Apache Kafka 是一個開放原始碼的分散式串流平台。 它通常會用來作為訊息代理程式,因為可以提供類似「發佈-訂閱」訊息佇列的功能。
在本快速入門中,您會了解如何使用 Azure 入口網站來建立 Apache Kafka 叢集。 您也會了解如何使用內含的公用程式,使用 Apache Kafka 來傳送和接收訊息。 如需可用設定的深入說明,請參閱在 HDInsight 中設定叢集。 如需如何使用入口網站來建立叢集的其他資訊,請參閱在入口網站中建立叢集。
警告
不論使用與否,HDInsight 叢集都是按分鐘計費。 請務必在使用完叢集後將它刪除。 請參閱如何刪除 HDInsight 叢集。
Apache Kafka API 只能由同一個虛擬網路中的資源來存取。 在本快速入門中,您會使用 SSH 直接存取叢集。 若要將其他服務、網路或虛擬機器連線到 Apache Kafka,您必須先建立虛擬網路,然後建立網路中的資源。 如需詳細資訊,請參閱使用虛擬網路連線到 Apache Kafka 文件。 如需如何為 HDInsight 規劃虛擬網路的一般資訊,請參閱為 Azure HDInsight 規劃虛擬網路。
如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。
必要條件
SSH 用戶端。 如需詳細資訊,請參閱使用 SSH 連線至 HDInsight (Apache Hadoop)。
建立 Apache Kafka 叢集
若要在 HDInsight 上建立 Apache Kafka 叢集,請使用下列步驟:
登入 Azure 入口網站。
從頂部功能表選取 [+建立資源]。
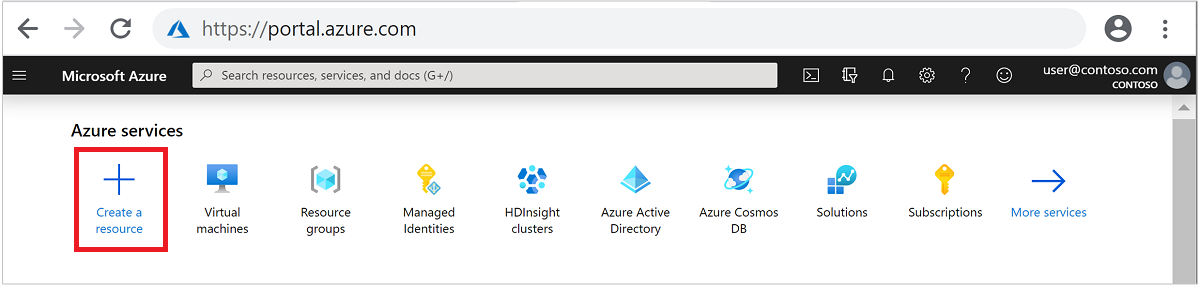
選取 [分析]>[Azure HDInsight] 以移至 [建立 HDInsight 叢集] 頁面。
在 [基本資料] 索引標籤中提供下列資訊:
屬性 描述 訂用帳戶 從下拉式清單中,選取用於此叢集的 Azure 訂用帳戶。 資源群組 建立資源群組,或選取現有的資源群組。 資源群組是 Azure 元件的容器。 在此案例中,資源群組包含 HDInsight 叢集和相依的 Azure 儲存體帳戶。 叢集名稱 輸入全域唯一名稱。 名稱最多可包含 59 個字元,而這些字元可以是字母、數字和連字號。 名稱的第一個和最後一個字元不可以是連字號。 區域 從下拉式清單中,選取要在其中建立叢集的區域。 選擇靠近您的區域,以獲得最佳效能。 叢集類型 選取 [選取叢集類型] 以開啟清單。 從清單中,選取 [Kafka] 作為叢集類型。 版本 將會指定叢集類型的預設版本。 如果您想要指定不同的版本,請從下拉式清單中選取。 叢集登入使用者名稱和密碼 預設登入名稱為 admin。 密碼長度至少必須為 10 個字元,且至少必須包含一個數字、一個大寫字母、一個小寫字母及一個非英數字元 (字元' ` "除外)。 確定您不會提供常見密碼,例如Pass@word1。安全殼層 (SSH) 使用者名稱 預設的使用者名稱為 sshuser。 您可以為 SSH 使用者名稱提供另一個名稱。使用 SSH 的叢集登入密碼 選取此核取方塊,讓 SSH 使用者所使用的密碼等同於您提供給叢集登入使用者的密碼。 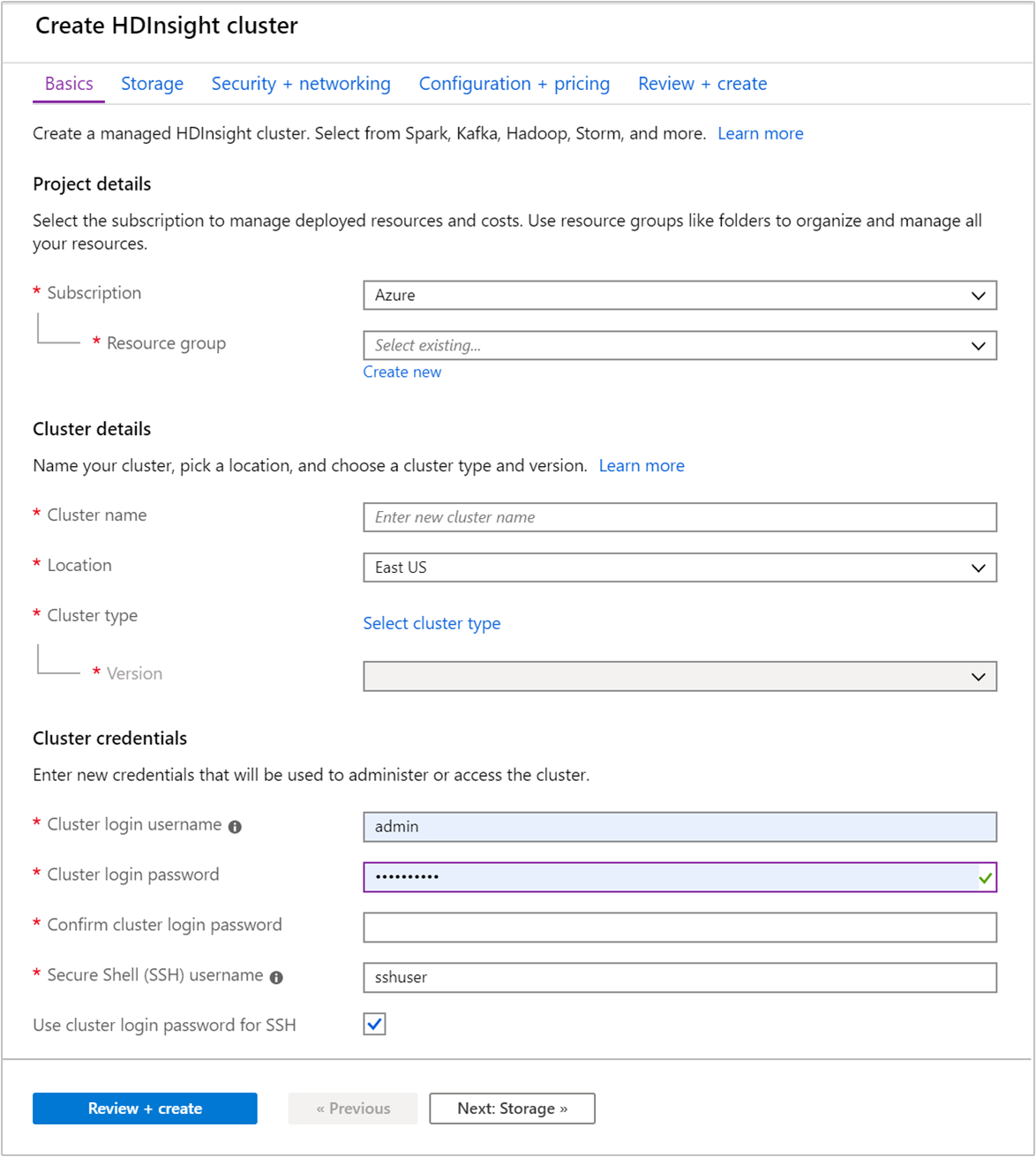
每個 Azure 區域 (位置) 提供容錯網域。 容錯網域是 Azure 資料中心內基礎硬體的邏輯群組。 每個容錯網域會共用通用電源和網路交換器。 實作 HDInsight 叢集內節點的虛擬機器和受控磁碟會分散於這些容錯網域。 此架構會限制實體硬體故障的潛在影響。
若要獲得高度資料可用性,請選取包含「三個容錯網域」的區域 (位置)。 如需區域中的容錯網域數目的資訊,請參閱 Linux 虛擬機器的可用性文件。
選取 [下一步: 儲存體 >>] 索引標籤,以前進到儲存體設定。
在 [儲存體] 索引標籤中,提供下列值:
屬性 描述 主要儲存體類型 使用預設值 [Azure 儲存體]。 選取方法 使用預設值 [從清單中選取]。 主要儲存體帳戶 使用下拉式清單來選取現有的儲存體帳戶,或選取 [新建]。 如果您建立新的帳戶,其名稱的長度必須介於 3 到 24 個字元之間,且只能包含數字和小寫字母。 容器 使用自動填入的值。 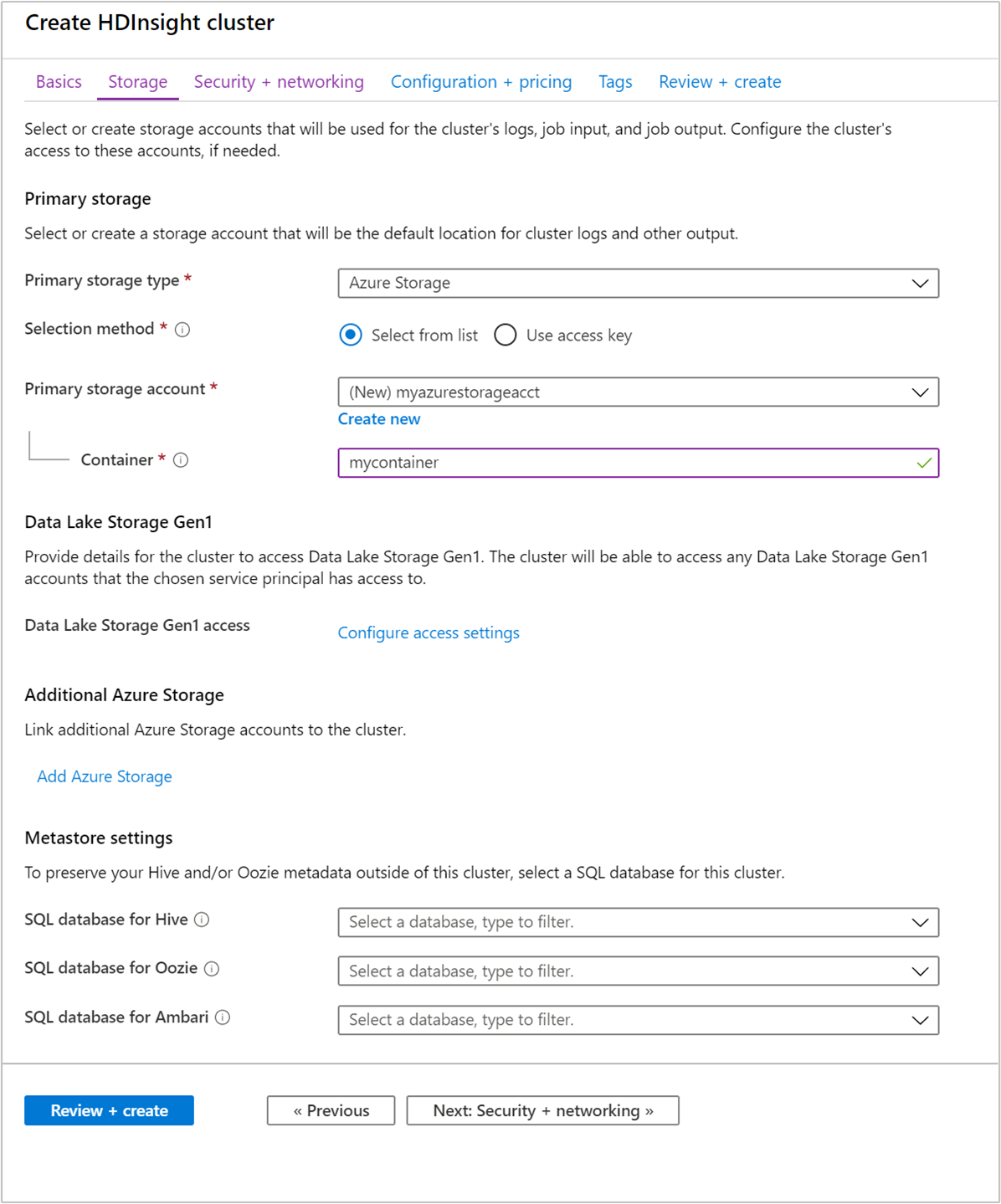
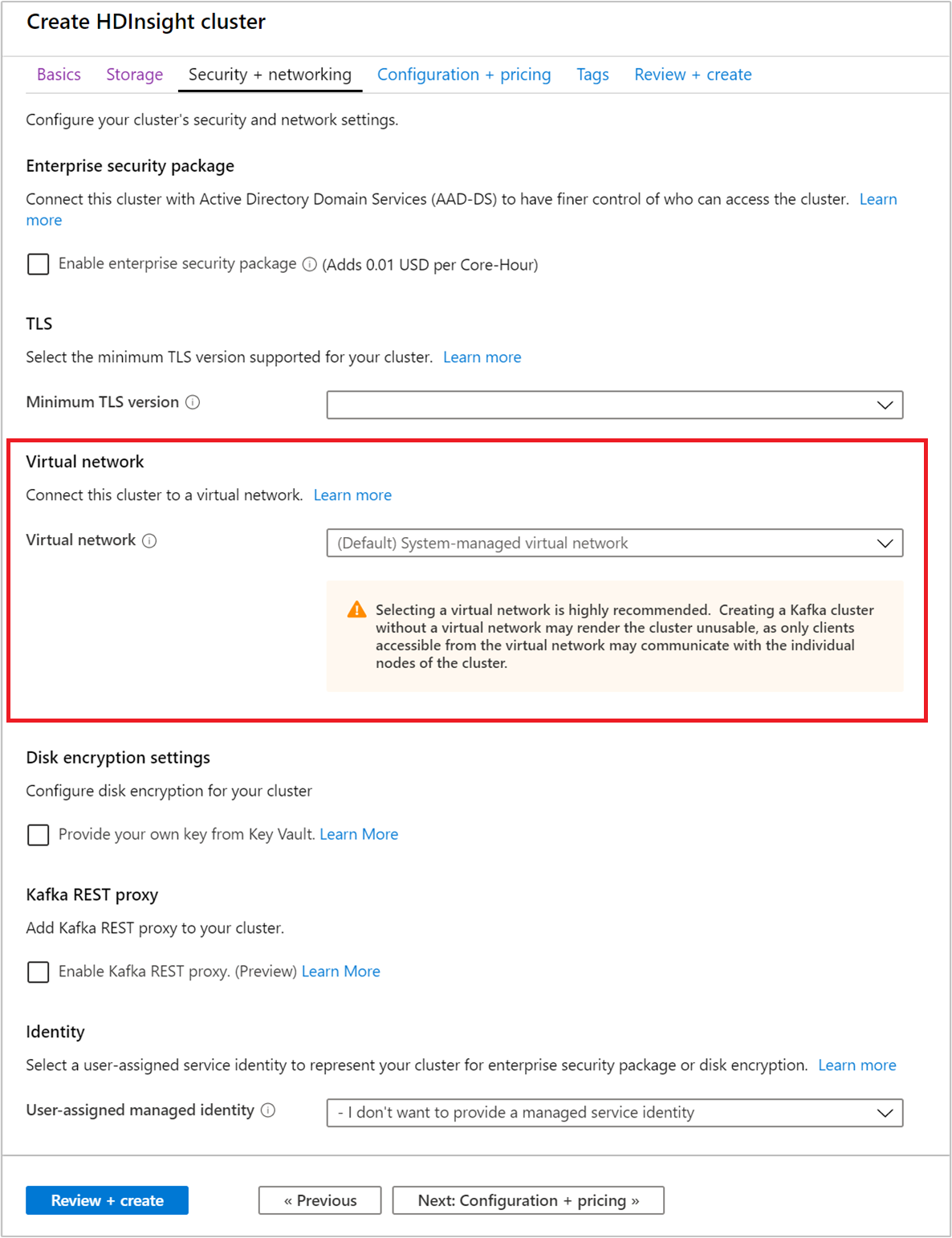
選取 [安全性 + 網路] 索引標籤。
針對本快速入門,請保留預設的安全性設定。 若要深入了解企業安全性套件,請造訪使用 Microsoft Entra Domain Service 設定具有企業安全性套件的 HDInsight 叢集。 若要了解如何使用您自己的金鑰進行 Apache Kafka 磁碟加密,請造訪客戶管理的金鑰磁碟加密
如果您想要將叢集連線到虛擬網路,請從 [虛擬網路] 下拉式清單中選取虛擬網路。
選取 [組態 + 定價] 索引標籤。
若要保證 HDInsight 上的 Apache Kafka 可用性,則必須將 [背景工作節點] 的 [節點數目] 項目設為 3 或更高。 預設值為 4。
[每個背景工作節點的標準磁碟數] 項目會設定 HDInsight 上 Apache Kafka 的延展性。 HDInsight 上的 Apache Kafka 會在叢集中使用虛擬機器的本機磁碟來儲存資料。 Apache Kafka 的 I/O 非常大量,因此會使用 Azure 受控磁碟來提供高輸送量,並為每個節點提供更多儲存空間。 受控磁碟的類型可以是標準 (HDD) 或進階 (SSD)。 磁碟類型取決於背景工作節點 (Apache Kafka 代理程式) 所使用的 VM 大小。 進階磁碟會自動與 DS 和 GS 系列的 VM 搭配使用。 所有其他的 VM 類型是使用標準磁碟。
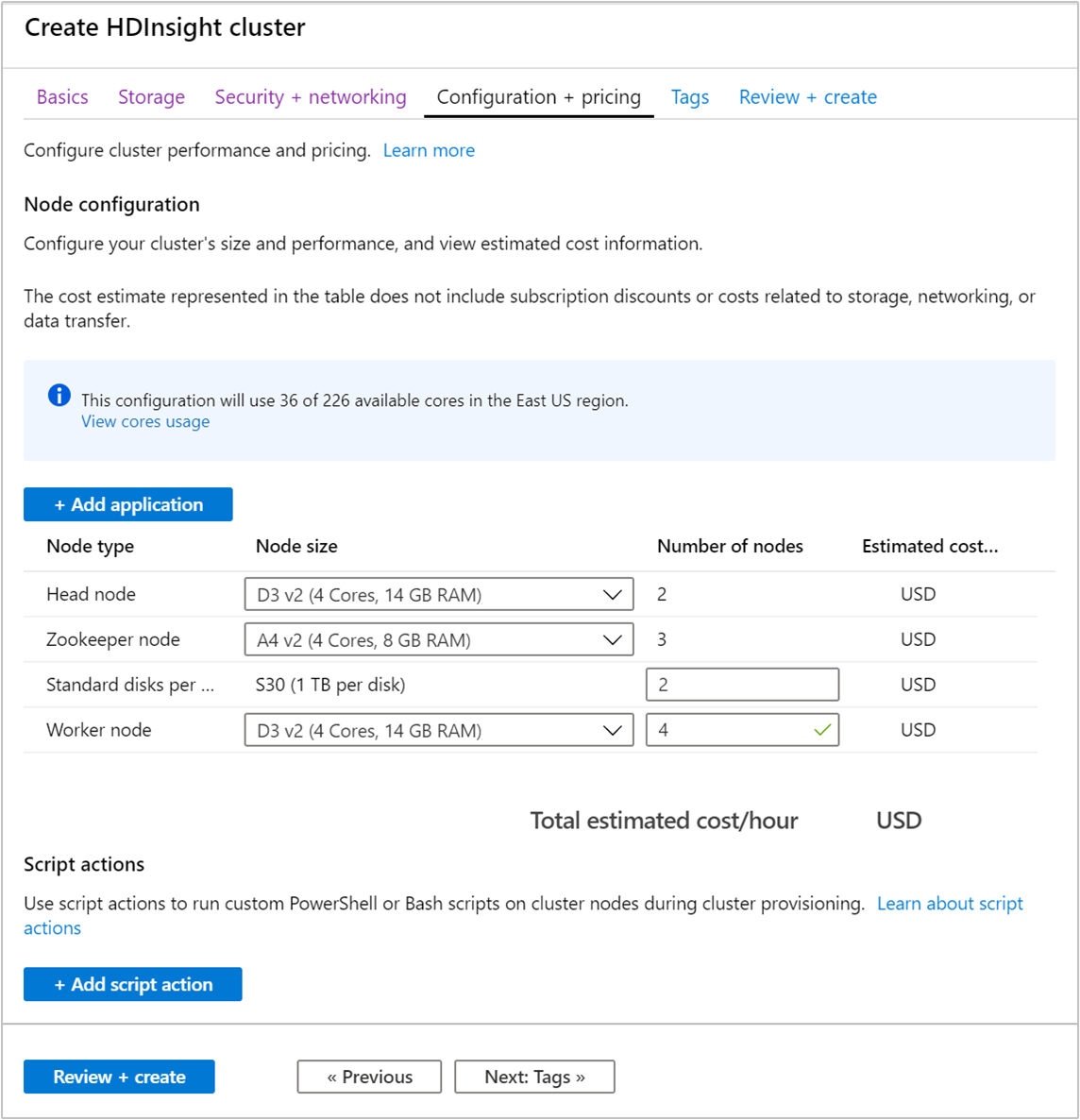
選取 [檢閱 + 建立] 索引標籤。
檢閱叢集的組態。 變更任何不正確的設定。 最後,選取 [建立] 以建立叢集。
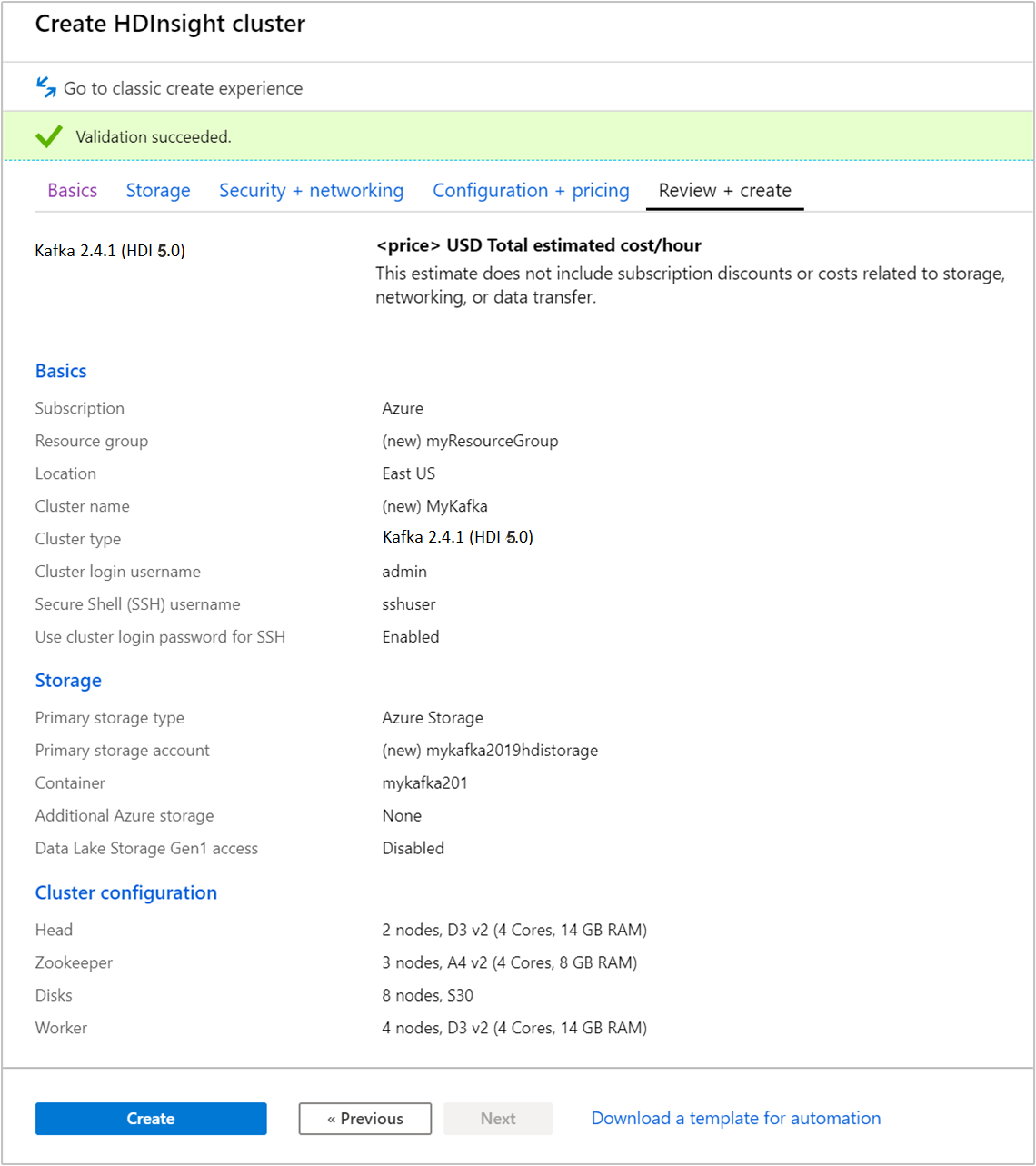
建立叢集可能需要花費 20 分鐘的時間。
連線至叢集
使用 ssh 命令來連線到您的叢集。 編輯以下命令並將 CLUSTERNAME 取代為您叢集的名稱,然後輸入命令:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net出現提示時,請輸入 SSH 使用者的密碼。
連線之後,您會看到類似下列文字的資訊:
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
取得 Apache Zookeeper 和訊息代理程式主機資訊
使用 Kafka 時,您必須知道 Apache Zookeeper 主機和「訊息代理程式」主機。 這些主機可搭配 Apache Kafka API 以及 Kafka 隨附的許多公用程式使用。
在本節中,您會從叢集上的 Apache Ambari REST API 取得主機資訊。
安裝 jq,這是命令列 JSON 處理器。 此公用程式可用來剖析 JSON 文件,而且在剖析主機資訊時很有用。 從開啟的 SSH 連線,輸入下列命令來安裝
jq:sudo apt -y install jq設定密碼變數。 請將
PASSWORD取代為叢集登入密碼,然後輸入下列命令:export PASSWORD='PASSWORD'擷取正確大小寫的叢集名稱。 視叢集的建立方式而定,叢集名稱的實際大小寫可能與您預期的不同。 此命令會取得實際的大小寫,然後將其儲存在變數中。 輸入下列命令:
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')注意
如果您是從叢集外部執行此程序,則應以不同的程序儲存叢集名稱。 請從 Azure 入口網站取得小寫的叢集名稱。 然後,在下列命令中,以叢集名稱取代
<clustername>,並執行命令:export clusterName='<clustername>'。若要使用 Zookeeper 主機資訊設定環境變數,請使用以下命令。 此命令會擷取所有的 Zookeeper 主機,然後只傳回前兩個項目。 這是因為考量備援之故,以防某一部主機無法連線。
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);注意
此命令需要 Ambari 存取權。 如果您的叢集位於 NSG 後方,請從可存取 Ambari 的機器執行此命令。
若要確認是否已正確設定環境變數,請使用下列命令:
echo $KAFKAZKHOSTS此命令會傳回類似以下文字的資訊:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181若要使用 Apache Kafka 訊息代理程式主機資訊來設定環境變數,請使用下列命令:
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);注意
此命令需要 Ambari 存取權。 如果您的叢集位於 NSG 後方,請從可存取 Ambari 的機器執行此命令。
若要確認是否已正確設定環境變數,請使用下列命令:
echo $KAFKABROKERS此命令會傳回類似以下文字的資訊:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
管理 Apache Kafka 主題
Kafka 會將資料串流儲存於「主題」中。 您可以使用 kafka-topics.sh 公用程式來管理主題。
若要建立主題,請在 SSH 連線中使用下列命令:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --bootstrap-server $KAFKABROKERS此命令會使用
$KAFKABROKERS中儲存的主機資訊連線到 Broker。 然後建立名為 test 的 Apache Kafka 主題。此主題中所儲存的資料會分割到八個分割區。
每個分割區都會在叢集中的三個背景工作節點之間進行複寫。
如果您已在 Azure 區域中建立叢集來提供三個容錯網域,請使用複寫因子 3。 否則,使用複寫因子 4。
在具有三個容錯網域的區域中,複寫因子 3 可讓複本散佈於容錯網域中。 在具有兩個容錯網域的區域中,複寫因子 4 會在網域中平均散佈複本。
如需區域中的容錯網域數目的資訊,請參閱 Linux 虛擬機器的可用性文件。
Apache Kafka 不知道 Azure 容錯網域。 為主題建立副本時,可能無法正確發散副本以實現高可用性。
若要確保高可用性,請使用 Apache Kafka 分割重新平衡工具。 您必須從連往 Apache Kafka 叢集前端節點的 SSH 連線來執行此工具。
為了讓 Apache Kafka 資料具有最高可用性,您應該在下列情況中重新平衡主題的分割區複本:
建立新主題或磁碟分割時
擴大叢集時
若要列出主題,請使用下列命令:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --bootstrap-server $KAFKABROKERS此命令會列出可在 Apache Kafka 叢集上使用的主題。
若要刪除主題,請使用下列命令:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --bootstrap-server $KAFKABROKERS此命令會刪除名為
topicname的主題。警告
如果您刪除先前建立的
test主題,則必須加以重新建立。 本文件稍後的步驟會用到此主題。
如需 kafka-topics.sh 公用程式可用命令的詳細資訊,請使用下列命令:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
產生和取用記錄
Kafka 會在主題中儲存「記錄」。 記錄是由「產生者」產生,並由「取用者」取用。 產生者與取用者會與「Kafka 訊息代理程式」服務進行通訊。 HDInsight 叢集中的每個背景工作節點都是一部 Apache Kafka 訊息代理程式主機。
若要將記錄儲存至您稍早建立的 test 主題,然後利用取用者進行讀取,請使用下列步驟:
若要將記錄寫入主題,請從 SSH 連線使用
kafka-console-producer.sh公用程式:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic test在此命令之後,您會抵達空白行。
在空白行中輸入文字訊息並按一下 enter 鍵。 如此輸入幾個訊息,然後使用 Ctrl + C 返回一般提示。 每一行都會以個別記錄傳送至 Apache Kafka 主題。
若要從主題讀取記錄,請從 SSH 連線使用
kafka-console-consumer.sh公用程式:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginning此命令會擷取主題中的記錄並加以顯示。 使用
--from-beginning告知取用者從串流的開頭開始,所以會擷取所有的記錄。如果您使用舊版 Kafka,請以
--bootstrap-server $KAFKABROKERS取代--zookeeper $KAFKAZKHOSTS。使用 Ctrl + C 來停止取用者。
您也可以利用程式設計方式建立產生者和取用者。 如需使用此 API 的範例,請參閱使用 Apache Kafka Producer 和 Consumer API 搭配 HDInsight 文件。
清除資源
若要清除本快速入門所建立的資源,您可以刪除資源群組。 刪除資源群組也會刪除相關聯的 HDInsight 叢集,以及與資源群組相關聯的任何其他資源。
若要使用 Azure 入口網站移除資源群組:
- 在 Azure 入口網站中展開左側功能表,以開啟服務的功能表,然後選擇 [資源群組] 以顯示資源群組的清單。
- 找出要刪除的資源群組,然後以滑鼠右鍵按一下清單右側的 [更多] 按鈕 (...)。
- 選取 [刪除資源群組],並加以確認。
警告
刪除 HDInsight 上的 Apache Kafka 叢集,也會刪除 Kafka 中儲存的任何資料。