本文涵蓋資料流 Gen2 中適用於 Microsoft Fabric 的 Data Factory 的增量數據刷新。 當您使用資料流進行資料引入和轉換時,有時您只需要重新整理新的或已更新的資料,特別是在資料不斷增長的情況下。
累加式重新整理可協助您:
- 減少重新整理時間
- 避免長時間執行的進程,讓作業更可靠
- 使用較少的資源
Prerequisites
若要在數據流 Gen2 中使用累加式重新整理,您需要:
目的地支援
這些資料目的地支援累加式重新整理:
- Fabric 湖屋
- 布料倉儲
- Azure SQL Database
您也可以使用其他目的地進行增量更新。 建立第二個查詢,參考暫存數據以更新目的地。 此方法仍然可讓您使用累加式重新整理來減少需要從來源系統處理的數據。 不過,您必須執行從暫存數據到最終目的地的完整重新整理。
此外,增量更新不支援預設的目的地設定。 您必須在查詢設定中明確定義目的地。
如何使用增量刷新
建立新的數據流 Gen2,或開啟現有的數據流。
在數據流編輯器中,建立新的查詢,以取得您想要以累加方式重新整理的數據。
檢查數據預覽,以確定您的查詢會傳回具有 DateTime、Date 或 DateTimeZone 數據行的數據以進行篩選。
請確定您的查詢完全折疊,這表示查詢會向下推送至來源系統。 如果它未完全折疊,請修改您的查詢,使其正常運作。 您可以在查詢編輯器中查看查詢步驟,以檢查查詢是否已完全折疊。
以滑鼠右鍵按下查詢,然後選取 [ 累加式重新整理]。
設定增量重新整理的必要設定。
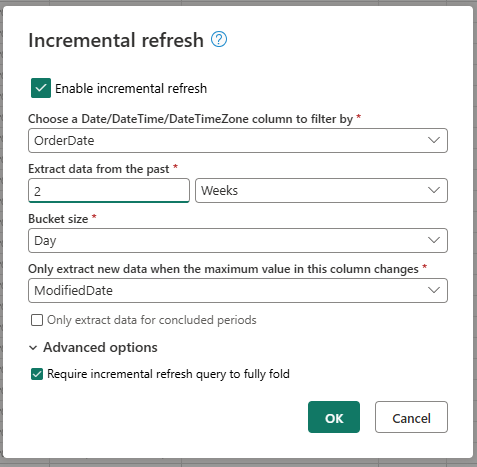
- 選擇一個 DateTime 欄位以進行篩選。
- 從過去擷取數據。
- 桶大小。
- 只有在此數據行中的最大值變更時,才擷取新的數據。
視需要設定進階設定。
- 需要增量更新查詢才能完整折疊。
選取 [確定 ] 以儲存您的設定。
如果您想要,請設定查詢的數據目的地。 請在第一次累加式重新整理之前執行此動作,或目的地只會包含自上次重新整理后以累加方式變更的數據。
發佈 Dataflow Gen2。
設定累加式重新整理之後,數據流會根據您的設定,以累加方式重新整理數據。 數據流只會取得自上次重新整理后變更的數據,因此其執行速度較快,且使用較少的資源。
增量刷新在幕後的運作原理
增量刷新會根據 DateTime 欄,將資料分割成不同區塊。 每個桶都包含自上次更新後變更的資料。 數據流會藉由檢查您所指定數據行中的最大值來知道變更的內容。
如果該桶的最大值發生改變,數據流會取得整個桶並取代目的地中的數據。 如果最大值未變更,數據流就不會取得任何數據。 以下是其逐步運作方式。
第一個步驟:評估變更
當數據流執行時,它會先檢查數據源中的變更。 它會查看 DateTime 資料行中的最大值,並將它與上次重新整理的最大值進行比較。
如果最大值已變更(或這是您的第一次重新整理),數據流會將該貯體標示為「已變更」,並將處理它。 如果最大值相同,數據流會略過該桶。
第二個步驟:取得數據
現在數據流會取得已變更之每個儲存桶的數據。 它會同時處理多個儲存桶,以加快速度。
數據流會將此數據載入暫存區域。 它只會取得落在貯體時間範圍內的數據,這表示只會取得自上次重新整理后實際變更的數據。
最後一個步驟:取代目的地中的數據
數據流會使用新的數據來更新目的地。 它會使用「取代」方法:先刪除該特定貯體的舊數據,然後插入新的數據。
此過程只會影響桶時間範圍內的資料。 該範圍以外的任何數據(例如較舊的歷程記錄數據)保持不變。
增量重新整理設定說明
若要設定累加式重新整理,您必須指定這些設定。
一般設定
這些設定是必要的,並指定累加式重新整理的基本組態。
選擇要篩選依據的 DateTime 欄位
此必要設定會指定數據流用來篩選數據的數據行。 此數據行應該是 DateTime、Date 或 DateTimeZone 數據行。 數據流會使用此數據行來篩選數據,並只取得自上次重新整理后變更的數據。
從過去擷取數據
此必要設定會指定數據流應該擷取數據的回溯時間範圍。 此設定會取得初始數據載入。 數據流會從指定時間範圍內的來源系統取得所有數據。 可能的值包括:
- X 天
- X 週
- X 個月
- X 季度
- X 年
例如,如果您指定 1 個月,數據流會在上個月從來源系統取得所有新數據。
貯體大小
此必要設定會指定數據流用來篩選數據之貯體的大小。 數據流會根據 DateTime 欄位將數據分割成不同的桶。 每個桶都包含自上次更新後變更的資料。 桶大小會決定每次迭代中處理多少數據量:
- 較小的貯體大小 表示數據流處理每個反覆項目中的數據較少,但需要更多反覆項目來處理所有數據。
- 較大的貯體大小 表示數據流會在每個反覆項目中處理更多數據,但需要較少的反覆項目來處理所有數據。
只有當此數據行中的最大值變更時,才擷取新的數據
此必要設定會指定資料流所使用的資料欄,用以判斷資料是否變更。 數據流會將此數據行中的最大值與上一次重新整理的最大值進行比較。 如果最大值已變更,數據流會取得自上次重新整理后變更的數據。 如果最大值未變更,數據流就不會取得任何數據。
只擷取結束期間的數據
這個選擇性設定會指定數據流是否只應該擷取結束期間的數據。 如果啟用此設定,數據流只會擷取結束期間的數據。 數據流只會擷取已完成且不包含任何未來數據的期間數據。 如果停用此設定,數據流會擷取所有期間的數據,包括未完成且包含未來數據的期間。
例如,如果您有包含交易日期的 DateTime 資料行,而且您只想要重新整理完整的月份,您可以使用 貯體大小 month來啟用此設定。 數據流只會擷取完整月份的數據,而且不會擷取不完整月份的數據。
進階設定
某些設定會被視為進階,而且大部分案例都不需要。
需要累加式重新整理查詢才能完全折疊
此設定可控制您的累加式重新整理查詢是否必須「完全折疊」。當查詢完全折疊時,它會完全向下推送至來源系統進行處理。
如果啟用此設定,您的查詢必須完全折疊。 如果停用它,數據流可以部分處理查詢,而不是您的來源系統。
強烈建議您保持啟用此設定。 在儲存資料流程之後,它可確保我們驗證是否可以將查詢折疊至來源。 如果此驗證失敗,您的資料流程可能會降低效能,並最終可能會擷取不必要的未篩選資料。
在編寫過程中,您可能會在某些情況下看到綠色摺疊指示器。 不過,當我們驗證最終資料流程定義時,可能無法再進行摺疊;例如,如果像 Table.SelectRows 這樣的步驟中斷折疊。 這可能會導致驗證錯誤。
Limitations
Lakehouse 支援附帶額外的條件
使用 Lakehouse 作為數據目的地時,請注意下列限制:
並行評估的數目上限為 10。 這表示數據流只能同時評估10個桶。 如果您有超過10個桶,則必須限制桶的數量或限制同時進行的評估數量。
當您寫入 Lakehouse 時,數據流會追蹤其寫入的檔案。 這會遵循標準的 Lakehouse 實務。
但問題來了:如果其他工具(例如 Spark)或進程也寫入到相同的數據表,它們可能會干擾漸進式更新。 建議您在使用增量重新整理時避免其他用戶進行資料寫入。
如果您必須使用其他編寫人員,確保它們不會與累加式重新整理程序衝突。 此外,使用累加式重新整理的表格,不支援進行如 OPTIMIZE 或 REORG TABLE 這類操作的表格維護。
如果您利用資料閘道連線至資料來源,請確定閘道已更新至至少 2025 年 5 月更新 (3000.270) 或更新版本。 這對於維持相容性並確保累加式重新整理與湖庫目的地正確運作至關重要。
目的地中現有重疊的資料不支援從非增量更新切換至增量更新。 如果 Lakehouse 目的地已包含與設定中定義的增量值區重疊的值區資料,則系統無法在不重寫整個 Delta 資料表的情況下,安全地轉換成增量更新。 我們建議篩選初始資料擷取,以僅包含在最早增量儲存單元之前的資料,從而避免重疊並確保重新整理行為的正確性。
數據目的地必須設定為固定架構
數據目的地必須設定為固定架構,這表示數據目的地中的數據表架構必須固定且無法變更。 如果數據目的地中的數據表架構設定為動態架構,您必須先將它變更為固定架構,再設定累加式重新整理。
數據目的地中唯一支援的更新方法為 replace
數據目的地中唯一支援的更新方法是 replace,這表示數據流會以新的數據取代數據目的地中每個貯體的數據。 然而,桶範圍以外的數據不會受到影響。 如果資料目的地中的資料比第一個資料桶的資料更早,累加式重新整理不會影響這些資料。
單一查詢的貯體數目上限為 50,整個數據流則為 150 個
每個查詢最多可以處理 50 個桶。 如果您有超過 50 個儲存桶,就需要增加儲存桶的大小或縮短時間範圍,以減少數量。
您的整個資料流程限額為總計150個儲存桶。 如果您達到此限制,您可以使用累加式重新整理來減少查詢數目,或增加查詢之間的貯體大小。
數據流 Gen1 和 Dataflow Gen2 中的累加式重新整理之間的差異
數據流 Gen1 和 Dataflow Gen2 之間的累加式重新整理運作方式有一些差異。 以下是主要差異:
第一類功能:累加式重新整理現在是數據流 Gen2 中的第一級功能。 在 Dataflow Gen1 中,您已在發佈數據流之後設定累加式重新整理。 在數據流 Gen2 中,您可以直接在數據流編輯器中設定它。 這可讓您更輕鬆地設定和降低錯誤的風險。
沒有歷程記錄數據範圍:在數據流 Gen1 中,您在設定累加式重新整理時指定了歷程記錄數據範圍。 在數據流 Gen2 中,您未指定此範圍。 數據流不會從值區範圍以外的目的地移除任何數據。 如果您的目的地中的數據早於第一個資料桶,增量更新不會影響它。
自動參數:在數據流 Gen1 中,您在設定時指定了累加式重新整理的參數。 在數據流 Gen2 中,您未指定這些參數。 數據流會自動將篩選和參數新增為查詢的最後一個步驟。
FAQ
我收到警告,指出我使用相同的欄來偵測變更和篩選。 這表示什麼意思?
如果您收到此警告,表示您為偵測變更指定的數據行也會用於篩選數據。 我們不建議您這麼做,因為它可能會導致非預期的結果。
請改用不同的數據行來偵測變更並篩選數據。 如果資料在桶之間移動,資料流可能無法正確偵測變更,而且可能會導致目的地出現重複的資料。
您可以使用不同的數據行來偵測變更並篩選數據,來解決此警告。 或者,如果您確定數據不會在您指定的數據行重新整理之間變更,則可以忽略警告。
我想要搭配不支援的資料目的地使用漸進式更新。 我能做什麼?
如果您想要搭配不支援累加式重新整理的數據目的地使用累加式重新整理,以下是您可以執行的動作:
在您的查詢上啟用累加式重新整理,並建立參考暫存數據的第二個查詢。 然後使用第二個查詢來更新最終目的地。 此方法仍會減少來源系統的資料處理,但您必須從暫存資料完整刷新到最終目的地。
請確定您已正確設定視窗和汲取槽大小。 我們不保證分段的數據會在儲存桶範圍之外保持可用。
另一個選項是使用增量式蒐集模式。 請參閱我們的指南: 使用數據流 Gen2 累加匯總數據。
我要如何知道我的查詢是否已啟用累加式重新整理?
您可以在數據流編輯器中檢查查詢旁的圖示,以查看查詢是否已啟用累加式重新整理。 如果圖示包含藍色三角形,則會啟用累加式重新整理。 如果圖示不包含藍色三角形,則不會啟用累加式重新整理。
當我使用增量刷新時,我的來源會收到太多要求。 我能做什麼?
您可以控制數據流傳送至來源系統的要求數目。 方法如下:
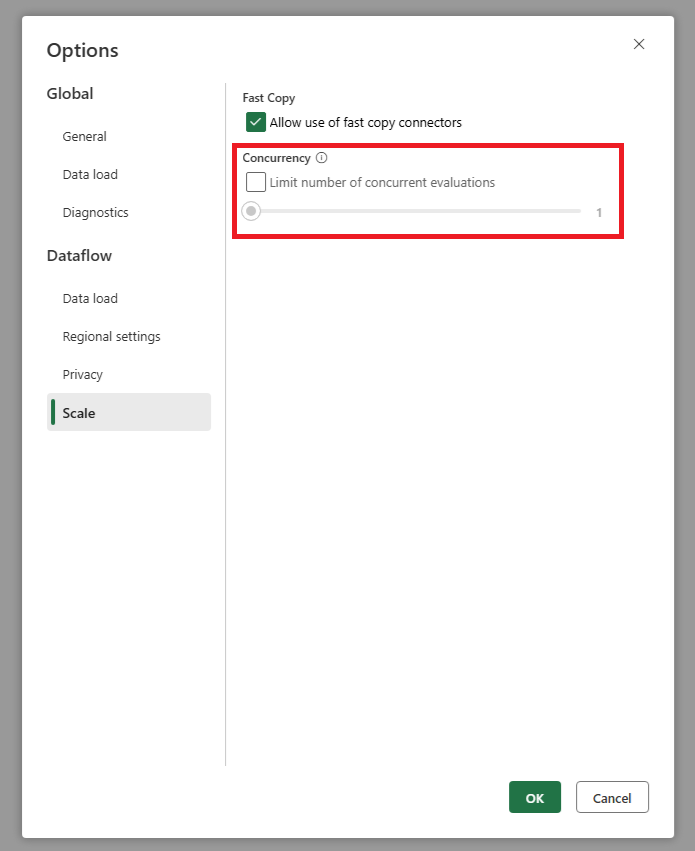
移至數據流的全域設定,並尋找平行查詢評估設定。 將此設定為較低的數位,以減少傳送至來源系統的要求。 這有助於減少來源上的負載,並可以改善其效能。
若要尋找此設定:請移至全域設定 >比例 標籤 > 設定平行查詢評估的最大數目。
如果您的來源系統無法處理預設的並行要求數目,建議您只使用此限制。
我想要使用累加式重新整理,但看到啟用之後,數據流需要較長的時間才能重新整理。 我能做什麼?
累加式重新整理可以通过减少需处理的数据量来提高数据流的速度。 但有時情況正好相反。 這通常意味著管理儲存桶和檢查變更的額外負荷所需的時間比通過處理較少的數據節省的時間還要多。
以下是您可以嘗試的內容:
調整您的設定:增加貯體大小以減少貯體數目。 較少的儲存桶表示管理負擔較少。
嘗試完整更新:如果調整設定沒有幫助,請考慮停用增量刷新。 針對您的特定案例,完整重新整理實際上可能更有效率。