Apache Spark 是一個平行處理架構,可支援記憶體內部處理,以大幅提升巨量資料分析應用程式的效能。 Azure Synapse Analytics 中的 Apache Spark 是 Microsoft 在雲端中的其中一種 Apache Spark 實作。 Azure Synapse 可讓您輕鬆地在 Azure 中建立和設定無伺服器 Apache Spark 集區。 Azure Synapse 中的 Spark 集區與 Azure 儲存體和 Azure Data Lake Generation 2 Storage 相容。 因此,您可以使用 Spark 集區來處理儲存於 Azure 的資料。
什麼是 Apache Spark
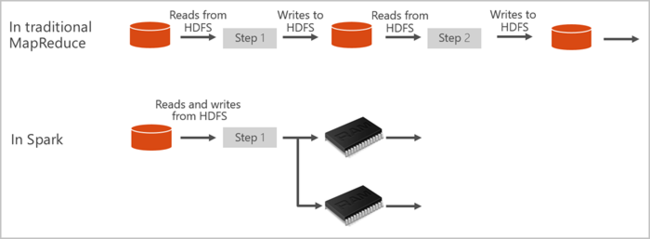
Apache Spark 提供用於記憶體內部叢集運算的基本項目。 Spark 作業可將資料載入並快取到記憶體,以便重複查詢。 記憶體內部運算比以磁碟為基礎的應用程式更快。 Spark 也會與多種程式設計語言整合,讓您處理分散式資料集 (像是本機集合)。 您不需要將一切建構成對應和縮減作業。 您可以從 Apache Spark for Synapse 影片深入瞭解。
Azure Synapse 中的 Spark 集區提供完全受控的 Spark 服務。 此處列出在 Azure Synapse Analytics 中建立 Spark 集區的優點。
| 功能 | 描述 |
|---|---|
| 速度與效率 | 針對少於 60 個節點的情況,Spark 執行個體會在大約 2 分鐘內啟動;針對超過 60 個節點的情況,則會在大約 5 分鐘之內啟動。 實例預設會在上次作業執行 5 分鐘後關閉,除非筆記本連線保持運作。 |
| 輕鬆建立 | 您可以使用 Azure 入口網站、Azure PowerShell 或 Synapse Analytics .NET SDK,在幾分鐘內在 Azure Synapse 中建立新的 Spark 集區。 請參閱 開始使用 Azure Synapse Analytics 中的 Spark 集區。 |
| 使用方便 | Synapse Analytics 包含衍生自 nteract 的自定義筆記本。 您可以為互動式資料處理與視覺效果使用這些筆記本。 |
| REST API | Azure Synapse Analytics 中的 Spark 包含 Apache Livy,這是 REST API 型 Spark 作業伺服器,可遠端提交和監視作業。 |
| 針對 Azure Data Lake Storage 第 2 代的支援 | Azure Synapse 中的 Spark 集區可以使用 Azure Data Lake Storage 第 2 代和 BLOB 記憶體。 如需 Data Lake Storage 的詳細資訊,請參閱 Azure Data Lake Storage 概觀 |
| 第三方 IDE 整合 | Azure Synapse 提供 JetBrains IntelliJ IDEA 的 IDE 外掛程式,有助於建立應用程式並將其提交至 Spark 集區。 |
| 預先載入的 Anaconda 連結庫 | Azure Synapse 中的 Spark 集區隨附預安裝 Anaconda 連結庫。 Anaconda 提供近 200 個用於機器學習、數據分析、視覺效果和其他技術的連結庫。 |
| 延展性 | Azure Synapse 集區中的 Apache Spark 可啟用自動擴縮,因此集區可視需要透過新增或移除節點來進行擴縮。 此外,所有資料都儲存在 Azure Storage 或 Data Lake Storage 中,因此可以將 Spark 集區關機,而不會遺失資料。 |
Azure Synapse 中的 Spark 集區包含下列預設可在集區上使用的元件:
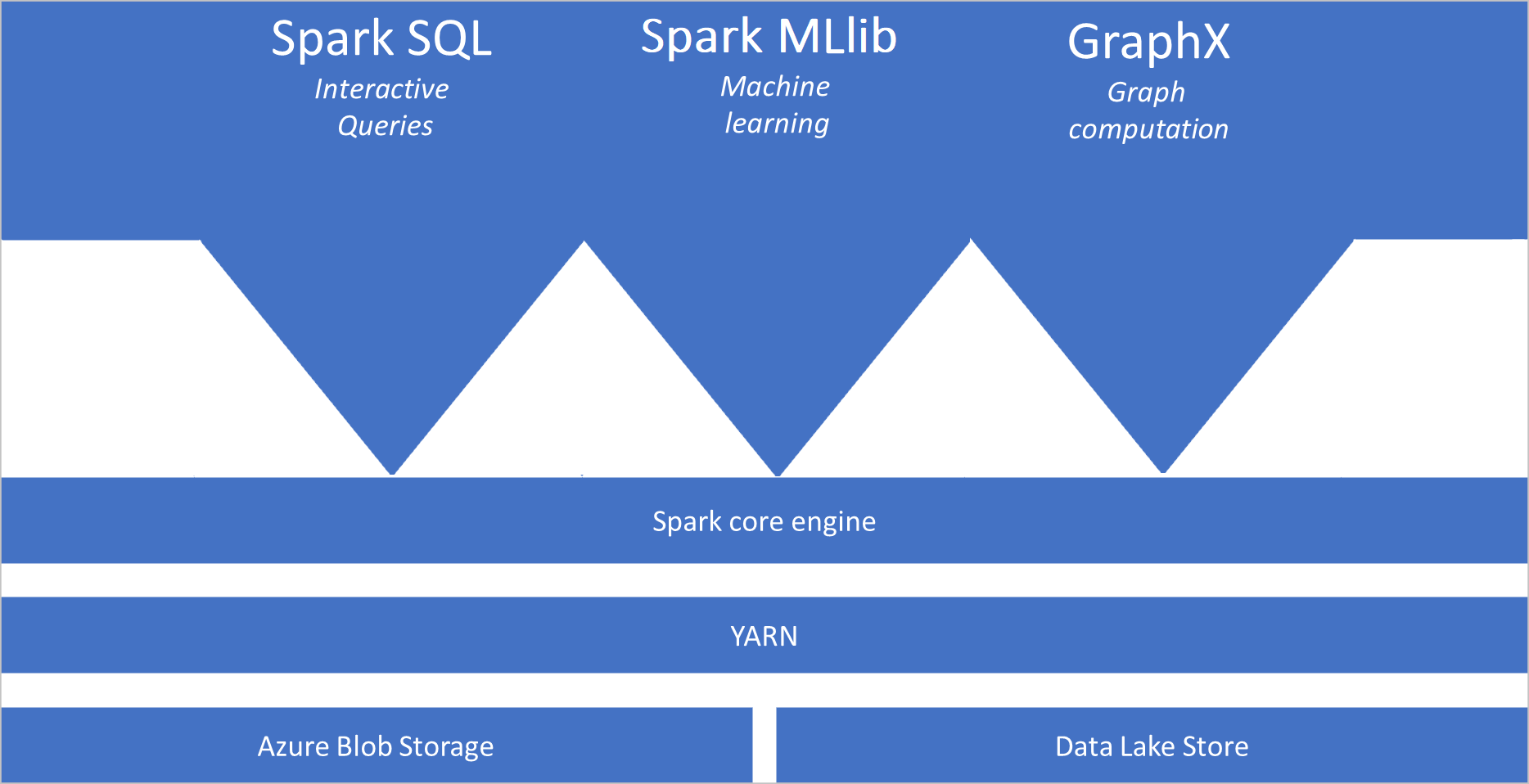
- Spark Core。 包括 Spark Core、Spark SQL、GraphX 及 MLlib。
- Anaconda
- Apache Livy
- nteract Notebook
Spark 集區架構
Spark 應用程式會在集區上以獨立的進程集執行,由 SparkContext 主要程式中的物件協調,稱為 驅動程式程式。
SparkContext可以連線到叢集管理員,以跨應用程式配置資源。 叢集管理員是 Apache Hadoop YARN。 線上之後,Spark 會在集區中的節點上取得執行程式,這些程式會執行計算並儲存應用程式的數據。 接下來,它會將 JAR 或 Python 檔案所定義的應用程式程式代碼傳送至 SparkContext執行程式。 最後, SparkContext 將工作傳送至執行程式以執行。
會 SparkContext 執行使用者的主要函式,並在節點上執行各種平行作業。 然後,會 SparkContext 收集作業的結果。 節點會讀取和寫入檔案系統的數據。 節點也會將已轉換的數據快取為復原分散式數據集(RDD)。
會 SparkContext 連線到 Spark 集區,並負責將應用程式轉換成有向無循環圖表 (DAG)。 此圖表是由節點上執行程序進程內執行的個別工作所組成。 每個應用程式都會取得自己的執行程式處理序,而這些處理序會在整個應用程式的持續時間保持運作,並且在多個執行緒中執行工作。
Azure Synapse Analytics 中的 Apache Spark 使用案例
Azure Synapse Analytics 中的 Spark 集區可啟用下列主要案例:
- 資料工程師/數據準備
Apache Spark 包含許多語言功能,可支援準備和處理大量數據,讓其更有價值,然後由 Azure Synapse Analytics 內的其他服務取用。 這可透過多種語言 (C#、Scala、PySpark、Spark SQL) 和提供的連結庫來啟用,以便處理和連線。
- Machine Learning
Apache Spark 隨附 MLlib,這是建置在 Spark 之上的機器學習連結庫,您可以從 Azure Synapse Analytics 中的 Spark 集區使用。 Azure Synapse Analytics 中的 Spark 集區也包含 Anaconda,這是 Python 散發套件,其中包含各種數據科學套件,包括機器學習。 結合對筆記本的內建支援,您就具備可建立機器學習應用程式的環境。
- 資料流資料
只要您執行支援的 Azure Synapse Spark 運行時間版本,Synapse Spark 支援 Spark 結構化串流。 所有工作都支援活七天。 這同時適用於批次和串流作業,一般而言,客戶會使用 Azure Functions 自動重新啟動程式。
相關內容
使用下列文章深入瞭解 Azure Synapse Analytics 中的 Apache Spark:
注意
某些官方 Apache Spark 文件依賴使用 Spark 控制台,而 Azure Synapse Spark 無法使用。 請改用 Notebook 或 IntelliJ 體驗。