Apache Spark 集區的資料整頓 (已淘汰)

警告
Azure Synapse Analytics 與 Python SDK v1 中提供的 Azure Machine Learning 整合已淘汰。 使用者仍然可以使用向 Azure Machine Learning 註冊為連結服務的 Synapse 工作區。 不過,新的 Synapse 工作區無法再向 Azure Machine Learning 註冊為連結服務。 我們建議使用無伺服器 Spark 計算和連結的 Synapse Spark 集區,可在 CLI v2 和 Python SDK v2 中取得。 如需詳細資訊,請瀏覽 https://aka.ms/aml-spark。
在本文中,您會了解如何在 Jupyter 筆記本中,以互動方式於 Azure Synapse Analytics 提供的專用 Synapse 工作階段內執行資料整頓工作。 這些工作要依賴 Azure Machine Learning Python SDK。 如需 Azure Machine Learning 管線的詳細資訊,請瀏覽如何在您的機器學習管線中使用 Apache Spark (由 Azure Synapse Analytics 提供) (預覽)。 如需如何搭配使用 Azure Synapse Analytics 與 Synapse 工作區的詳細資訊,請瀏覽 Azure Synapse Analytics 開始使用系列文章。
Azure Machine Learning 和 Azure Synapse Analytics 整合
Azure Synapse Analytics 與 Azure Machine Learning (預覽) 整合可讓您連結 Azure Synapse 所支援的 Apache Spark 集區,以進行互動式資料探索和準備。 透過此整合,您可以獲得專用計算資源以進行大規模的資料整頓,而這一切全都在您用來定型機器學習模型的相同 Python 筆記本內。
必要條件
設定開發環境以安裝 Azure Machine Learning SDK,或使用已安裝 SDK 的 Azure Machine Learning Compute 執行個體
使用下列程式碼安裝
azureml-synapse套件 (預覽):pip install azureml-synapse將您的 Azure Machine Learning 工作區和 Azure Synapse Analytics 工作區與 Azure Machine Learning Python SDK 或與 Azure Machine Learning 工作室連結
連結 Synapse Spark 集區以作為計算目標
針對資料整頓工作啟動 Synapse Spark 集區
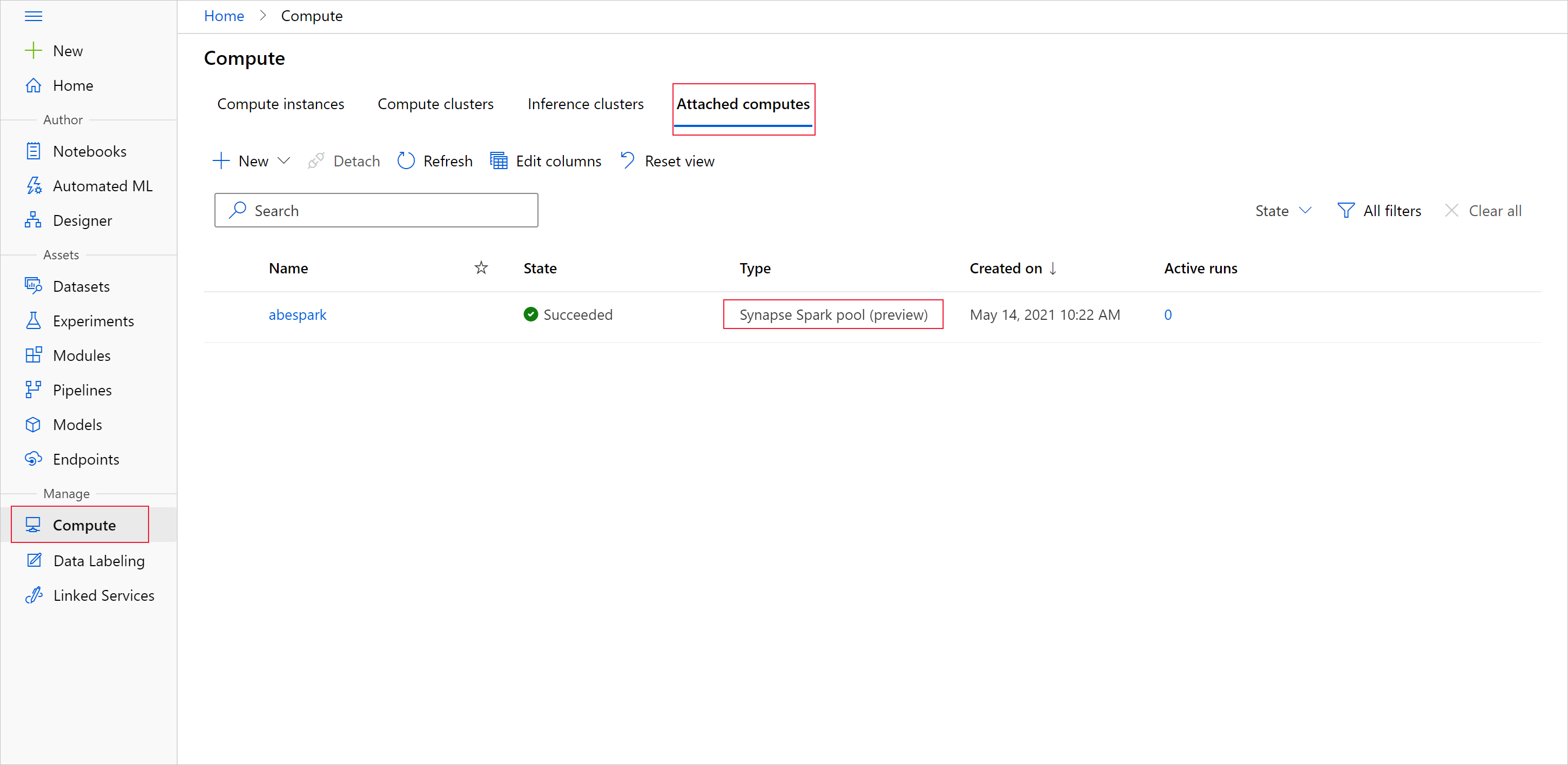
若要使用 Apache Spark 集區來開始準備資料,請指定連結的 Spark Synapse 計算名稱。 您可以在 [連結的計算] 索引標籤下,找到 Azure Machine Learning 工作室的這個名稱。
重要
若要繼續使用 Apache Spark 集區,您必須指出要在整個資料整頓工作中使用的計算資源。 若為單行程式碼,請使用 %synapse,若為多行程式碼,請使用 %%synapse:
%synapse start -c SynapseSparkPoolAlias
工作階段啟動之後,您就可以檢查工作階段的中繼資料:
%synapse meta
您可以指定 Apache Spark 工作階段期間要使用的 Azure Machine Learning 環境。 只有在環境中指定的 Conda 相依性才會生效。 不支援 Docker 映像。
警告
Synapse Spark 集區不支援在環境 Conda 相依性中指定的 Python 相依性。 目前,只支援固定的 Python 版本。請在您的指令碼中加入 sys.version_info 以檢查 Python 版本
此程式碼會建立 myenv 環境變數,以在工作階段開始之前安裝 azureml-core 1.20.0 版和 numpy 1.17.0 版。 然後,您可以將此環境包含在 Apache Spark 工作階段 start 陳述式中。
from azureml.core import Workspace, Environment
# creates environment with numpy and azureml-core dependencies
ws = Workspace.from_config()
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core==1.20.0")
env.python.conda_dependencies.add_conda_package("numpy==1.17.0")
env.register(workspace=ws)
若要在自訂環境中使用 Apache Spark 集區來開始準備資料,請指定要在 Apache Spark 工作階段期間使用的 Apache Spark 集區名稱和環境。 您可以提供訂用帳戶識別碼、機器學習工作區資源群組,以及機器學習工作區的名稱。
%synapse start -c SynapseSparkPoolAlias -e myenv -s AzureMLworkspaceSubscriptionID -r AzureMLworkspaceResourceGroupName -w AzureMLworkspaceName
從儲存體載入資料
在 Apache Spark 工作階段啟動後,請讀取您想要準備的資料。 Azure Blob 儲存體和 Azure Data Lake Storage Generations 1 和 2 皆支援使用者委派 SAS。
您有兩個選項可從這些儲存體服務載入資料:
使用 Hadoop 分散式檔案系統 (HDFS) 路徑,直接從儲存體載入資料
從現有的 Azure Machine Learning 資料集讀取資料
若要存取這些儲存體服務,您必須至少具有儲存體 Blob 資料讀取者存取權。 若要將資料寫回這些儲存體服務,您需要儲存體 Blob 資料參與者權限。 深入了解儲存體權限和角色。
使用 Hadoop 分散式檔案系統將資料載入 (HDFS) 路徑
若要使用對應的 HDFS 路徑從儲存體載入和讀取資料,您必須有可用的資料存取驗證認證。 這些認證會根據您的儲存體類型而有所不同。 此程式碼範例示範如何使用共用存取簽章 (SAS) 權杖或存取金鑰,將資料從 Azure Blob 儲存體讀取到 Spark 資料框架:
%%synapse
# setup access key or SAS token
sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<storage account name>.blob.core.windows.net", "<access key>")
sc._jsc.hadoopConfiguration().set("fs.azure.sas.<container name>.<storage account name>.blob.core.windows.net", "<sas token>")
# read from blob
df = spark.read.option("header", "true").csv("wasbs://demo@dprepdata.blob.core.windows.net/Titanic.csv")
此程式碼範例示範如何使用服務主體認證,從 Azure Data Lake Storage Generation 1 (ADLS Gen 1) 讀取資料:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.access.token.provider.type","ClientCredential")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.client.id", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.credential", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.refresh.url",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("adl://<storage account name>.azuredatalakestore.net/<path>")
此程式碼範例示範如何使用服務主體認證,從 Azure Data Lake Storage Generation 2 (ADLS Gen 2) 讀取資料:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<storage account name>.dfs.core.windows.net","OAuth")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<storage account name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<storage account name>.dfs.core.windows.net", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<storage account name>.dfs.core.windows.net", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<storage account name>.dfs.core.windows.net",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("abfss://<container name>@<storage account>.dfs.core.windows.net/<path>")
從已註冊的資料集讀取資料
您也可以在工作區中放置現有的已註冊資料集,並且,如果您想要將其轉換為 Spark 資料框架,則對其執行資料準備。 此範例會向工作區進行驗證、取得會參考 Blob 儲存體中檔案的已註冊 TabularDataset (blob_dset),並將該 TabularDataset 轉換為 Spark 資料框架。 當您將資料集轉換為 Spark 資料框架時,您可以使用 pyspark 資料探索和準備程式庫。
%%synapse
from azureml.core import Workspace, Dataset
subscription_id = "<enter your subscription ID>"
resource_group = "<enter your resource group>"
workspace_name = "<enter your workspace name>"
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
dset = Dataset.get_by_name(ws, "blob_dset")
spark_df = dset.to_spark_dataframe()
執行資料整頓工作
在擷取和探索資料後,就可以執行資料整頓工作了。 此程式碼範例會在上一節中的 HDFS 範例上展開。 根據 Survivor 資料行,其會篩選依 Age 列出的 Spark 資料框架 df 和群組中的資料:
%%synapse
from pyspark.sql.functions import col, desc
df.filter(col('Survived') == 1).groupBy('Age').count().orderBy(desc('count')).show(10)
df.show()
將資料儲存至儲存體並停止 spark 工作階段
當您的資料探索和準備完成後,請儲存您備妥的資料以供稍後在 Azure 上的儲存體帳戶中使用。 在此程式碼範例中,已備妥的資料會寫回到 Azure Blob 儲存體,並覆寫 training_data 目錄中的原始 Titanic.csv 檔案。 若要回寫至儲存體,您需要儲存體 Blob 資料參與者權限。 如需詳細資訊,請瀏覽指派 Azure 角色以存取 Blob 資料。
%% synapse
df.write.format("csv").mode("overwrite").save("wasbs://demo@dprepdata.blob.core.windows.net/training_data/Titanic.csv")
完成資料準備,並將備妥的資料儲存到儲存體後,請使用下列命令結束使用 Apache Spark 集區:
%synapse stop
建立資料集以代表備妥的資料
當您準備好要使用備妥的資料進行模型定型時,請使用 Azure Machine Learning 資料存放區連線到您的儲存體,並指定要與 Azure Machine Learning 資料集搭配使用的檔案。
此程式碼範例
- 假設您已建立資料存放區,以連接到您儲存備妥資料的儲存體服務
- 使用 get() 方法,從工作區
ws中擷取現有的資料存放區mydatastore。 - 建立 FileDataset (
train_ds),以參考位於mydatastoretraining_data目錄中的備妥資料檔案 - 建立變數
input1。 稍後,此變數可以將train_ds資料集的資料檔案提供給定型工作的計算目標使用。
from azureml.core import Datastore, Dataset
datastore = Datastore.get(ws, datastore_name='mydatastore')
datastore_paths = [(datastore, '/training_data/')]
train_ds = Dataset.File.from_files(path=datastore_paths, validate=True)
input1 = train_ds.as_mount()
使用 ScriptRunConfig 將實驗執行提交至 Synapse Spark 集區
如果您已準備好將資料整頓工作自動化並 productionize,您可以使用ScriptRunConfig物件將實驗回合提交至附加的 Synapse Spark 集區。 同樣地,如果您有 Azure Machine Learning 管線,您可以使用 SynapseSparkStep 來指定 Synapse Spark 集區,做為管線中資料準備步驟的計算目標。 資料是否可供 Synapse Spark 集區使用取決於您的資料集類型。
- 若為 FileDataset,您可以使用
as_hdfs()方法。 提交回合時,Synapse Spark 集區會將資料集提供給 Spark 集區,以做為 Hadoop 分散式檔案系統 (HFDS) - 若為 TabularDataset,您可以使用
as_named_input()方法
下列程式碼範例
- 會從 FileDataset
train_ds(其本身是在先前的程式碼範例中建立的) 建立變數input2 - 會使用
HDFSOutputDatasetConfiguration類別建立變數output。 執行完成之後,這個類別可讓我們將執行的輸出儲存至mydatastore資料存放區中的資料集test。 在 [Azure Machine Learning] 工作區中,test資料集是在名稱下註冊registered_dataset - 設定回合應使用的設定,以在 Synapse Spark 集區上執行
- 定義的 ScriptRunConfig 參數,以便
- 使用
dataprep.py指令碼來執行 - 指定要做為輸入的資料,以及如何將該資料提供給 Synapse Spark 集區使用
- 指定儲存
output輸出資料的位置
- 使用
from azureml.core import Dataset, HDFSOutputDatasetConfig
from azureml.core.environment import CondaDependencies
from azureml.core import RunConfiguration
from azureml.core import ScriptRunConfig
from azureml.core import Experiment
input2 = train_ds.as_hdfs()
output = HDFSOutputDatasetConfig(destination=(datastore, "test").register_on_complete(name="registered_dataset")
run_config = RunConfiguration(framework="pyspark")
run_config.target = synapse_compute_name
run_config.spark.configuration["spark.driver.memory"] = "1g"
run_config.spark.configuration["spark.driver.cores"] = 2
run_config.spark.configuration["spark.executor.memory"] = "1g"
run_config.spark.configuration["spark.executor.cores"] = 1
run_config.spark.configuration["spark.executor.instances"] = 1
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-core==1.20.0")
run_config.environment.python.conda_dependencies = conda_dep
script_run_config = ScriptRunConfig(source_directory = './code',
script= 'dataprep.py',
arguments = ["--file_input", input2,
"--output_dir", output],
run_config = run_config)
如需 run_config.spark.configuration 和一般 Spark 設定的詳細資訊,請瀏覽 SparkConfiguration 類別和 Apache Spark 的設定文件。
在設定 ScriptRunConfig 物件後,就可以提交該執行。
from azureml.core import Experiment
exp = Experiment(workspace=ws, name="synapse-spark")
run = exp.submit(config=script_run_config)
run
如需詳細資訊,包括此範例中使用的 dataprep.py 指令碼相關資訊,請參閱範例筆記本。
在準備好資料後,便可以將其作為定型作業的輸入。 在上述程式碼範例中,請將 registered_dataset 指定為用於定型作業的輸入資料。
Notebook 範例
請檢閱這些範例筆記本,以取得 Azure Synapse Analytics 的詳細概念和示範,以及 Azure Machine Learning 整合功能:
- 從 Azure Machine Learning 工作區中的筆記本執行互動式 Spark 工作階段。
- 提交 Azure Machine Learning 實驗,並以 Synapse Spark 集區作為您的計算目標來執行。