適用於: Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
在本文中,您將瞭解如何將模型部署至線上端點,以用於即時推斷。 首先,您將在本機電腦上部署模型,以針對任何錯誤執行偵錯。 接著,您將在 Azure 中部署及測試模型、檢視部署記錄,以及監視服務等級協定 (SLA)。 在本文結束時,您將擁有可擴展的 HTTPS/REST 端點,可用於即時推論。
線上端點是用於即時推斷的端點。 在線端點有兩種類型:受控在線端點和 Kubernetes 在線端點。 如需差異的詳細資訊,請參閱 受控在線端點與 Kubernetes 在線端點。
受控線上端點可協助您以周全的方式部署機器學習模型。 受控線上端點會以可調整且完全受控的方式,在 Azure 中使用強大的 CPU 和 GPU 機器。 受控在線端點會負責服務、調整、保護及監視您的模型。 這項協助可讓您免於設定和管理基礎結構的額外負荷。
本文中的主要範例使用受控線上端點進行部署。 若要改為使用 Kubernetes,請參閱本文件中的附註與受控線上端點討論。
先決條件
適用於:Azure CLI ml 延伸模組 v2 (目前)
Azure 角色型訪問控制 (Azure RBAC) 可用來授與 Azure Machine Learning 中作業的存取權。 若要執行本文中的步驟,您必須為 Azure Machine Learning 工作區指派使用者帳戶的擁有者或參與者角色,或自定義角色必須允許 Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*。 如果您使用 Azure Machine Learning Studio 來建立和管理在線端點或部署,則需要資源群組擁有者的額外許可權 Microsoft.Resources/deployments/write 。 如需詳細資訊,請參閱 管理 Azure Machine Learning 工作區。
(選擇性) 如要執行本機部署,您必須在本機電腦上安裝 Docker 引擎。
強烈建議使用此選項,讓您更輕鬆地偵錯問題。
適用於:Python SDK azure-ai-ml v2 (目前)
Azure Machine Learning 工作區。 如需建立工作區的步驟,請參閱 建立工作區。
適用於 Python v2 的 Azure Machine Learning SDK。 若要安裝 SDK,請使用下列命令:
pip install azure-ai-ml azure-identity
若要將現有的 SDK 安裝更新為最新版本,請使用下列命令:
pip install --upgrade azure-ai-ml azure-identity
如需詳細資訊,請參閱 適用於 Python 的 Azure Machine Learning 套件用戶端連結庫。
Azure RBAC 可用來授與 Azure Machine Learning 中作業的存取權。 若要執行本文中的步驟,您必須為 Azure Machine Learning 工作區指派使用者帳戶的擁有者或參與者角色,或自定義角色必須允許 Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*。 如需詳細資訊,請參閱 管理 Azure Machine Learning 工作區。
(選擇性) 如要執行本機部署,您必須在本機電腦上安裝 Docker 引擎。
強烈建議使用此選項,讓您更輕鬆地偵錯問題。
在您遵循本文中的步驟之前,請確定您具備下列必要條件:
適用於機器學習的 Azure CLI 和 CLI 擴充功能會用於這些步驟,但並非主要焦點。 它們會用來做為公用程式,將範本傳遞至 Azure,並檢查範本部署的狀態。
- Azure RBAC 可用來授與 Azure Machine Learning 中作業的存取權。 若要執行本文中的步驟,您必須為 Azure Machine Learning 工作區指派使用者帳戶的擁有者或參與者角色,或自定義角色必須允許
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*。 如需詳細資訊,請參閱管理對 Azure Machine Learning 工作區的存取。
確保已為部署分配足夠的虛擬機器 (VM) 配額。 Azure Machine Learning 會保留 20% 的計算資源,以在部分 VM 版本上執行升級。 例如,如果您在部署中要求 10 個實例,則 VM 版本的每個核心數目都必須有 12 個配額。 若無法預留額外計算資源,便會發生錯誤。 某些 VM 版本會免除額外的配額保留。 如需配額配置的詳細資訊,請參閱 部署的虛擬機配額配置。
或者,您可以在有限的時間內使用 Azure Machine Learning 共用配額集區的配額。 Azure Machine Learning 提供共用配額集區,供不同區域的使用者根據可用性,在有限時間內存取配額並執行測試。
當使用工作室將 Llama-2、Phi、Nemotron、Mistral、Dolly 和 Deci-DeciLM 模型從模型目錄部署到受控線上端點時,您可暫時存取 Azure Machine Learning 共用配額集區,以便進行測試。 如需共用配額集區的詳細資訊,請參閱 Azure Machine Learning 共用配額。
準備您的系統
設定環境變數
如果您尚未設定 Azure CLI 的預設值,請儲存您的預設設定。 如要避免多次傳遞訂閱、工作區和資源群組的值,請執行下列程式碼:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
複製範例存放庫
若要遵循本文,請先複製 azureml-examples 存放庫,然後變更為存放庫的 azureml-examples/cli 目錄:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli
使用 --depth 1 僅複製存放庫的最新認可,如此可縮短完成作業的時間。
本教學課程中的命令位於 cli 目錄中的檔案 deploy-local-endpoint.sh 和 deploy-managed-online-endpoint.sh。 YAML 組態檔位於 endpoints/online/managed/sample/ 子目錄中。
附註
Kubernetes 在線端點的 YAML 組態檔位於 endpoints/online/kubernetes/ 子目錄中。
複製範例存放庫
若要執行訓練範例,請先複製 azureml-examples 存放庫,然後進入 azureml-examples/sdk/python/endpoints/online/managed 目錄:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
使用 --depth 1 僅複製存放庫的最新認可,如此可縮短完成作業的時間。
本文中的資訊是以 online-endpoints-simple-deployment.ipynb 筆記本為基礎。 其包含與本文相同的內容,雖然程式碼的順序稍有不同。
連線至 Azure Machine Learning 工作區
工作區是 Azure Machine Learning 的最上層資源。 它提供一個集中的平台,讓您在使用 Azure Machine Learning 時管理您建立的所有工件。 在本節中,您會連線至要執行部署工作的工作區。 若要繼續,請開啟您的 online-endpoints-simple-deployment.ipynb 筆記本。
匯入必要的程式庫:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration
)
from azure.identity import DefaultAzureCredential
附註
如果您使用 Kubernetes 在線端點,請從 KubernetesOnlineEndpoint 庫導入 KubernetesOnlineDeployment 和 azure.ai.ml.entities 類別。
設定工作區詳細資料,並取得工作區的控制代碼。
若要連線到工作區,您需要這些標識符參數:訂用帳戶、資源群組和工作區名稱。 您將使用來自 MLClient 之 azure.ai.ml 中的詳細資料,以掌握所需的 Azure Machine Learning 工作區。 此範例會使用預設的 Azure 驗證。
# enter details of your Azure Machine Learning workspace
subscription_id = "<subscription ID>"
resource_group = "<resource group>"
workspace = "<workspace name>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
如果您已在本機電腦上安裝 Git,便可遵循指示複製範例存放庫。 否則,請遵循指示從範例存放庫中下載檔案。
複製範例存放庫
若要遵循本文,請先複製 azureml-examples 存放庫,然後變更為 azureml-examples/cli/endpoints/online/model-1 目錄。
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
使用 --depth 1 僅複製存放庫的最新認可,如此可縮短完成作業的時間。
從範例存放庫下載檔案
如果您已複製範例存放庫,則本機電腦已經有此範例的檔案複本,因此您可以跳至下一節。 如果您未複製存放庫,請將它下載到本機計算機。
- 移至範例存放 庫 (azureml-examples)。
- 移至頁面上的 [ <> 程序代碼 ] 按鈕,然後在 [ 本機 ] 索引標籤上,選取 [ 下載 ZIP]。
- 找出 /cli/endpoints/online/model-1/model 資料夾和 檔案 /cli/endpoints/online/model-1/onlinescoring/score.py。
設定環境變數
設定下列環境變數,讓您可以在本文的範例中使用它們。 將值取代為您的 Azure 訂用帳戶標識碼、工作區所在的 Azure 區域、包含工作區的資源群組,以及工作區名稱:
export SUBSCRIPTION_ID="<subscription ID>"
export LOCATION="<your region>"
export RESOURCE_GROUP="<resource group>"
export WORKSPACE="<workspace name>"
幾個範例會要求您將檔案上傳至工作區的 Azure Blob 記憶體。 下列步驟會查詢工作區,並將此資訊儲存在範例所使用的環境變數中:
取得存取權杖:
TOKEN=$(az account get-access-token --query accessToken -o tsv)
設定 REST API 版本:
API_VERSION="2022-05-01"
取得儲存體資訊:
# Get values for storage account
response=$(curl --location --request GET "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices/workspaces/$WORKSPACE/datastores?api-version=$API_VERSION&isDefault=true" \
--header "Authorization: Bearer $TOKEN")
AZUREML_DEFAULT_DATASTORE=$(echo $response | jq -r '.value[0].name')
AZUREML_DEFAULT_CONTAINER=$(echo $response | jq -r '.value[0].properties.containerName')
export AZURE_STORAGE_ACCOUNT=$(echo $response | jq -r '.value[0].properties.accountName')
複製範例存放庫
若要遵循本文,請先複製 azureml-examples 存放庫,然後變更為 azureml-examples 目錄:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
使用 --depth 1 僅複製存放庫的最新認可,如此可縮短完成作業的時間。
定義端點
若要定義在線端點,請指定端點名稱和驗證模式。 如需受控線上端點的詳細資訊,請參閱線上端點。
設定端點名稱
若要設定端點名稱,請執行下列命令。 將 <YOUR_ENDPOINT_NAME> 替換為 Azure 區域中的唯一名稱。 如需命名規則的詳細資訊,請參閱 端點限制。
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
下列程式碼片段顯示 endpoints/online/managed/sample/endpoint.yml 檔案:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
下表說明端點 YAML 格式的參考。 若要了解如何指定這些屬性,請參閱線上端點 YAML 參考 (部分機器翻譯)。 如需受控端點相關限制的相關信息,請參閱 Azure Machine Learning 在線端點和批次端點。
| Key |
描述 |
$schema |
(選擇性) YAML 結構描述。 若要查看 YAML 檔案中的所有可用選項,您可以在瀏覽器內檢視上述程式碼片段中的結構描述。 |
name |
端點的名稱。 |
auth_mode |
使用 key 進行金鑰式驗證。
使用 aml_token 進行 Azure Machine Learning 權杖型驗證。
使用 aad_token 進行Microsoft Entra 權杖型驗證 (預覽)。
如需驗證的詳細資訊,請參閱驗證線上端點的用戶端。 |
請先定義在線端點的名稱,然後設定端點。
將 <YOUR_ENDPOINT_NAME> 替換為在 Azure 區域中唯一的名稱,或者使用範例方法定義隨機名稱。 請務必刪除您不使用的方法。 如需命名規則的詳細資訊,請參閱 端點限制。
# method 1: define an endpoint name
endpoint_name = "<YOUR_ENDPOINT_NAME>"
# method 2: example way to define a random name
import datetime
endpoint_name = "endpt-" + datetime.datetime.now().strftime("%m%d%H%M%f")
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name = endpoint_name,
description="this is a sample endpoint",
auth_mode="key"
)
先前的程式碼以 key 進行金鑰式驗證。 若要使用 Azure Machine Learning 權杖型驗證,則請使用 aml_token。 若要使用 Microsoft Entra 權杖型驗證 (預覽),請使用 aad_token。 如需驗證的詳細資訊,請參閱驗證線上端點的用戶端。
從工作室部署至 Azure 時,您會建立端點以及要新增至該端點的部署。 此時,系統會提示您提供端點和部署的名稱。
定義部署
部署是託管執行實際推斷模型所需的一組資源。 在此範例中,您會部署 scikit-learn 執行回歸的模型,並使用評分腳本 score.py 在特定輸入要求上執行模型。
若要深入瞭解部署的主要屬性,請參閱線上部署。
您的部署組態會使用您想要部署的模型位置。
下列程式碼片段顯示 endpoints/online/managed/sample/blue-deployment.yml 檔案,以及所有要設定部署所需的輸入:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
blue-deployment.yml 檔案會指定下列部署屬性:
-
model:使用 path 參數 (檔案上傳來源) 指定內嵌模型屬性。 CLI 會自動上傳模型檔案,並以自動產生的名稱登錄模型。
-
environment:使用內嵌定義,其中包含上傳檔案的來源位置。 CLI 會自動上傳 conda.yaml 檔案並註冊環境。 稍後,若要建置環境,部署會使用 image 基底映像的參數。 在此範例中為 mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest。
conda_file 相依性會安裝在基礎映像上。
-
code_configuration:在部署期間,從開發環境上傳本機檔案,例如評分模型的 Python 來源。
如需關於 YAML 結構描述的詳細資訊,請參閱線上端點 YAML 參考。
附註
若要以 Kubernetes 端點而非受控線上端點做為計算目標,則必須:
- 使用 Azure Machine Learning 工作室建立 Kubernetes 叢集做為計算目標,並將其連結至 Azure Machine Learning 工作區。
- 使用 端點 YAML 以 Kubernetes 為目標,而不是受控端點 YAML。 您必須編輯 YAML,以將
compute 的值變更為已登錄的計算目標名稱。 您可以使用此 deployment.yaml ,其具有適用於 Kubernetes 部署的其他屬性。
本文中針對受控線上端點所使用的所有命令,皆適用於 Kubernetes 端點,但下列功能並不適用於 Kubernetes 端點:
使用下列程式代碼來設定部署:
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
-
Model:使用 path 參數 (檔案上傳來源) 指定內嵌模型屬性。 SDK 會自動上傳模型檔案,並以自動產生的名稱登錄模型。
-
Environment:使用內嵌定義,其中包含上傳檔案的來源位置。 SDK 會自動上傳 conda.yaml 檔案並註冊環境。 稍後,若要建置環境,部署會使用 image 基底映像的參數。 在此範例中為 mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest。
conda_file 相依性會安裝在基礎映像上。
-
CodeConfiguration:在部署期間,從開發環境上傳本機檔案,例如評分模型的 Python 來源。
如需線上部署定義的詳細資訊,請參閱 OnlineDeployment 類別。
部署至 Azure 時,您會建立端點以及要新增至該端點的部署。 此時,系統會提示您提供端點和部署的名稱。
瞭解評分指令碼
適用於線上端點的評分指令碼格式,與先前版本的 CLI 和 Python SDK 中使用的格式相同。
code_configuration.scoring_script 中指定的評分指令碼必須具有 init() 函式與 run() 函式。
評分指令碼必須具有 init() 函式與 run() 函式。
評分指令碼必須具有 init() 函式與 run() 函式。
評分指令碼必須具有 init() 函式與 run() 函式。 本文將使用 score.py file。
當您使用範本進行部署時,必須先將評分檔案上傳至 Blob 記憶體,然後加以註冊:
下列程式代碼會使用 Azure CLI 命令 az storage blob upload-batch 來上傳評分檔案:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/score -s cli/endpoints/online/model-1/onlinescoring --account-name $AZURE_STORAGE_ACCOUNT
下列程式代碼會使用範本來註冊程式代碼:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/code-version.json \
--parameters \
workspaceName=$WORKSPACE \
codeAssetName="score-sklearn" \
codeUri="https://$AZURE_STORAGE_ACCOUNT.blob.core.windows.net/$AZUREML_DEFAULT_CONTAINER/score"
此範例會使用您稍早複製或下載之存放庫的 score.py 檔案 :
import os
import logging
import json
import numpy
import joblib
def init():
"""
This function is called when the container is initialized/started, typically after create/update of the deployment.
You can write the logic here to perform init operations like caching the model in memory
"""
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment.
# It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION)
# Please provide your model's folder name if there is one
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl"
)
# deserialize the model file back into a sklearn model
model = joblib.load(model_path)
logging.info("Init complete")
def run(raw_data):
"""
This function is called for every invocation of the endpoint to perform the actual scoring/prediction.
In the example we extract the data from the json input and call the scikit-learn model's predict()
method and return the result back
"""
logging.info("model 1: request received")
data = json.loads(raw_data)["data"]
data = numpy.array(data)
result = model.predict(data)
logging.info("Request processed")
return result.tolist()
初始化或啟動容器時,會呼叫 init() 函式。 初始化作業通常會在建立或更新部署後立即執行。
init 函式可用來撰寫全域初始化作業的邏輯,例如在記憶體中快取模型 (如同此 score.py 檔案中所示)。
每次 run() 叫用端點時都會呼叫函式。 它會執行實際的評分和預測。 在此 score.py 檔案中,run() 函式會從 JSON 輸入擷取資料、呼叫 SciKit-Learn 學習模型的 predict() 方法,然後傳回預測結果。
使用本機端點在本機執行部署和偵錯
強烈建議您在本機測試執行端點,以在部署至 Azure 之前驗證和偵錯您的程式代碼和組態。 Azure CLI 和 Python SDK 支援本機端點和部署,但 Azure Machine Learning Studio 和 ARM 範本則不支援。
若要在本機部署,就必須安裝和執行 Docker 引擎。 Docker 引擎通常會在電腦啟動時啟動。 若未啟動,您可針對 Docker 引擎進行疑難排解。
您可以使用 Azure Machine Learning 推斷 HTTP 伺服器 Python 套件 ,在本機偵錯評分腳本 ,而不需要 Docker 引擎。 使用推斷伺服器進行偵錯可協助您在部署至本機端點之前偵錯評分腳本,讓您可以偵錯,而不會受到部署容器組態的影響。
如需在部署至 Azure 之前於本機偵錯在線端點的詳細資訊,請參閱 在線端點偵錯。
在本機部署模型
首先,建立端點。 或者,針對本地端點,您可以省略這一步驟。 您可以直接建立部署(下一個步驟),進而建立必要的元數據。 在本機部署模型適用於開發和測試用途。
az ml online-endpoint create --local -n $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
ml_client.online_endpoints.begin_create_or_update(endpoint, local=True)
工作室不支援本機端點。 如需在本機測試端點的步驟,請參閱 Azure CLI 或 Python 索引標籤。
範本不支援本機端點。 如需在本機測試端點的步驟,請參閱 Azure CLI 或 Python 索引標籤。
現在,請在端點下方建立名為 blue 的部署。
az ml online-deployment create --local -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml
--local 旗標會指示 CLI 在 Docker 環境中部署端點。
ml_client.online_deployments.begin_create_or_update(
deployment=blue_deployment, local=True
)
local=True 旗標會引導 SDK 在 Docker 環境中部署端點。
工作室不支援本機端點。 如需在本機測試端點的步驟,請參閱 Azure CLI 或 Python 索引標籤。
範本不支援本機端點。 如需在本機測試端點的步驟,請參閱 Azure CLI 或 Python 索引標籤。
確認本機部署成功
檢查部署狀態,查看是否已部署模型,且未發生錯誤:
az ml online-endpoint show -n $ENDPOINT_NAME --local
輸出應如下列 JSON 所示: 參數 provisioning_state 為 Succeeded。
{
"auth_mode": "key",
"location": "local",
"name": "docs-endpoint",
"properties": {},
"provisioning_state": "Succeeded",
"scoring_uri": "http://localhost:49158/score",
"tags": {},
"traffic": {}
}
ml_client.online_endpoints.get(name=endpoint_name, local=True)
該方法會傳回ManagedOnlineEndpoint 實體。 參數 provisioning_state 為 Succeeded。
ManagedOnlineEndpoint({'public_network_access': None, 'provisioning_state': 'Succeeded', 'scoring_uri': 'http://localhost:49158/score', 'swagger_uri': None, 'name': 'endpt-10061534497697', 'description': 'this is a sample endpoint', 'tags': {}, 'properties': {}, 'id': None, 'Resource__source_path': None, 'base_path': '/path/to/your/working/directory', 'creation_context': None, 'serialize': <msrest.serialization.Serializer object at 0x7ffb781bccd0>, 'auth_mode': 'key', 'location': 'local', 'identity': None, 'traffic': {}, 'mirror_traffic': {}, 'kind': None})
工作室不支援本機端點。 如需在本機測試端點的步驟,請參閱 Azure CLI 或 Python 索引標籤。
範本不支援本機端點。 如需在本機測試端點的步驟,請參閱 Azure CLI 或 Python 索引標籤。
下表包含 provisioning_state 的可能值:
| 值 |
描述 |
Creating |
正在建立資源。 |
Updating |
正在更新資源。 |
Deleting |
正在刪除資源。 |
Succeeded |
建立或更新作業成功。 |
Failed |
建立、更新或刪除作業失敗。 |
使用您的模型叫用本機端點以評分資料
使用 invoke 命令並傳遞儲存在 JSON 檔案中的查詢參數,以叫用端點為模型評分:
az ml online-endpoint invoke --local --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
若您想要使用 REST 用戶端 (例如 curl),您必須具有評分 URI。 如要取得評分 URI,請執行 az ml online-endpoint show --local -n $ENDPOINT_NAME。 在傳回的資料中,尋找 scoring_uri 屬性。
使用 invoke 命令並傳遞儲存在 JSON 檔案中的查詢參數,以叫用端點為模型評分。
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
request_file="../model-1/sample-request.json",
local=True,
)
若您想要使用 REST 用戶端 (例如 curl),您必須具有評分 URI。 若要取得評分 URI,請執行下列程式碼。 在傳回的資料中,尋找 scoring_uri 屬性。
endpoint = ml_client.online_endpoints.get(endpoint_name, local=True)
scoring_uri = endpoint.scoring_uri
工作室不支援本機端點。 如需在本機測試端點的步驟,請參閱 Azure CLI 或 Python 索引標籤。
範本不支援本機端點。 如需在本機測試端點的步驟,請參閱 Azure CLI 或 Python 索引標籤。
檢閱記錄以取得叫用作業的輸出
在範例 score.py 檔案中,run() 方法會將某些輸出記錄至主控台。
您可以使用 get-logs 命令來檢視此輸出:
az ml online-deployment get-logs --local -n blue --endpoint $ENDPOINT_NAME
您可以使用 get_logs 方法來檢視此輸出:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, local=True, lines=50
)
工作室不支援本機端點。 如需在本機測試端點的步驟,請參閱 Azure CLI 或 Python 索引標籤。
範本不支援本機端點。 如需在本機測試端點的步驟,請參閱 Azure CLI 或 Python 索引標籤。
將線上端點部署至 Azure
接下來,將線上端點部署至 Azure。 作為生產環境的最佳做法,建議您註冊部署中使用的模型和環境。
登錄模型和環境
我們建議先登錄模型和環境再部署至 Azure,以便在部署期間指定已登錄的名稱與版本。 註冊資產之後,您不需要在每次建立部署時上傳資產,就可以重複使用它們。 這種做法會增加重現性和可追蹤性。
與部署至 Azure 不同,本機部署不支援使用已登錄的模型與環境。 相反地,本機部署會使用本機模型檔案,並只使用具有本機檔案的環境。
若要部署至 Azure,您可以使用本機或已登錄的資產 (模型與環境)。 在本文中,此節將利用已註冊的資產部署至 Azure,但您也能選擇使用本機資產。 如需有關可上傳本機檔案,以進行本機部署的部署設定範例,請參閱設定部署。
若要登錄模型和環境,請使用 model: azureml:my-model:1 或 environment: azureml:my-env:1 格式。
若要註冊,您可以將 和 model 的 environment YAML 定義擷取至 endpoints/online/managed/sample 資料夾中的個別 YAML 檔案,並使用 命令az ml model create和 az ml environment create。 如要深入瞭解這些命令,請執行 az ml model create -h 和 az ml environment create -h。
建立模型的 YAML 定義。 將檔案命名 為model.yml:
$schema: https://azuremlschemas.azureedge.net/latest/model.schema.json
name: my-model
path: ../../model-1/model/
註冊模型:
az ml model create -n my-model -v 1 -f endpoints/online/managed/sample/model.yml
建立環境的 YAML 定義。 將檔案命名 為environment.yml:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: my-env
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
conda_file: ../../model-1/environment/conda.yaml
登錄環境:
az ml environment create -n my-env -v 1 -f endpoints/online/managed/sample/environment.yml
如需如何將模型註冊為資產的詳細資訊,請參閱 使用 Azure CLI 或 Python SDK 註冊模型。 如需建立環境的詳細資訊,請參閱 建立自定義環境。
註冊模型:
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
file_model = Model(
path="../model-1/model/",
type=AssetTypes.CUSTOM_MODEL,
name="my-model",
description="Model created from local file.",
)
ml_client.models.create_or_update(file_model)
登錄環境:
from azure.ai.ml.entities import Environment
env_docker_conda = Environment(
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file="../model-1/environment/conda.yaml",
name="my-env",
description="Environment created from a Docker image plus Conda environment.",
)
ml_client.environments.create_or_update(env_docker_conda)
若要瞭解如何將模型註冊為資產,以便您可以在部署期間指定其已註冊的名稱和版本,請參閱 使用 Azure CLI 或 Python SDK 註冊模型。
如需建立環境的詳細資訊,請參閱 建立自定義環境。
註冊模型
模型註冊是工作區中可能包含單一模型檔案的邏輯實體,或是多個檔案的目錄。 作為用於生產使用的最佳做法,請註冊模型和運行環境。 在本文中建立端點和部署之前,請先註冊包含 模型的模型資料夾 。
若要註冊範例模型,請遵循下列步驟:
移至 [Azure Machine Learning 工作室]。
在左窗格中,選取 [ 模型] 頁面。
選取 [註冊],然後選擇 [從本機檔案]。
針對 [模型類型] 選取 [未指定類型]。
選取 [瀏覽],然後選擇 [瀏覽資料夾]。

從您稍早複製或下載的存放庫本機複本中,選取 \azureml-examples\cli\endpoints\online\model-1\model 資料夾。 出現提示時,請選取 [ 上傳 ],並等候上傳完成。
選取 下一步。
輸入模型的友善名稱。 本文中的步驟假設模型名為 model-1。
選取 [下一步],然後選取 [ 註冊 ] 以完成註冊。
如需如何使用已註冊模型的詳細資訊,請參閱 使用已註冊的模型。
建立並登錄環境
在左窗格中,選取 [ 環境] 頁面。
選取 [ 自定義環境] 索引標籤,然後選擇 [ 建立]。
在 設定 頁面上,輸入名稱,例如為環境輸入 my-env。
針對 [選取環境來源],選擇 [使用現有的 Docker 映像搭配選用的 Conda 來源]。

選取 [下一步 ] 以移至 [自定義 ] 頁面。
從您稍早複製或下載的存放庫複製 \azureml-examples\cli\endpoints\online\model-1\environment\conda.yaml 檔案的內容。
將內容貼到文字輸入框中。

選取 [下一步 ],直到您進入 [ 建立 ] 頁面,然後選取 [ 建立]。
如需如何在 Studio 中建立環境的詳細資訊,請參閱 建立環境。
若要使用範本註冊模型,您必須先將模型檔案上傳至 Blob 記憶體。 下列範例會使用 az storage blob upload-batch 命令將檔案上傳至工作區的預設儲存體:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/model -s cli/endpoints/online/model-1/model --account-name $AZURE_STORAGE_ACCOUNT
上傳檔案之後,請使用範本來建立模型註冊。 在下列範例中,modelUri 參數包含模型的路徑:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/model-version.json \
--parameters \
workspaceName=$WORKSPACE \
modelAssetName="sklearn" \
modelUri="azureml://subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/workspaces/$WORKSPACE/datastores/$AZUREML_DEFAULT_DATASTORE/paths/model/sklearn_regression_model.pkl"
環境的一部分是 conda 檔案,可指定裝載模型所需的模型相依性。 下列範例示範如何將 conda 檔案的內容讀到環境變數內:
CONDA_FILE=$(cat cli/endpoints/online/model-1/environment/conda.yaml)
下列範例示範如何使用範本來註冊環境。 來自上一個步驟的 conda 檔案內容會使用 condaFile 參數傳遞至範本:
ENV_VERSION=$RANDOM
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/environment-version.json \
--parameters \
workspaceName=$WORKSPACE \
environmentAssetName=sklearn-env \
environmentAssetVersion=$ENV_VERSION \
dockerImage=mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20210727.v1 \
condaFile="$CONDA_FILE"
重要事項
當您定義部署的自定義環境時,請確定 azureml-inference-server-http 套件包含在 conda 檔案中。 此套件對於推斷伺服器正常運作至關重要。 如果您不熟悉如何建立自己的自定義環境,請使用我們的其中一個策劃環境,例如 minimal-py-inference (針對不使用 mlflow的自定義模型)或 mlflow-py-inference (適用於使用 mlflow的模型)。 您可以在 Azure Machine Learning Studio 實例的 [ 環境 ] 索引標籤上找到這些策展環境。
您的部署組態會使用您想要部署的已註冊模型和已註冊的環境。
在部署定義中使用已登錄的資產 (模型和環境)。 下列程式碼片段展示 endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml 檔案,其中包含設定部署所需的所有輸入:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:my-model:1
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment: azureml:my-env:1
instance_type: Standard_DS3_v2
instance_count: 1
若要設定部署,請使用已登錄的模型和環境:
model = "azureml:my-model:1"
env = "azureml:my-env:1"
blue_deployment_with_registered_assets = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
從工作室進行部署,您會建立端點以及要新增至該端點的部署。 此時,系統會提示您輸入端點和部署的名稱。
使用不同的 CPU 和 GPU 執行個體類型和映像
您可以在部署定義中,向本機部署和針對 Azure 的部署指定 CPU 或 GPU 執行個體類型和映像。
您在 blue-deployment-with-registered-assets.yml 檔案中的部署定義使用了一般用途型的 Standard_DS3_v2 實例和無 GPU 的 Docker 映像 mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest。 針對 GPU 計算,請選擇 GPU 計算類型版本和 GPU Docker 映像。
如需支援的一般用途和 GPU 實例類型,請參閱 受控在線端點 SKU 清單。 如需 Azure Machine Learning CPU 和 GPU 基礎映像的清單,請參閱Azure Machine Learning 基礎映像 (英文)。
您可以在部署設定中,向本機部署與針對 Azure 的部署指定 CPU 或 GPU 執行個體類型與映像。
稍早,您已設定了部署,且其使用一般用途類型 Standard_DS3_v2 執行個體和非 GPU Docker 映像 mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest。 針對 GPU 計算,請選擇 GPU 計算類型版本和 GPU Docker 映像。
如需支援的一般用途和 GPU 實例類型,請參閱 受控在線端點 SKU 清單。 如需 Azure Machine Learning CPU 和 GPU 基礎映像的清單,請參閱Azure Machine Learning 基礎映像 (英文)。
環境先前的註冊會使用 mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04 參數,將 值傳遞至 environment-version.json 範本,以指定非 GPU Docker 映射dockerImage。 針對 GPU 計算,將 GPU Docker 映像的值提供給範本(使用 dockerImage 參數),並將 GPU 計算類型版本 online-endpoint-deployment.json 提供給範本(使用 skuName 參數)。
如需支援的一般用途和 GPU 實例類型,請參閱 受控在線端點 SKU 清單。 如需 Azure Machine Learning CPU 和 GPU 基礎映像的清單,請參閱Azure Machine Learning 基礎映像 (英文)。
接下來,將線上端點部署至 Azure。
部署至 Azure
在 Azure 雲端中建立端點:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
在端點下建立名為 blue 的部署:
az ml online-deployment create --name blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml --all-traffic
建立部署可能需要最多約 15 分鐘的時間,視基礎環境或映像是否為第一次建置而定。 後續若使用相同環境進行部署,將會更快完成。
若您不想封鎖 CLI 主控台,可將旗標 --no-wait 新增至命令。 不過,此選項會停止部署狀態的互動式顯示。
用於建立部署之程式碼 --all-traffic 中的 az ml online-deployment create 旗標,會將 100% 的端點流量配置到新建立的藍色部署。 使用此選項有助於開發和測試目的,但針對生產環境,您可能想要透過具體指令將流量路由至新的部署。 例如,使用 az ml online-endpoint update -n $ENDPOINT_NAME --traffic "blue=100"。
建立端點:
藉由使用 endpoint 您稍早定義的 參數和 MLClient 您稍早建立的參數,您現在可以在工作區中建立端點。 此命令會啟動端點建立,並在端點建立繼續時傳回確認回應。
ml_client.online_endpoints.begin_create_or_update(endpoint)
建立部署:
藉由使用您先前定義的 blue_deployment_with_registered_assets 參數和您先前建立的 MLClient 參數,您現在可以在工作區中進行部署。 此命令會啟動部署建立,並在部署建立繼續時傳回確認回應。
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
若您不想封鎖 Python 主控台,則可將旗標 no_wait=True 新增至參數。 不過,此選項會停止部署狀態的互動式顯示。
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint)
建立受控線上端點和部署
使用工作室直接在瀏覽器中建立受控線上端點。 在工作室建立受控線上端點時,您必須定義初始部署。 您無法建立空的受控線上端點。
在工作室中建立受控線上端點的其中一種方式是從 [模型] 頁面。 此方法也提供將模型新增至現有受控線上部署的簡單方法。 若要部署先前在model-1一節中所登錄,且名為 的模型,您必須:
移至 [Azure Machine Learning 工作室]。
在左窗格中,選取 [ 模型] 頁面。
選取名為 model-1的模型。
選取 [部署]>[即時端點]。
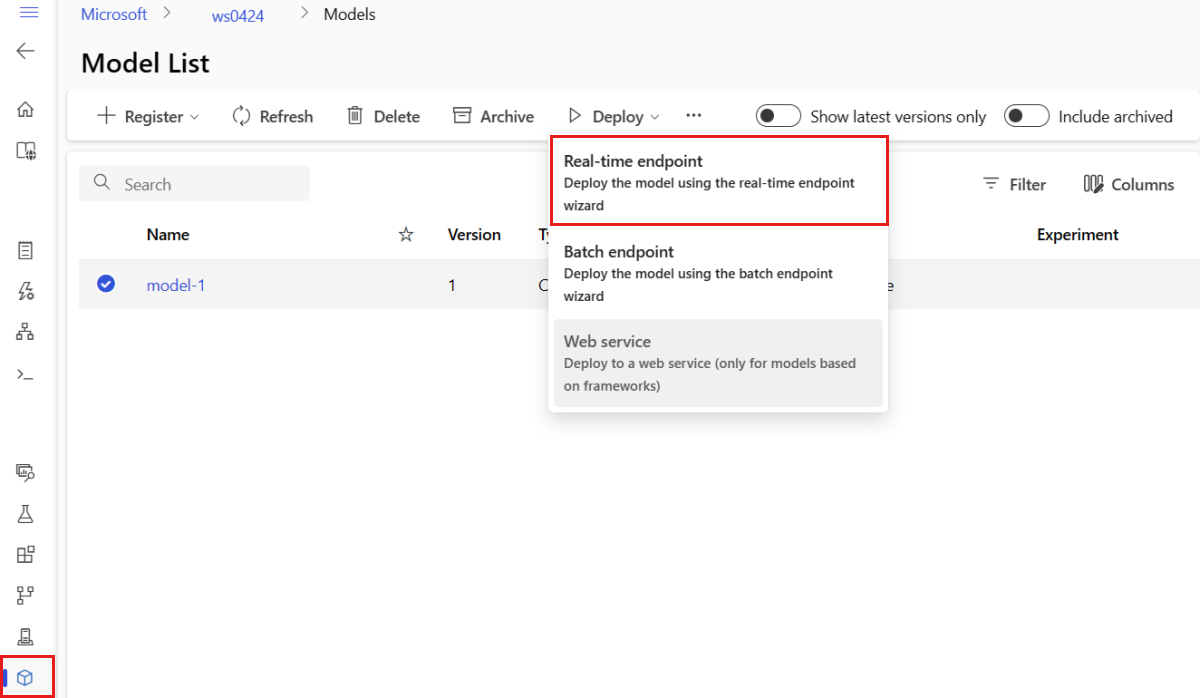
此動作會開啟一個視窗,您可以在其中指定端點的詳細資料。
輸入 Azure 區域中唯一的端點名稱。 如需命名規則的詳細資訊,請參閱 端點限制。
針對計算類型,保留預設的選取項目 [受控]。
針對驗證類型,保留預設的選取項目 [金鑰型驗證]。 如需驗證的詳細資訊,請參閱驗證線上端點的用戶端。
選取 [下一步 ],直到您進入 [部署] 頁面。 將 Application Insights 診斷 切換為 [已啟用] ,以便稍後在 Studio 中檢視端點活動的圖表,並使用 Application Insights 分析計量和記錄。
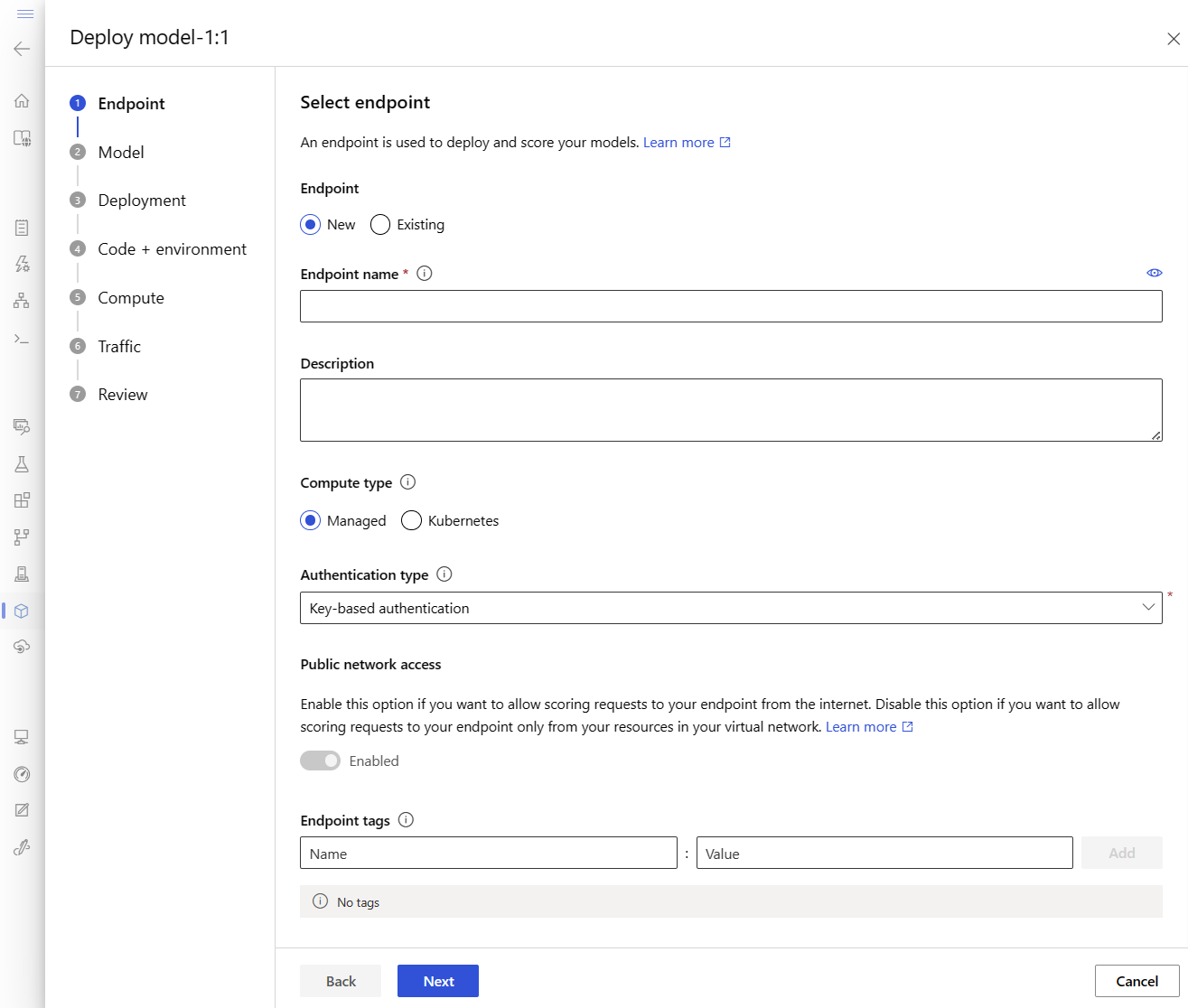
選取 [下一步] 以移至 [程式碼 + 環境] 頁面。 選取下列選項:
-
選取評分腳本以進行推斷:流覽,然後從您稍早複製或下載的存放庫選取 \azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py 檔案。
-
[選取環境] 區段:選取 [自訂環境],接著選取先前所建立的 my-env:1 環境。
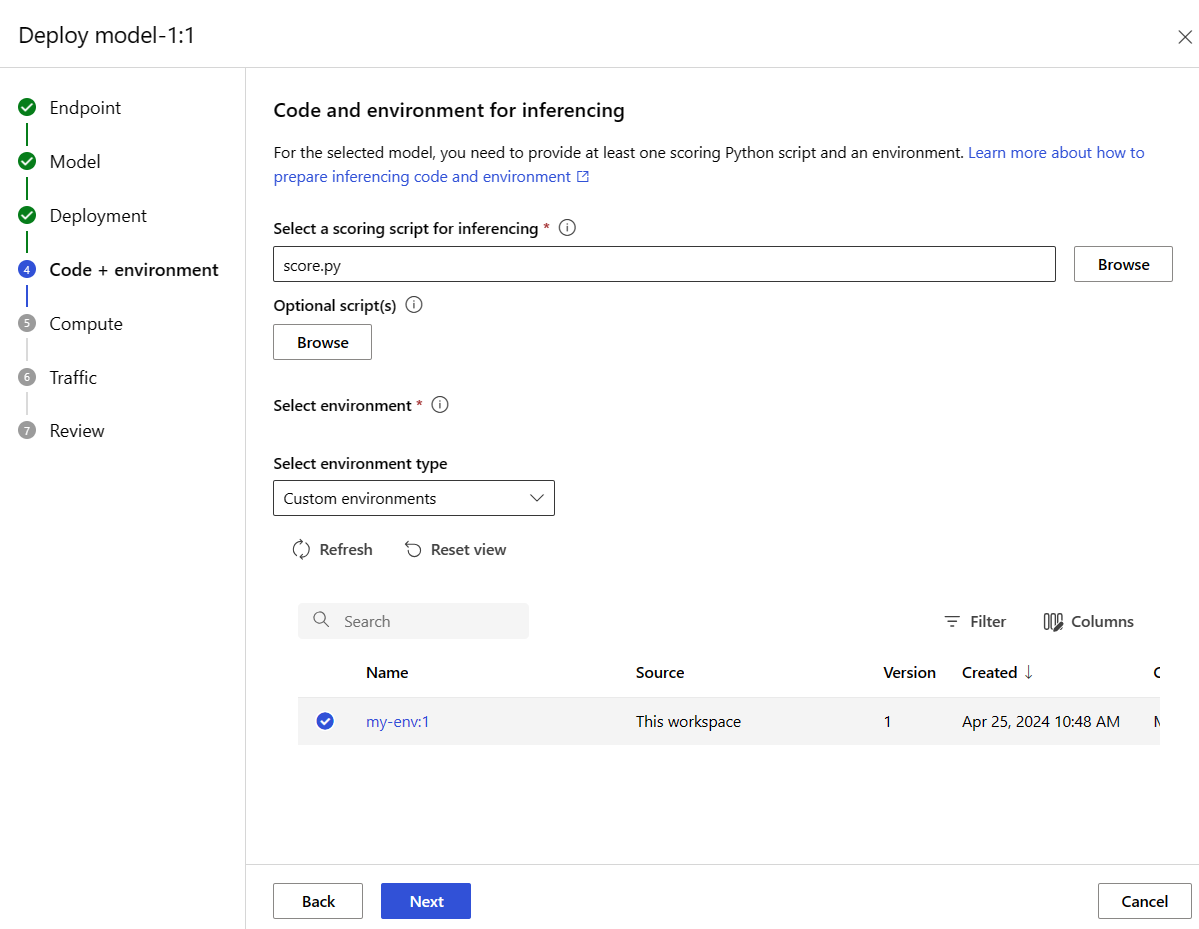
選取 [下一步],並接受預設值,直到系統提示您建立部署為止。
檢閱您的部署設定,然後選取 [ 建立]。
或者,您也可以從工作室中的 [端點] 頁面建立受控線上端點。
移至 [Azure Machine Learning 工作室]。
在左窗格中,選取 [端點頁面]。
選取 [+ 建立]。
![顯示從 [端點] 索引標籤建立受控在線端點的螢幕快照。](media/how-to-deploy-online-endpoints/endpoint-create-managed-online-endpoint.png?view=azureml-api-2)
此動作會開啟視窗,供您選取模型,並指定端點和部署的詳細資料。 輸入您端點和部署的設定,如先前所述,然後選取 [ 建立 ] 以建立部署。
使用範本以建立線上端點:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint.json \
--parameters \
workspaceName=$WORKSPACE \
onlineEndpointName=$ENDPOINT_NAME \
identityType=SystemAssigned \
authMode=AMLToken \
location=$LOCATION
建立端點之後,將模型部署至端點:
resourceScope="/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices"
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint-deployment.json \
--parameters \
workspaceName=$WORKSPACE \
location=$LOCATION \
onlineEndpointName=$ENDPOINT_NAME \
onlineDeploymentName=blue \
codeId="$resourceScope/workspaces/$WORKSPACE/codes/score-sklearn/versions/1" \
scoringScript=score.py \
environmentId="$resourceScope/workspaces/$WORKSPACE/environments/sklearn-env/versions/$ENV_VERSION" \
model="$resourceScope/workspaces/$WORKSPACE/models/sklearn/versions/1" \
endpointComputeType=Managed \
skuName=Standard_F2s_v2 \
skuCapacity=1
若要針對部署中的錯誤進行偵錯,請參閱疑難排解線上端點部署。
檢查在線端點的狀態
使用 show 命令,在 provisioning_state 中顯示端點與部署的資訊:
az ml online-endpoint show -n $ENDPOINT_NAME
使用 list 命令,以資料表格式列出工作區中的所有端點:
az ml online-endpoint list --output table
檢查端點狀態,查看是否已部署模型,且未發生錯誤:
ml_client.online_endpoints.get(name=endpoint_name)
使用 list 方法,以資料表格式列出工作區中的所有端點:
for endpoint in ml_client.online_endpoints.list():
print(endpoint.name)
此方法會傳回 ManagedOnlineEndpoint 實體的清單 (迭代器)。
您可以藉由指定更多參數來取得其他資訊。 例如,輸出類似資料表的端點清單:
print("Kind\tLocation\tName")
print("-------\t----------\t------------------------")
for endpoint in ml_client.online_endpoints.list():
print(f"{endpoint.kind}\t{endpoint.location}\t{endpoint.name}")
檢視受控線上端點
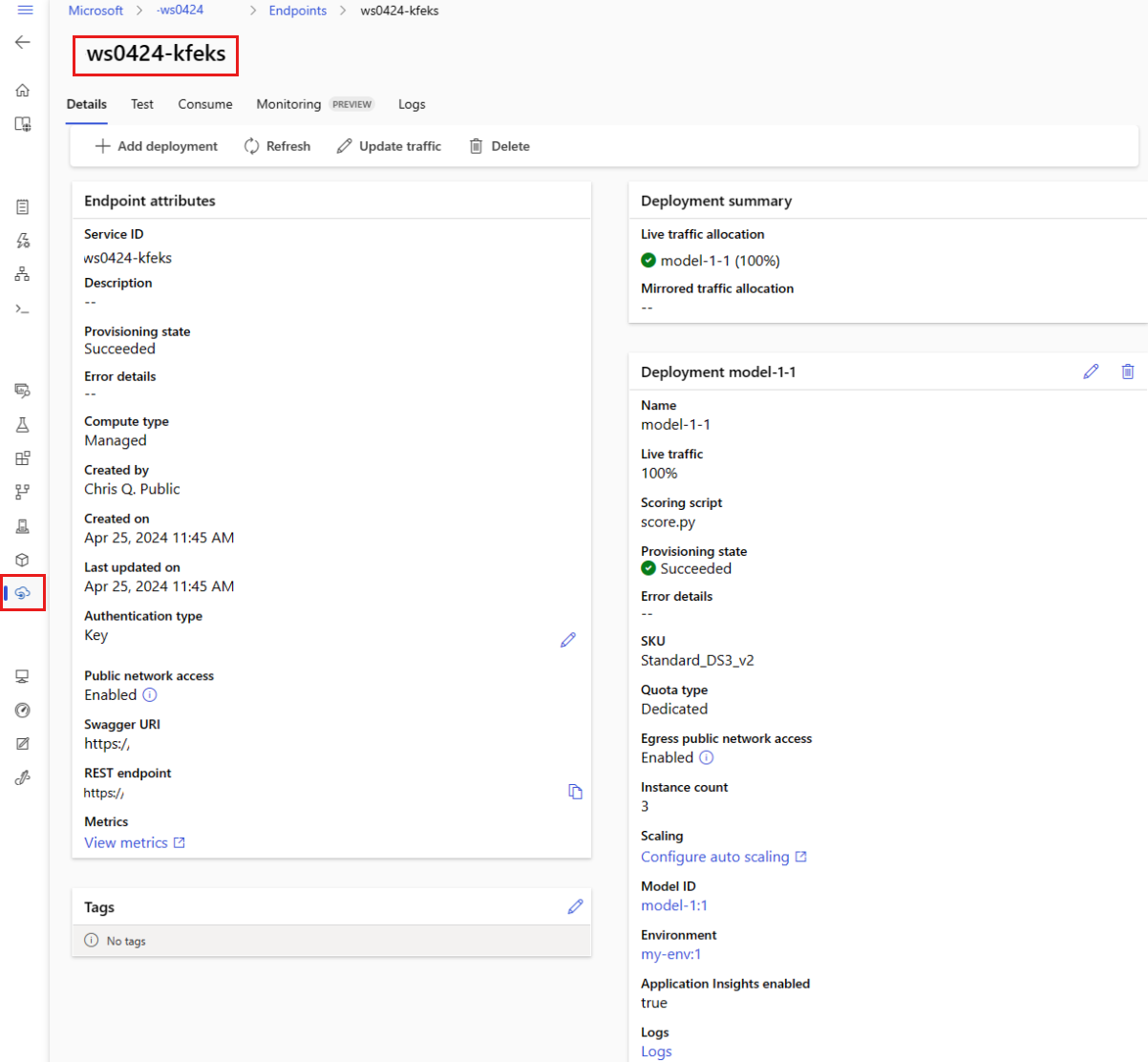
您可以在 [ 端點 ] 頁面上檢視所有受控在線端點。 移至端點的 [詳細數據] 頁面以尋找重要資訊,例如端點 URI、狀態、測試工具、活動監視器、部署記錄,以及範例取用程式代碼。
在左窗格中,選取 [ 端點 ] 以查看工作區中所有端點的清單。
(選擇性)在 計算類型 上建立篩選,只顯示 Managed 計算類型。
選取端點名稱以檢視端點的 [詳細資料] 頁面。
範本對於部署資源很有用,但您無法使用它們來列出、顯示或叫用資源。 使用 Azure CLI、Python SDK 或工作室來執行這些作業。 下列程式碼使用 Azure CLI。
使用 show 命令,在 provisioning_state 參數中顯示端點與部署的資訊:
az ml online-endpoint show -n $ENDPOINT_NAME
使用 list 命令,以資料表格式列出工作區中的所有端點:
az ml online-endpoint list --output table
檢查線上部署的狀態
檢查記錄查看是否已部署模型,且未發生錯誤。
若要查看容器的記錄輸出,請使用下列 CLI 命令:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
根據預設,系統會從推斷伺服器容器中提取記錄。 若要查看儲存體初始設定式容器中的記錄,請新增 --container storage-initializer 旗標。 如需部署記錄的詳細資訊,請參閱取得容器記錄。
您可以使用 get_logs 方法來檢視記錄輸出:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
根據預設,系統會從推斷伺服器容器中提取記錄。 若要查看儲存體初始設定式容器中的記錄,請新增 container_type="storage-initializer" 選項。 如需部署記錄的詳細資訊,請參閱取得容器記錄。
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50, container_type="storage-initializer"
)
若要檢視記錄輸出,請在端點頁面中選取 [記錄] 索引標籤。 如果您在端點中有多個部署,請使用下拉式清單來選取您想要查看記錄的部署。
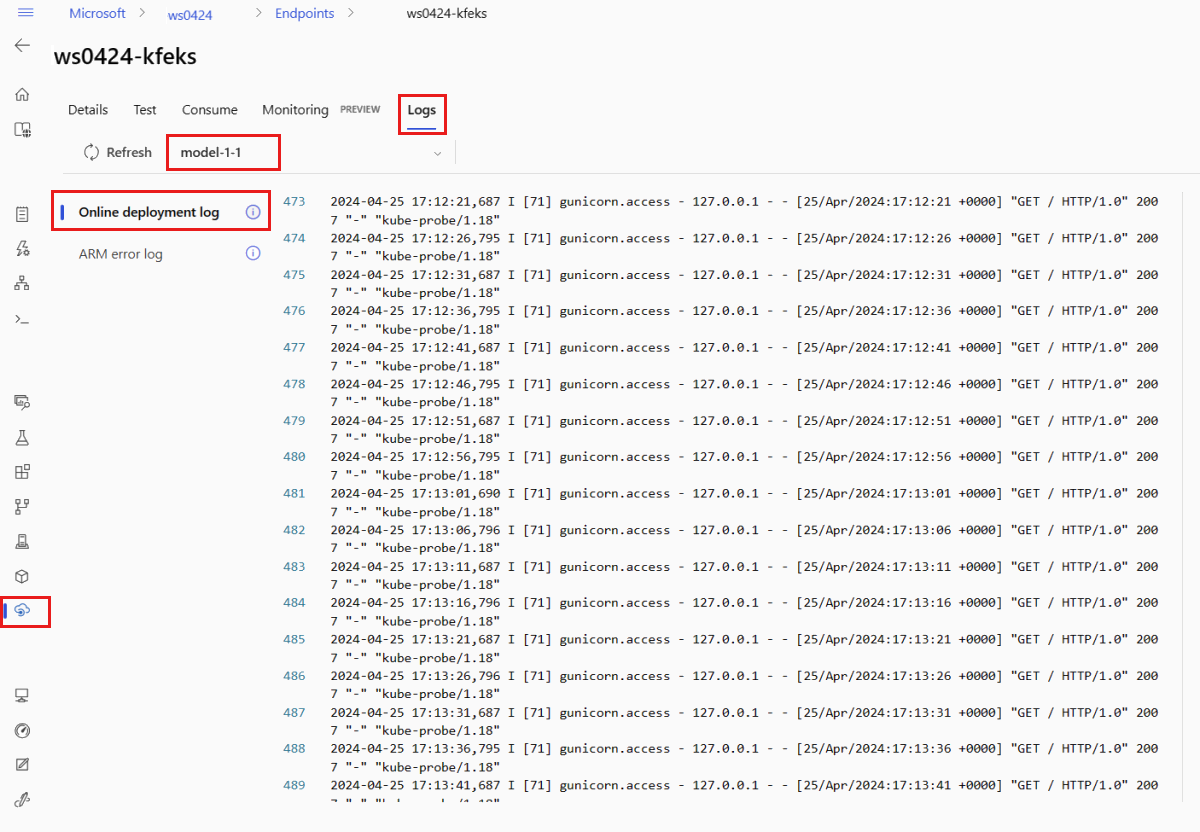
根據預設,系統會從推斷伺服器中提取記錄。 若要查看儲存體初始設定式容器中的記錄,請使用 Azure CLI 或 Python SDK (請查看各個索引標籤以取得詳細資訊)。 儲存體初始設定式容器中的記錄會提供是否已成功將程式碼和模型資料下載至容器的資訊。 如需部署記錄的詳細資訊,請參閱取得容器記錄。
範本對於部署資源很有用,但您無法使用它們來列出、顯示或叫用資源。 使用 Azure CLI、Python SDK 或工作室來執行這些作業。 下列程式碼使用 Azure CLI。
若要查看容器的記錄輸出,請使用下列 CLI 命令:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
根據預設,系統會從推斷伺服器容器中提取記錄。 若要查看儲存體初始設定式容器中的記錄,請新增 --container storage-initializer 旗標。 如需部署記錄的詳細資訊,請參閱取得容器記錄。
使用模型叫用端點以評分資料
使用 invoke 命令或您所選的 REST 用戶端,來叫用端點並為部分資料評分:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
取得用來驗證端點的金鑰:
您可以將 Microsoft Entra 安全性主體指派給允許 Microsoft.MachineLearningServices/workspaces/onlineEndpoints/token/action 和 Microsoft.MachineLearningServices/workspaces/onlineEndpoints/listkeys/action 的自訂角色,藉以控制哪些主體可取得驗證金鑰。 如需如何管理工作區授權的詳細資訊,請參閱 管理 Azure Machine Learning 工作區的存取權。
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n $ENDPOINT_NAME -o tsv --query primaryKey)
使用 curl 來為資料評分。
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @endpoints/online/model-1/sample-request.json
請注意,您使用 show 和 get-credentials 命令來取得驗證認證。 另請注意,您會使用 --query 旗標只篩選所需的屬性。 如要深入瞭解 --query 旗標,請參閱查詢 Azure CLI 命令輸出。
如要查看叫用記錄,請再次執行 get-logs。
透過使用您稍早建立的 MLClient 參數,即可取得端點的控制。 接著,您可以使用 invoke 命令,搭配下列參數來叫用端點:
-
endpoint_name:端點的名稱。
-
request_file:具有要求數據的檔案。
-
deployment_name:要在端點中測試的特定部署名稱。
使用 JSON 檔案傳送範例要求。
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
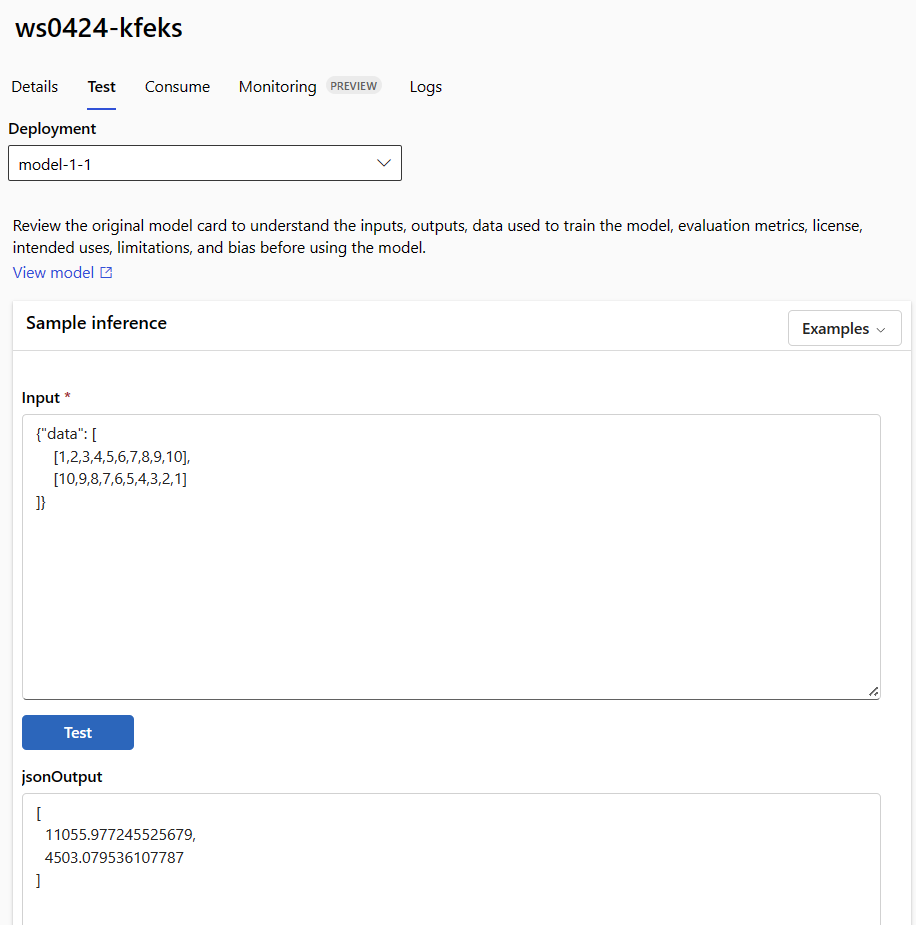
使用端點詳細數據頁面上的 [ 測試 ] 索引標籤來測試受控在線部署。 輸入樣本輸入並檢視結果。
選取端點詳細數據頁面上的 [ 測試 ] 索引標籤。
使用下拉式清單選取您要測試的部署。
輸入樣本輸入。
選取 [測試]。
範本對於部署資源很有用,但您無法使用它們來列出、顯示或叫用資源。 使用 Azure CLI、Python SDK 或工作室來執行這些作業。 下列程式碼使用 Azure CLI。
使用 invoke 命令或您所選的 REST 用戶端,來叫用端點並為部分資料評分:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file cli/endpoints/online/model-1/sample-request.json
(選擇性) 更新部署
如果您想要更新程序代碼、模型或環境,請更新 YAML 檔案。 然後執行 az ml online-endpoint update 命令。
如果您在單 update 一命令中更新實例計數(以調整部署規模),以及其他模型設定(例如程序代碼、模型或環境),則會先執行調整作業。 接下來會套用其他更新。 在生產環境中,最好是個別執行這些作業。
瞭解 update 如何運作:
開啟 online/model-1/onlinescoring/score.py 檔案。
變更 init() 函式的最後一行:在 logging.info("Init complete") 後方新增 logging.info("Updated successfully")。
儲存檔案。
請執行這個命令:
az ml online-deployment update -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml
使用 YAML 進行更新為宣告式。 也就是說,YAML 中的變更會反映在基礎 Resource Manager 資源 (端點和部署) 中。 宣告式方法可輔助 GitOps:所有的端點與部署變更 (甚至是 instance_count)皆會經過 YAML。
您可以搭配使用泛型更新參數 (例如 --set 參數) 與 CLI update 命令,來覆寫 YAML 中的屬性,或設定特定屬性,而不需要在 YAML 檔案中傳遞這些屬性。 在開發和測試案例中,針對單一屬性使用 --set 特別有用。 例如,若要擴大第一個部署的 instance_count 值,您可以使用 --set instance_count=2 旗標。 不過,由於 YAML 並未更新,此技巧無法輔助 GitOps。
指定 YAML 檔案 不是 必須的。 例如,如果您要針對特定部署測試不同的並行設定,您可以嘗試類似 az ml online-deployment update -n blue -e my-endpoint --set request_settings.max_concurrent_requests_per_instance=4 environment_variables.WORKER_COUNT=4。 此方法會保留所有現有的組態,但只會更新指定的參數。
因為您修改了 init() 在建立或更新端點時執行的函式,因此訊息 Updated successfully 會出現在記錄中。 藉由執行下列動作來擷取記錄:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
此 update 命令亦適用於本機部署。 使用相同的 az ml online-deployment update 命令搭配 --local 旗標。
如果您想要更新程序代碼、模型或環境,請更新組態,然後執行 MLClient的 online_deployments.begin_create_or_update 方法來 建立或更新部署。
如果您在單 begin_create_or_update 一方法中更新實例計數(以調整部署規模),以及其他模型設定(例如程序代碼、模型或環境),則會先執行調整作業。 接下來會套用其他更新。 在生產環境中,最好是個別執行這些作業。
瞭解 begin_create_or_update 如何運作:
開啟 online/model-1/onlinescoring/score.py 檔案。
變更 init() 函式的最後一行:在 logging.info("Init complete") 後方新增 logging.info("Updated successfully")。
儲存檔案。
執行方法:
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
因為您修改了 init() 在建立或更新端點時執行的函式,因此訊息 Updated successfully 會出現在記錄中。 藉由執行下列動作來擷取記錄:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
begin_create_or_update 方法亦適用於本機部署。 使用相同的方法搭配 local=True 旗標。
目前,您只能對部署的實例計數進行更新。 根據下列指示,調整執行個體的數目來擴大或縮小個別部署:
- 開啟端點的 [詳細資料] 頁面,並尋找所要更新部署的卡片。
- 選取部署名稱旁的編輯圖示 (鉛筆圖示)。
- 更新與部署相關聯的執行個體計數。 選擇 預設 或 目標使用率 作為 部署規模類型。
- 如果您選取 [預設值],您也可以指定 實例計數的數值。
- 如果您選取 [ 目標使用率],您可以在自動調整部署時指定要用於參數的值。
- 選取 [更新] 以完成部署的執行個體計數更新。
附註
本節中的部署更新是就地輪流更新的範例。
- 針對受控線上端點,部署一次會將 20% 的節點更新為新的設定。 也就是說,若部署有 10 個節點,則一次只會更新 2 個節點。
- 針對 Kubernetes 線上端點,系統會使用新的設定逐一建立新部署執行個體,並刪除舊的部署執行個體。
- 針對生產環境的使用方式,請考慮藍綠部署,其為更新 Web 服務提供了更安全的替代方案。
自動調整會自動執行正確的資源量,以處理應用程式的負載。 受控線上端點透過與 Azure 監視器自動調整功能的整合,支援自動調整。 若要設定自動調整,請參閱自動調整線上端點。
(選擇性) 使用 Azure 監視器監視 SLA
若要根據 SLA 檢視計量和設定警示,請遵循 監視在線端點中所述的步驟。
(選擇性) 與記錄分析整合
get-logs CLI 的命令或 get_logs SDK 的 方法只提供自動選取實例的最後幾百行記錄。 不過,記錄分析會提供一種方式來永久儲存和分析記錄。 如需如何使用記錄的詳細資訊,請參閱 使用記錄。
刪除端點和部署
使用下列命令來移除端點及其所有基礎部署:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
使用下列命令來移除端點及其所有基礎部署:
ml_client.online_endpoints.begin_delete(name=endpoint_name)
使用下列命令來移除端點及其所有基礎部署:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
相關內容






![顯示從 [端點] 索引標籤建立受控在線端點的螢幕快照。](media/how-to-deploy-online-endpoints/endpoint-create-managed-online-endpoint.png?view=azureml-api-2#lightbox)


