教學課程:建立、評估機器故障偵測模型及評分
本教學課程提供 Microsoft Fabric 中 Synapse 資料科學工作流程的端對端範例。 該案例會使用機器學習,以更為系統化的方法來進行錯誤診斷、主動識別問題,及在實際機器失敗之前採取動作。 目標是預測機器是否會基於處理溫度、旋轉速度等失敗。
本教學課程涵蓋了下列步驟:
- 安裝自訂程式庫
- 載入及處理資料
- 透過探索式資料分析來了解資料
- 使用 Scikit-learn、LightGBM 和 MLflow 訓練機器學習模型,並使用 Fabric 自動記錄功能追蹤實驗
- 使用 Fabric
PREDICT功能為訓練的模型評分、儲存最佳模型,並載入該模型以進行預測 - 使用已載入的 Power BI 視覺效果顯示模型效能
必要條件
取得 Microsoft Fabric 訂用帳戶。 或註冊免費的 Microsoft Fabric 試用版。
登入 Microsoft Fabric。
使用首頁左側的體驗切換器,切換至 Synapse 資料科學體驗。
![體驗切換器功能表的螢幕擷取畫面,顯示選取 [資料科學] 的位置。](media/tutorial-data-science-prepare-system/switch-to-data-science.png)
- 如有必要,請建立 Microsoft Fabric lakehouse,如在 Microsoft Fabric 中建立 lakehouse 中所述。
遵循筆記本中的指示
您可以選擇下列選項之一,以遵循筆記本中的指示操作:
- 在資料科學體驗中開啟並執行內建筆記本
- 將筆記本從 GitHub 上傳至資料科學體驗
開啟內建筆記本
本教學課程隨附範例機器失敗筆記本。
在 Synapse 資料科學體驗中開啟教學課程的內建範例筆記本:
移至 Synapse 資料科學首頁。
選取 [使用範例]。
選取對應的範例:
- 如果範例適用於 Python 教學課程,則從預設的 [端對端工作流程 (Python)] 索引標籤選取。
- 如果範例適用於 R 教學課程,則從 [端對端工作流程] 索引標籤選取。
- 如果範例適用於快速教學課程,則從 [快速教學課程] 索引標籤選取。
開始執行程式碼之前,將 Lakehouse 連結至筆記本。
從 GitHub 匯入筆記本
本教學課程隨附 AISample - 預測性維護筆記本。
若要開啟本教學課程隨附的筆記本,請遵循為資料科學教學課程準備系統中的指示,將筆記本匯入您的工作區。
如果您想要複製並貼上此頁面中的程式碼,則可以建立新的筆記本。
開始執行程式碼之前,請務必將 Lakehouse 連結至筆記本。
步驟 1:安裝自訂程式庫
針對機器學習模型開發或臨機操作資料分析,您可能需要快速安裝 Apache Spark 工作階段的自訂程式庫。 安裝程式庫有兩個選項。
- 使用筆記本的內嵌安裝功能 (
%pip或%conda),僅在您目前的筆記本中安裝程式庫。 - 或者,您可以建立 Fabric 環境,從公用來源安裝程式庫,或將自訂程式庫上傳至該環境,然後您的工作區管理員可將環境連結為工作區的預設值。 環境中的所有程式庫隨後可供在工作區中的任何筆記本和 Spark 工作定義使用。 如需有關環境的詳細資訊,請參閱在 Microsoft Fabric 中建立、設定和使用環境。
在本教學課程中,使用 %pip install 在您的筆記本中安裝 imblearn 程式庫。
注意
執行 %pip install 之後,PySpark 核心會重新啟動。 在執行任何其他資料格之前,請先安裝所需的程式庫。
# Use pip to install imblearn
%pip install imblearn
步驟 2:載入資料
資料集會模擬製造機器參數的記錄作為時間函式,這在工業設定中很常見。 其包含儲存為資料列的 10,000 個資料點,以及儲存為資料行的特徵。 這些功能包括:
範圍從 1 到 10000 的唯一識別碼 (UID)
產品識別碼,包含表示產品品質變體的字母 L (低)、M (中) 或 H(高),以及變體專用序號。 低、中、高品質變體分別佔所有產品的 60%、30% 和 10%
空氣溫度,以克耳文 (K) 為單位
處理溫度,以克耳文為單位
旋轉速度,以每分鐘轉速 (RPM) 為單位
扭力,以牛頓米 (Nm) 為單位
工具磨損,以分鐘為單位。 品質變體 H、M 和 L 分別將 5、3 和 2 分鐘的工具磨損新增至程序中使用的工具
機器失敗標籤,指出機器是否在特定資料點失敗。 此特定資料點可以有下列五種獨立失敗模式中的任何一種:
- 工具磨損失敗 (TWF):在隨機選取的工具磨損時間 (200 到 240 分鐘) 取代工具或工具發生故障
- 散熱失敗 (HDF):如果空氣溫度和處理溫度之間的差值小於 8.6 K,且工具的旋轉速度小於 1380 RPM,則散熱會導致程序失敗
- 電源故障 (PWF):扭力和旋轉速度 (以每秒弧度為單位) 的乘積等於程序所需的功率。 如果此功率低於 3,500 W 或超過 9,000 W,則程序會失敗
- 過度應變失敗 (OSF):如果 L 產品變體的工具磨損和扭力的乘積超過最小值 11,000 Nm (M 為 12,000、H 為 13,000),則程序會因為過度應變而失敗
- 隨機失敗 (RNF):不論程序參數為何,每個程序都有 0.1% 的失敗機率
注意
如果上述失敗模式中至少有一個為 true,則程序會失敗,且「機器失敗」標籤會設定為 1。 機器學習方法無法判定是哪個失敗模式導致程序失敗。
下載資料集並上傳至 Lakehouse
連線到 Azure 開放資料集容器,並載入預測性維護資料集。 此程式碼會下載公開可用的資料集版本,然後將其儲存在 Fabric Lakehouse 中:
重要
在執行筆記本之前,新增 Lakehouse 至筆記本。 否則,您會收到錯誤。 如需有關新增 Lakehouse 的資訊,請參閱連線 lakehouses 和 Notebook。
# Download demo data files into the lakehouse if they don't exist
import os, requests
DATA_FOLDER = "Files/predictive_maintenance/" # Folder that contains the dataset
DATA_FILE = "predictive_maintenance.csv" # Data file name
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/MachineFaultDetection"
file_list = ["predictive_maintenance.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
將資料集下載到 Lakehouse 之後,您可以將其載入為 Spark DataFrame:
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}raw/{DATA_FILE}")
.cache()
)
df.show(5)
下表顯示資料的預覽:
| UDI | 產品識別碼 | 類型 | 空氣溫度 [K] | 處理溫度 [K] | 旋轉速度 [rpm] | 扭力 [Nm] | 工具磨損 [min] | Target | 失敗類型 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | 月 | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | 沒有失敗 |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | 沒有失敗 |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | 沒有失敗 |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | 沒有失敗 |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | 沒有失敗 |
將 Spark DataFrame 寫入 Lakehouse Delta 資料表
格式化資料 (例如,以底線取代空格),以便在後續步驟中輔助 Spark 作業:
# Replace the space in the column name with an underscore to avoid an invalid character while saving
df = df.toDF(*(c.replace(' ', '_') for c in df.columns))
table_name = "predictive_maintenance_data"
df.show(5)
此資料表顯示具有重新格式化資料行名稱的資料的預覽:
| UDI | Product_ID | 類型 | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | Target | Failure_Type |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | 月 | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | 沒有失敗 |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | 沒有失敗 |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | 沒有失敗 |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | 沒有失敗 |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | 沒有失敗 |
# Save data with processed columns to the lakehouse
df.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
步驟 3:前置處理資料並執行探索式資料分析
將 Spark DataFrame 轉換成 Pandas DataFrame,以使用 Pandas 相容的熱門繪圖程式庫。
提示
針對大型資料集,您可能需要載入該資料集的一部分。
data = spark.read.format("delta").load("Tables/predictive_maintenance_data")
SEED = 1234
df = data.toPandas()
df.drop(['UDI', 'Product_ID'],axis=1,inplace=True)
# Rename the Target column to IsFail
df = df.rename(columns = {'Target': "IsFail"})
df.info()
視需要將資料集的特定資料行轉換為浮點數或整數類型,並將字串 ('L'、'M'、'H') 對應至數值 (0、1、2):
# Convert temperature, rotational speed, torque, and tool wear columns to float
df['Air_temperature_[K]'] = df['Air_temperature_[K]'].astype(float)
df['Process_temperature_[K]'] = df['Process_temperature_[K]'].astype(float)
df['Rotational_speed_[rpm]'] = df['Rotational_speed_[rpm]'].astype(float)
df['Torque_[Nm]'] = df['Torque_[Nm]'].astype(float)
df['Tool_wear_[min]'] = df['Tool_wear_[min]'].astype(float)
# Convert the 'Target' column to an integer
df['IsFail'] = df['IsFail'].astype(int)
# Map 'L', 'M', 'H' to numerical values
df['Type'] = df['Type'].map({'L': 0, 'M': 1, 'H': 2})
透過視覺效果探索資料
# Import packages and set plotting style
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
sns.set_style('darkgrid')
# Create the correlation matrix
corr_matrix = df.corr(numeric_only=True)
# Plot a heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True)
plt.show()
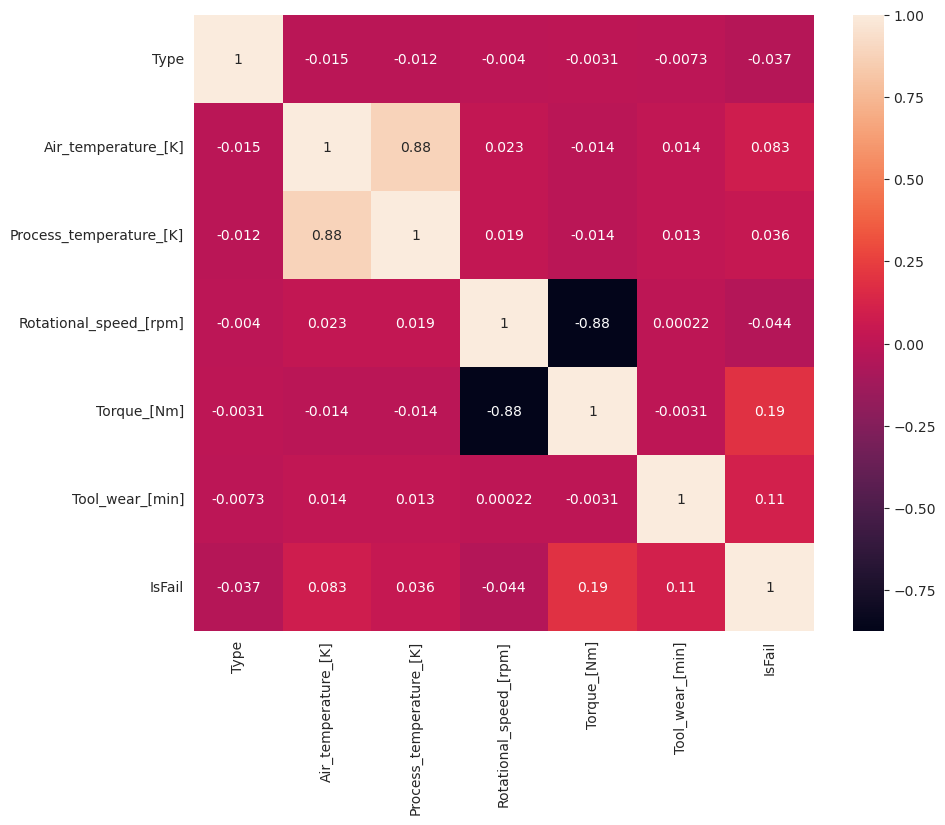
如預期般,失敗 (IsFail) 會與選取的特徵 (資料行) 相互關聯。 相互關聯矩陣顯示 Air_temperature、Process_temperature、Rotational_speed、Torque 和 Tool_wear 與 IsFail 變數具有最高關聯性。
# Plot histograms of select features
fig, axes = plt.subplots(2, 3, figsize=(18,10))
columns = ['Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']
data=df.copy()
for ind, item in enumerate (columns):
column = columns[ind]
df_column = data[column]
df_column.hist(ax = axes[ind%2][ind//2], bins=32).set_title(item)
fig.supylabel('count')
fig.subplots_adjust(hspace=0.2)
fig.delaxes(axes[1,2])
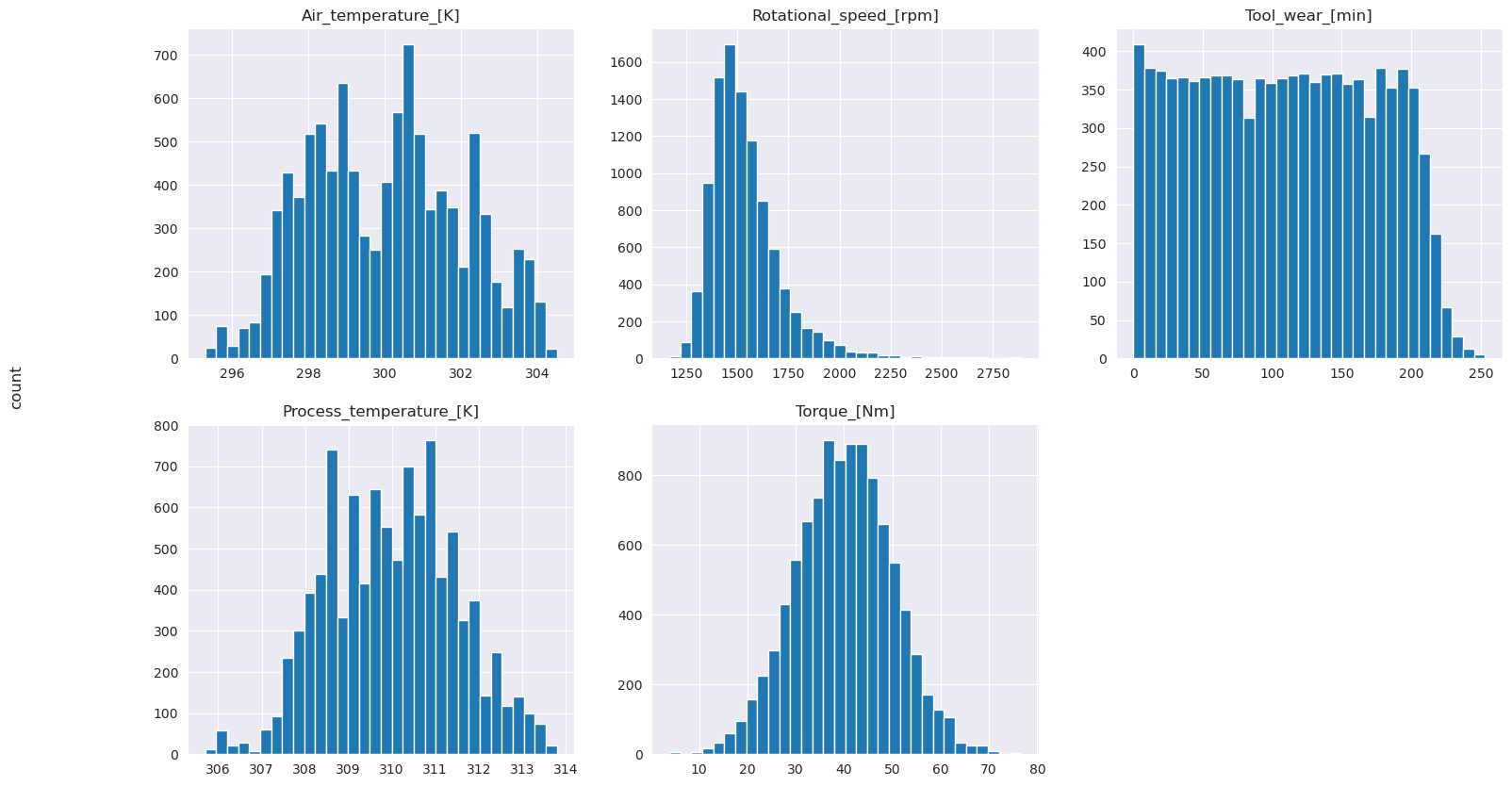
如繪製的圖表所示,Air_temperature、Process_temperature、Rotational_speed、Torque 和 Tool_wear 變數並不疏鬆。 在特徵空間中,它們似乎具有良好持續性。 這些繪圖會確認,在此資料集上訓練機器學習模型可能會產生可靠的結果,而這些結果可一般化為新資料集。
檢查類別不平衡的目標變數
計算失敗和未失敗機器的樣本數目,並檢查每個類別的資料平衡 (IsFail=0、IsFail=1):
# Plot the counts for no failure and each failure type
plt.figure(figsize=(12, 2))
ax = sns.countplot(x='Failure_Type', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
# Plot the counts for no failure versus the sum of all failure types
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
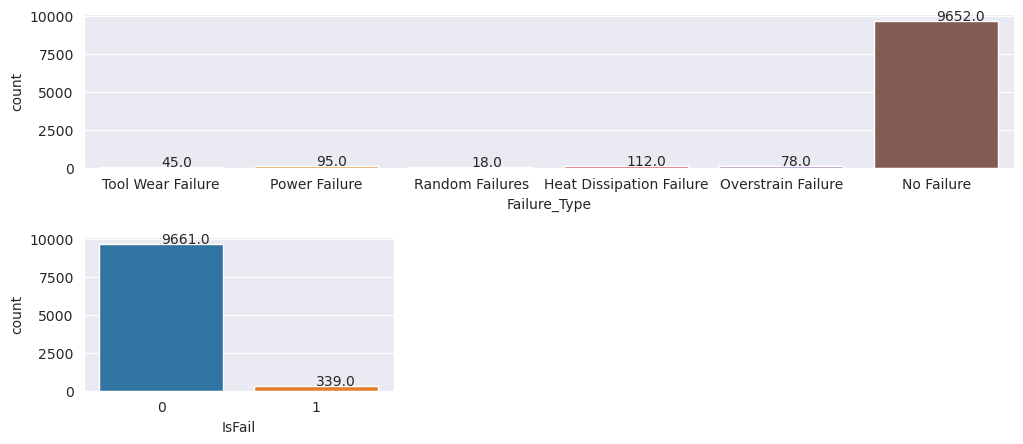
繪圖表示沒有失敗類別 (如第二個繪圖中的 IsFail=0 所示) 構成了大部分樣本。 使用過度取樣技術來建立更平衡的訓練資料集:
# Separate features and target
features = df[['Type', 'Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']]
labels = df['IsFail']
# Split the dataset into the training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Save test data to the lakehouse for use in future sections
table_name = "predictive_maintenance_test_data"
df_test_X = spark.createDataFrame(X_test)
df_test_X.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
過度取樣以平衡訓練資料集中的類別
先前的分析顯示資料集高度不平衡。 這種不平衡會導致問題,因為少數類別的範例太少,模型無法有效地了解決策邊界。
SMOTE 可以解決問題。 SMOTE 是一種廣泛使用的過度取樣技術,可產生綜合範例。 其會根據資料點之間的 Euclidian 距離,產生少數類別的範例。 此方法與隨機過度取樣不同,因為它會建立新的範例,而不只是複製少數類別。 方法會成為處理不平衡資料集的更有效技術。
# Disable MLflow autologging because you don't want to track SMOTE fitting
import mlflow
mlflow.autolog(disable=True)
from imblearn.combine import SMOTETomek
smt = SMOTETomek(random_state=SEED)
X_train_res, y_train_res = smt.fit_resample(X_train, y_train)
# Plot the counts for both classes
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=pd.DataFrame({'IsFail': y_train_res.values}))
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
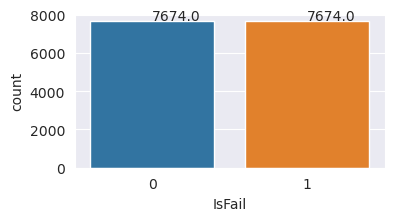
您已成功平衡資料集。 您現在可以移至模型訓練。
步驟 4︰訓練及評估模型
MLflow 會註冊模型、訓練和比較各種模型,並挑選最適合預測用途的模型。 您可以使用下列三個模型進行模型訓練:
- 隨機樹系分類器
- 羅吉斯迴歸分類器
- XGBoost 分類器
訓練隨機樹系分類器
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from mlflow.models.signature import infer_signature
from sklearn.metrics import f1_score, accuracy_score, recall_score
mlflow.set_experiment("Machine_Failure_Classification")
mlflow.autolog(exclusive=False) # This is needed to override the preconfigured autologging behavior
with mlflow.start_run() as run:
rfc_id = run.info.run_id
print(f"run_id {rfc_id}, status: {run.info.status}")
rfc = RandomForestClassifier(max_depth=5, n_estimators=50)
rfc.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
rfc,
"machine_failure_model_rf",
signature=signature,
registered_model_name="machine_failure_model_rf"
)
y_pred_train = rfc.predict(X_train)
# Calculate the classification metrics for test data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = rfc.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
# Print the classification metrics
print("F1 score_test:", f1_test)
print("Accuracy_test:", accuracy_test)
print("Recall_test:", recall_test)
從輸出中,當使用隨機樹系分類器時,訓練和測試資料集產生的 F1 分數、正確性和召回率均約為 0.9。
訓練羅吉斯迴歸分類器
from sklearn.linear_model import LogisticRegression
with mlflow.start_run() as run:
lr_id = run.info.run_id
print(f"run_id {lr_id}, status: {run.info.status}")
lr = LogisticRegression(random_state=42)
lr.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
lr,
"machine_failure_model_lr",
signature=signature,
registered_model_name="machine_failure_model_lr"
)
y_pred_train = lr.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = lr.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
訓練 XGBoost 分類器
from xgboost import XGBClassifier
with mlflow.start_run() as run:
xgb = XGBClassifier()
xgb_id = run.info.run_id
print(f"run_id {xgb_id}, status: {run.info.status}")
xgb.fit(X_train_res.to_numpy(), y_train_res.to_numpy())
signature = infer_signature(X_train_res, y_train_res)
mlflow.xgboost.log_model(
xgb,
"machine_failure_model_xgb",
signature=signature,
registered_model_name="machine_failure_model_xgb"
)
y_pred_train = xgb.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = xgb.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
步驟 5:選取最佳模型並預測輸出
在上一節中,您已訓練三個不同的分類器:隨機樹系、羅吉斯迴歸和 XGBoost。 您現在可以選擇以程式設計方式存取結果,或使用使用者介面 (UI)。
針對 [UI 路徑] 選項,瀏覽至您的工作區並篩選模型。
選取個別模型,以取得模型效能的詳細資料。
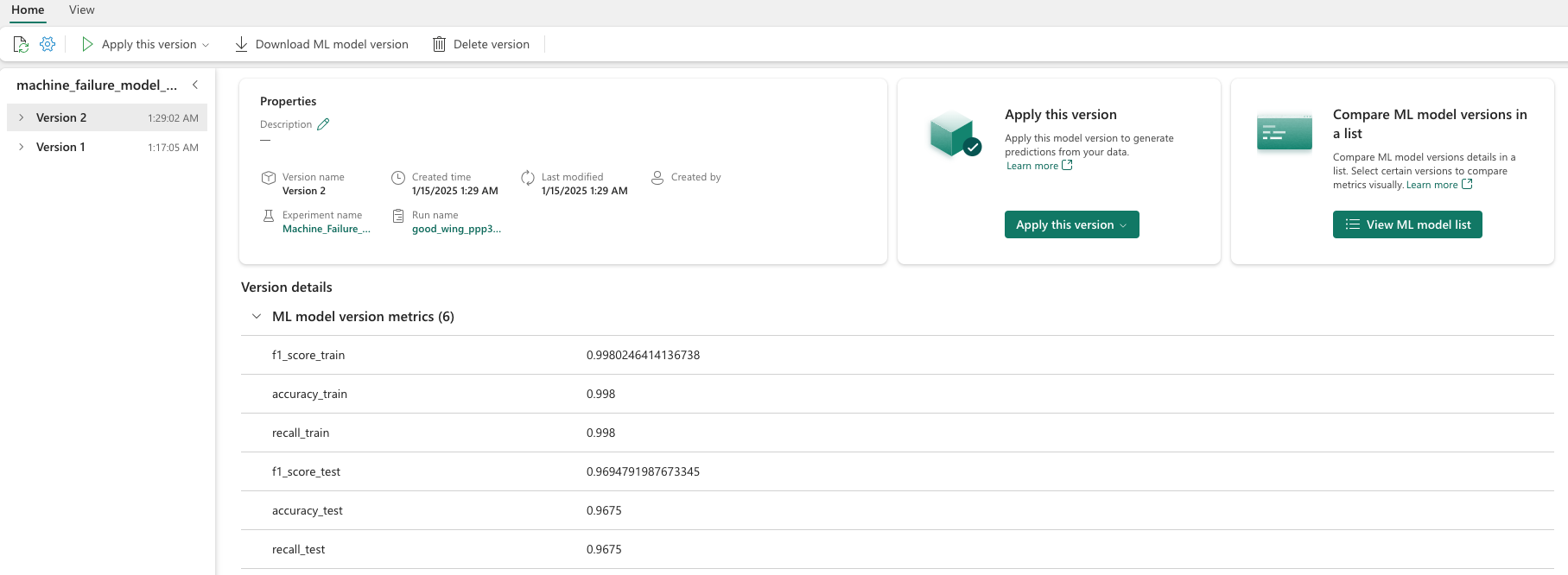
此範例示範如何透過 MLflow 以程式設計方式存取模型:
runs = {'random forest classifier': rfc_id,
'logistic regression classifier': lr_id,
'xgboost classifier': xgb_id}
# Create an empty DataFrame to hold the metrics
df_metrics = pd.DataFrame()
# Loop through the run IDs and retrieve the metrics for each run
for run_name, run_id in runs.items():
metrics = mlflow.get_run(run_id).data.metrics
metrics["run_name"] = run_name
df_metrics = df_metrics.append(metrics, ignore_index=True)
# Print the DataFrame
print(df_metrics)
雖然 XGBoost 會在訓練集上產生最佳結果,但在測試資料集上的執行效能不佳。 效能不佳表示過度學習。 羅吉斯迴歸分類器在訓練和測試資料集上的執行效能不佳。 整體而言,隨機樹系會在訓練效能與避免過度學習之間取得良好的平衡。
在下一節中,選擇已註冊的隨機樹系模型,並使用 PREDICT 特徵執行預測:
from synapse.ml.predict import MLFlowTransformer
model = MLFlowTransformer(
inputCols=list(X_test.columns),
outputCol='predictions',
modelName='machine_failure_model_rf',
modelVersion=1
)
藉助您建立的用來載入推斷模型的 MLFlowTransformer 物件,使用轉換器 API 在測試資料集上為模型評分:
predictions = model.transform(spark.createDataFrame(X_test))
predictions.show()
下表顯示輸出:
| 類型 | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | 預測 |
|---|---|---|---|---|---|---|
| 0 | 300.6 | 309.7 | 1639.0 | 30.4 | 121.0 | 0 |
| 0 | 303.9 | 313.0 | 1551.0 | 36.8 | 140.0 | 0 |
| 1 | 299.1 | 308.6 | 1491.0 | 38.5 | 166.0 | 0 |
| 0 | 300.9 | 312.1 | 1359.0 | 51.7 | 146.0 | 1 |
| 0 | 303.7 | 312.6 | 1621.0 | 38.8 | 182.0 | 0 |
| 0 | 299.0 | 310.3 | 1868.0 | 24.0 | 221.0 | 1 |
| 2 | 297.8 | 307.5 | 1631.0 | 31.3 | 124.0 | 0 |
| 0 | 297.5 | 308.2 | 1327.0 | 56.5 | 189.0 | 1 |
| 0 | 301.3 | 310.3 | 1460.0 | 41.5 | 197.0 | 0 |
| 2 | 297.6 | 309.0 | 1413.0 | 40.2 | 51.0 | 0 |
| 1 | 300.9 | 309.4 | 1724.0 | 25.6 | 119.0 | 0 |
| 0 | 303.3 | 311.3 | 1389.0 | 53.9 | 39.0 | 0 |
| 0 | 298.4 | 307.9 | 1981.0 | 23.2 | 16.0 | 0 |
| 0 | 299.3 | 308.8 | 1636.0 | 29.9 | 201.0 | 0 |
| 1 | 298.1 | 309.2 | 1460.0 | 45.8 | 80.0 | 0 |
| 0 | 300.0 | 309.5 | 1728.0 | 26.0 | 37.0 | 0 |
| 2 | 299.0 | 308.7 | 1940.0 | 19.9 | 98.0 | 0 |
| 0 | 302.2 | 310.8 | 1383.0 | 46.9 | 45.0 | 0 |
| 0 | 300.2 | 309.2 | 1431.0 | 51.3 | 57.0 | 0 |
| 0 | 299.6 | 310.2 | 1468.0 | 48.0 | 9.0 | 0 |
將資料儲存至 Lakehouse。 然後,資料會變成可供稍後使用 ,例如 Power BI 儀表板。
# Save test data to the lakehouse for use in the next section.
table_name = "predictive_maintenance_test_with_predictions"
predictions.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
步驟 6:透過 Power BI 中的視覺效果檢視商業智慧
使用 Power BI 儀表板以離線格式顯示結果。
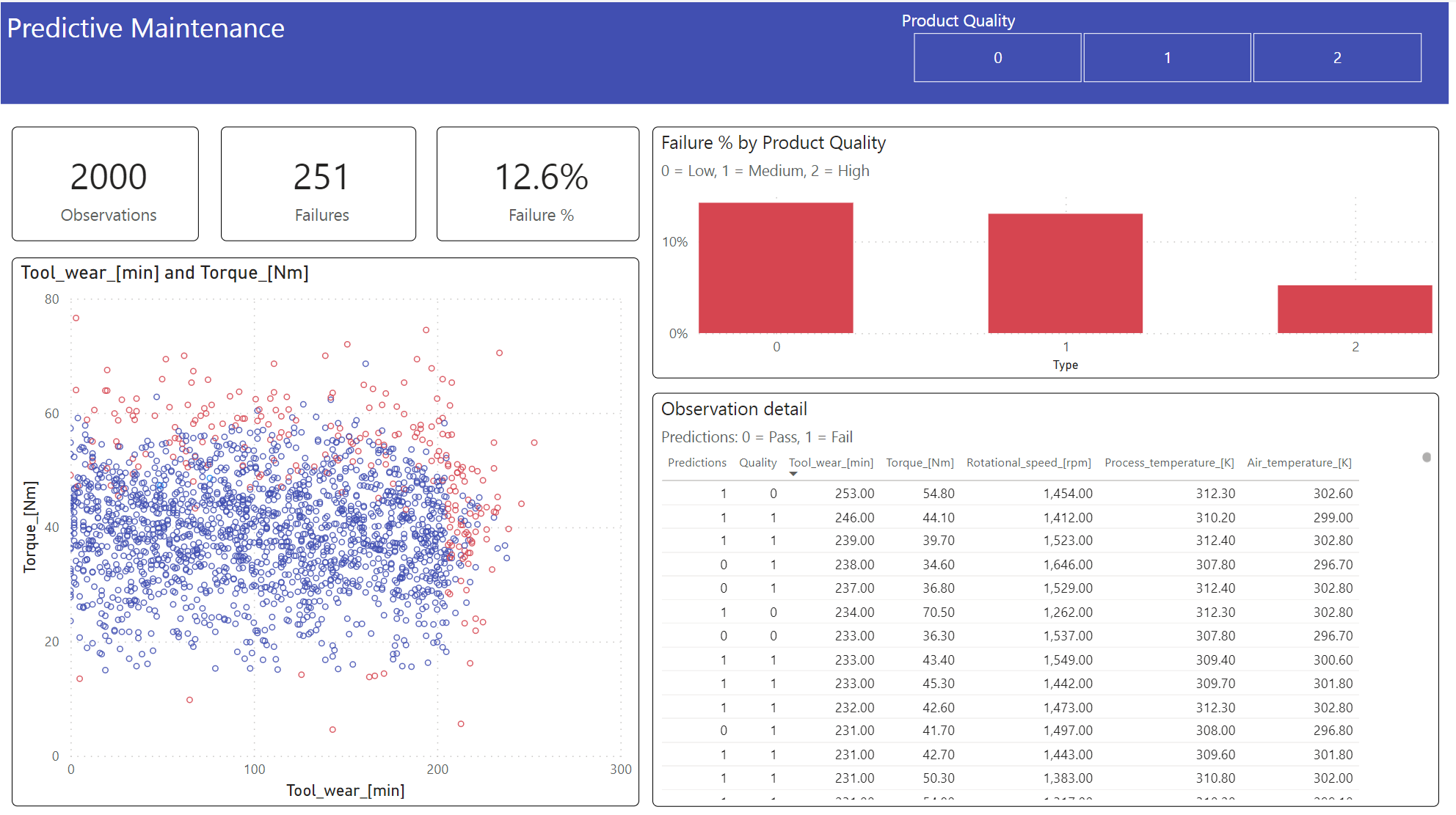
儀表板會顯示,Tool_wear 和 Torque 在失敗與未失敗案例之間建立明顯的邊界,如步驟 2 中早期關聯性分析所預期。