定型 PyTorch 模型
本文描述如何使用 Azure Machine Learning 設計工具中的定型 PyTorch 模型元件來定型 PyTorch 模型,例如 DenseNet。 定型是在您定義模型並設定其參數之後進行,需要已標記的資料。
目前,定型 PyTorch 模型元件支援單一節點和分散式定型。
如何使用定型 PyTorch 模型
將定型 PyTorch 模型元件新增至管線。 您可以在 [模型定型] 類別下找到此元件。 展開 [定型],然後將 [定型 PyTorch 模型] 元件拖曳至管線。
注意
定型 PyTorch 模型元件最好在大型資料集的 GPU 類型計算上執行,否則管線會失敗。 您可以在元件的右窗格中設定 [使用其他計算目標],以選取特定元件的計算。
在左側輸入中,附加未定型的模型。 將定型資料集和驗證資料集附加至定型 PyTorch 模型的中間和右側輸入。
若為未定型的模型,則必須是 PyTorch 模型,例如 DenseNet,否則會擲回 'InvalidModelDirectoryError'。
若為資料集,定型資料集必須是已標記的映像目錄。 請參閱轉換為映像目錄,以了解如何取得已標記的映像目錄。 如果未標記,則會擲回 'NotLabeledDatasetError'。
定型資料集和驗證資料集有相同的標籤分類,否則會擲回 InvalidDatasetError。
在 [時期] 中,指定您想要定型多少個時期。 每個時期中會逐一查看整個資料集,預設為 5。
在 [批次大小] 中,指定一個批次中要定型多少個執行個體,預設為 16。
在 [熱身步驟編號] 中,指定您要讓定型熱身多少個時期,以防初始學習速率稍微太大而無法開始收斂,預設為 0。
在 [學習速率] 中,指定「學習速率」的值,預設值為 0.001。 學習速率控制每次測試和更正模型時,最佳化工具 (例如 sgd) 中使用的步驟大小。
速率設定越小,越經常測試模型,風險是可能陷入局部高原。 速率設定越大,越快收斂,風險是越過真正最小值。
注意
如果定型損失在定型期間變成 nan (可能因為學習速率太高),降低學習速率可能有幫助。 在分散式定型中,為了保持梯度下降穩定,以
lr * torch.distributed.get_world_size()計算實際學習速率,因為流程群組的批次大小是單一流程的 world size 倍。 已套用多項式學習速率衰減,有助於產生效能較佳的模型。在 [隨機種子] 中,選擇性輸入整數值做為種子。 如果您想要確保實驗跨作業的重現性,建議使用種子。
在 [容忍] 中,指定如果驗證損失未連續減少,則要提前多少個時期停止定型。 預設為 3。
在 [列印頻率] 中,指定每個時期在反覆運算上的定型記錄列印頻率,預設為 10。
提交管線。 如果資料集較大,則需要一些時間,建議使用 GPU 計算。
分散式定型
在分散式定型中,定型模型的工作負載分散到多個迷你處理器分攤,稱為背景工作節點。 這些背景工作節點平行運作以加速模型定型。 目前,設計工具支援定型 PyTorch 模型元件的分散式定型。
定型時間
分散式定型可讓定型 PyTorch 模型只要幾小時就能定型大型資料集,例如 ImageNet (1000 個類別,120 萬個影像)。 下表顯示根據不同的裝置,在 ImageNet 上從頭開始定型 Resnet50 的 50 個時期的定型時間和效能。
| 裝置 | 定型時間 | 定型輸送量 | 第 1 名驗證精確度 | 前 5 名驗證精確度 |
|---|---|---|---|---|
| 16 個 V100 GPU | 6h22min | ~3200 影像/秒 | 68.83% | 88.84% |
| 8 個 V100 GPU | 12h21min | ~1670 影像/秒 | 68.84% | 88.74% |
按一下此元件的 [計量] 索引標籤,然後查看定型計量圖表,例如「每秒定型影像數」和「第 1 名精確度」。

如何啟用分散式定型
若要啟用定型 PyTorch 模型元件的分散式定型,您可以在元件右窗格的 [作業設定] 中設定。 分散式定型僅支援 AML 計算叢集。
注意
需要多個 GPU才能啟動分散式定型,因為 NCCL 後端定型 PyTorch 模型元件使用需要 cuda。
選取元件,然後開啟右面板。 展開 [作業設定] 區段。
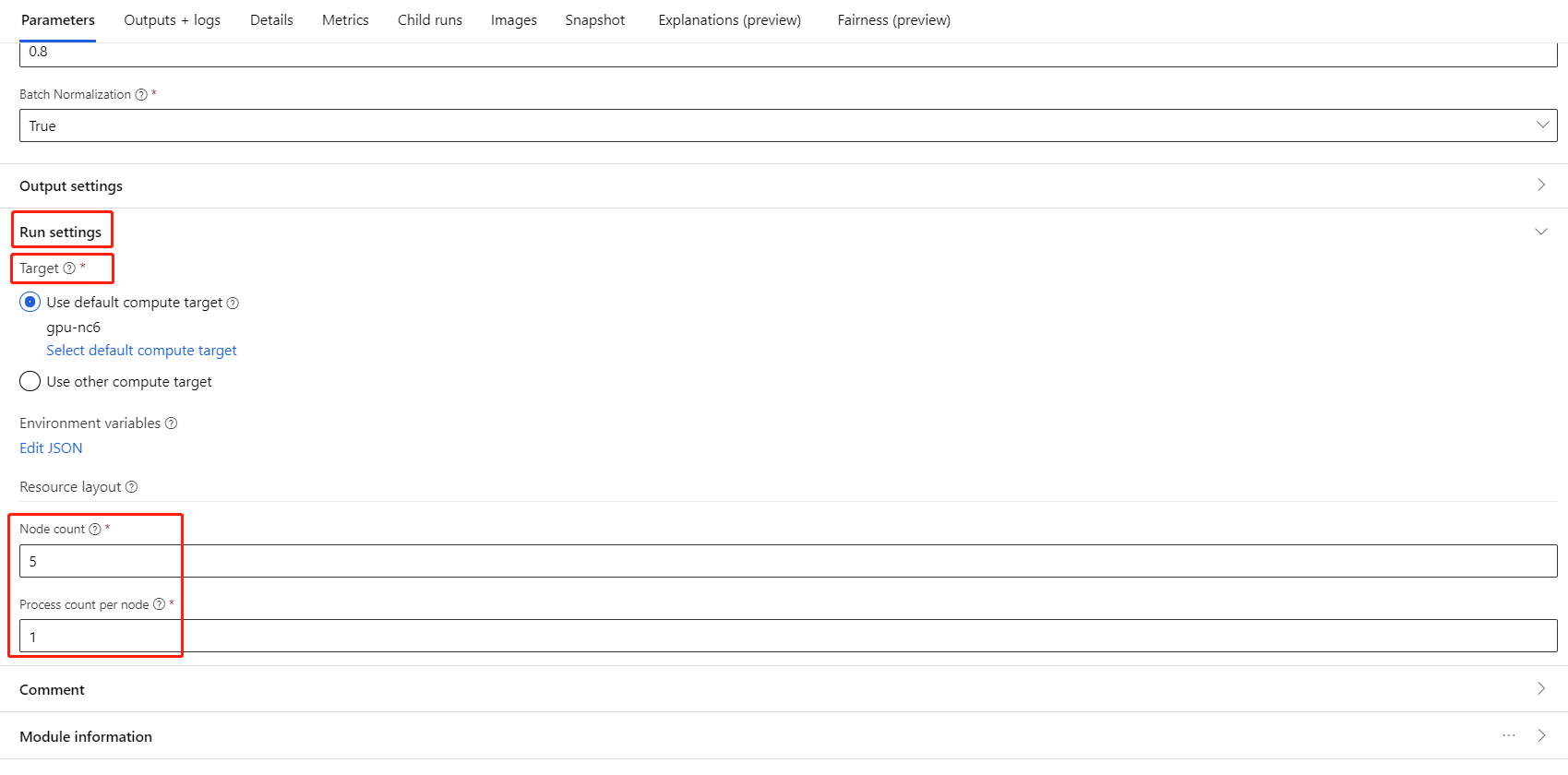
請確定您已選取計算目標的 AML 計算。
在 [資源配置] 區段中,您需要設定下列值:
節點計數:計算目標中用於定型的節點數目。 應該小於或等於計算叢集的節點數目上限。 預設為 1,表示單一節點作業。
每個節點的流程計數:每個節點觸發的流程數目。 應該小於或等於計算的處理單位。 預設為 1,表示單一流程作業。
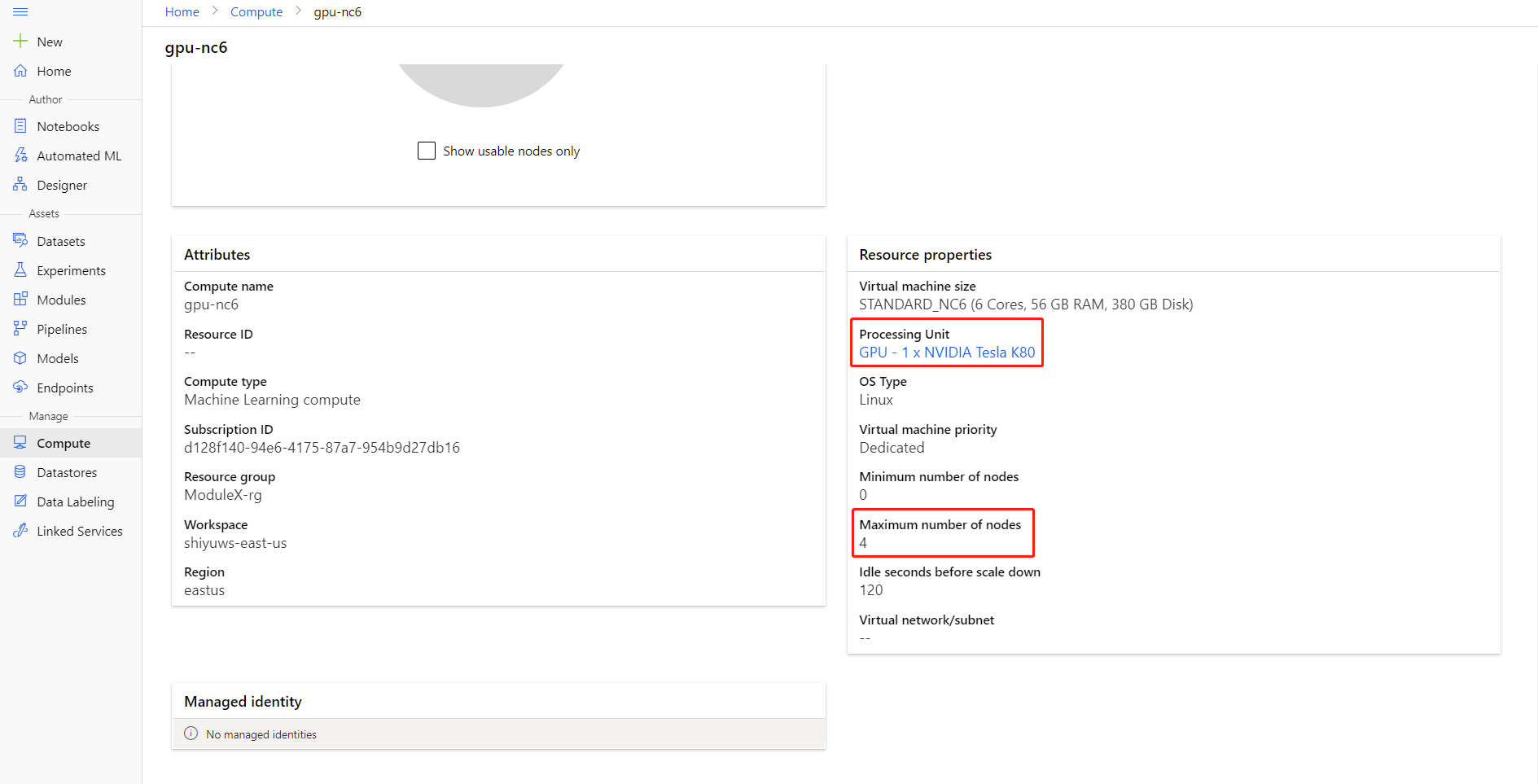
您可以按一下計算名稱進入計算詳細資料頁面,以檢查計算的節點數目上限和處理單位。


您可以在這裡深入了解 Azure Machine Learning 中的分散式定型。
分散式定型的疑難排解
如果您對此元件啟用分散式定型,則每個流程會有驅動程式記錄。 70_driver_log_0 適用於主要流程。 您可以在右窗格的 [輸出 + 記錄] 索引標籤下,查看驅動程式記錄中每個流程的錯誤詳細資料。

如果已啟用分散式定型的元件失敗,但沒有任何 70_driver 記錄,您可以在 70_mpi_log 中查看錯誤詳細資料。
下列範例顯示常見的錯誤:每個節點的流程計數大於計算的處理單位。

如需元件疑難排解的詳細資訊,請參閱這篇文章。
結果
在管線作業完成後,若要使用模型來評分,請將定型 PyTorch 模型連接至評分影像模型,以預測新輸入範例的值。
技術說明
預期的輸入
| 名稱 | 類型 | 描述 |
|---|---|---|
| 未定型的模型 | UntrainedModelDirectory | 未定型的模型,需要 PyTorch |
| 定型資料集 | ImageDirectory | 定型資料集 |
| 驗證資料集 | ImageDirectory | 每個時期評估的驗證資料集 |
元件參數
| 名稱 | 範圍 | 類型 | 預設 | 描述 |
|---|---|---|---|---|
| 時期 | >0 | 整數 | 5 | 選取包含標籤或結果資料行的資料行 |
| 批次大小 | >0 | 整數 | 16 | 批次中要定型的執行個體數目 |
| 熱身步驟編號 | >=0 | 整數 | 0 | 定型熱身的時期數目 |
| 學習率 | >=double.Epsilon | Float | 0.1 | 隨機梯度下降最佳化工具的初始學習速率。 |
| 隨機種子 | 任意 | 整數 | 1 | 模型使用的亂數產生器的種子。 |
| 容忍 | >0 | 整數 | 3 | 提前停止定型的時期數目 |
| 列印頻率 | >0 | 整數 | 10 | 每個時期在反覆運算上的記錄列印頻率 |
輸出
| 名稱 | 類型 | Description |
|---|---|---|
| 定型的模型 | ModelDirectory | 定型的模型 |
後續步驟
請參閱 Azure Machine Learning 可用的元件集。