教學課程:建立、評估和評分推薦系統
本教學課程提供 Microsoft Fabric 中 Synapse 資料科學工作流程的端對端範例。 此案例會建置線上書籍推薦的模型。
本教學課程涵蓋了下列步驟:
- 將資料上傳至 Lakehouse
- 執行探索式資料分析
- 使用 MLflow 將模型訓練並進行記錄
- 輸入模型並進行預測
我們有許多推薦演算法類型可供使用。 本教學課程使用交替最小平方 (ALS) 矩陣分解演算法。 ALS 是基於模型為的共同作業篩選演算法。

ALS 會嘗試將評等矩陣 R 估計為兩個低階矩陣的乘積,即 U 和 V。在這裡,R = U * Vt。 通常,這些近似值稱為因數矩陣。
ALS 演算法為迭代式。 每個迭代都會保存其中一個因數矩陣常數,同時使用最小平方法求解另一個因數矩陣。 然後,它會保留新解析的因數矩陣常數,同時會解決其他因數矩陣。

必要條件
取得 Microsoft Fabric 訂用帳戶。 或註冊免費的 Microsoft Fabric 試用版。
登入 Microsoft Fabric。
使用首頁左下方的體驗切換器,切換至 Fabric。
![體驗切換器功能表的螢幕擷取畫面,顯示選取 [資料科學] 的位置。](media/tutorial-data-science-prepare-system/switch-to-data-science.png)
- 如有必要,請建立 Microsoft Fabric lakehouse,如在 Microsoft Fabric 中建立 lakehouse 中所述。
遵循筆記本中的指示
您可以選擇下列選項之一,以遵循筆記本中的指示操作:
- 開啟並執行內建筆記本。
- 從 GitHub 上傳您的筆記本。
開啟內建筆記本
本教學課程隨附範例書籍推薦筆記本。
若要開啟本教學課程的範例筆記本,請遵循 中的指示來準備系統,用於資料科學教學課程。
開始執行代碼之前,請務必將湖屋 附加至筆記本。
從 GitHub 匯入筆記本
本教學課程隨附 AIsample - Book Recommendation.ipynb 筆記本。
若要開啟本教學隨附的筆記本,請遵循 在數據科學教學準備系統中的指示, 將筆記本匯入到您的工作區。
如果您想要複製並貼上此頁面中的程式碼,則可以建立新的筆記本。
開始執行程式碼之前,請務必將 Lakehouse 連結至筆記本。
步驟 1:載入資料
此案例中的書籍推薦資料集包含三個不同的資料集:
Books.csv:國際標準書號 (ISBN) 會識別每本書,並移除無效的日期。 資料集也包含標題、作者和發行者。 對於具有多個作者的書籍,Books.csv 檔案只會列出第一作者。 URL 指向 Amazon 網站的封面影像資源,有三種尺寸。
ISBN 書名 書籍-作者 發行年份 發行者 Image-URL-S Image-URL-M Image-URL-l 0195153448 古典神話 Mark P. O. Morford 2002 牛津大學出版社 http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 加拿大哈珀弗拉明戈 http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv:每本書的評分是明確的 (由使用者提供,範圍為 1 到 10) 或隱含的 (無需使用者輸入即可觀察到,並以 0 表示)。
使用者識別碼 ISBN 書籍評分 276725 034545104X 0 276726 0155061224 5 Users.csv:使用者識別碼會匿名並對應至整數。 如果有,提供人口統計資料 (例如位置與年齡)。 如果無法使用此資料,則這些值為
null。使用者識別碼 Location 年齡 1 「美國紐約州紐約市」 2 「美國加州斯托克頓」 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
定義這些參數,以便您搭配不同的資料集使用此筆記本:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
下載資料並將其儲存在 Lakehouse 中
此程式碼會下載資料集,然後將其儲存在 Lakehouse 中。
重要
在執行筆記本之前,請確定已將 Lakehouse 新增至筆記本。 否則,您會收到錯誤。
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
設定 MLflow 實驗追蹤
使用此程式碼來設定 MLflow 實驗追蹤。 該範例會停用自動記錄。 如需詳細資訊,請參閱 Microsoft Fabric 中的自動記錄文章。
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
從 Lakehouse 讀取資料
將正確的資料放入 Lakehouse 之後,請將這三個資料集讀入筆記本中的單獨 Spark DataFrame。 此程式碼中的檔案路徑會使用稍早定義的參數。
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
步驟 2:執行探索式資料分析
顯示未經處理資料
使用 display 命令來探索 DataFrame。 使用此命令,您可以檢視高階 DataFrame 統計資料,並了解不同的資料集資料行彼此間的關聯性。 探索資料集之前,請先使用此程式碼匯入必要的程式庫:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
使用此程式碼來檢視包含書籍資料的 DataFrame:
display(df_items, summary=True)
新增 _item_id 資料行,以供日後使用。
_item_id 值必須是推薦模型的整數。 此程式碼會使用 StringIndexer 將 ITEM_ID_COL 轉換成索引:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
顯示 DataFrame,並檢查 _item_id 值是否依預期以單調和連續方式增加:
display(df_items.sort(F.col("_item_id").desc()))
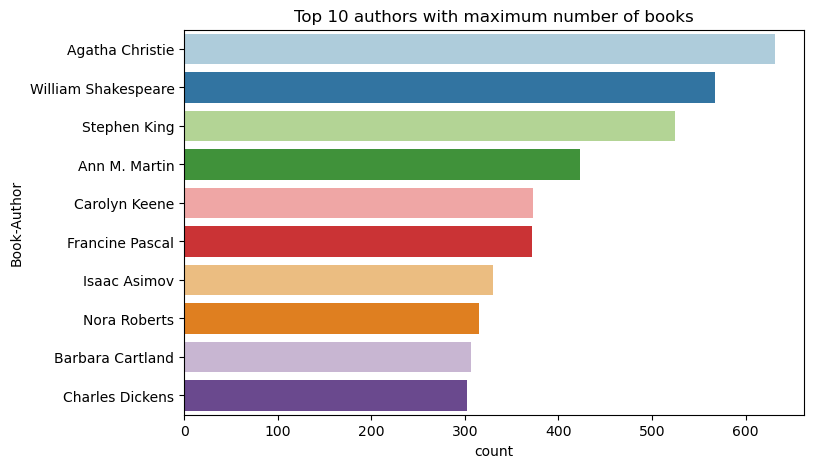
使用此程式碼以遞減順序繪製前 10 位作者的書籍數目。 阿加莎·克裡斯蒂是擁有 600 多本書的主要作者,其次是威廉·莎士比亞。
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
接下來,顯示包含使用者資料的 DataFrame:
display(df_users, summary=True)
如果資料列有遺漏的 User-ID 的值,請卸除該資料列。 自訂資料集中的遺漏值不會造成問題。
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
新增 _user_id 資料行,以供日後使用。 對於推薦模型,_user_id 值必須為整數。 下列程式碼範例會使用 StringIndexer 將 USER_ID_COL 轉換成索引。
書籍資料集已經有整數 User-ID 資料行。 不過,新增 _user_id 資料行以與不同的資料集相容,讓此範例更加強固。 使用此程式碼來新增 _user_id 資料行:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
使用此程式碼來檢視評分資料:
display(df_ratings, summary=True)
取得相異評等,並進行儲存,以供稍後在名為 ratings 的清單中使用:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
使用此程式碼來顯示評分最高的前 10 本書:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
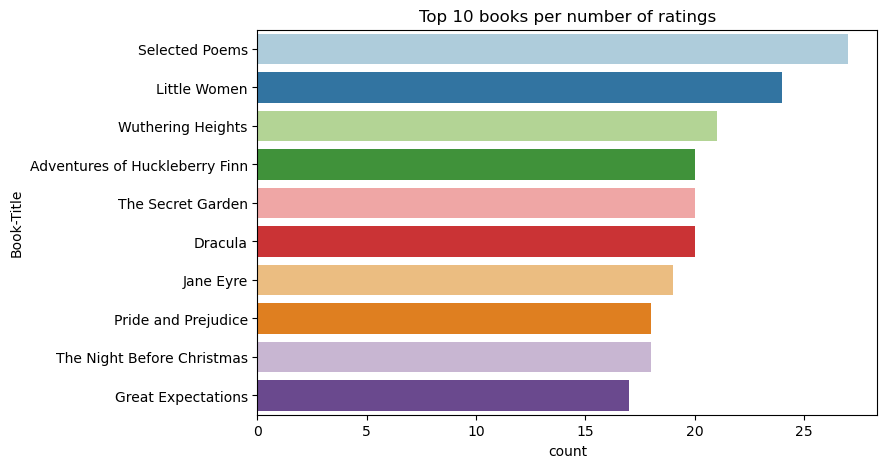
根據評分,詩選 (Selected Poems) 是最熱門的書籍。 《哈克貝利費恩歷險記》、《秘密花園》和《德古拉》的評分相同。
合併資料
將三個 DataFrame 合併成一個 DataFrame,以進行更全面的分析:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
使用此程式碼來顯示相異使用者、書籍和互動的計數:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
計算及繪製最熱門的項目
使用此程式碼來計算及顯示前 10 大熱門書籍:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
提示
使用<topn>或熱門購買推薦區段的 值。
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

準備訓練與測試的資料集
ALS 矩陣在訓練之前需要一些資料準備。 使用此程式碼範例來準備資料。 此程式碼會執行這些動作:
- 將評分資料行轉換成正確的類型
- 使用使用者評分來取樣訓練資料
- 將資料分割成訓練集和測試資料集
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
稀疏性是指稀疏的意見反應資料,無法識別使用者興趣中的相似性。 若要進一步了解資料和目前的問題,請使用此程式碼來計算資料集稀疏性:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
步驟 3:開發和訓練模型
將 ALS 模型訓練,以提供使用者個人化的推薦。
定義模型
Spark ML 提供方便的 API 以建置 ALS 模型。 不過,模型無法可靠地處理資料稀疏性和冷啟動等問題 (當使用者或項目為新時提出建議)。 要改善模型效能,請結合交叉驗證和自動超參數微調。
使用此程式碼匯入模型訓練和評估所需的程式庫:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
微調模型超參數
下一個程式碼範例會建構參數方格,以協助搜尋超參數。 此程式碼也會建立迴歸評估工具,其中會使用均方根誤差 (RMSE) 作為評估計量:
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
下一個程式碼範例會根據預先設定的參數啟動不同的模型微調方法。 如需模型微調的詳細資訊,請參閱 Apache Spark 網站上 ML 微調:模型選取和超參數微調。
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
評估模型
您應該根據測試資料評估模組。 訓練良好的模型應該在資料集上具有高計量。
過度調整的模型可能需要增加訓練資料的大小,或減少一些備援功能。 模型結構描述可能需要變更,或其參數可能需要一些微調。
注意
負 R 平方計量值表示訓練的模型執行得比水平線差。 這項發現表明已訓練的模型不會解釋資料。
若要定義評估函數,請使用下列程式碼:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
使用 MLflow 追蹤實驗
使用 MLflow 來追蹤所有實驗,並記錄參數、計量和模型。 若要開始模型訓練和評估,請使用下列程式碼:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
從工作區選取名為 aisample-recommendation 的實驗,以檢視訓練執行的記錄資訊。 如果您變更實驗名稱,則選取具有新名稱的實驗。 記錄的資訊類似下圖:

步驟 4:載入最終模型以進行評分,並進行預測
完成模型訓練之後,選取最佳模型,載入模型以進行評分 (有時稱為推斷)。 此程式碼會載入模型,並使用預測來為每個使用者推薦前 10 本書:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
輸出看起來會像此資料表:
| _item_id | _user_id | rating | 書名 |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Lives of ... |
| 786 | 7 | 6.2255826 | The Piano Man's D... |
| 45330 | 7 | 4.980466 | State of Mind |
| 38960 | 7 | 4.980466 | All He Ever Wanted |
| 125415 | 7 | 4.505084 | Harry Potter and ... |
| 44939 | 7 | 4.3579073 | Taltos: Lives of ... |
| 175247 | 7 | 4.3579073 | The Bonesetter's ... |
| 170183 | 7 | 4.228735 | Living the Simple... |
| 88503 | 7 | 4.221206 | Island of the Blu... |
| 32894 | 7 | 3.9031885 | Winter Solstice |
將預測儲存到 Lakehouse
使用此程式碼將推薦寫回 Lakehouse:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)