事件
3月31日 下午11時 - 4月2日 下午11時
最終Microsoft Fabric、Power BI、SQL 和 AI 社群主導的活動。 2025 年 3 月 31 日至 4 月 2 日。
立即註冊此文章以使用 Power BI Desktop 的資料模型製作人員為目標。 其會描述在資料模型中強制執行資料列層級安全性 (RLS) 的良好設計做法。
請務必了解 RLS 會篩選「資料表資料列」。 其無法設定來限制對模型物件的存取,這包括資料表、資料行或量值。
注意
此文章不會說明 RLS 或其設定方式。 如需詳細資訊,請參閱使用 Power BI Desktop 的資料列層級安全性 (RLS) 來限制資料存取。
同時,其也不會涵蓋使用 Azure Analysis Services 或 SQL Server Analysis Services 在針對外部裝載模型的即時連線中強制執行 RLS 的內容。 在這些情況下,RLS 是由 Analysis Services 強制執行。 當 Power BI 使用單一登入 (SSO) 連線時,Analysis Services 將會強制執行 RLS (除非該帳戶具備系統管理員權限)。
您可以建立多個角色。 當您考慮單一報表使用者的權限需求時,請盡量建立能授與所有那些需求的單一角色,而不是使用報表使用者將會是多個角色之成員的設計。 這是因為報表使用者可能會對應至多個角色,無論是使用其使用者帳戶來直接對應,或是透過安全性群組成員資格來間接對應。 多個角色對應可能會導致非預期的結果。
將報表使用者指派至多個角色時,RLS 篩選會相加。 這表示報表使用者可以看見代表那些篩選之聯集的資料表資料列。 此外,在某些案例下,並無法保證報表使用者看不見某個資料表中的資料列。 因此,此情況與套用至 SQL Server 資料庫物件 (及其他權限模型) 的權限不同,並不適用「一旦拒絕便會一律拒絕」的原則。
請考慮具有兩個角色的模型:名為 Workers 的第一個角色,會使用下列規則運算式來限制針對所有 Payroll 資料表資料列的存取:
FALSE()
注意
當規則的運算式評估為 FALSE 時,將不會傳回任何資料表資料列。
但是,名為 Managers 的第二個角色,會使用下列規則運算式來允許針對所有 Payroll 資料表資料列的存取:
TRUE()
請注意:當報表使用者對應至這兩個角色時,其將能看見所有 Payroll 資料表資料列。
RLS 的運作方式是自動將篩選套用到每個 DAX 查詢,而這些篩選對查詢效能可能會有負面影響。 因此,有效率的 RLS 會取決於良好的模型設計。 請務必遵循模型設計指導方針,如下列文章中所述:
一般而言,在維度類型資料表上強制執行 RLS 篩選的效率,會高於在事實類型資料表上執行的效率。 而且需要仰賴設計良好的關聯性,以確保 RLS 篩選能傳播到其他模型資料表上。 RLS 篩選只會透過作用中關聯性傳播。 因此,在使用模型關聯性便能達到相同結果時,請避免使用 LOOKUPVALUE DAX 函數。
每當在 DirectQuery 資料表上強制執行 RLS 篩選,而且存在與其他 DirectQuery 資料表的關聯性時,請務必將來源資料庫最佳化。 這可能會涉及設計適當的索引,或是使用保存的計算資料行。 如需詳細資訊,請參閱 Power BI Desktop 中的 DirectQuery 模型指引。
您可以使用效能分析器在 Power BI Desktop 中測量 RLS 篩選的效能影響。 首先,請判斷未強制執行 RLS 時,報表視覺效果查詢的持續時間。 然後使用 [模型化] 功能區索引標籤上的 [檢視身分] 命令來強制執行 RLS,並判斷及比較查詢持續時間。
發佈至 Power BI 之後,您必須將成員對應至語意模型角色。 只有語意模型擁有者或工作區系統管理員可以將成員新增至角色。 如需詳細資訊,請參閱 Power BI 的資料列層級安全性 (RLS) (管理模型的安全性)。
成員可以是使用者帳戶、安全性群組、通訊群組或啟用郵件的群組。 如果可以的話,建議您將安全性群組對應至語意模型角色。 它牽涉到管理Microsoft Entra標識碼中的安全組成員資格。 可能的話,其會將工作委派給您的網路系統管理員。
測試每個角色來確保其會正確篩選模型。 這可以透過使用 [模型化] 功能區索引標籤上的 [檢視身分] 命令來輕鬆完成。
當模型具有使用 USERNAME DAX 函數的動態規則時,請務必針對預期的和「非預期的」值進行測試。 內嵌 Power BI 內容 (具體而言是使用對客戶進行內嵌案例) 時,應用程式邏輯可以將任何值傳遞為有效的身分識別使用者名稱。 可以的話,請盡可能確保意外或惡意的值所導致的篩選不會傳回任何資料列。
假設一個使用 Power BI 內嵌的範例,其中應用程式會將使用者的作業角色傳遞為有效的使用者名稱:其可以為 "Manager" 或 "Worker"。 Manager 可以看見所有資料列,但 Worker 只能看見 Type 資料行值為 "Internal" 的資料列。
會定義下列規則運算式:
IF(
USERNAME() = "Worker",
[Type] = "Internal",
TRUE()
)
此規則運算式的問題,在於其所有值 (除了 "Worker" 之外) 都會傳回「所有資料表資料列」。 因此,非預期的值 (例如 "Wrker") 將會意外傳回所有資料表資料列。 因此撰寫會針對每個預期的值進行測試的運算式會比較安全。 在下列改善的規則運算式中,非預期的值會導致資料表不會傳回任何資料列。
IF(
USERNAME() = "Worker",
[Type] = "Internal",
IF(
USERNAME() = "Manager",
TRUE(),
FALSE()
)
)
有時候,計算需要未受 RLS 篩選限制的值。 例如,報表可能會需要顯示報表使用者銷售區域的收益與「所有收益」之間的比率。
雖然不可能讓 DAX 運算式覆寫 RLS (事實上,其甚至無法判斷是否已強制執行 RLS),您可以使用摘要模型資料表。 系統會查詢摘要模型資料表以擷取「所有區域」的收益,且其不受任何 RLS 篩選所限制。
讓我們看看您可以如何實作此設計需求。 首先,請考慮下列模型設計:
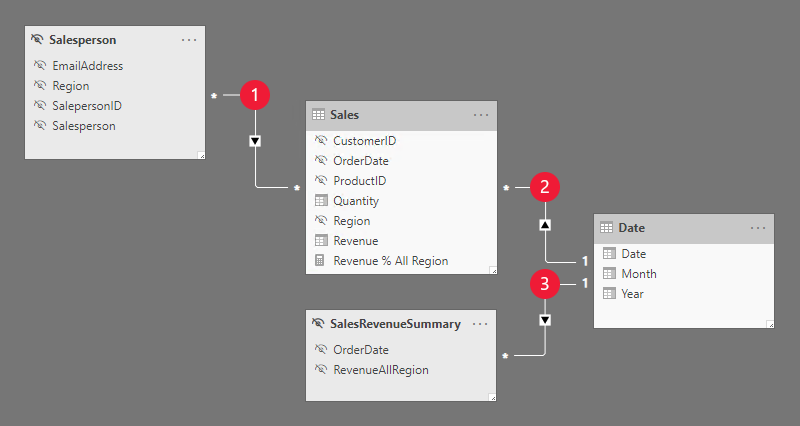
模型包含四個資料表:
下列運算式會定義 SalesRevenueSummary 計算資料表:
SalesRevenueSummary =
SUMMARIZECOLUMNS(
Sales[OrderDate],
"RevenueAllRegion", SUM(Sales[Revenue])
)
注意
彙總資料表可以達成相同的設計需求。
下列 RLS 規則會套用至 Salesperson 資料表:
[EmailAddress] = USERNAME()
下表說明三種模型關聯性:
| 關聯 | 描述 |
|---|---|
 |
Salesperson 和 Sales 資料表之間具有多對多關聯性。 RLS 規則會使用 USERNAME DAX 函數來篩選隱藏 Salesperson 資料表的 EmailAddress 資料行。 Region 資料行值 (適用於報表使用者) 會傳播至 Sales 資料表。 |
 |
Date 和 Sales 資料表之間具有一對多關聯性。 |
 |
Date 和 SalesRevenueSummary 資料表之間具有一對多關聯性。 |
下列運算式會定義 Revenue % All Region 量值:
Revenue % All Region =
DIVIDE(
SUM(Sales[Revenue]),
SUM(SalesRevenueSummary[RevenueAllRegion])
)
注意
請小心避免洩漏敏感性事實。 如果此範例中只有兩個區域,報表使用者便可以計算出另一個區域的收益。
有時候在合理的情況下要避免使用 RLS。 如果您只有會套用靜態篩選的幾個簡單 RLS 規則,請考慮改為發佈多個語意模型。 所有的語意模型都不會定義角色,因為每個語意模型都包含適用於特定報表使用者對象的資料,而這些對象都具有相同的資料權限。 然後,針對每個對象建立單一工作區,並將存取權限指派給該工作區或應用程式。
例如,一家只有兩個銷售區域的公司,決定將「適用於每個銷售區域的」語意模型發佈至不同的工作區。 語意模型不會強制執行 RLS。 不過,其會使用查詢參數
避免使用 RLS 有幾個相關聯的優勢:
不過,避免使用 RLS 有幾個相關聯的缺點:
如果 RLS 產生非預期的結果,請檢查下列問題:
當特定使用者看不見任何資料時,這可能是因為其 UPN 並未儲存,或是以不正確的方式輸入。 這可能會因為其使用者帳戶因名稱變更而變更,所以突然發生。
提示
基於測試目的,請新增會傳回 USERNAME DAX 函數的量值。 您可以將其命名為類似 "Who Am I" (我是誰) 的名稱。 然後將該量值新增到報表中的卡片視覺效果,並將其發佈至 Power BI。
只有語意模型讀取讀取的建立者和取用者只能檢視允許其查看的資料 (根據其 RLS 角色對應)。
當使用者在工作區或應用程式中檢視報表時,RLS 可能會或可能不會根據其語意模型權限強制執行。 基於這個理由,僅在必須強制執行 RLS 時,內容取用者和建立者才擁有基礎語意模型的讀取權限。 如需決定是否強制執行 RLS 的權限規則詳細資訊,請參閱報表取用者安全性規劃一文。
如需本文的詳細資訊,請參閱下列資源:
事件
3月31日 下午11時 - 4月2日 下午11時
最終Microsoft Fabric、Power BI、SQL 和 AI 社群主導的活動。 2025 年 3 月 31 日至 4 月 2 日。
立即註冊訓練
模組
資料列層級安全性 (RLS) 可讓您建立單一報表或一組報表,以挑出資料給特定使用者。 在本課程模組中,您將了解如何使用靜態或動態方法來實作 RLS,以及 Microsoft Power BI 如何在 Power BI Desktop 和 Power BI 服務中簡化測試 RLS。
認證
Microsoft Certified: Power BI Data Analyst Associate - Certifications
示範符合使用 Microsoft Power BI 進行資料建模、視覺化和分析的業務和技術要求的方法和最佳做法。