將 Azure HDInsight 中的 Apache Hive 查詢最佳化
本文說明一些最常見的效能最佳化,可用於改善 Apache Hive 查詢的效能。
叢集類型選取
在 Azure HDInsight 中,您可在幾個不同的叢集類型上執行 Apache Hive 查詢。
選擇適當的叢集類型,有助於依工作負載需求最佳化效能:
- 選擇互動式查詢叢集類型,可將
ad hoc、互動式查詢最佳化。 - 選擇 Apache Hadoop 叢集類型,將作為批次程序使用的 Hive 查詢最佳化。
- Spark 和 HBase 叢集類型也可執行 Hive 查詢,若您執行那些工作負載也可能適用。
如需針對不同 HDInsight 叢集類型執行 Hive 查詢的詳細資訊,請參閱Azure HDInsight 上的 Apache Hive 和 HiveQL 是什麼?。
擴增背景工作節點
增加 HDInsight 叢集中的背景工作節點數目,可讓工作使用更多對應器和歸納器平行執行。 在 HDInsight 中您有兩種方法可擴增:
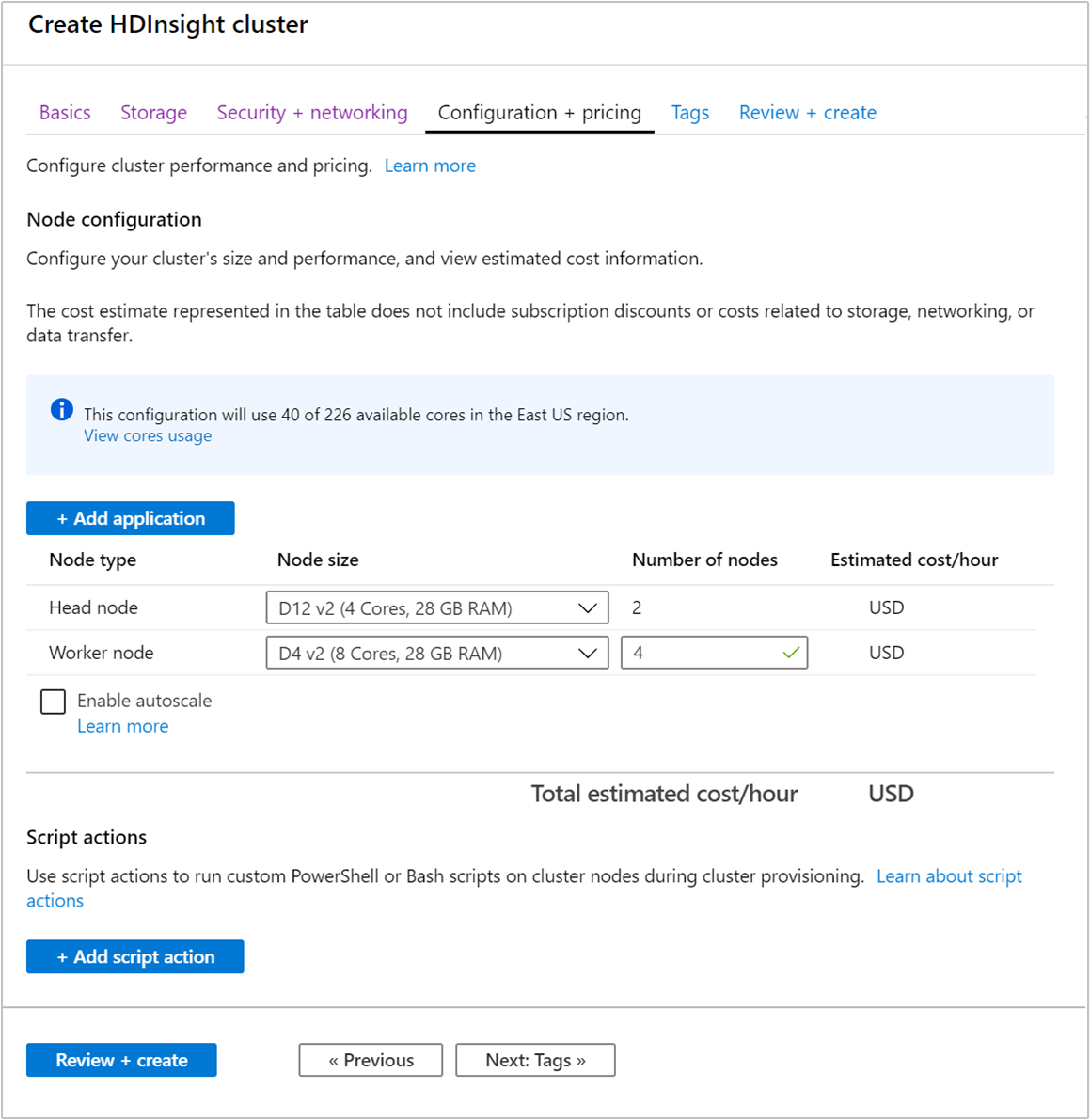
建立叢集時,您可使用 Azure 入口網站、Azure PowerShell 或命令列介面來指定背景工作節點的數目。 如需詳細資訊,請參閱建立 HDInsight 叢集。 下列畫面顯示 Azure 入口網站上的背景工作節點組態:
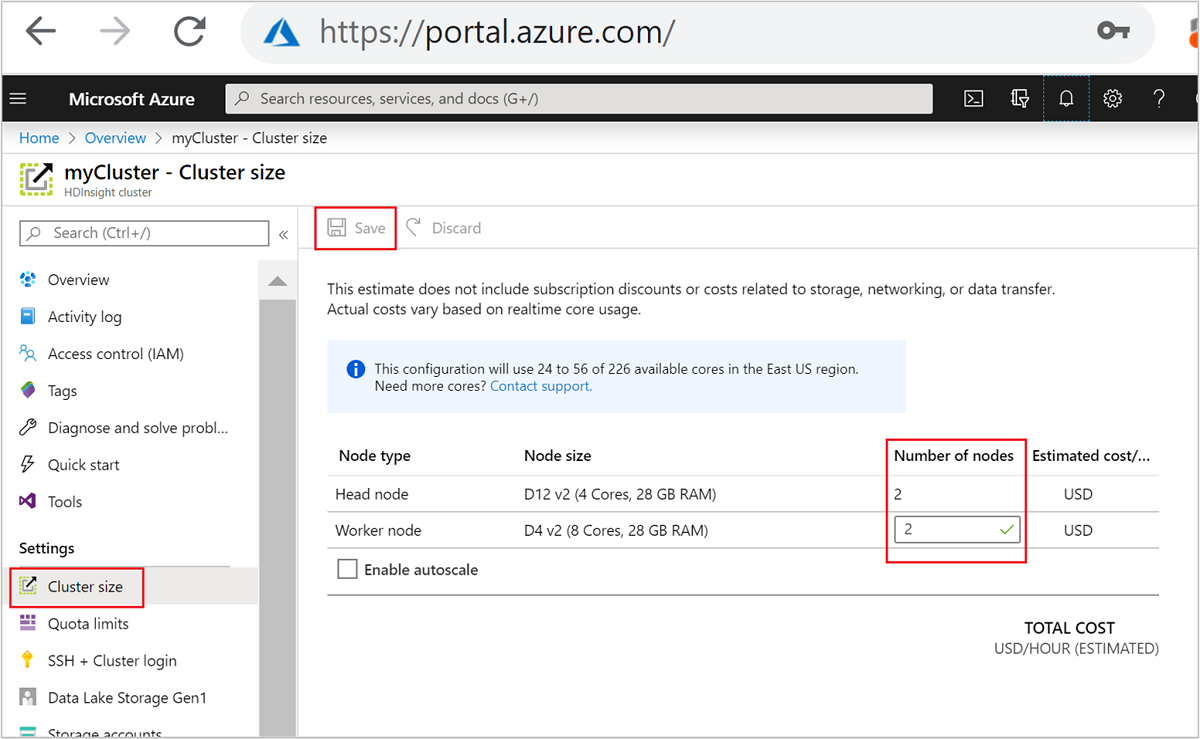
建立之後,您也可以編輯背景工作節點數目,以進一步擴增叢集,而不必重新建立:
如需調整 HDInsight 的詳細資訊,請參閱調整 HDInsight 叢集
使用 Apache Tez 而非 Mapreduce
Apache Tez 是 MapReduce 引擎的替代執行引擎。 以 Linux 為基礎的 HDInsight 叢集預設啟用 Tez。
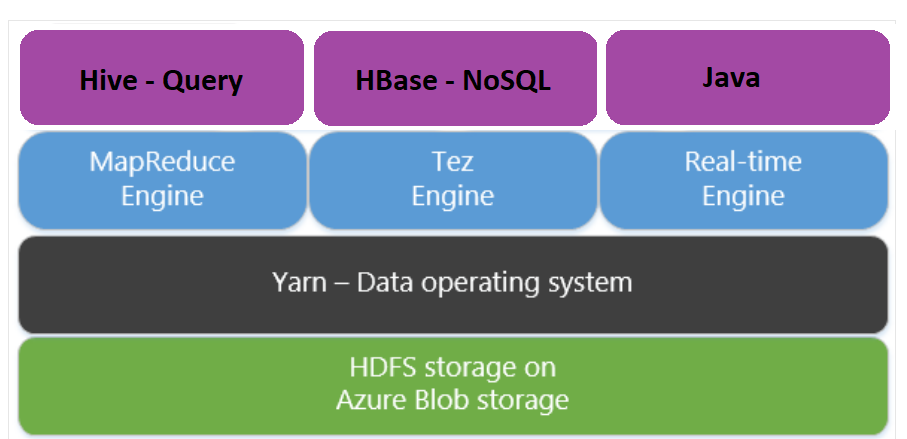
Tez 比較迅速,因為:
- 在 MapReduce 引擎中,以單一作業的形式執行有向非循環圖 (DAG)。 DAG 要求每組對應器後面接著一組 Reducer。 這項需求會導致每個 Hive 查詢有多個 MapReduce 作業遭到關閉。 Tez 沒有這類條件約束,而且可以將複雜的 DAG 處理為一項作業,以將作業啟動額外負荷降至最低。
- 避免不必要的寫入。 多項作業可用來處理 MapReduce 引擎中的相同 Hive 查詢。 每個 MapReduce 作業的輸出都會寫入 HDFS 以取得中繼資料。 由於 Tez 將每個 Hive 查詢的作業數目降到最低,因此可以避免不必要的寫入。
- 將啟動延遲降至最低。 Tez 藉由減少需要啟動的對應器數目,以及改善整個最佳化,以將啟動延遲降到最低。
- 重複使用容器。 只要有可能,Tez 就會重複使用容器,以確保減少啟動容器的延遲。
- 持續最佳化技術。 傳統上會在編譯階段完成最佳化。 不過,我們提供了有關輸入的詳細資訊,可在執行階段進行更好的最佳化。 Tez 會使用持續最佳化技術,讓其進一步將方案最佳化至執行階段。
如需這些概念的詳細資訊,請參閱 Apache TEZ。
在查詢的前面加上下列設定命令,即可啟用任何 Hive 查詢 Tez:
set hive.execution.engine=tez;
Hive 分割
I/O 作業是執行 Hive 查詢的主要效能瓶頸。 如果可以減少需要讀取的資料量,即可改善效能。 根據預設,Hive 查詢會掃描整個 Hive 資料表。 但是,對於只需要掃描少量資料的查詢 (例如具有篩選的查詢),這種行為就會產生不必要的額外負荷。 Hive 分割可讓 Hive 查詢只存取 Hive 資料表中所需的資料量。
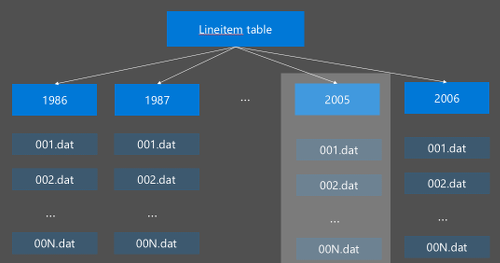
Hive 資料分割的實作方法是將未經處理的資料重新整理成新的目錄。 每個分割區都有自己的檔案目錄。 使用者定義資料分割。 下圖說明如何依據 年度資料行來分割 Hive 資料表。 每年都會建立新的目錄。
一些分割考量:
- 請勿分割不足 - 若只依據少數幾個值的資料行進行分割,可能會造成很少的分割區。 例如,依據性別進行分割時,只會建立兩個分割區 (男性和女性),最多讓延遲降低一半。
- 請勿分割過度 - 另一方面,在具有唯一值 (如使用者識別碼) 的資料行建立分割區時,則會造成多個分割區。 過度分割會在叢集 namenode 上造成太多壓力,因為它必須處理大量目錄。
- 避免資料扭曲 - 明智地選擇分割索引鍵,讓所有分割區的大小平均。 例如,「州/省」資料行上的資料分割可能會扭曲資料的分佈。 由於加州的人口幾乎是佛蒙特州的 30 倍,因此,分割區大小可能會有偏差,且效能可能有極大差異。
若要建立分割資料表,請使用 Partitioned By 子句:
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
建立分割資料表後,您可以建立靜態分割或動態分割。
靜態資料分割表示您在適當的目錄中已有分區化資料。 使用靜態資料分割,您可以根據目錄位置手動新增 Hive 資料分割。 下列範例為程式碼片段。
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'動態分割 表示您要 Hive 為您自動建立分割區。 您已從暫存資料表建立資料分割資料表,因此僅須將資料插入至資料分割資料表:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
如需詳細資訊,請參閱資料分割資料表 \(英文\)。
使用 ORCFile 格式
Hive 支援不同的檔案格式。 例如:
- 文字:預設檔案格式且適用於大部分的案例。
- Avro:適用於互通性案例。
- ORC/Parquet:最適合處理效能。
ORC (最佳化的資料列單欄式) 格式是儲存 Hive 資料的高效率方式。 相較於其他格式,ORC 具有下列優點:
- 支援複雜的類型,包括 DateTime 和複雜和半結構化類型。
- 高達 70% 的壓縮。
- 每 10,000 個資料列的索引可讓您略過一些資料列。
- 執行階段的執行大幅減少。
若要啟用 ORC 格式,請先使用子句 Stored as ORC建立資料表:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
接著,將資料從暫存資料表插入至 ORC 資料表。 例如:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
您可以在 Apache Hive 語言手冊 (英文) 進一步了解 ORC 格式。
向量化
向量化可讓 Hive 一起處理 1024 個資料列的批次,而不是一次處理一個資料列。 這表示簡單的作業會更快完成,因為需要執行較少的內部程式碼。
若要啟用向量化,請在 Hive 查詢的前面加上以下列設定:
set hive.vectorized.execution.enabled = true;
如需詳細資訊,請參閱 向量化查詢執行。
其他最佳化方法
您有更多最佳化方法可以考慮,例如:
- Hive 值區: 能將大型資料集叢集化或分段以最佳化查詢效能的技術。
- 聯結最佳化: Hive 的查詢執行計劃最佳化,可改善聯結的效率並減少使用者提示的需求。 如需詳細資訊,請參閱 聯結最佳化。
- 增加歸納器。
下一步
在本文中,您學到幾種常見的 Hive 查詢最佳化方法。 如需詳細資訊,請參閱下列文章: