以篩選為基礎的特徵選取
本文說明如何在 Azure Machine Learning 設計工具中,使用以篩選為基礎的特徵選取元件。 此元件可協助您識別輸入資料集中具有最佳預測能力的資料行。
一般而言,特徵選取是指在指定的輸出中,將統計測試套用至輸入的流程。 其目標在於判斷輸出中的哪些資料行較具有預測性。 以篩選為基礎的特徵選取元件提供多種特徵選取演算法可供選擇。 此元件包含相互關聯方法,例如皮耳森積差相關分析和卡方值。
在使用「以篩選為基礎的特徵選取」元件時,您會提供資料集,並識別包含標籤或相依變數的資料行。 接下來,指定要用來測量特徵重要度的單一方法。
元件會輸出包含最佳特徵資料行的資料集,並依預測能力排序。 此外也會從選取的計量中,輸出特徵的名稱及其分數。
什麼是以篩選為基礎的特徵選取
此特徵選取元件稱為「以篩選為基礎」,因為會使用所選的計量來找出不相關的屬性。 然後您變可以從模型中篩選掉多餘的資料行。 您可以選擇適合資料的單一統計衡量標準,而該元件會計算每個特徵資料行的分數。 傳回的資料行會依其特性分數排序。
選擇正確的特徵就有可能改善分類的精確度和效率。
您通常只會使用具有最佳分數的資料行來建置預測模型。 特徵選取分數不佳的資料行會留在資料集中,且在您建立模型時,會忽略該資料行。
如何選擇特徵選取計量
以篩選為基礎的特徵選取元件提供各種計量,來評估每個資料行中的資訊值。 本節提供每項計量的一般說明,以及其套用方式。 您可以在技術提示和設定每個元件的指示當中,找到關於使用每個計量的其他需求資訊。
皮耳森積差相關分析
皮耳森積差相關分析統計或皮耳森相關係數在統計模型中也稱為
r值。 對於任何兩個變數,它會傳一個指出相關強度的值。皮耳森相關係數的計算公式是先取兩個變數的共變異數,再除以其標準差的乘積。 兩個變數的尺度變更不會影響此係數。
卡方值
雙向卡方測試是一種統計方法,它能測量期望值與實際結果之間的差距。 該方法假設變數是隨機的,並且是從適當的獨立變數範例中抽出。 產生的卡方統計量能指出結果與預期 (隨機) 結果之間的差距。
提示
若您需要不同的自訂特徵選取方法選項,請使用執行 R 指令碼元件。
如何設定以篩選為基礎的特徵選取
您可以選擇標準統計計量。 元件會計算一對資料行之間的相互關聯:標籤資料行和特徵資料行。
將「以篩選為基礎的特徵選取」元件新增至您的管線。 您可以在設計工具的 [特徵選取] 類別中找到它。
與輸入資料集連線,資料集中須至少包含兩個可能特徵的資料行。
針對 [特徵評分方法] 選擇下列其中一個已建立的統計方法,以用於計算分數。
方法 規格需求 皮耳森積差相關分析 標籤可以是文字或數值。 特徵則必須是數值。 卡方值 標籤和特徵可以是文字或數值。 使用此方法來計算兩個類別資料行的特徵重要度。 提示
若您變更選取的計量,則會重設其他所有選取項目。 因此,請務必先設定此選項。
選取 [僅操作特徵資料行] 選項,只針對先前標示為特徵的資料行產生分數。
若您清除此選項,元件將會為任何其他符合準則的資料行建立分數,最多可達 [所需特徵數] 中指定的資料行數目。
針對 [目標資料行] 選取 [啟動資料行選取器],依其名稱或索引來選擇標籤資料行。 (索引是以一為基礎。)
牽涉到統計相互關聯的所有方法都需要標籤資料行。 若您選擇無標籤資料行或多個標籤資料行,元件會傳回設計階段錯誤。針對 [所需的特徵數],輸入您想要傳回結果的特徵資料行數目:
您可以指定的最小特徵數目為 1,但建議您增加此值。
如果指定的所需特徵數目大於資料集的資料行數目,則會傳回所有特徵。 甚至會傳回分數為零的特徵。
若您指定的結果資料行數目少於特徵資料行,則會依分數遞減的方式來排序這些特徵。 系統僅會傳回最高分的特徵。
提交管線。
重要
若您要在推斷中使用 [以篩選為基礎的特徵選取],則必須使用 [選取資料行轉換] 來儲存已選取特徵的結果,並選取 [套用轉換] 將已選取特徵的轉換套用至評分資料集。
請參閱下列螢幕擷取畫面來建置您的管線,以確保評分流程的資料行選取項目皆相同。
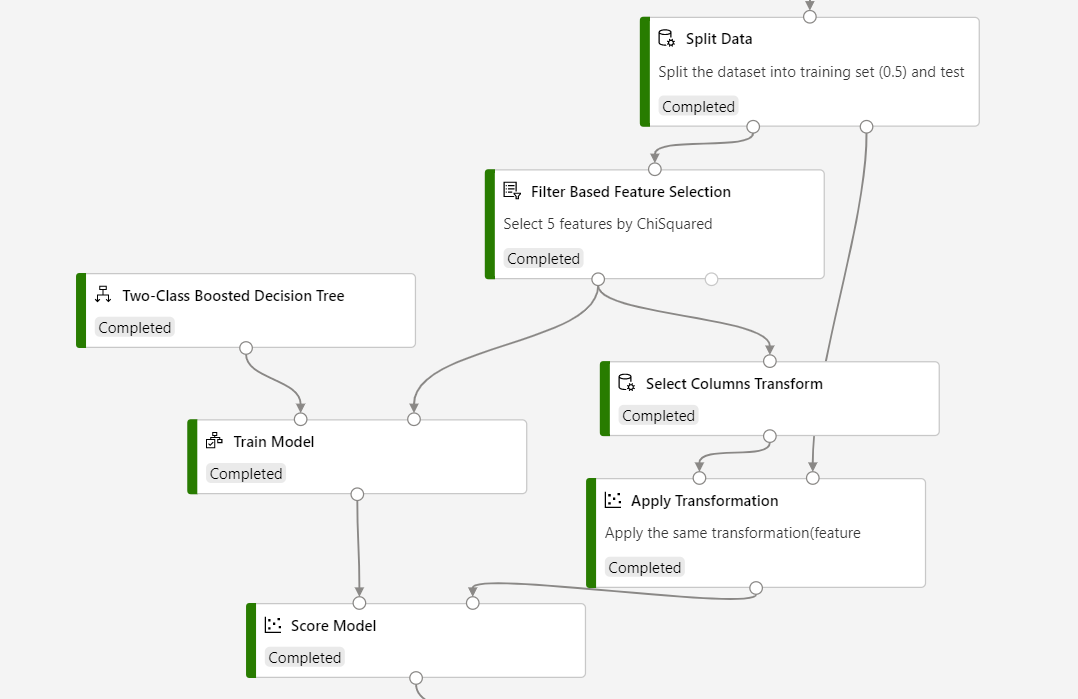
結果
完成處理之後:
如要查看已分析特徵資料行及其分數的完整清單,請以滑鼠右鍵按一下元件,然後選取 [視覺化]。
如要根據您的特徵選取準則來查看資料集,請以滑鼠右鍵按一下元件,然後選取 [視覺化]。
若資料集包含的資料行數目少於預期,請檢查元件設定。 亦請針對提供做為輸入的資料行,檢查其資料類型。 例如,若您將 [所需的特徵數] 設定為 1,則輸出資料集只會包含兩個資料行:標籤資料行,以及最高順位的特徵資料行。
技術說明
實作詳細資料
若您在數值特徵和類別標籤上使用皮耳森積差相關分析,則會以下列方式計算特徵分數:
針對類別資料行中的每個層級,計算數值資料行的條件平均值。
將條件平均值的資料行與數值資料行相互關聯。
規格需求
系統無法針對任何已指定為 [標籤] 或 [分數] 資料行的資料行來產生特徵選取分數。
若您嘗試將評分方法與該方法不支援的資料類型資料行搭配使用,元件將會引發錯誤。 或系統會指派該資料行為零分。
若資料行包含邏輯 (true/false) 值,則會以
True = 1和False = 0來處理。若您已將資料行指定為 [標籤] 或 [分數],該資料行便無法成為特徵。
如何處理遺漏值
您無法將具有完全遺漏值的任何資料行,指定為目標 (標籤) 資料行。
若資料行包含遺漏值,則元件會在計算資料行的分數時忽略這些值。
若指定為特徵資料行的資料行具有完全遺漏值,則元件會指派零分。
後續步驟
請參閱 Azure Machine Learning 可用的元件集。