Troubleshoot healthcare data solutions in Microsoft Fabric
This article provides information about some issues or errors you might see when using healthcare data solutions in Microsoft Fabric and how to resolve them. The article also includes some application monitoring guidance.
If your issue continues to persist after following the guidance in this article, create an incident ticket for the support team.
Troubleshoot deployment issues
Sometimes, you might encounter intermittent issues when you deploy healthcare data solutions to the Fabric workspace. Here are some commonly observed problems and workarounds to fix them:
Solution creation fails or takes too long.
Error: Creation of the healthcare solution is in progress for more than 5 minutes, and/or fails.
Cause: This error occurs if there's another healthcare solution that shares the same name, or was recently deleted.
Resolution: If you recently deleted a solution, wait for 30 to 60 minutes before attempting another deployment.
Capability deployment fails.
Error: Capabilities within healthcare data solutions fail to deploy.
Resolution: Verify whether the capability is listed under the Manage deployed capabilities section.
- If the capability isn't listed in the table, try deploying it again. Select the capability tile and then select the Deploy to workspace button.
- If the capability is listed in the table with the status value Deployment failed, redeploy the capability. Alternatively, you can create a new healthcare data solutions environment and redeploy the capability there.
Troubleshoot unidentified tables
When delta tables are created in the lakehouse for the first time, they might temporarily show up as "unidentified" or empty in the Lakehouse Explorer view. However, they should appear correctly under the tables folder after a few minutes.

Rerun data pipeline
To rerun the sample data from end to end, follow these steps:
Run a Spark SQL statement from a notebook to delete all the tables from a lakehouse. Here's an example:
lakehouse_name = "<lakehouse_name>" tables = spark.sql(f"SHOW TABLES IN {lakehouse_name}") for row in tables.collect(): spark.sql(f"DROP TABLE {lakehouse_name}.{row[1]}")Use OneLake file explorer to connect to OneLake in your Windows File Explorer.
Navigate to your workspace folder in Windows File Explorer. Under
<solution_name>.HealthDataManager\DMHCheckpoint, delete all the corresponding folders in<lakehouse_id>/<table_name>. Alternatively, you can also use Microsoft Spark Utilities (MSSparkUtils) for Fabric to delete the folder.Rerun the data pipelines, beginning with the clinical data ingestion in the bronze lakehouse.
Monitor Apache Spark applications with Azure Log Analytics
The Apache Spark application logs are sent to an Azure Log Analytics workspace instance that you can query. Use this sample Kusto query to filter the logs specific to healthcare data solutions:
AppTraces
| where Properties['LoggerName'] contains "Healthcaredatasolutions"
or Properties['LoggerName'] contains "DMF"
or Properties['LoggerName'] contains "RMT"
| limit 1000
The notebook's console logs also log the RunId for each execution. You can use this value to retrieve logs for a specific run as shown in the following sample query:
AppTraces
| where Properties['RunId'] == "<RunId>"
For general monitoring information, see Use the Fabric Monitoring hub.
Use OneLake file explorer
The OneLake file explorer application seamlessly integrates OneLake with Windows file explorer. You can use OneLake file explorer to view any folder or file deployed within your Fabric workspace. You can also see the sample data, OneLake files and folders, and the checkpoint files.
Use Azure Storage Explorer
You can also use Azure Storage Explorer to:
Reset Spark runtime version in the Fabric workspace
By default, all new Fabric workspaces use the latest Fabric runtime version, which is currently Runtime 1.3. However, healthcare data solutions only support Runtime 1.2.
So, after you deploy healthcare data solutions to your workspace, ensure the default Fabric runtime version is set to Runtime 1.2 (Apache Spark 3.4 and Delta Lake 2.4). If not, your data pipeline and notebook executions can fail. For more information, see Multiple runtimes support in Fabric.
Follow these steps to review/update the Fabric runtime version:
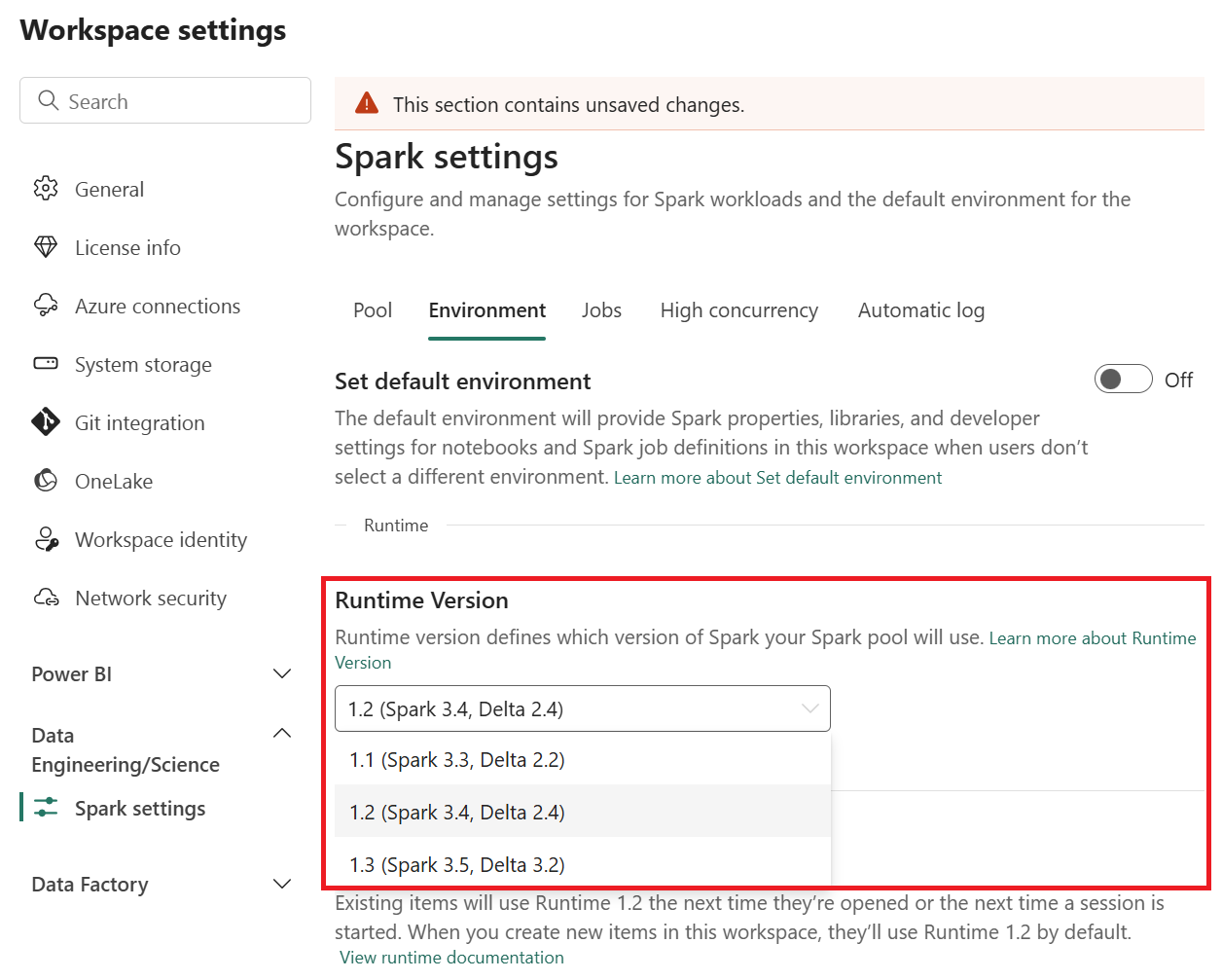
Go to your healthcare data solutions workspace and select Workspace settings.
On the workspace settings page, expand the Data Engineering/Science drop-down box, and select Spark settings.
On the Environment tab, update the Runtime Version value to 1.2 (Spark 3.4, Delta 2.4), and save the changes.

Refresh the Fabric UI and OneLake file explorer
Sometimes, you might notice that the Fabric UI or OneLake file explorer doesn't always refresh the content after each notebook execution. If you don't see the expected result in the UI after running any execution step (such as creating a new folder or lakehouse, or ingesting new data into a table), try refreshing the artifact (table, lakehouse, folder). This refresh can often resolve discrepancies before you explore other options or investigate further.