重要
Machine Learning 工作室 (傳統) 的支援將於 2024 年 8 月 31 日結束。 建議您在該日期之前轉換成 Azure Machine Learning。
自 2021 年 12 月 1 日起,您將無法建立新的 Machine Learning 工作室 (傳統) 資源。 在 2024 年 8 月 31 日之前,您可以繼續使用現有的 Machine Learning 工作室 (傳統) 資源。
ML 工作室 (傳統) 文件即將淘汰,未來將不再更新。
從機器學習實驗執行 Python 腳本
類別: Python 語言模組
模組概觀
本文說明如何在 機器學習 Studio 中使用執行 Python 腳本模組, (傳統) 來執行 Python 程式碼。 如需 Studio 中 Python (傳統) 架構和設計原則的詳細資訊,請參閱 下列文章。
透過 Python,您可以執行現有 Studio 目前不支援的工作, (傳統) 模組,例如:
- 使用 將資料視覺化
matplotlib - 使用 Python 程式庫列舉工作區中的資料集和模型
- 從匯入資料模組不支援的來源讀取、載入及操作資料
機器學習 Studio (傳統) 使用 Python 的 Anaconda 散發,其中包含許多常見的公用程式來進行資料處理。
如何使用執行 Python 腳本
執行 Python 腳本模組包含可用來作為起點的範例 Python 程式碼。 若要設定 執行 Python 腳本 模組,您必須提供一組輸入和 Python 程式碼,以在 [Python 腳本 ] 文字方塊中執行。
將 執行 Python 腳本 模組新增至您的實驗。
捲動至 [ 屬性 ] 窗格底部,針對 [Python 版本],選取腳本中要使用的 Python 程式庫和執行時間版本。
- Python 2.7.7 的 Anaconda 2.0 發行版本
- Python 2.7.11 的 Anaconda 4.0 發行版本
- Python 3.5 的 Anaconda 4.0 發行版本 (預設)
建議您先設定版本,再輸入任何新的程式碼。 如果您稍後變更版本,提示會要求您確認變更。
重要
如果您在實驗中使用多個執行 Python 腳本 模組的實例,則必須為實驗中的所有模組選擇單一版本的 Python。
從 Studio (傳統) 的任何資料集,在 Dataset1 上新增並連接您想要用於輸入的資料集。 在您的 Python 指令碼中,將此資料集參照為 DataFrame1。
如果您想要使用 Python 產生資料,或使用 Python 程式碼直接將資料匯入模組,則使用資料集是選擇性的。
本課程模組支援在 Dataset2上新增第二個 Studio (傳統) 資料集。 在您的 Python 指令碼中,將第二個資料集參照為 DataFrame2。
使用本課程模組載入時,儲存在 Studio (傳統) 中的資料集會自動轉換成 pandas data.frames。
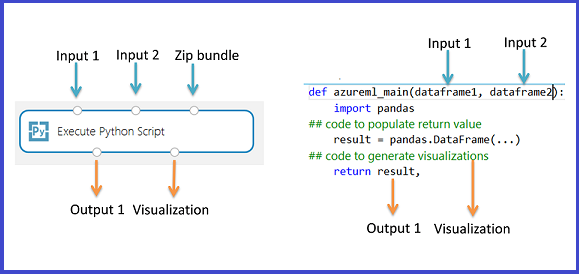
若要包含新的 Python 套件或程式碼,請在 腳本套件組合上新增包含這些自訂資源的壓縮檔案。 腳本套件組合的輸入必須是已上傳至工作區的壓縮檔案。 如需如何準備和上傳這些資源的詳細資訊,請參閱 解壓縮壓縮的資料。
上傳壓縮封存中包含的任何檔案都可以在實驗執行期間使用。 如果封存包含目錄結構,則會保留結構,但您必須在路徑前面加上名為 src 的目錄。
在 [Python 指令碼] 文字輸入框中,輸入或貼上有效的 Python 指令碼。
Python 腳本文字方塊會預先填入批註中的一些指示,以及資料存取和輸出的範例程式碼。 您必須編輯或取代此程式碼。 請務必遵循有關縮排和大小寫的 Python 慣例。
- 腳本必須包含名為
azureml_main的函式,作為此課程模組的進入點。 - 進入點函式最多可以包含兩個輸入引數:
Param<dataframe1>和Param<dataframe2> - 連接到第三個輸入埠的壓縮檔會解壓縮並儲存在目錄中,
.\Script Bundle這也會新增至 Pythonsys.path。
因此,如果您的 zip 檔案包含
mymodule.py,請使用import mymodule匯入它。- 單一資料集可以傳回至 Studio (傳統) ,必須是 類型的
pandas.DataFrame序列。 您可以在 Python 程式碼中建立其他輸出,並將其直接寫入 Azure 儲存體,或使用 Python 裝置建立視覺效果。
- 腳本必須包含名為
執行實驗,或選取模組,然後按一下 [執行] 以 只執行 Python 腳本。
所有資料和程式碼都會載入虛擬機器,並使用指定的 Python 環境執行。
結果
模組會傳回這些輸出:
結果資料集。 內嵌 Python 程式碼所執行的任何計算結果都必須以 pandas data.frame 的形式提供,此框架會自動轉換成機器學習資料集格式,讓您可以將結果與實驗中的其他模組搭配使用。 模組僅限於單一資料集作為輸出。 如需詳細資訊,請參閱 資料表。
Python 裝置。 此輸出支援主控台輸出和 PNG 圖形使用 Python 解譯器顯示。
如何附加腳本資源
「執行 Python 腳本」模組支援任意 Python 腳本檔案作為輸入,前提是它們已事先備妥,並上傳至工作區作為.ZIP檔案的一部分。
將包含 Python 程式碼的 ZIP 檔案Upload至您的工作區
在 機器學習 Studio 的實驗區域中, (傳統) ,按一下 [資料集],然後按一下 [新增]。
選取 [ 從本機檔案] 選項。
在[Upload新的資料集] 對話方塊中,按一下 [選取新資料集類型] 的下拉式清單,然後選取[Zip 檔案] (.zip) 選項。
按一下 [流覽 ] 以找出壓縮檔案。
輸入要用於工作區的新名稱。 您指派給資料集的名稱會成為工作區中擷取內含檔案的資料夾名稱。
將壓縮套件上傳至 Studio (傳統) 之後,請確認已 儲存的資料集 清單中有壓縮檔,然後將資料集連線到 腳本套件組合 輸入埠。
ZIP 檔案中包含的所有檔案都可在執行時間使用:例如範例資料、腳本或新的 Python 套件。
如果您的壓縮檔案包含任何尚未安裝在 機器學習 Studio 中的程式庫, (傳統) ,您必須在自訂腳本中安裝 Python 程式庫套件。
如果有目錄結構存在,則會保留該目錄結構。 不過,您必須變更程式碼,以將目錄 src 前面加上路徑。
對 Python 程式碼進行偵錯
當程式碼已以明確定義的輸入和輸出作為函式,而不是鬆散相關的可執行語句序列時, 執行 Python 腳本 模組最適合。
此 Python 模組不支援 Intellisense 和偵錯等功能。 如果模組在執行時間失敗,您可以在模組的輸出記錄檔中檢視一些錯誤詳細資料。 不過,無法使用完整的 Python 堆疊追蹤。 因此,我們建議使用者在不同的環境中開發和偵錯其 Python 腳本,然後將程式碼匯入模組。
您可以尋找的一些常見問題:
檢查您要從
azureml_main傳回之資料框架中的資料類型。 如果資料行包含數數值型別和字串以外的資料類型,可能會發生錯誤。使用
dataframe.dropna()從 Python 腳本匯出時,從資料集移除 NA 值。 準備您的資料時,請使用 清除遺漏的資料 模組。檢查內嵌程式碼是否有縮排和空白字元錯誤。 如果您收到錯誤「縮排Error:預期縮排區塊」,請參閱下列資源以取得指引:
已知的限制
Python 執行時間已沙箱化,不允許以持續性方式存取網路或本機檔案系統。
所有本機儲存的文件都會被隔離,並且在模組結束時加以刪除。 Python 程式碼無法在其執行的機器上存取大部分的目錄,但目前的目錄及其子目錄例外。
當您提供壓縮檔作為資源時,會將檔案從工作區複製到實驗執行空間、解壓縮,然後使用。 複製和解壓縮資源可能會耗用記憶體。
模組可以輸出單一資料框架。 無法傳回任意 Python 物件,例如將定型的模型直接傳回 Studio (傳統) 執行時間。 不過,您可以將物件寫入儲存體或工作區。 另一個選項是使用
pickle將多個物件序列化成位元組陣列,然後傳回資料框架內的陣列。
範例
如需將 Python 腳本與 Studio (傳統) 實驗整合的範例,請參閱 Azure AI 資源庫中的這些資源:
- 執行 Python 腳本:使用 執行 Python 腳本 模組使用文字標記化、字幹分析和其他自然語言處理。
- Azure ML中的自訂 R 和 Python 腳本:逐步引導您完成將自訂程式碼新增至 (R 或 Python) 、處理資料和視覺化結果的程式。
- 分析 PyPI 資料以判斷 Python 3 支援:使用 Python 2.7 的 Python 3 需求時,預估其需求。