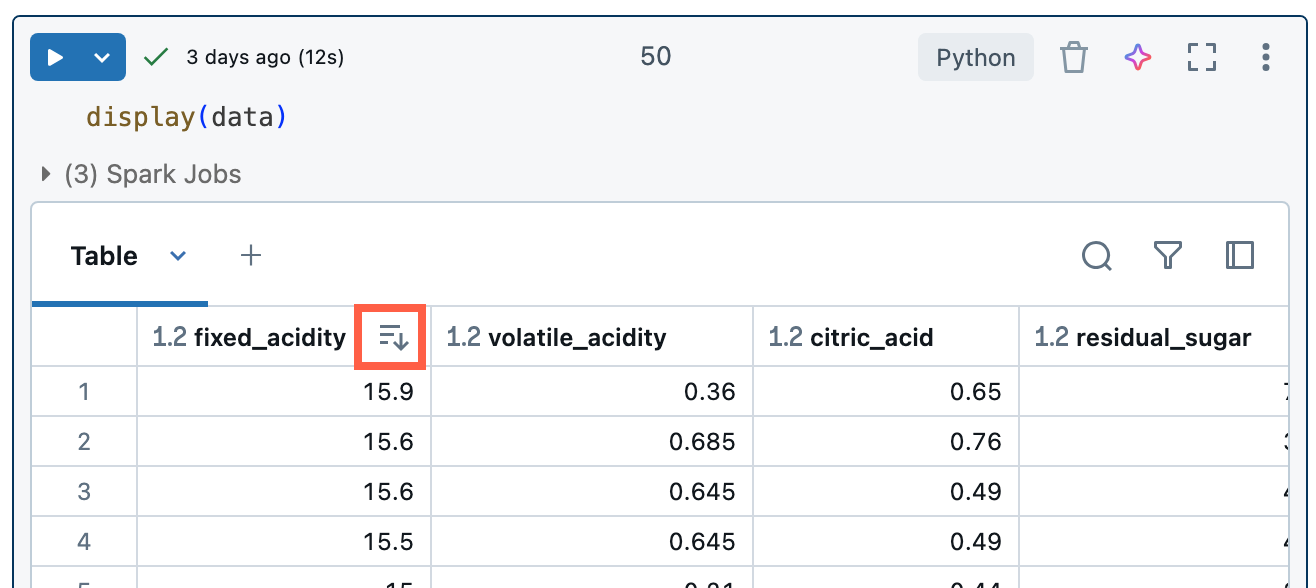
若要依多個數據行排序,請在按兩下數據行的排序箭號時,按住 Shift 鍵。
根據預設,排序會遵循自然排序順序。 若要強制執行語彙排序順序,請在 SQL 或環境中可用的個別 ORDER BY 函式中使用 SORT。
篩選結果
使用結果數據表上的篩選來深入了解數據。 套用至結果數據表的篩選也會影響視覺效果,在不修改基礎查詢或數據集的情況下啟用互動式探索。 請參閱 篩選視覺效果。
有數種方式可以建立篩選:
Databricks 助理
使用自然語言提示與小幫手互動
使用自然語言提示建立篩選器:
- 按兩下
![[篩選] 圖示。](../_static/images/product-icons/filtericon.svg) 在儲存格結果的右上方。
在儲存格結果的右上方。 - 在出現的對話框中,輸入描述所要篩選條件的文字。
- 按兩下
![[傳送] 圖示。](../_static/images/product-icons/sendicon.svg) 。 Genie Code 會自動生成並套用這個篩選器。
。 Genie Code 會自動生成並套用這個篩選器。
如果您想要使用小幫手建立其他篩選,請按兩下 [ ![]() 在篩選條件旁輸入另一個提示。
在篩選條件旁輸入另一個提示。
請參閱使用自然語言提示篩選資料。
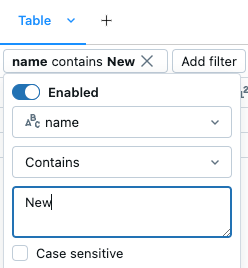
篩選對話框
使用內建篩選對話框
- 如果你沒有啟用精靈代碼,請點擊篩選 在格子結果右上角開啟篩選對話框。 您也可以按下
![[新增篩選] 按鈕](../_static/images/notebooks/add-filter.png) 來存取此對話框。
來存取此對話框。 - 選取您要篩選的數據行。
- 選取您要套用的篩選規則。
- 選取您想要篩選的值。
按價值
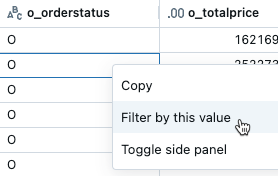
依特定值篩選
- 從結果表中,右鍵點擊帶有該值的儲存格。
- 從下拉功能表中選取 [ 依此值篩選 ]。
按欄
篩選特定數據行
- 將滑鼠停留在您要篩選的數據行上。
- 按兩下 。
- 按兩下 [篩選]。
- 選取您要篩選的值。
要暫時開啟或關閉過濾器,請點擊對話框中的 啟用/停用 按鈕。
若要刪除篩選,請按下 ![]() 在篩選名稱旁
在篩選名稱旁  。
。
將篩選套用至完整數據集
根據預設,篩選只會套用至結果數據表中顯示的結果。 如果傳回的數據被截斷(例如,當查詢傳回超過 10,000 個數據列或數據集大於 2MB 時),篩選只會套用至傳回的數據列。 數據表右上方的附註表示篩選已套用至截斷的數據。
你可以選擇篩選完整資料集。 點選 「截斷資料」,然後選擇 「完整資料集」。 視數據集的大小而定,套用篩選可能需要很長的時間。

從篩選的結果建立查詢
從具有 SQL 作為 預設語言的筆記本中篩選的結果數據表或視覺效果,您可以使用套用的篩選條件來建立新的查詢。 在數據表或視覺效果的右上方,按兩下 [建立查詢]。 查詢會新增為筆記本中的下一個儲存格。
建立的查詢會在原始查詢上方套用篩選。 這可讓您使用更小、更相關的數據集,以更有效率地探索和分析數據。

探索欄位
為了方便使用具有許多數據列的數據表,您可以使用數據列瀏覽器。 若要開啟欄目探險器,請點擊結果表格右上方的欄圖示(![]() )。
)。
欄位瀏覽器可讓您:
- 搜尋資料列:在搜尋列中輸入以篩選資料列清單。 點擊瀏覽器中的欄,即可前往結果表格的該欄。
- 顯示或隱藏資料行:使用複選框來控制數據行可見性。 頂端的複選框可以同時切換所有欄位的可見性。 您可以使用其名稱旁的複選框來顯示或隱藏個別數據行。
- 釘選欄位:將滑鼠停留在欄位名稱上方以顯示釘選圖示。 按一下釘選圖示以釘選欄位。 當您水平捲動結果表時,釘選的欄會保持可見。
-
重新排列數據行:按住數據行名稱右邊的拖曳圖示(
 ),然後將數據行拖放到其新的所需位置。 這會重新排序結果數據表中的數據行。
),然後將數據行拖放到其新的所需位置。 這會重新排序結果數據表中的數據行。

格式化欄位
數據行標頭表示數據行的數據類型。 例如,整數類型數據行  表示整數數據類型。 將滑鼠停留在指標上方以查看資料類型。
表示整數數據類型。 將滑鼠停留在指標上方以查看資料類型。
您可以將結果表中的欄格式化為不同的類型,例如 貨幣、百分比、URL 等等,並控制小數位數,以便讓表格更清楚地呈現。
從欄名稱的kebab選單格式化欄位。
下載結果
預設狀態下,會啟用下載結果。 要更改此設定,請參閱 「管理從筆記本下載結果的能力」。
您可以將包含表格式輸出的儲存格結果下載到本機電腦。 按一下索引標籤標題旁邊的向下方向鍵。 功能表選項取決於結果中的資料列數目和 Databricks Runtime 版本。 下載的結果會以 CSV 檔案形式儲存在本機電腦上,檔案名稱對應於您的筆記本名稱。
對於連接到 SQL 倉庫或無伺服器運算的筆記本,你也可以下載結果的 Excel 檔案。

探索 SQL 儲存格結果
在 Databricks 筆記本中,SQL 語言的單元格結果會自動被指派給變數 _sqldf,作為 DataFrame 來使用。 你可以用 _sqldf 變數來參考後續 Python 和 SQL 儲存格中之前的 SQL 輸出。 如需詳細資訊,請參閱 探索 SQL 數據格結果。
檢視每個儲存格的多個輸出
Python筆記本和非Python的筆記本中的%python單元支持每個單元多個輸出。 例如,下列程式代碼的輸出同時包含繪圖和數據表:
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
iris = pd.DataFrame(data=data.data, columns=data.feature_names)
ax = iris.plot()
print("plot")
display(ax)
print("data")
display(iris)
調整輸出大小
藉由拖曳數據表或視覺效果的右下角來調整單元格輸出的大小。

提交 Databricks Git 資料夾中的筆記本內容
若要了解如何提交 .ipynb 筆記本輸出,請參閱允許提交 .ipynb 筆記本輸出。
- 筆記本必須是 .ipynb 檔案
- 工作區管理員設定必須允許提交筆記本輸出