在 HDInsight 中搭配 Apache Hadoop 使用 Apache Ambari Hive 檢視
了解如何使用 Apache Ambari Hive 檢視執行 Hive 查詢。 Hive 檢視可讓您從網頁瀏覽器編寫、最佳化及執行 Hive 查詢。
必要條件
HDInsight 上的 Hadoop 叢集。 請參閱開始在 Linux 上使用 HDInsight。
執行 HIVE 查詢
從 Azure 入口網站中,選取您的叢集。 請參閱列出和顯示叢集以取得指示。 叢集會在新的入口網站檢視中開啟。
從 [叢集儀表板] 中,選取 [Ambari 檢視]。 出現驗證的提示時,請使用您在建立叢集時提供的叢集登入 (預設為
admin) 帳戶名稱和密碼。 您也可以在瀏覽器中,導覽至https://CLUSTERNAME.azurehdinsight.net/#/main/views,其中CLUSTERNAME是叢集的名稱。從檢視清單中,選取 [Hive 檢視]。
Hive 檢視頁面類似於下圖:
![[Hive 檢視] 的查詢工作表影像。](media/apache-hadoop-use-hive-ambari-view/ambari-worksheet-view.png)
從 [查詢] 索引標籤中,將下列 HiveQL 陳述式貼到工作表中:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;這些陳述式會執行下列動作:
陳述式 描述 DROP TABLE 刪除資料表和資料檔 (如果資料表已經存在)。 CREATE EXTERNAL TABLE 在 Hive 中建立新的「外部」資料表。 外部資料表只會將資料表定義儲存在 Hive 中。 資料會留在原來的位置。 ROW FORMAT 顯示設定資料格式的方式。 在此情況下,每個記錄中的欄位會以空格隔開。 STORED AS TEXTFILE LOCATION 顯示資料的儲存位置,以及資料是儲存為文字。 SELECT 選取 t4 資料行包含 [ERROR] 值之所有資料列的計數。 重要
將 [資料庫] 選取項目保留為 [預設]。 本文件中的範例使用 HDInsight 隨附的預設資料庫。
若要啟動查詢,請選取工作表下方的 [執行]。 按鈕會變成橘色,而且文字會變更為 [停止]。
查詢完成之後,[結果] 索引標籤會顯示作業的結果。 下列文字是查詢結果:
loglevel count [ERROR] 3您可以使用 [記錄] 索引標籤來檢視作業所建立的記錄資訊。
提示
在 [結果] 索引標籤下方的 [動作] 下拉式對話方塊中,下載或儲存結果。
視覺效果說明
若要顯示查詢計劃的視覺效果,請選取工作表下方的 [視覺效果說明] 索引標籤。
查詢的 [視覺效果說明] 檢視有助於了解複雜查詢的流程。
Tez UI
若要顯示查詢的 Tez UI,請選取工作表下方的 [Tez UI] 索引標籤。
重要
Tez 的用途並非解析所有查詢。 您不需要使用 Tez 便可解析許多查詢。
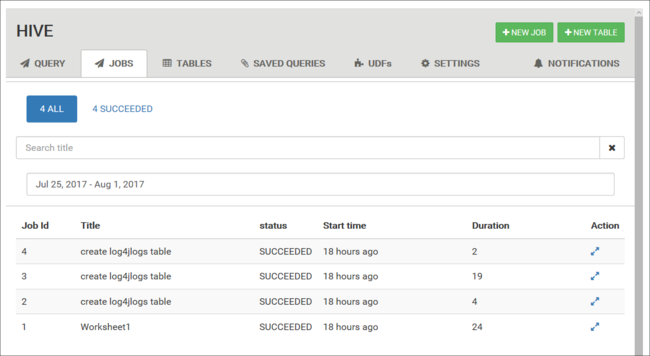
檢視作業記錄
[作業] 索引標籤會顯示 Hive 查詢的歷程記錄。
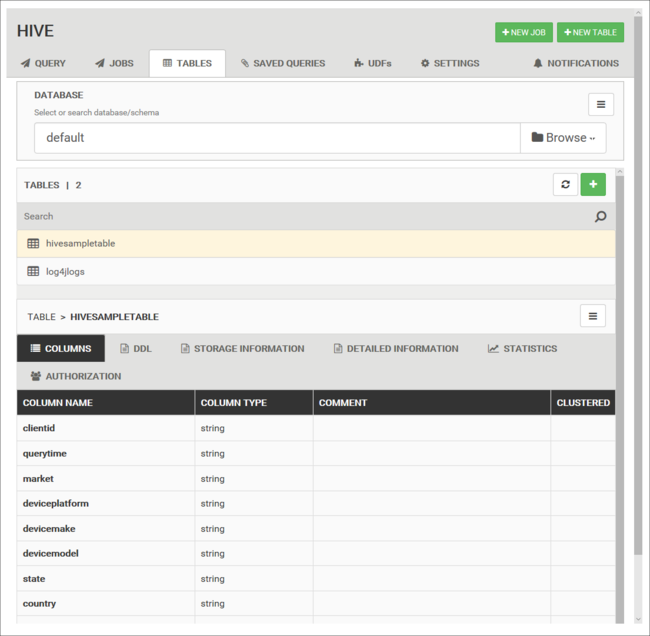
資料庫資料表
您可以使用 [資料表] 索引標籤,在 Hive 資料庫中使用資料表。
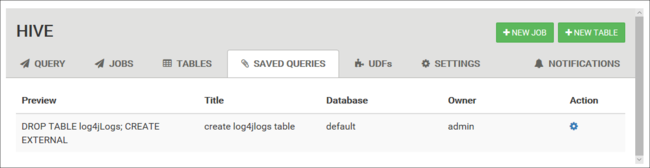
已儲存的查詢
從 [查詢] 索引標籤中,您可以選擇性地儲存查詢。 儲存查詢之後,您就可以從 [儲存的查詢] 索引標籤重複使用它。
提示
已儲存的查詢會存放在預設叢集儲存體中。 您可以路徑 /user/<username>/hive/scripts 下找到儲存的查詢。 這些查詢會儲存為純文字 .hql 檔案。
如果您刪除該叢集,但保留儲存體,您可以使用 Azure 儲存體總管或 Data Lake 儲存體總管 (從 Azure 入口網站) 之類的公用程式來擷取查詢。
使用者自訂函數
您可以透過使用者定義函式 (UDF) 來擴充 Hive 。 使用 UDF 在 HiveQL 中實作不易模型化的功能或邏輯。
使用 [Hive 檢視] 頂端的 [UDF] 索引標籤來宣告並儲存一組 UDF。 這些 UDF 可以在 [查詢編輯器] 中使用。
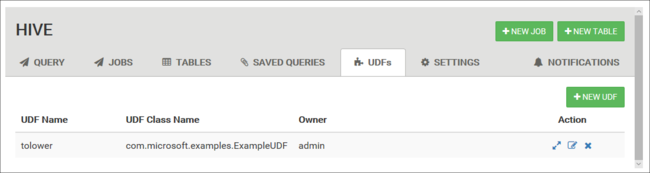
[插入 udfs] 按鈕會顯示在 [查詢編輯器] 的底部。 這個項目會顯示 [Hive 檢視] 中定義之 UDF 的下拉式清單。 選取 UDF 會將 HiveQL 陳述式新增至查詢以啟用 UDF。
例如在已使用下列屬性定義 UDF 的情況下:
資源名稱:myudfs
資源路徑︰/myudfs.jar
UDF 名稱:myawesomeudf
UDF 類別名稱:com.myudfs.Awesome
使用 [插入 udf] 按鈕會顯示名為 [myudfs] 的項目,以及針對該資源定義的每個 UDF 的另一個下拉式清單。 在此案例中為 myawesomeudf。 選取此項目會將下列項目新增至查詢的開頭:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
您接著可以在查詢中使用 UDF。 例如: SELECT myawesomeudf(name) FROM people; 。
如需在 HDInsight 上搭配 Hive 使用 UDF 的詳細資訊,請參閱下列文章:
Hive 設定
您可以變更各種 Hive 設定,例如將 Hive 的執行引擎從 Tez (預設) 變更為 MapReduce。
下一步
如需 HDInsight 中 Hive 的一般資訊: