在 Azure HDInsight 中使用 Apache Ambari 優化 Apache Hive
Apache Ambari 是用來管理和監視 HDInsight 叢集的 Web 介面。 如需Ambari Web UI的簡介,請參閱 使用Apache Ambari Web UI管理 HDInsight 叢集。
下列各節說明優化整體 Apache Hive 效能的組態選項。
- 若要修改 Hive 組態參數,請從 [服務] 提要字段中選取 [Hive ]。
- 瀏覽至 [ 設定] 索引標籤 。
設定Hive執行引擎
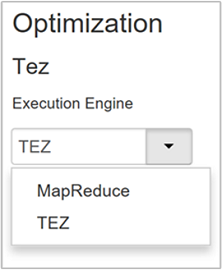
Hive 提供兩個執行引擎:Apache Hadoop MapReduce 和 Apache TEZ。 Tez 比 MapReduce 快。 HDInsight Linux 叢集具有Tez作為預設執行引擎。 若要變更執行引擎:
在 [Hive 組態] 索引 標籤中,於篩選方塊中輸入 執行引擎 。
Optimization 屬性的預設值為 Tez。
調整對應程式
Hadoop 會嘗試將單一檔案分割成多個檔案,並以平行方式處理產生的檔案。 對應程式的數目取決於分割的數目。 下列兩個組態參數會驅動 Tez 執行引擎的分割數目:
tez.grouping.min-size:群組分割大小下限,預設值為 16 MB(16,777,216 個字節)。tez.grouping.max-size:群組分割大小上限,預設值為 1 GB(1,073,741,824 個字節)。
作為效能指導方針,請降低這兩個參數以改善延遲,以提高輸送量。
例如,若要為 128 MB 的數據大小設定四個對應程式工作,請將這兩個參數分別設定為 32 MB(33,554,432 個字節)。
若要修改限制參數,請流覽至 Tez 服務的 [設定 ] 索引標籤。 展開 [ 一般] 面板,然後找出
tez.grouping.max-size和tez.grouping.min-size參數。將這兩個參數設定為 33,554,432 個字節(32 MB)。

這些變更會影響伺服器上的所有 Tez 作業。 若要取得最佳結果,請選擇適當的參數值。
微調歸納器
Apache ORC 和 Snappy 都提供高效能。 不過,Hive 預設可能會有太少的歸納器,而導致瓶頸。
例如,假設您的輸入數據大小為 50 GB。 具有Snappy 壓縮的ORC格式數據為1 GB。 Hive 會估計所需的歸納器數目:(對應器/ hive.exec.reducers.bytes.per.reducer的位元組輸入數目)。
使用預設設定時,此範例是四個歸納器。
參數 hive.exec.reducers.bytes.per.reducer 會指定每個歸納器處理的位元元組數目。 預設值為 64 MB。 將此值調低會增加平行處理原則,並可能改善效能。 調整太低也可能產生太多歸納器,可能會對效能造成負面影響。 此參數是以您的特定數據需求、壓縮設定和其他環境因素為基礎。
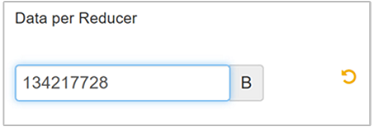
若要修改參數,請流覽至 [Hive Configs] 索引標籤,並在 [設定] 頁面上尋找 [每個歸納器] 參數的數據。
選取 [編輯 ] 將值修改為 128 MB(134,217,728 個字節),然後按 Enter 儲存。
假設輸入大小為 1,024 MB,每個歸納器的數據為 128 MB,則有 8 個歸納器(1024/128)。
每個 Reducer 參數的數據值不正確,可能會導致大量的歸納器,對查詢效能造成負面影響。 若要限制歸納器數目上限,請將 設定
hive.exec.reducers.max為適當的值。 預設值為 1009。
啟用平行執行
Hive 查詢會在一或多個階段中執行。 如果獨立階段可以平行執行,這會增加查詢效能。
若要啟用平行查詢執行,請流覽至 [Hive 設定 ] 索引標籤並搜尋
hive.exec.parallel屬性。 預設值為 false。 將值變更為 true,然後按 Enter 以儲存值。若要限制平行執行的作業數目,請修改
hive.exec.parallel.thread.number屬性。 預設值為 8。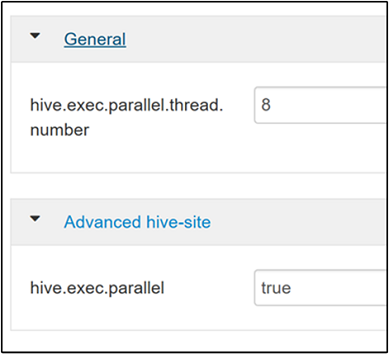
啟用向量化
Hive 會逐列處理數據列。 向量化會將Hive導向處理1,024個數據列區塊中的數據,而不是一次處理一個數據列。 向量化僅適用於 ORC 檔案格式。
若要啟用向量化查詢執行,請流覽至 [Hive 組態] 索引 標籤並搜尋
hive.vectorized.execution.enabled參數。 Hive 0.13.0 或更新版本的預設值為 true。若要啟用查詢縮減端的向量化執行,請將 參數設定
hive.vectorized.execution.reduce.enabled為 true。 預設值為 false。
開啟以成本為基礎的優化 (CBO)
根據預設,Hive 會遵循一組規則來尋找一個最佳的查詢執行計劃。 以成本為基礎的優化 (CBO) 會評估多個計劃來執行查詢。 並將成本指派給每個方案,然後判斷執行查詢的成本最低。
若要啟用 CBO,請流覽至 Hive>Configs> 設定 並尋找 [啟用成本型優化器],然後將切換按鈕切換為 [開啟]。

啟用 CBO 時,下列其他組態參數會增加 Hive 查詢效能:
hive.compute.query.using.stats設定為 true 時,Hive 會使用儲存在其中繼存放區中的統計資料來回應簡單的查詢,例如
count(*)。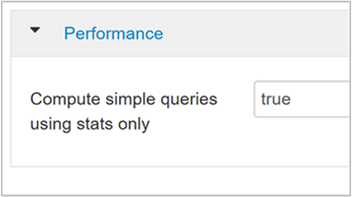
hive.stats.fetch.column.stats啟用 CBO 時,會建立數據行統計數據。 Hive 會使用儲存在中繼存放區中的數據行統計數據來優化查詢。 當數據行數目很高時,擷取每個數據行的數據行統計數據需要較長的時間。 當設定為 false 時,此設定會停用從中繼存放區擷取數據行統計數據。
hive.stats.fetch.partition.stats基本數據分割統計數據,例如數據列數目、數據大小和檔案大小,會儲存在中繼存放區中。 如果設定為 true,則會從中繼存放區擷取分割區統計數據。 若為 false,則會從文件系統擷取檔案大小。 而且會從數據列架構擷取數據列數目。
如需進一步閱讀,請參閱 Azure 部落格上的分析中的 Hive 成本型優化部落格文章
啟用中繼壓縮
對應工作會建立歸納器工作所使用的中繼檔案。 中繼壓縮會壓縮中繼檔案大小。
Hadoop 作業通常是 I/O 瓶頸。 壓縮數據可以加速 I/O 和整體網路傳輸。
可用的壓縮類型如下:
| 格式 | 工具 | 演算法 | 副檔名 | 可分割? |
|---|---|---|---|---|
| Gzip | Gzip | 緊縮 | .gz |
No |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
Yes |
| LZO | Lzop |
LZO | .lzo |
是,如果已編製索引 |
| 活潑 | N/A | 活潑 | 活潑 | No |
一般情況下,讓壓縮方法可分割很重要,否則會建立少數對應程式。 如果輸入數據是文字, bzip2 則為最佳選項。 針對 ORC 格式,Snappy 是最快的壓縮選項。
若要啟用中繼壓縮,請流覽至 [Hive 組態 ] 索引標籤,然後將 參數設定
hive.exec.compress.intermediate為 true。 預設值為 false。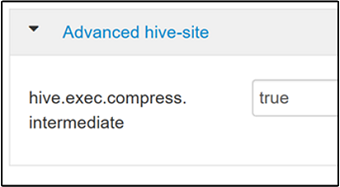
注意
若要壓縮中繼檔案,請選擇 CPU 成本較低的壓縮編解碼器,即使編解碼器沒有高壓縮輸出也一樣。
若要設定中繼壓縮編解碼器,請將自定義屬性
mapred.map.output.compression.codec新增至hive-site.xml或mapred-site.xml檔案。若要新增自訂設定:
a. 流覽至 [Hive>設定>進階>自定義 Hive-site]。
b. 選取 [自定義 Hive 網站] 窗格底部的 [新增屬性... ]。
c. 在 [新增屬性] 視窗中,輸入
mapred.map.output.compression.codec作為索引鍵和org.apache.hadoop.io.compress.SnappyCodec值。d. 選取 [新增]。
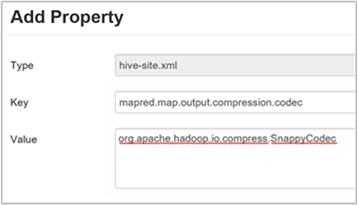
此設定會使用 Snappy 壓縮來壓縮中繼檔案。 新增 屬性之後,它就會出現在 [自定義 Hive 網站] 窗格中。
注意
此程式會
$HADOOP_HOME/conf/hive-site.xml修改檔案。
壓縮最終輸出
最後的Hive輸出也可以壓縮。
若要壓縮最終的Hive輸出,請流覽至 [Hive 組態 ] 索引標籤,然後將 參數設定
hive.exec.compress.output為 true。 預設值為 false。若要選擇輸出壓縮編解碼器,請將
mapred.output.compression.codec自定義屬性新增至 [自定義 Hive 網站] 窗格,如上一節的步驟 3 所述。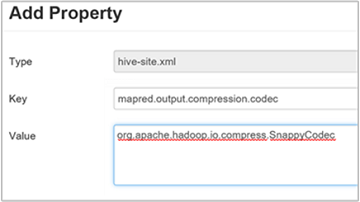
啟用推測性執行
推測式執行會啟動特定數目的重複工作,以偵測和拒絕列出緩慢執行的工作追蹤器。 藉由優化個別工作結果來改善整體作業執行。
對於具有大量輸入的長時間執行的 MapReduce 工作,不應該開啟推測式執行。
若要啟用推測性執行,請流覽至 [Hive Configs ] 索引標籤,然後將 參數設定
hive.mapred.reduce.tasks.speculative.execution為 true。 預設值為 false。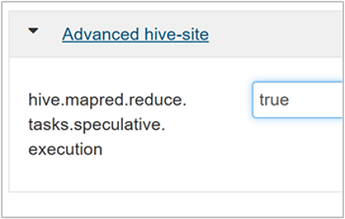
調整動態分割區
Hive 允許在將記錄插入數據表時建立動態分割區,而不需要預先定義每個分割區。 這項功能是一項強大的功能。 雖然可能會導致建立大量的分割區。 以及每個分割區的大量檔案。
若要讓Hive執行動態分割區,
hive.exec.dynamic.partition參數值應該是 true (預設值)。將動態分割模式變更為 strict。 在 strict 模式中,至少一個分割區必須是靜態的。 此設定可防止 WHERE 子句中沒有數據分割篩選條件的查詢,也就是說 ,strict 會防止掃描所有分割區的查詢。 流覽至 [Hive 設定] 索引 標籤,然後將 設定
hive.exec.dynamic.partition.mode為 strict。 預設值為 非字串。若要限制要建立的動態分割區數目,請修改
hive.exec.max.dynamic.partitions參數。 預設值為 5000。若要限制每個節點的動態分割區總數,請修改
hive.exec.max.dynamic.partitions.pernode。 預設值為 2000。
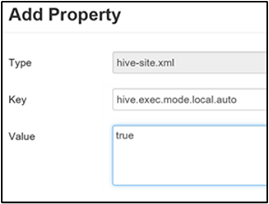
啟用本機模式
本機模式可讓Hive在單一電腦上執行作業的所有工作。 或有時是在單一程式中。 如果輸入數據很小,此設定可改善查詢效能。 而啟動查詢工作的額外負荷會耗用整體查詢執行的重要百分比。
若要啟用本機模式,請將 參數新增hive.exec.mode.local.auto至自定義Hive網站面板,如啟用中繼壓縮一節的步驟3中所述。
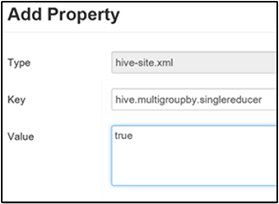
設定單一 MapReduce MultiGROUP BY
當此屬性設定為 true 時,具有一般群組索引鍵的 MultiGROUP BY 查詢會產生單一 MapReduce 作業。
若要啟用此行為,請將 參數新增hive.multigroupby.singlereducer至 [自定義 Hive 網站] 窗格,如啟用中繼壓縮一節的步驟 3 中所述。
其他Hive優化
下列各節說明您可以設定的其他Hive相關優化。
聯結優化
Hive 中的預設聯結類型是 隨機聯結。 在Hive中,特殊對應程式會讀取輸入,並將聯結索引鍵/值組發出至中繼檔案。 Hadoop 會在隨機階段排序和合併這些配對。 這個洗牌階段很昂貴。 根據您的數據選取正確的聯結可大幅改善效能。
| 聯結類型 | 時機 | 方式 | Hive 設定 | 註解 |
|---|---|---|---|---|
| 隨機聯結 |
|
|
不需要重要的Hive設定 | 每次都能運作 |
| 對應聯結 |
|
|
hive.auto.confvert.join=true |
快速,但有限 |
| 排序合併貯體 | 如果這兩個數據表都是:
|
每個程式:
|
hive.auto.convert.sortmerge.join=true |
高效率 |
執行引擎優化
最佳化 Hive 執行引擎的其他建議:
| 設定 | 建議需求 | HDInsight 預設值 |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = 更安全、更緩慢;false = 更速 | false |
tez.am.resource.memory.mb |
最多 4 GB 上限 | 自動調整 |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20000+ | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40000+ | 20000 |