使用 Apache Hadoop、Apache Spark、Apache Kafka 及其他工具在 HDInsight 中設定叢集
了解如何在 HDInsight 中安裝並設定 Apache Hadoop、Apache Spark、Apache Kafka、互動式查詢或 Apache HBase。 此外,了解如何自訂叢集,並將叢集加入網域以提升安全性。
Hadoop 叢集由數個虛擬機器 (節點) 組成,可用於分散處理作業。 Azure HDInsight 會處理個別節點所安裝和設定的實作細節,您只需要提供一般設定資訊即可。
重要
HDInsight 叢集的計費起自叢集建立時,終至叢集刪除時。 計費是以每分鐘按比例計算,因此不再使用時,請一律刪除您的叢集。 了解如何刪除叢集。
如果您同時使用多個叢集,您會想要建立虛擬網路,如果您使用的是 Spark 叢集,也會想要使用 Hive Warehouse Connector。 如需詳細資訊,請參閱針對 Azure HDInsight 規劃虛擬網路和整合 Apache Spark 和 Apache Hive 與 Hive Warehouse Connector。
叢集設定方法
下表顯示可用來設定 HDInsight 叢集的不同方法。
| 叢集建立方法 | 網頁瀏覽器 | 命令列 | REST API | SDK |
|---|---|---|---|---|
| Azure 入口網站 | ✅ | |||
| Azure Data Factory | ✅ | ✅ | ✅ | ✅ |
| Azure CLI | ✅ | |||
| Azure PowerShell | ✅ | |||
| cURL | ✅ | ✅ | ||
| Azure 資源管理員範本 | ✅ |
本文會逐步引導您完成 Azure 入口網站中的設定,您可以在此入口網站中建立 HDInsight 叢集。
基本概念
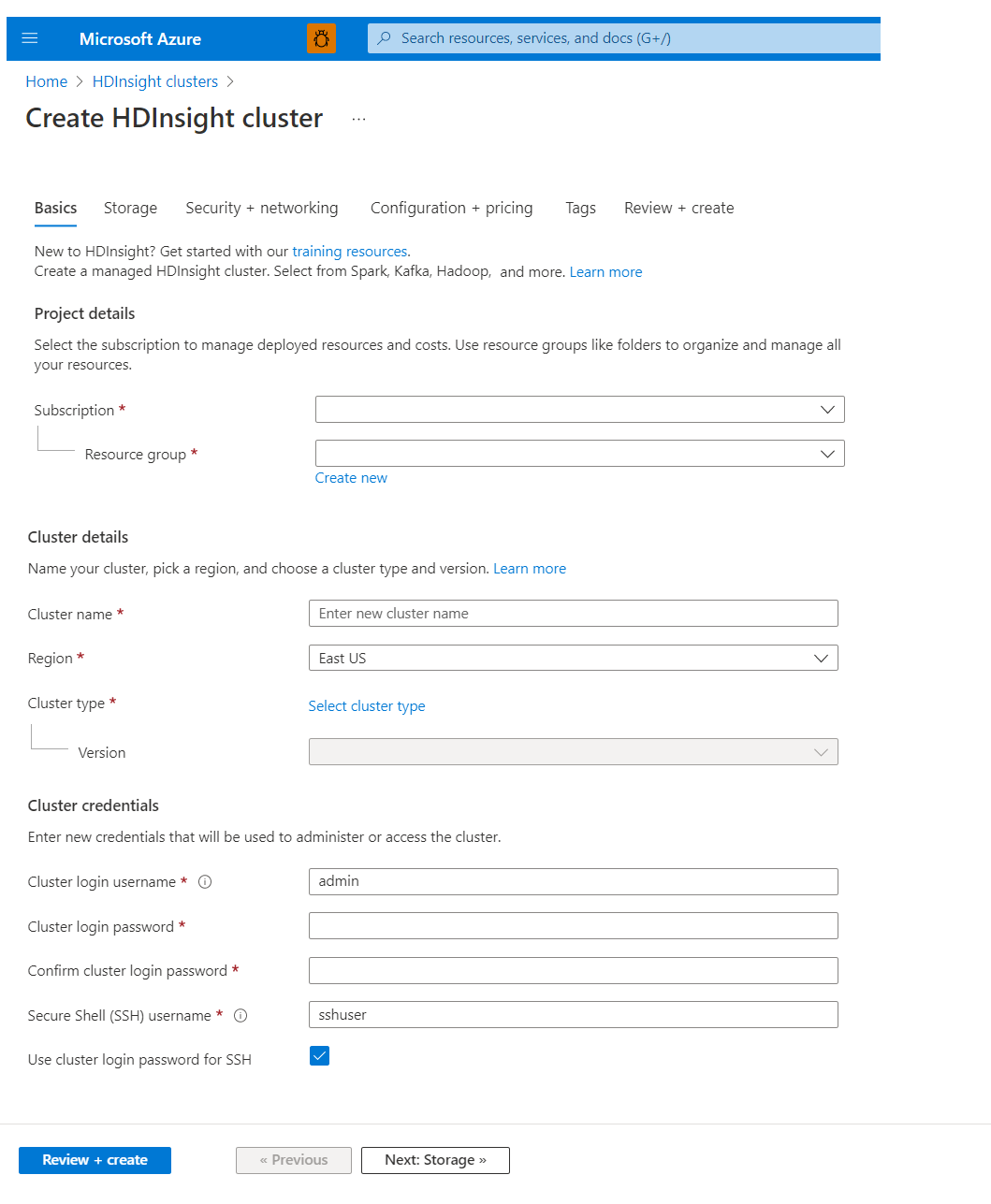
專案詳細資料
Azure Resource Manager 可協助您將應用程式中的資源做為群組使用,稱為 Azure 資源群組。 您可以在單一、協調的作業中,將應用程式的所有資源進行部署、更新、監視或刪除。
叢集詳細資料
叢集名稱
HDInsight 叢集名稱具有下列限制:
- 允許的字元:a-z、0-9、A-Z
- 長度上限:59
- 保留名稱:apps
- 叢集命名範圍適用於所有 Azure,橫跨所有訂用帳戶。 因此,叢集名稱必須是全球唯一的。
- 前六個字元在虛擬網路內必須是唯一的
區域
不需明確指定叢集位置:叢集位於和預設儲存體相同的位置。 如需支援的區域清單,請選取 HDInsight 價格中的 [區域] 下拉式清單。
叢集類型
Azure HDInsight 目前提供下列的叢集類型,每種都有一組提供特定功能的元件。
重要
HDInsight 叢集有多種類型,每種類型均適用於單一工作負載或技術。 沒有任何支援方法可建立結合多個類型的叢集,例如在一個叢集上並存 HBase。 如果您的解決方案需要會分散到多個 HDInsight 叢集類型的技術,Azure 虛擬網路可以連接必要的叢集類型。
| 叢集類型 | 功能 |
|---|---|
| Hadoop | 批次查詢和分析儲存的資料 |
| HBase | 處理大量無綱要的 NoSQL 資料 |
| 互動式查詢 | 更快速之互動式 Hive 查詢的記憶體內快取 |
| Kafka | 可用來建置即時串流資料管線和應用程式的分散式串流平台 |
| Spark | 記憶體內處理、互動式查詢、微批次串流處理 |
版本
選擇此叢集的 HDInsight 版本。 如需詳細資訊,請參閱支援的 HDInsight 版本。
叢集認證
使用 HDInsight 叢集,您可以在建立叢集期間設定兩個使用者帳戶:
- 叢集登入使用者名稱:預設名稱是系統管理員。使用 Azure 入口網站上的基本組態。 有時稱為「叢集使用者」或「HTTP 使用者」。
- 安全殼層 (SSH) 使用者名稱:用來透過 SSH 連線至叢集。 如需詳細資訊,請參閱搭配 HDInsight 使用 SSH。
HTTP 使用者名稱具有下列限制:
- 允許的特殊字元:
_和@ - 不允許的字元:
#;."',/:!*?$(){}[]<>|&--=+%~^space` - 最大長度:20
SSH 使用者名稱具有下列限制:
- 允許的特殊字元:
_和@ - 不允許的字元:
#;."',/:!*?$(){}[]<>|&--=+%~^space` - 最大長度:64
- 保留名稱:hadoop、users、oozie、hive、mapred、ambari-qa、zookeeper、tez、hdfs、sqoop、yarn、hcat、ams、hbase、administrator、admin、user、user1、test、user2、test1、user3、admin1、1、123、a、
actuser、adm、admin2、aspnet、backup、console、David、guest、John、owner、root、server、sql、support、support_388945a0、sys、test2、test3、user4、user5、spark
儲存體
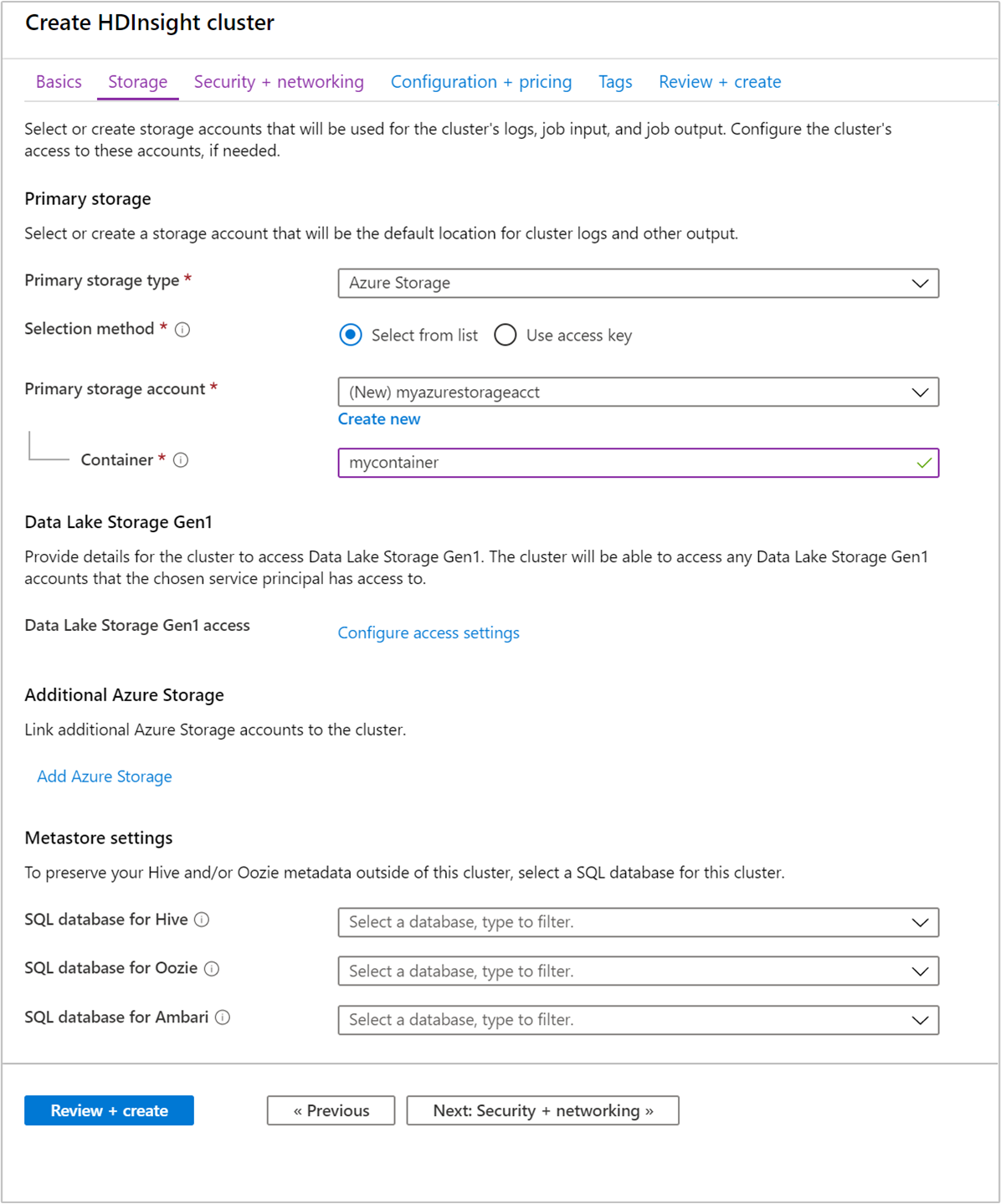
內部部署安裝的 Hadoop 叢集使用 Hadoop 分散式檔案系統 (HDFS) 作為叢集上的儲存體,但在雲端中,您可以使用已連接到叢集的儲存體端點。 使用雲端儲存空間表示您可以安全地刪除用於計算的 HDInsight 叢集,同時仍會留存您的資料。
HDInsight 叢集可以使用下列儲存體選項:
- Azure Data Lake Storage Gen2
- Azure 儲存體一般用途 v2
-
- Azure 儲存體區塊 Blob (僅支援作為次要儲存體)
如需 HDInsight 儲存體選項的詳細資訊,請參閱比較與 Azure HDInsight 叢集搭配使用的儲存體選項。
警告
不支援在與 HDInsight 叢集不同的位置中使用其他儲存體帳戶。
在設定期間,您要為預設儲存體端點指定 Azure 儲存體帳戶的 Blob 容器或 Data Lake Storage。 預設儲存體包含應用程式與系統記錄。 您也可以選擇指定叢集可存取的其他已連結 Azure 儲存體帳戶和 Data Lake Storage 帳戶。 HDInsight 叢集與相依的儲存體帳戶必須位於相同的 Azure 位置。
注意
需要安全傳輸的功能會透過安全連線,強制執行您帳戶的所有要求。 只有 HDInsight 叢集 3.6 版或更新版本支援這項功能。 如需詳細資訊,請參閱在 Azure HDInsight 中使用安全傳輸儲存體帳戶建立 Apache Hadoop 叢集。
重要
在建立叢集之後啟用安全的儲存體傳輸可能會導致使用儲存體帳戶發生錯誤,不建議這麼做。 最好是使用已啟用安全傳輸的儲存體帳戶來建立新的叢集。
注意
Azure HDInsight 不會自動將儲存在 Azure 儲存體中的資料從一個區域傳輸、移動或複製到另一個區域。
中繼存放區設定
您可以建立選擇性的 Hive 或 Apache Oozie 中繼存放區。 不過,並非所有叢集類型都支援中繼存放區,且 Azure Synapse Analytics 與中繼存放區不相容。
如需詳細資訊,請參閱在 Azure HDInsight 中使用外部中繼資料存放區。
重要
在建立自訂中繼存放區時,資料庫名稱請勿使用破折號、連字號或空格。 這可能會導致叢集建立程序失敗。
適用於 Hive 的 SQL 資料庫
如果想要在刪除 HDInsight 叢集之後保留 Hive 資料表,請使用自訂的中繼存放區。 您可以接著將中繼存放區附加至另一個 HDInsight 叢集。
針對某個 HDInsight 叢集版本建立的 HDInsight 中繼存放區,不能在不同的 HDInsight 叢集版本之間共用。 如需 HDInsight 版本清單,請參閱支援的 HDInsight 版本。
重要
預設中繼存放區會提供基本層 5 DTU 限制 (無法升級) 的 Azure SQL Database! 適用於基本測試用途。 針對大型或生產工作負載,建議您移轉至外部中繼存放區。
適用於 Oozie 的 SQL 資料庫
為提升使用 Oozie 時的效能,請使用自訂的中繼存放區。 在您刪除叢集後,中繼存放區也可提供 Oozie 作業資料的存取。
Ambari 的 SQL 資料庫
Ambari 可用來監視 HDInsight 叢集、進行設定變更,以及儲存叢集管理資訊和作業記錄。 自訂 Ambari DB 功能可讓您在您所管理的外部資料庫中部署新的叢集並設定 Ambari。 如需詳細資訊,請參閱自訂 Ambari DB。
重要
您無法重複使用自訂的 Oozie 中繼存放區。 若要使用自訂的 Oozie 中繼存放區,您必須在建立 HDInsight 叢集時提供空的 Azure SQL Database。
安全性 + 網路
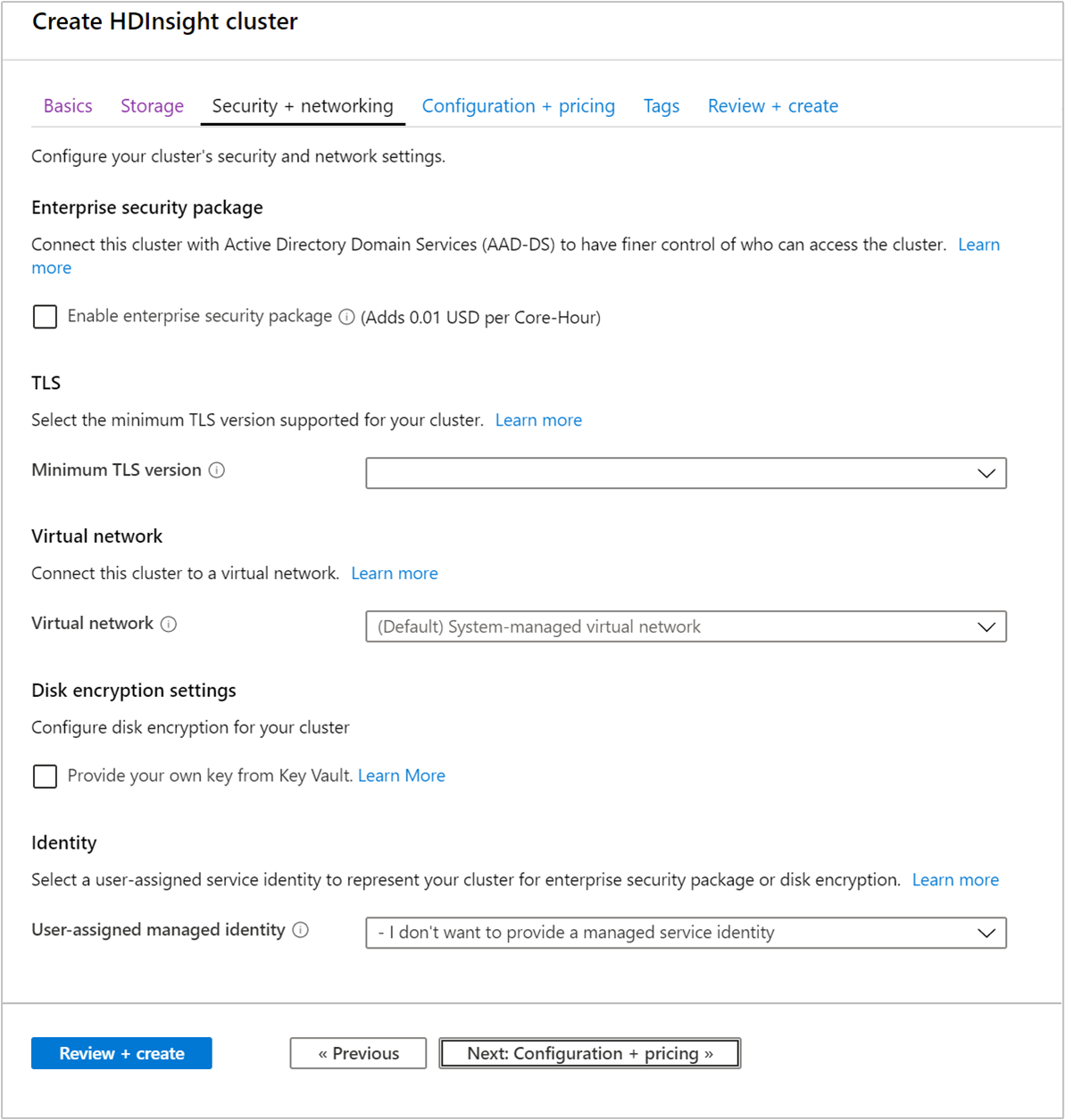
企業安全性套件
對於 Hadoop、Spark、HBase、Kafka 互動式查詢叢集類型,您可以選擇啟用 [企業安全性套件]。 此套件能透過使用 Apache Ranger 並與 Microsoft Entra ID 整合,讓您可選擇更安全的叢集設定。 如需詳細資訊,請參閱 Azure HDInsight 中企業安全性的概觀。
企業安全性套件可讓您整合 HDInsight 與 Active Directory 及 Apache Ranger。 使用企業安全性套件可以建立多個使用者。
如需建立已加入網域之 HDInsight 叢集的詳細資訊,請參閱建立已加入網域的 HDInsight 沙箱環境。
TLS
如需詳細資訊,請參閱傳輸層安全性
虛擬網路
如果您的解決方案需要會分散到多個 HDInsight 叢集類型的技術,Azure 虛擬網路可以連接必要的叢集類型。 此設定可讓叢集 (以及您對它們部署的任何程式碼) 直接彼此通訊。
如需如何搭配使用 Azure 虛擬網路與 HDInsight 的詳細資訊,請參閱規劃 HDInsight 的虛擬網路。
如需在 Azure 虛擬網路內使用兩個叢集類型的範例,請參閱使用 Apache Spark 結構化串流搭配 Apache Kafka。 如需搭配虛擬網路使用 HDInsight 的詳細資訊 (包含虛擬網路的特定組態需求),請參閱規劃 HDInsight 的虛擬網路。
磁碟加密設定
如需詳細資訊,請參閱客戶管理的金鑰磁碟加密。
Kafka REST Proxy
此設定僅適用於叢集類型 Kafka。 如需詳細資訊,請參閱使用 REST Proxy。
身分識別
如需詳細資訊,請參閱 Azure HDInsight 中的受控身分識別。
設定 + 定價
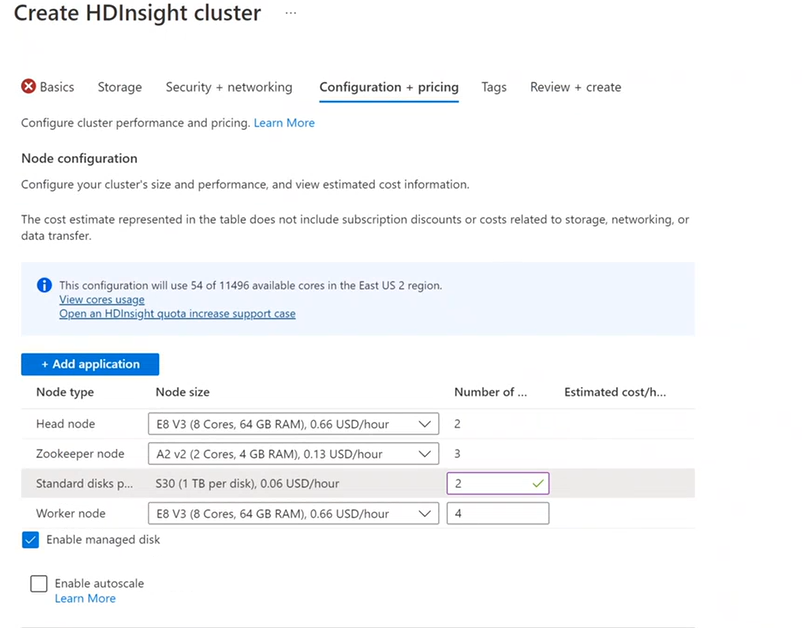
只要叢集存在,就會針對您的節點使用量收費。 建立叢集後就開始計費,並在叢集刪除後停止計費。 無法取消配置或保留叢集。
節點組態
每個叢集類型都有自己的節點數目、節點術語和預設 VM 大小。 下表中各節點類型的節點數目位於括號中。
| 類型 | 節點 | 圖表 |
|---|---|---|
| Hadoop | 前端節點 (2)、背景工作節點 (1+) | 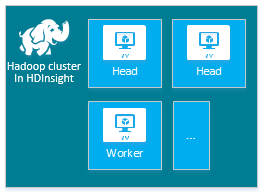
|
| hbase | 前端伺服器 (2)、區域伺服器 (1+)、主要/Zookeeper 節點 (3) | 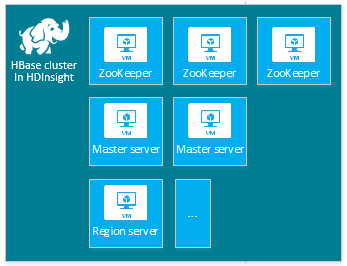
|
| Spark | 前端節點 (2)、背景工作節點 (1+)、Zookeeper 節點 (3) (A1 Zookeeper VM 大小不限) | 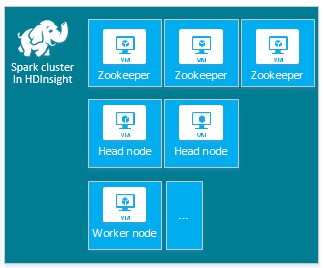
|
如需詳細資訊,請參閱<HDInsight 中的 Hadoop 元件和版本是什麼?>中的叢集的預設節點設定和虛擬機器大小。
HDInsight 叢集的成本是由節點數和節點的虛擬機器大小來決定。
不同的叢集類型具有不同的節點類型、節點數目和節點大小:
- Hadoop 叢集類型的預設值:
兩個前端節點
四個背景工作節點
如果您只是在試用 HDInsight,建議您使用一個背景工作節點。 如需關於 HDInsight 定價的詳細資訊,請參閱 HDInsight 定價。
注意
叢集大小限制會隨著 Azure 訂用帳戶而有所不同。 若要提高限制,請與 Azure 帳務支援人員連絡。
使用 Azure 入口網站設定叢集時,節點大小會透過 [設定 + 定價] 索引標籤公開。在入口網站中,您也可以查看與不同節點大小相關聯的成本。
虛擬機器大小
當您部署叢集時,請依據計劃部署的解決方案選擇計算資源。 下列 VM 可用於 HDInsight 叢集:
- A 和 D1-4 系列 VM:一般用途 Linux VM 大小
- D11-14 系列 VM:記憶體最佳化 Linux VM 大小
如需使用不同的 SDK 或使用 Azure PowerShell 建立叢集時應用來指定 VM 大小的值,請參閱使用於 HDInsight 叢集的 VM 大小。 在此連結的文件中,請使用資料表中 Size (大小) 資料行的值。
重要
如果您的叢集需要 32 個以上的背景工作節點,則必須選取具有至少 8 個核心和 14 GB RAM 的前端節點大小。
如需相關資訊,請參閱虛擬機器的大小。 如需各式大小的價格資訊,請參閱 HDInsight 價格。
磁碟附件
注意
新增的磁碟只會針對節點管理員本機目錄進行設定,而不會針對 datanode 目錄進行設定
HDInsight 叢集隨附以 SKU 為基礎的預先定義磁碟空間。 如果您執行某些大型應用程式,可能會導致磁碟空間不足 (發生磁碟完整錯誤 - LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE) 和作業失敗。
您可以使用 NodeManager的本機目錄新功能,將更多磁碟新增至叢集。 在 Hive 和 Spark 叢集建立時,可以選取磁碟數目並新增至背景工作角色節點。 選取的磁碟大小各為 1TB,會是 NodeManager 本機目錄的一部分。
- 選取 [設定 + 定價] 索引標籤。
- 選取 [啟用受控磁碟] 選項
- 從 [標準磁碟],輸入 [磁碟數目]
- 選擇您的 [背景工作角色節點]
您可以從 [檢閱 + 建立] 索引標籤的 [叢集設定] 底下確認磁碟數目
新增應用程式
HDInsight 應用程式是使用者可以在以 Linux 為基礎的 HDInsight 叢集上安裝的應用程式。 您可以使用由 Microsoft、協力廠商所提供或或您開發的應用程式。 如需詳細資訊,請參閱在 Azure HDInsight 上安裝第三方 Apache Hadoop 應用程式。
大部分的 HDInsight 應用程式會安裝在空白的邊緣節點。 空白的邊緣節點是一部 Linux 虛擬機器,其中已安裝及設定和前端節點相同的用戶端工具。 您可以使用邊緣節點存取叢集,測試並託管您的用戶端應用程式。 如需詳細資訊,請參閱 Use empty edge nodes in HDInsight (在 HDInsight 中使用空白的邊緣節點)。
指令碼動作
您可以在建立期間使用指令碼來安裝其他元件或自訂組態。 這類指令碼可透過 指令碼動作叫用,指令碼動作是一個組態選項,其可從 Azure 入口網站、HDInsight Windows PowerShell Cmdlet 或 HDInsight .NET SDK 使用。 如需詳細資訊,請參閱 使用指令碼動作自訂 HDInsight 叢集。
您可以使用 JAVA 封存 (JAR) 檔案形式在叢集上執行一些原生 JAVA 元件 (例如 Apache Mahout 和 Cascading)。 這些 JAR 檔案可以配送至 Azure 儲存體,並透過 Hadoop 作業提交機制提交至 HDInsight 叢集。 如需詳細資訊,請參閱以程式設計方式提交 Apache Hadoop 作業。
注意
如果您在將 JAR 檔案部署至 HDInsight 叢集,或在 HDInsight 叢集上呼叫 JAR 檔案時發生問題,請連絡 Microsoft 支援。
Cascading 不受 HDInsight 支援,而且不符合「Microsoft 支援」的資格。 如需所支援元件的清單,請參閱 HDInsight 所提供叢集版本的新功能。
有時候,您可能要在建立程序期間設定下列組態檔:
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
如需詳細資訊,請參閱 使用 Bootstrap 自訂 HDInsight 叢集。