使用 Apache Spark 分析資料
在本教學課程中,您將瞭解如何使用 Azure 開放資料集和 Apache Spark 來執行探索式資料分析。 然後,您可以在 Azure Synapse Analytics 的 Synapse Studio 筆記本中將結果視覺化。
具體而言,我們將分析紐約市 (NYC) 計程車資料集。 您可以透過 Azure 開放資料集取得資料。 此資料集的子集包含黃色計程車行程的相關資訊:每趟行程的相關資訊、開始和結束時間及位置、成本和其他有趣的屬性。
開始之前
依照建立 Apache Spark 集區教學課程中的指示,建立 Apache Spark 集區。
下載並準備資料
使用 PySpark 核心建立筆記本。 如需相關指示,請參閱 建立筆記本。
注意
由於使用 PySpark 核心,因此不需要明確建立任何內容。 當您執行第一個程式碼儲存格時,系統會自動為您建立 Spark 內容。
在本教學課程中,我們將使用數個不同的程式庫,協助我們將資料集視覺化。 若要進行這項分析,請匯入下列程式庫:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd因為未經處理的資料採用 Parquet 格式,所以您可以使用 Spark 內容,直接將檔案當作資料框架提取至記憶體中。 透過開放資料集 API 擷取資料,以建立 Spark 資料框架。 在此,我們使用 Spark 資料框架「讀取時的結構描述」屬性,來推斷資料類型和結構描述。
from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())讀取資料後,我們要進行一些初始篩選以清理資料集。 我們可能會移除不必要的資料行,並新增可擷取重要資訊的資料行。 此外,我們也會篩選出資料集內的異常狀況。
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
分析資料
身為資料分析師的您,擁有各式各樣的工具可協助您從資料中擷取見解。 在本教學課程的這部分,我們將逐步解說 Azure Synapse Analytics 筆記本中可用的一些實用工具。 在這項分析中,我們想瞭解在我們選取的期間內,產生較高計程車小費的因素。
Apache Spark SQL Magic
首先,我們將使用 Azure Synapse 筆記本的 Apache Spark SQL 和 magic 命令來執行探索式資料分析。 在查詢完成之後,我們將使用內建 chart options 功能將結果視覺化。
在筆記本中建立新的資料格,並複製下列程式碼。 藉由此查詢,我們想瞭解在我們選取的期間內,平均的小費金額如何變動。 此查詢也可協助我們識別其他有用的見解,包括每天最少/最多的小費金額和平均車資金額。
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASC當完成查詢之後,我們就可以切換到圖表檢視將結果視覺化。 此範例藉由將
day_of_month欄位指定為索引碼和將avgTipAmount指定為值來建立折線圖。 完成選取之後,請選取 [套用] 以重新整理圖表。
顯現資料
除了內建的筆記本圖表選項外,您還可以使用常用的開放原始碼程式庫來建立自己的視覺效果。 在下列範例中,我們將使用 Seaborn 和 Matplotlib。 這些通常是用於資料視覺化的 Python 程式庫。
注意
根據預設,Azure Synapse Analytics 中的每個 Apache Spark 集區都包含一組常用和預設的程式庫。 您可以在Azure Synapse 執行階段文件中檢視程式庫的完整清單。 此外,若要讓您的應用程式可以使用協力廠商或本機建置的程式碼,可以安裝程式庫到您其中一個 Spark 集區。
為了讓開發變得更容易且成本更低,我們會縮小資料集取樣。 我們將使用內建的 Apache Spark 取樣功能。 此外,Seaborn 和 Matplotlib 都需要 Pandas 資料框架或 NumPy 陣列。 若要取得 Pandas 資料框架,請使用
toPandas()命令來轉換資料框架。# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()我們想瞭解資料集中的小費分佈狀況。 我們將使用 Matplotlib 來建立長條圖,以顯示小費金額和數量的分佈狀況。 根據分佈狀況,我們可以看到小費朝著金額小於或等於 $10 傾斜。
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()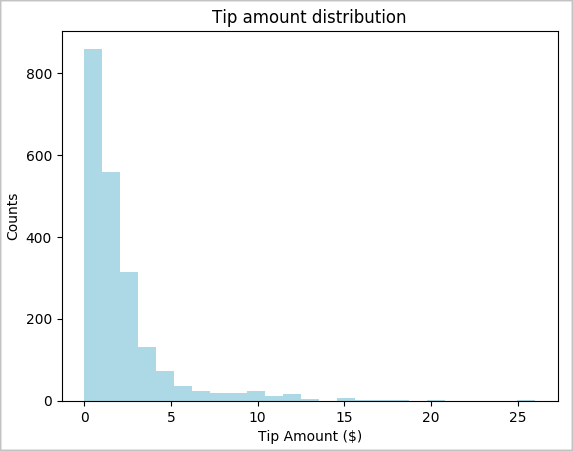
接下來,我們想瞭解指定行程的小費與日期 (星期幾) 之間的關聯性。 使用 Seaborn 建立一個盒狀圖,以摘要說明一周間每天的趨勢。
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()
我們的另一個假設是,乘客數目與計程車小費總金額之間可能有正面的關聯性。 若要確認此關聯性,請執行下列程式碼來產生箱型圖,以說明每位乘客技術的小費金額分佈狀況。
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()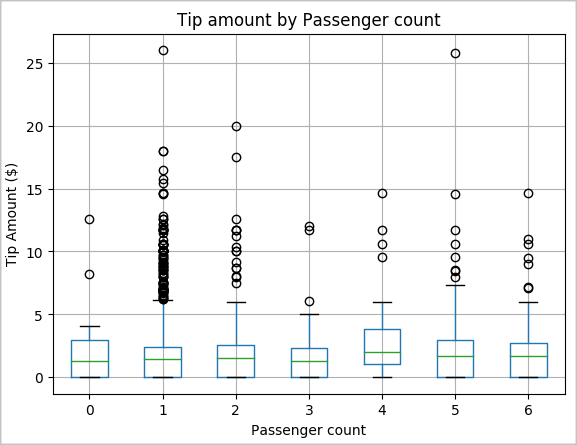
最後,我們想瞭解車資金額與小費金額之間的關聯性。 根據結果,我們可以看到有些人不給小費的幾項觀察。 不過,我們也會看到整體車資金額和小費金額之間有正面的關聯性。
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()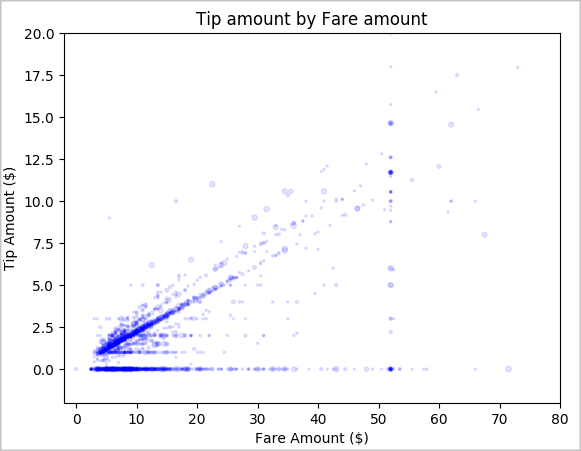
關閉 Spark 執行個體
應用程式執行完畢之後,請關閉筆記本以釋放資源。 您可以選擇關閉索引標籤,或從筆記本底部的狀態列中選取 [結束工作階段]。
另請參閱
後續步驟
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應