重要事項
本文提供使用 Azure Machine Learning SDK v1 的相關信息。 SDK v1 自 2025 年 3 月 31 日起已被取代。 其支援將於 2026 年 6 月 30 日結束。 您可以在該日期之前安裝並使用 SDK v1。 您使用 SDK v1 的現有工作流程將在支援終止日期後繼續運作。 不過,如果產品發生架構變更,它們可能會面臨安全性風險或重大變更。
建議您在 2026 年 6 月 30 日之前轉換至 SDK v2。 如需 SDK v2 的詳細資訊,請參閱 什麼是 Azure Machine Learning CLI 和 Python SDK v2? 和 SDK v2 參考。
重要事項
本文說明如何使用適用於 Python (v1) 的 Azure Machine Learning CLI (v1) 和 Azure Machine Learning SDK 以部署模型。 如需 v2 的建議方法,請參閱使用線上端點來部署和評分機器學習模型。
了解如何使用 Azure Machine Learning 在 Azure Kubernetes Service (AKS) 上將模型部署為 Web 服務。 AKS 適用於大規模生產環境部署。 如果您需要下列一或多個功能,請使用 AKS:
- 快速回應時間
- 已部署服務的自動調整
- 記錄
- 模型資料收集
- 驗證
- TLS 終止
- 硬體加速選項,例如 GPU 和可現場程式化閘道陣列 (FPGA)
在部署至 AKS 時,您會部署至與工作區連線的 AKS 叢集。 如需將 AKS 叢集連線至工作區的相關資訊,請參閱建立和連結 Azure Kubernetes Service 叢集。
重要事項
建議您先在本機進行偵錯,再部署至 Web 服務。 如需詳細資訊,請參閱本地模型部署的疑難排解。
附註
Azure Machine Learning 端點 (v2) 提供經過改良且更簡單的部署體驗。 端點同時支援即時和 Batch 推斷案例。 端點會提供整合介面,以叫用和管理跨計算類型的模型部署。 請參閱什麼是 Azure Machine Learning 端點?。
先決條件
Azure Machine Learning 工作區。 如需詳細資訊,請參閱建立 Azure Machine Learning 工作區。
在您的工作區中登錄的機器學習模型。 如果您沒有已註冊的模型,請參閱將機器學習模型部署至 Azure。
適用於 Machine Learning 服務的 Azure CLI 延伸模組 (第 1 版)、Azure Machine Learning Python SDK 或 Azure Machine Learning Visual Studio Code 延伸模組。
重要事項
本文中的 Azure CLI 命令使用
azure-cli-ml或 v1 (Azure Machine Learning 的擴充功能)。 CLI v1 的支援已於 2025 年 9 月 30 日結束。 Microsoft 將不再提供此服務的技術支援或更新。 您使用 CLI v1 的現有工作流程將在支援終止日期之後繼續運作。 不過,如果產品發生架構變更,它們可能會面臨安全性風險或重大變更。建議您盡快轉換至
ml或 v2 擴充功能。 如需有關 v2 延伸模組的詳細資訊,請參閱 Azure Machine Learning CLI 延伸模組和 Python SDK v2。本文中的 Python 程式碼片段會假設已設定下列變數:
-
ws- 設為您的工作區。 -
model- 設為您已註冊的模型。 -
inference_config- 設為模型的推斷設定。
如需設定這些變數的詳細資訊,請參閱部署模型的方式和位置。
-
本文中的 CLI 程式碼片段假設您已建立 inferenceconfig.json 文件。 如需建立本文件的詳細資訊,請參閱將機器學習模型部署至 Azure。
連線至工作區的 AKS 叢集。 如需詳細資訊,請參閱建立和連結 Azure Kubernetes Service 叢集。
- 如果您想要將模型部署至 GPU 節點或 FPGA 節點 (或任何特定產品),您必須建立具有特定產品的叢集。 不支援在現有的叢集中建立次要節點集區,並在次要節點集區中部署模型。
了解部署流程
Kubernetes 和 Azure Machine Learning 中都會使用「部署 (deployment)」一詞。
在這兩個內容中,「部署」具有不同的意義。 在 Kubernetes 中,部署是使用宣告式 YAML 檔案指定的具象實體。 Kubernetes 部署具有已定義的生命週期和與其他 Kubernetes 實體 (例如 Pods 和 ReplicaSets) 的具象關聯性。 您可以從位於什麼是 Kubernetes?的文件和影片了解 Kubernetes。
在 Azure Machine Learning 中,部署會用於提供和清除您的專案資源的更一般概念。 Azure Machine Learning 認為屬於部署一部分的步驟為:
- 壓縮專案資料夾中的檔案,並忽略 .amlignore 或 .gitignore 中所指定的檔案
- 擴充您的計算叢集 (與 Kubernetes 相關)
- 建立或下載 dockerfile 至計算節點 (與 Kubernetes 相關)
- 系統會計算下列雜湊:
- 基礎映像
- 自訂 Docker 步驟 (請參閱使用自訂 Docker 基礎映像部署模型)
- conda 定義 YAML (請參閱在 Azure Machine Learning 中建立及使用軟體環境)
- 系統會使用此雜湊作為工作區 Azure Container Registry (ACR) 查閱中的索引鍵
- 如果找不到,則會在全域 ACR 中尋找相符項目
- 如果找不到,系統會建置快取並推送至工作區 ACR 的新映像
- 系統會計算下列雜湊:
- 將壓縮的專案檔案下載至計算節點上的暫存儲存體
- 解壓縮專案檔
- 執行
python <entry script> <arguments>的計算節點 - 將寫入 ./outputs 的記錄、模型檔案和其他檔案儲存到與工作區相關聯的儲存體帳戶
- 縮減計算,包括移除暫存儲存體 (與 Kubernetes 相關)
Azure Machine Learning 路由器
將傳入推斷要求路由至部署的服務的前端元件 (azureml-fe) 會視需要自動調整。 azureml-fe 的調整是根據 AKS 叢集用途和大小 (節點數目)。 建立或連結 AKS 叢集時,會設定叢集目的和節點。 每個叢集都有一個 azureml-fe 服務,可能在多個 Pod 上執行。
重要事項
- 使用設定為
dev-test的叢集時,自我調整程式將會是已停用。 即使是 FastProd/DenseProd 叢集,Self-Scaler 也僅在遙測顯示需要時才會啟用。 - Azure Machine Learning 不會從容器 (包含系統容器) 自動上傳或儲存記錄。 若要進行完整的偵錯,建議您為 AKS 叢集啟用容器深入解析。 這可讓您視需要儲存、管理容器記錄並與 AML 小組共用。 若未啟用,則 AML 無法保證支援與 azureml-fe 相關的問題。
- 要求承載上限為 100 MB。
Azureml-fe 會擴大 (垂直) 以使用更多核心,及擴增 (水平) 以使用更多的 Pod。 進行擴大的決策時,會使用路由傳入推斷要求所耗費的時間。 如果此時間超過閾值,就會發生擴大。 如果路由傳入要求的時間持續超過閾值,則會發生擴增。
進行縮減和縮小時,會使用 CPU 使用量。 如果達到 CPU 使用量閾值,則前端會先縮減。 如果 CPU 使用量下降到縮小閾值,就會發生縮小作業。 僅當有足夠的可用叢集資源時,才會進行擴充和擴增。
相應增加或相應減少時,將會重新啟動 azureml-fe Pod 以套用 CPU/記憶體變更。 重新啟動不會影響推斷要求。
了解 AKS 推斷叢集的連線需求
Azure Machine Learning 建立或連結 AKS 叢集時,會使用下列兩種網路模型的其中一種來部署 AKS 叢集:
- Kubenet 網路:在部署 AKS 叢集時通常會建立並設定網路資源。
- Azure 容器網路介面 (CNI) 網路:AKS 叢集會連線至現有的虛擬網路資源和設定。
針對 Kubenet 網路功能,會為 Azure Machine Learning 服務建立並正確設定網路。 針對 CNI 網路功能,您需要了解連線需求,並確保 AKS 推斷的 DNS 解析和輸出連線。 例如,您可能使用防火牆來封鎖網路流量。
下圖顯示 AKS 推斷的連線需求。 黑色箭號代表實際的通訊,而藍色箭號代表網域名稱。 您可能需要將這些主機的項目新增至您的防火牆或自訂 DNS 伺服器。
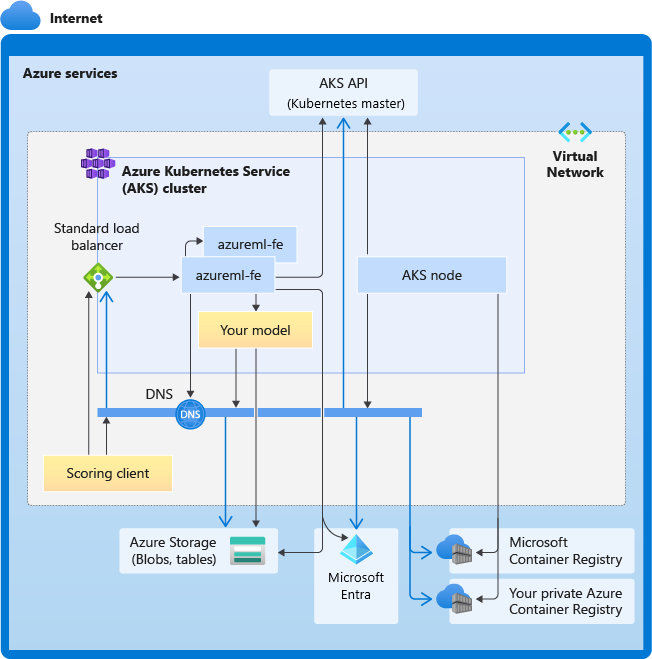
如需一般 AKS 連線需求,請參閱在 AKS 中使用 Azure 防火牆限制網路流量。
如需在防火牆後方存取 Azure Machine Learning 服務,請參閱設定輸入和輸出網路流量。
整體 DNS 解析需求
現有虛擬網路內的 DNS 解析在您的控制之下。 例如,防火牆或自訂 DNS 伺服器。 下列主機必須可連線:
| 主機名稱 | 使用者 |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
AKS API 伺服器 |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
您的 Azure Container Registry (ACR) |
<account>.table.core.windows.net |
Azure 儲存體帳戶 (資料表儲存體) |
<account>.blob.core.windows.net |
Azure 儲存體帳戶 (Blob 儲存體) |
api.azureml.ms |
Microsoft Entra 驗證 |
ingest-vienna<region>.kusto.windows.net |
用於上傳遙測的 Kusto 端點 |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
端點網域名稱,如果您使用 Azure Machine Learning 自動產生。 如果您使用自訂網域名稱,則不需要此項目。 |
連線需求 (按時間順序)
在 AKS 建立或連結的程序中,會將 Azure Machine Learning 路由器 (azureml-fe) 部署至 AKS 叢集。 為了部署 Azure Machine Learning 路由器,AKS 節點應能夠:
- 解析 AKS API 伺服器的 DNS
- 解析 MCR 的 DNS,以便下載適用於 Azure Machine Learning 路由器的 Docker 映像
- 從 MCR 下載映像,其中需要輸出連線
部署 azureml-fe 之後,隨即嘗試啟動,而您需要執行下列動作:
- 解析 AKS API 伺服器的 DNS
- 查詢 AKS API 伺服器以探索其本身的其他執行個體 (這是多 Pod 服務)
- 連線至其本身的其他執行個體
一旦啟動 azureml-fe,需要下列項目,連線才能正常運作:
- 連線 Azure 儲存體,以下載動態設定
- 解析 Microsoft Entra 驗證伺服器 api.azureml.ms 的 DNS,並在部署的服務使用 Microsoft Entra 驗證時與其通訊。
- 查詢 AKS API 伺服器以探索部署的模型
- 與已部署的模型 Pod 通訊
在模型部署時,為了成功模型部署,AKS 節點應該能夠:
- 解析客戶的 ACR DNS
- 從客戶的 ACR 下載映像
- 解析儲存模型所在 Azure Blob 的 DNS
- 從 Azure Blob 下載模型
模型部署且服務啟動之後,azureml-fe 將使用 AKS API 自動探索,並準備好將要求路由至其中。 它必須能夠與模型 Pod 通訊。
附註
如果已部署的模型需要任何連線 (例如查詢外部資料庫或其他 REST 服務,或者下載 BLOB),則應該同時啟用這些服務的 DNS 解析和輸出通訊。
部署到 AKS
若要將模型部署至 AKS,請建立部署設定,以描述所需的計算資源。 例如,核心和記憶體數目。 您也需要推斷設定,其中描述裝載模型和 Web 服務所需的環境。 如需建立推斷設定的詳細資訊,請參閱部署模型的方式和位置。
附註
要部署的模型數目限制為每個部署 (每個容器) 1,000 個模型。
適用於: 適用於 Python 的 Azure Machine Learning SDK v1
適用於 Python 的 Azure Machine Learning SDK v1
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
如需此範例中所使用的類別、方法和參數的詳細資訊,請參閱下列參考文件:
自動調整
適用於:適用於 Python 的 Azure Machine Learning SDK v1
為 Azure Machine Learning 模型部署處理自動調整的元件是 azureml-fe,也就是智慧型要求路由器。 因為所有推斷要求都會通過該元件,因此其具有自動調整已部署模型的必要資料。
重要事項
請勿為模型部署啟用 Kubernetes 水平 Pod 自動調整程式 (HPA)。 這麼做會導致兩個自動調整元件互相競爭。 Azureml-fe 的設計可自動調整 Azure ML 部署的模型,其中的 HPA 必須從一般計量 (例如 CPU 使用量或自訂計量設定) 猜測或估計模型使用率。
Azureml-fe 無法調整 AKS 叢集中的節點數目,因為這可能會導致非預期的成本增加。 相反地,它會在實體叢集界限內調整模型的複本數目。 如果您需要調整叢集內的節點數目,您可以手動調整叢集或設定 AKS 叢集自動調整程式。
您可以藉由設定 autoscale_target_utilization、autoscale_min_replicas 和 autoscale_max_replicas 來控制 AKS Web 服務的自動調整。 下列範例示範如何啟用自動調整:
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
擴大或縮減的決策是以目前容器複本的使用量為基礎。 忙碌中 (處理要求) 的複本數目除以目前複本的總數即為目前的使用率。 如果此數目超過 autoscale_target_utilization,則會建立更多複本。 如果低於此數目,即會減少複本。 依預設,目標使用率為 70%。
新增複本的決策是積極且快速 (大約 1 秒)。 移除複本的決策是保守 (大約 1 分鐘)。
您可以使用下列程式碼來計算所需的複本:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
如需設定 autoscale_target_utilization、autoscale_max_replicas 和 autoscale_min_replicas 的詳細資訊,請參閱 AksWebservice 模組參考。
Web 服務驗證
部署到 Azure Kubernetes Service 時,預設會啟用金鑰型驗證。 您也可以啟用「權杖型」驗證。 權杖型驗證要求用戶端使用 Microsoft Entra 帳戶來要求驗證權杖,其會用來對已部署的服務提出要求。
若要「停用」驗證,請在建立部署設定時設定 auth_enabled=False 參數。 下列範例會使用 SDK 停用驗證:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
如需從用戶端應用程式進行驗證的詳細資訊,請參閱取用部署為 Web 服務的 Azure Machine Learning 模型。
使用金鑰驗證
如果啟用金鑰驗證,則可以使用 get_keys 方法來擷取主要和次要驗證金鑰:
primary, secondary = service.get_keys()
print(primary)
重要事項
如果您需要重新產生金鑰,請使用 service.regen_key。
使用權杖驗證
若要啟用權杖驗證,請在建立或更新部署時設定 token_auth_enabled=True 參數。 下列範例會使用 SDK 啟用權杖驗證:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
如果已啟用令牌驗證,您可以使用 get_token 方法來擷取 JWT 和該令牌的到期時間:
token, refresh_by = service.get_token()
print(token)
重要事項
您必須在權杖的 refresh_by 時間之後要求新的權杖。
Microsoft 強烈建議在與 AKS 叢集相同的區域中建立 Azure Machine Learning 工作區。 若要使用權杖進行驗證,Web 服務會呼叫 Azure Machine Learning 工作區的建立區域。 如果您的工作區區域無法使用,即使您的叢集與您的工作區位於不同的區域,您也將無法提取 Web 服務的權杖。 這實際上會導致權杖型驗證無法使用,直到您的工作區區域再次可供使用為止。 此外,叢集區域和工作區區域之間的距離愈大,擷取權杖所需的時間就越長。
若要取得權杖,您必須使用 Azure Machine Learning SDK 或 az ml service get-access-token 命令。
弱點掃描
適用於雲端的 Microsoft Defender 提供跨混合式雲端工作負載的整合式安全性管理與進階威脅保護。 您應允許適用於雲端的 Microsoft Defender 掃描您的資源,並遵循其建議。 如需深入了解,請參閱適用於容器的 Microsoft Defender 中的容器安全性。