原始產品版本:SQL Server
原始 KB 編號: 243589
簡介
本文說明如何處理資料庫應用程式在使用 SQL Server 時可能會遇到的效能問題:特定查詢或查詢群組的效能變慢。 下列方法可協助您縮小查詢緩慢問題的原因,並引導您解決。
尋找緩慢的查詢
若要確定您在 SQL Server 實例上有查詢效能問題,請從檢查查詢的運行時間(經過的時間)開始。 根據已建立的效能基準,檢查時間是否超過您已設定的臨界值(以毫秒為單位)。 例如,在壓力測試環境中,您可能已為工作負載建立不超過 300 毫秒的閾值,而且您可以使用此閾值。 然後,您可以識別超過該閾值的所有查詢,專注於每個個別查詢及其預先建立的效能基準持續時間。 最後,商務用戶會關心資料庫查詢的整體持續時間;因此,主要焦點在於執行持續時間。 收集 CPU 時間和邏輯讀取等其他計量,以協助縮小調查範圍。
針對目前執行的語句,請檢查sys.dm_exec_requests中的total_elapsed_time和cpu_time數據行。 執行下列查詢以取得資料:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;如需查詢的過去執行,請檢查sys.dm_exec_query_stats中的last_elapsed_time和last_worker_time數據行。 執行下列查詢以取得資料:
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESC注意
如果
avg_wait_time顯示負值,則為 平行查詢。如果您可以在 SQL Server Management Studio (SSMS) 或 Azure Data Studio 中視需要執行查詢,請使用 SET STATISTICS TIME
ON和 SET STATISTICS IOON來執行查詢。SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFF然後,您會從 訊息中看到 CPU 時間、經過的時間,以及如下所示的邏輯讀取:
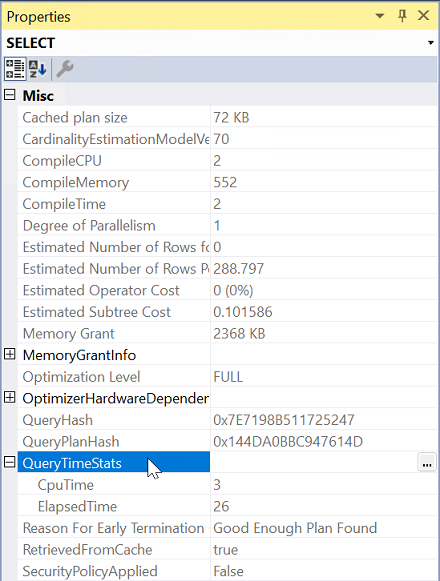
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.如果可以收集查詢計劃,請檢查執行 計劃屬性中的數據。
使用 [包含實際執行計劃] 執行查詢。
從 [執行計劃] 選取最左邊的運算子。
從 [屬性] 展開 [QueryTimeStats ] 屬性。
檢查 ElapsedTime 和 CpuTime。
執行與等候:查詢為何速度緩慢?
如果您發現超過預先定義閾值的查詢,請檢查它們可能變慢的原因。 效能問題的原因可以分成兩個類別,執行或等候:
等候:查詢可能會變慢,因為它們在等候瓶頸很長一段時間。 請參閱等候類型中瓶頸的詳細清單。
執行:查詢可能會很慢,因為它們長時間執行(執行中)。 換句話說,這些查詢會主動使用CPU資源。
系統可以將查詢執行一段時間,並在其存留期 (期限) 中等待一段時間。 不過,您的焦點是判斷哪一個是導致其長時間耗用時間的主要類別。 因此,第一項工作就是確定查詢屬於哪個類別。 很簡單:如果查詢未執行,則正在等候。 在理想情況下,查詢會花費大部分已耗用的時間處於執行中狀態,而且等待資源的時間很少。 此外,在最佳案例中,查詢會在預先決定的基準內或以下執行。 比較查詢經過的時間和CPU時間,以判斷問題類型。
類型 1:CPU 系結(執行器)
如果 CPU 時間接近、等於或高於經過的時間,您可以將它視為 CPU 系結查詢。 例如,如果經過的時間是 3000 毫秒(毫秒),而 CPU 時間是 2900 毫秒,這表示大部分經過的時間都花在 CPU 上。 然後我們可以說這是 CPU 系結的查詢。
執行 (CPU 系結) 查詢的範例:
| 經過的時間 (毫秒) | CPU 時間 (毫秒) | 讀取 (邏輯) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
邏輯讀取 - 讀取快取中的數據/索引頁面 - 最常是 SQL Server 中 CPU 使用率的驅動程式。 在某些情況下,CPU 使用來自其他來源:while 迴圈(在 T-SQL 或其他程式代碼中,例如 XProcs 或 SQL CRL 物件)。 數據表中的第二個範例說明這類案例,其中大部分的CPU不是來自讀取。
注意
如果 CPU 時間大於持續時間,這表示已執行平行查詢;多個線程同時使用CPU。 如需詳細資訊,請參閱 平行查詢 - 執行器或等候者。
類型 2:等候瓶頸 (等候者)
如果經過的時間明顯大於 CPU 時間,查詢會等候瓶頸。 經過的時間包括在 CPU 上執行查詢的時間(CPU 時間),以及等候釋放資源的時間(等候時間)。 例如,如果經過的時間是 2000 毫秒,而 CPU 時間是 300 毫秒,則等候時間為 1700 毫秒(2000 - 300 = 1700)。 如需詳細資訊,請參閱 等候類型。
等候查詢的範例:
| 經過的時間 (毫秒) | CPU 時間 (毫秒) | 讀取 (邏輯) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
平行查詢 - 執行器或等候者
平行查詢可能會使用比整體持續時間更多的CPU時間。 平行處理原則的目標是允許多個線程同時執行查詢的部分。 在時鐘時間的一秒內,查詢可能會藉由執行八個平行線程來使用八秒的CPU時間。 因此,根據經過的時間和CPU時間差異,判斷CPU系結或等候查詢會變得很困難。 不過,一般規則遵循上述兩節所列的原則。 摘要為:
- 如果經過的時間遠大於 CPU 時間,請考慮它是等候者。
- 如果 CPU 時間遠大於經過的時間,請考慮它為執行器。
平行查詢的範例:
| 經過的時間 (毫秒) | CPU 時間 (毫秒) | 讀取 (邏輯) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1500000 |
方法的高階視覺表示法

診斷並解決等待中的查詢
如果您已確定感興趣的查詢是服務員,下一個步驟就是專注於解決瓶頸問題。 否則,請移至步驟 4: 診斷並解決執行中的查詢。
若要優化等候瓶頸的查詢,請找出等候的時間長度,以及瓶頸所在的位置(等候類型)。 確認等候類型之後,請減少等候時間,或完全排除等候。
若要計算大約等候時間,請從查詢經過的時間減去 CPU 時間(背景工作時間)。 一般而言,CPU 時間是實際運行時間,而查詢存留期的剩餘部分正在等候。
如何計算近似等候持續時間的範例:
| 經過的時間 (毫秒) | CPU 時間 (毫秒) | 等候時間 (毫秒) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
識別瓶頸或等候
若要識別歷程記錄長時間等候的查詢(例如, >20% 的整體經過時間是等候時間),請執行下列查詢。 此查詢會針對 SQL Server 開頭之後的快取查詢計劃使用效能統計數據。
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESC若要識別目前執行超過 500 毫秒的查詢,請執行下列查詢:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1如果可以收集查詢計劃,請檢查 SSMS 中執行計劃屬性中的 WaitStats:
- 使用 [包含實際執行計劃] 執行查詢。
- 在 [執行計劃] 索引標籤中,以滑鼠右鍵按兩下最左邊的運算子
- 選取 [屬性],然後選取 [WaitStats] 屬性。
- 檢查 WaitTimeMs 和 WaitType。
如果您熟悉 PSSDiag/SQLdiag 或 SQL LogScout LightPerf/GeneralPerf 案例,請考慮使用其中一個來收集效能統計數據,並識別 SQL Server 實例上的等候查詢。 您可以匯入收集的數據檔,並使用 SQL Nexus 分析效能數據。
協助消除或減少等候的參考
每個等候類型的原因和解決方式會有所不同。 沒有一個一般方法可以解析所有等候類型。 以下是疑難解答和解決常見等候類型問題的文章:
- 瞭解並解決封鎖問題 (LCK_M_*)
- 了解並解決 Azure SQL 資料庫封鎖問題
- 針對 I/O 問題所造成的 SQL Server 效能緩慢進行疑難解答(PAGEIOLATCH_*、WRITELOG、IO_COMPLETION、BACKUPIO)
- 解決 SQL Server 中最後一頁插入 PAGELATCH_EX 爭用
- 記憶體授與說明和解決方案 (RESOURCE_SEMAPHORE)
- 針對ASYNC_NETWORK_IO等候類型所產生的慢速查詢進行疑難解答
- 針對具有AlwaysOn可用性群組的高HADR_SYNC_COMMIT等候類型進行疑難解答
- 運作方式:CMEMTHREAD 和偵錯
- 讓平行處理原則等候可採取動作 (CXPACKET 和 CXCONSUMER)
- THREADPOOL 等候
如需許多 Wait 類型及其指示的描述,請參閱 Waits 類型中的表格。
診斷並解決執行中的查詢
如果 CPU(背景工作角色)時間非常接近整體經過的持續時間,則查詢會花費大部分的存留期執行。 一般而言,當 SQL Server 引擎驅動高 CPU 使用量時,高 CPU 使用量來自驅動大量邏輯讀取的查詢(最常見的原因)。
若要識別目前負責高 CPU 活動的查詢,請執行下列語句:
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
如果查詢目前並未驅動 CPU,您可以執行下列語句來尋找歷程記錄的 CPU 系結查詢:
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
要解決長時間執行、與 CPU 繫結的查詢所用的常見方法
- 檢查查詢的查詢計劃
- 更新統計資料
- 識別並套用遺漏索引。 如需如何識別遺漏索引的詳細資訊,請參閱 使用遺漏索引建議調整非叢集索引
- 重新設計或重寫查詢
- 識別並解決參數敏感性計劃
- 找出並解決 SARG 能力問題
- 找出並解決 長時間執行巢狀迴圈可能是由 TOP、EXISTS、IN、FAST、SET ROWCOUNT、OPTION (FAST N) 所造成的數據列目標 問題。 如需詳細資訊,請參閱 數據列目標消失 Rogue 和 Showplan 增強功能 - 數據列目標 EstimateRowsWithoutRowGoal
- 評估和解決 基數估計 問題。 如需詳細資訊,請參閱 從 SQL Server 2012 或更早版本升級至 2014 或更新版本之後降低查詢效能
- 識別並解決似乎從未完成的查詢,請參閱 針對似乎永遠不會在 SQL Server 中結束的查詢進行疑難解答
- 識別並解決 受優化器逾時影響的慢速查詢
- 識別高 CPU 效能問題。 如需詳細資訊,請參閱 針對 SQL Server 中的高 CPU 使用量問題進行疑難解答
- 針對兩部伺服器之間效能差異顯著的查詢進行疑難排解
- 增加系統上的計算資源 (CPU)
- 針對窄和寬方案的UPDATE效能問題進行疑難解答