تنسيقات الملفات المعتمدة وبرامج ضغط الوسائط وفكها في Azure Data Factory وSynapse Analytics (النظام القديم)
ينطبق على:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
تنطبق هذه المقالة على الموصلات التالية القائمة على الملفات: المتوافقة مع: Amazon S3، Azure Blob، Azure Data Lake Storage Gen1، Azure Data Lake Storage Gen2، Azure Files، File System، FTP، Google Cloud Storage، HDFS، HTTP، SFTP.
هام
قدمت الخدمة نموذج مجموعة بيانات جديد يستند إلى التنسيق، راجع مقالة التنسيق المقابلة مع التفاصيل:
- تنسيق Avro
- تنسيق ثنائي
- تنسيق نص محدد
- تنسيق JSON
- تنسيق ORC
- تنسيق باركيه
لا تزال التكوينات الأخرى المذكورة في هذه المقالة معتمدة كما هي للتوافق مع الإصدارات السابقة. يُقترح عليك استخدام النموذج الجديد من الآن فصاعداً.
تنسيق النص (قديم)
إشعار
يمكنك التعرف على النموذج الجديد من مقالة تنسيق النص المحدد. التكوينات التالية فيما يتعلق بمجموعة بيانات مخزن البيانات القائم على الملفات لا تزال معتمدة كما هي للتوافق مع الإصدارات السابقة. يُقترح عليك استخدام النموذج الجديد من الآن فصاعداً.
إذا كنت تريد القراءة من ملف نصي أو الكتابة إلى ملف نصي، يمكنك تعيين type الخاصية في قسم مجموعة البيانات إلى formatTextFormat. يمكنك أيضاً تحديد الخصائص الاختيارية التالية في قسم format. يمكنك الاطلاع على قسم مثال TextFormat حول كيفية التكوين.
| الخاصية | الوصف | القيم المسموح بها | المطلوب |
|---|---|---|---|
| columnDelimiter | هو الحرف المستخدم في فصل الأعمدة في الملفات. حيث يمكنك التفكير في استخدام حرف نادر غير قابل للطباعة قد لا يكون موجودًا في بياناتك. على سبيل المثال، حدد "\u0001" الذي يمثل بداية العنوان (SOH). | يُسمح باستخدام حرف واحد فقط. القيمة الافتراضية هي الفاصلة ('،'). لاستخدام حرف Unicode، يمكنك الاطلاع على أحرف Unicode للحصول على التعليمات البرمجية المطابقة لها. |
لا |
| rowDelimiter | هو الحرف المُستخدم لفصل الصفوف في الملفات. | يُسمح باستخدام حرف واحد فقط. القيمة الافتراضية هي أي من القيم التالية في القراءة: ["\r\n" و"\r" و"\n"] و"\r\n" عند الكتابة. | لا |
| escapeChar | هو الحرف الخاص المستخدم للهروب من محدِّد عمود في محتوى ملف الإدخال. لا يمكنك تحديد كلٍ من escapeChar وquoteChar معاً لجدول واحد. |
يُسمح باستخدام حرف واحد فقط. لا يحتوي على قيمة افتراضية. مثال: إذا كان لديك فاصلة ('،') كمحدِّد عمود ولكن تريد أن يكون لديك حرف الفاصلة في النص (مثال: "مرحبا، أيها العالم")، يمكنك تعريف '$' كحرف الهروب واستخدام سلسلة "مرحبا$، العالم" في المصدر. |
لا |
| quoteChar | هو الحرف المستخدم في اقتباس قيمة سلسلة. سيتم التعامل مع محدِّدات الأعمدة والصفوف داخل أحرف الاقتباس كجزء من قيمة السلسلة. تنطبق هذه الخاصية على مجموعات بيانات الإدخال والإخراج. لا يمكنك تحديد كلٍ من escapeChar وquoteChar معاً لجدول واحد. |
يُسمح باستخدام حرف واحد فقط. لا يحتوي على قيمة افتراضية. على سبيل المثال، إذا كان لديك فاصلة ('،') كمحدِّد عمود ولكن تريد أن يكون حرف فاصلة في النص (مثال: <Hello, world>)، يمكنك تعريف " (علامات الاقتباس المزدوجة) كحرف اقتباس واستخدام السلسلة "مرحباً، أيها العالم" في المصدر. |
لا |
| قيمة خالية | هو حرف واحد أو أكثر يستخدم لتمثيل قيمة خالية. | يحتوي على حرف واحد أو أكثر. القيم الافتراضية هي "\N" و"NULL" في القراءة و"\N" عند الكتابة. | لا |
| encodingName | هو محدِّد اسم الترميز. | يحتوي على اسم ترميز صالح. يمكنك الاطلاع على خاصية Encoding.EncodingName. مثال: يمكنك كتابة windows-1250 أو shift_jis. القيمة الافتراضية هي UTF-8. | لا |
| firstRowAsHeader | يحدِّد ما إذا كان سيتم اعتبار الصف الأول كعنوان. وبالنسبة لمجموعة بيانات الإدخال، تقرأ الخدمة الصف الأول كعنوان. وبالنسبة لمجموعة بيانات الإخراج، تكتب الخدمة الصف الأول كعنوان. يمكنك الاطلاع على سيناريوهات الاستخدام firstRowAsHeader وskipLineCountعينة السيناريوهات. |
صواب خطأ (افتراضي) |
لا |
| skipLineCount | يشير إلى عدد الصفوف غير الفارغة المطلوب تخطيها عند قراءة البيانات من ملفات الإدخال. إذا تم تحديد كل من skipLineCount وfirstRowAsHeader، يتم تخطي الأسطر أولا ثم تتم قراءة معلومات العنوان من ملف الإدخال. يمكنك الاطلاع على سيناريوهات الاستخدام firstRowAsHeader وskipLineCountعينة السيناريوهات. |
Integer | لا |
| treatEmptyAsNull | يُحدِّد ما إذا كان سيتم التعامل مع سلسلة فارغة أو خالية كقيمة فارغة عند قراءة البيانات من ملف إدخال. | صحيح (افتراضي) خطأ |
لا |
مثال TextFormat
تُحدَّد بعض الخصائص الاختيارية، في تعريف JSON التالي لمجموعة بيانات.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
لاستخدام escapeChar بدلاً من quoteChar، استبدل السطر المزود بـ quoteChar بـ escapeChar التالي:
"escapeChar": "$",
سيناريوهات لاستخدام FirstRowAsHeader وskipLineCount
- أنت تنسخ من مصدر بصيغة أخرى إلى ملف نصي وتريد إضافة سطر عنوان يحتوي على بيانات التعريف للمخطط (على سبيل المثال: مخطط SQL). يمكنك تحديد
firstRowAsHeaderكإدخال صحيح في مجموعة بيانات الإخراج لهذا السيناريو. - أنت تنسخ من ملف نصي يحتوي على سطر عنوان إلى مصدر بصيغة أخرى وترغب في إسقاط هذا السطر. يمكنك تحديد
firstRowAsHeaderكإدخال صحيح في مجموعة بيانات الإدخال. - أنت تنسخ من ملف نصي وتريد تخطي بضعة أسطر في البداية التي لا تحتوي على أي بيانات أو معلومات حول العنوان. يمكنك تحديد
skipLineCountللإشارة إلى عدد الأسطر التي ستتخطاها. يمكنك أيضاً تحديدfirstRowAsHeaderإذا كانت الأجزاء الأخرى من الملف تحتوي على سطر العنوان. إذا حُدِّد كلٌ منskipLineCountوfirstRowAsHeader، يجب تخطي الأسطر أولاً ثم قراءة معلومات العنوان من ملفات الإدخال
تنسيق JSON (قديم)
إشعار
تعرف على النموذج الجديد من مقالة تنسيق JSON. التكوينات التالية فيما يتعلق بمجموعة بيانات مخزن البيانات القائم على الملفات لا تزال معتمدة كما هي للتوافق مع الإصدارات السابقة. يُقترح عليك استخدام النموذج الجديد من الآن فصاعداً.
لاستيراد/تصدير ملف JSON كما هو من/إلى Azure Cosmos DB، راجع استيراد/تصدير قسم مستندات JSON في مقالة نقل البيانات من/إلى Azure Cosmos DB.
إذا كنت تريد تحليل ملفات JSON أو كتابة البيانات بتنسيق JSON، يمكنك تحديد خاصية type في قسم format على تنسيق JSON. يمكنك أيضاً تحديد الخصائص الاختيارية التالية في قسم format. يمكنك الاطلاع على قسم مثال JsonFormat حول كيفية التكوين.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| filePattern | يشير إلى نمط البيانات المخزنة في كل ملف JSON. القيم المسموح بها هي: setOfObjects وarrayOfObjects. القيمة الافتراضية هي setOfObjects. يمكنك الاطلاع على قسم أنماط ملفات JSON للحصول على تفاصيل أكثر حول هذه الأنماط. | لا |
| jsonNodeReference | إذا كنت تريد تكرار البيانات واستخراجها من الكائنات الموجودة داخل حقل صفيف بنفس النمط، فعليك تحديد مسار JSON لذلك الصفيف. تُعتمد هذه الخاصية فقط عند نسخ البيانات من ملفات JSON. | لا |
| jsonPathDefinition | يحدد تعبير مسار JSON لكل تعيين عمود باسم عمود مخصص (ابدأ بالأحرف الصغيرة). تُعتمد هذه الخاصية فقط عند نسخ البيانات من ملفات JSON، ويمكنك استخراج البيانات من كائن أو صفيف. بالنسبة للحقول الموجودة تحت الكائن الجذر يمكنك البدء بالجذر $؛ وللحقول داخل الصفيف الذي اختير بواسطة خاصية jsonNodeReference، يمكنك البدء من عنصر الصفيف. يمكنك الاطلاع على قسم مثال JsonFormat حول كيفية التكوين. |
لا |
| encodingName | هو محدِّد اسم الترميز. للحصول على قائمة أسماء ترميز صالحة راجع: خاصية Encoding.EncodingName. على سبيل المثال: windows-1250 أو shift_jis. القيمة الافتراضية هي: UTF-8. | لا |
| nestingSeparator | الحرف المستخدم لفصل مستويات التداخل. القيمة الافتراضية هي '.' (نقطة). | لا |
إشعار
بالنسبة لحالة البيانات ذات التطبيق المتقاطع في الصفيف داخل صفوف متعددة (الحالة 1 -> عينة 2 في أمثلة JsonFormat)، يمكنك فقط اختيار توسيع صفيف واحد باستخدام خاصية jsonNodeReference.
أنماط ملفات JSON
يمكن لنشاط النسخ تحليل الأنماط التالية لملفات JSON:
الفئة الأولى: setOfObjects
يحتوي كل ملف على كائن واحد، أو كائنات متعددة محددة الأسطر/متسلسلة. عند اختيار هذا الخيار في مجموعة بيانات الإخراج، يُنتج نشاط النسخ ملف JSON واحد مع كل كائن (محدد السطر) لكل سطر.
مثال نموذج JSON كائن واحد
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }مثال نموذج JSON محدد الأسطر
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}مثال JSON المتصل
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
الفئة الثانية: arrayOfObjects
يحتوي كل ملف على صفيف من العناصر.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
مثال JsonFormat
الحالة 1: نسخ البيانات من ملفات JSON
نموذج 1: استخراج البيانات من الكائن والصفيف
أنت تتوقع، في هذا النموذج، تعيين كائن جذر واحد JSON لسجل واحد في نتيجة جدولية. إذا كان لديك ملف JSON يحتوي على التالي:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
وتريد نسخه إلى جدول Azure SQL بالتنسيق التالي، يمكنك القيام بذلك من خلال استخراج البيانات من كلٍّ من الكائنات والصفيف:
| بطاقة تعريف | DeviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | كمبيوتر شخصي | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 1/13/2017 11:24:37 صباحاً |
تُعرّف مجموعة بيانات الإدخال المزودة بنوع JsonFormat كما يلي: (تعريف جزئي مع الأجزاء ذات الصلة فقط). أكثر تحديدًا:
structureيحدد القسم أسماء الأعمدة المخصصة ونوع البيانات المطابق أثناء التحويل إلى بيانات جدولية. هذا القسم اختياري إلا إذا كنت بحاجة إلى تعيين العمود. لمزيد من المعلومات، يمكنك الاطلاع على تعيين أعمدة مجموعة البيانات المصدر إلى أعمدة مجموعة البيانات الوجهة.jsonPathDefinitionيحدد مسار JSON لكل عمود يشير إلى مكان استخراج البيانات. لنسخ البيانات من الصفيف، يمكنك استخدامarray[x].propertyلاستخراج قيمة الخاصية المعطى من كائنxth، أو يمكنك استخدامarray[*].propertyللبحث عن القيمة من أي كائن يحتوي على مثل هذه الخاصية.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
النموذج الثاني: تطبيق متقاطع لعدة كائنات بنفس النمط من الصفيف
في هذا النموذج، أنت تتوقع تحويل كائن جذر واحد JSON إلى سجلات متعددة في نتيجة جدولية. إذا كان لديك ملف JSON يحتوي على التالي:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
وتريد نسخه إلى جدول azure SQL بالتنسيق التالي، عن طريق تسوية البيانات داخل الصفيف وتقاطع الانضمام مع معلومات الجذر الشائعة:
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
تُعرّف مجموعة بيانات الإدخال المزودة بنوع JsonFormat كما يلي: (تعريف جزئي مع الأجزاء ذات الصلة فقط). أكثر تحديدًا:
structureيحدد القسم أسماء الأعمدة المخصصة ونوع البيانات المطابق أثناء التحويل إلى بيانات جدولية. هذا القسم اختياري إلا إذا كنت بحاجة إلى تعيين العمود. لمزيد من المعلومات، يمكنك الاطلاع على تعيين أعمدة مجموعة البيانات المصدر إلى أعمدة مجموعة البيانات الوجهة.jsonNodeReferenceيشير إلى التكرار واستخراج البيانات من الكائنات ذات نفس النمط ضمن صفيفorderlines.jsonPathDefinitionيحدد مسار JSON لكل عمود يشير إلى مكان استخراج البيانات. في هذا المثال، يكونordernumberوorderdateوcityضمن كائن جذر ويبدؤون مسار JSON بـ$.، بينما يُعرّفorder_pdوorder_priceبمسار مشتق من عنصر صفيف من غير$..
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
لاحظ النقاط التالية:
- إذا لم يُعرّف كلٌّ من
structureوjsonPathDefinitionفي مجموعة البيانات، يكتشف نشاط النسخ المخطط من الكائن الأول ذلك ويُبسِّط الكائن بأكمله. - إذا كان الإدخال JSON يحتوي على صفيف بشكل افتراضي، يُحوِّل نشاط النسخ قيمة الصفيف بأكمله إلى سلسلة. يمكنك اختيار استخراج البيانات منه باستخدام
jsonNodeReferenceو/أوjsonPathDefinition، أو تخطيها بعدم تحديدها فيjsonPathDefinition. - يختار نشاط النسخ آخر اسم، إذا كانت هناك أسماء مكررة في نفس المستوى.
- أسماء الخصائص حساسة لحالة الأحرف. يُتعامل مع الخاصيتين اللتين تحملان نفس الاسم ولكن تحتويان على كتابات مختلفة كخاصيتين منفصلتين.
الحالة 2: كتابة البيانات إلى ملف JSON
إذا كان لديك الجدول التالي في قاعدة بيانات SQL:
| بطاقة تعريف | order_date | سعر الطلب | order_by |
|---|---|---|---|
| 1 | 20170119 | 2000 | ديفيد |
| 2 | 20170120 | 3500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
وأنت تتوقع، بالنسبة لكل سجل، الكتابة إلى كائن JSON بالتنسيق التالي:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
تُعرّف مجموعة بيانات الإخراج المزودة بنمط JsonFormat كما يلي: (تعريف جزئي مع الأجزاء ذات الصلة فقط). وبشكل أكثر دقة، يُعرّف قسم structure أسماء الخصائص المخصصة في ملف الوجهة، وnestingSeparator (الافتراضي هو ".") المستخدم لتحديد طبقة التداخل من الاسم. هذا القسم اختياري إلا إذا كنت تريد تغيير اسم الخاصية مقارنة مع اسم العمود المصدر أو تضمين بعض الخصائص.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
تنسيق باركيه (قديم)
إشعار
تعرف على النموذج الجديد من مقالة تنسيق باركيه. التكوينات التالية فيما يتعلق بمجموعة بيانات مخزن البيانات القائم على الملفات لا تزال معتمدة كما هي للتوافق مع الإصدارات السابقة. يُقترح عليك استخدام النموذج الجديد من الآن فصاعداً.
إذا كنت ترغب في تحليل ملفات باركيه أو كتابة البيانات بتنسيق باركيه، عيّن خاصية formattype على تنسيق باركيه. فأنت لا تحتاج إلى تحديد أي خصائص في قسم التنسيق ضمن قسم typeProperties. مثال:
"format":
{
"type": "ParquetFormat"
}
لاحظ النقاط التالية:
- أنواع البيانات المعقدة (MAP، LIST) غير معتمدة.
- المسافة البيضاء في اسم العمود غير مدعومة.
- يحتوي ملف باركيه على الخيارات التالية المتعلقة بالضغط: NONE، وSNAPPY، وGZIP، وLZO. تدعم الخدمة قراءة البيانات من ملف باركيه في أي من هذه التنسيقات المضغوطة باستثناء LZO - فهي تستخدم برنامج ترميز الضغط في بيانات التعريف لقراءة البيانات. غير أن الخدمة تختار برنامج الترميز SNAPPY، عند الكتابة إلى ملف باركيه، وهو الافتراضي لتنسيق باركيه. حالياً، لا يوجد خيار لتجاوز هذا السلوك.
هام
بالنسبة للنسخة المُمكّنة بواسطة وقت تشغيل التكامل المستضاف ذاتياً، على سبيل المثال: بين مخازن البيانات المحلية والسحابية، إذا كنت لا تنسخ ملفات باركيه كما هي، فأنت بحاجة إلى تثبيت 64 بت JRE 8 (Java Runtime Environment) أو OpenJDK على جهاز IR الخاص بك. اطلع على الفقرة التالية مع مزيد من التفاصيل.
بالنسبة للنسخة التي تعمل على وقت تشغيل التكامل المستضاف ذاتياً مع تسلسل/إلغاء تسلسل ملف Parquet، تحدد الخدمة وقت تشغيل Java عن طريق التحقق أولاً من السجل (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) لـ JRE، إذا لم يتم العثور عليه، وثانياً تتحقق من متغير النظام JAVA_HOME لـ OpenJDK.
- لاستخدام JRE: يتطلب IR 64 بت JRE 64 بت. يمكنك العثور عليه من هنا.
- لاستخدام OpenJDK: معتمد منذ إصدار IR 3.13. جمّع jvm.dll مع كل التجميعات الأخرى المطلوبة من OpenJDK في جهاز وقت تشغيل التكامل المستضاف ذاتياً، وعيّن متغير بيئة النظام JAVA_HOME وفقاً لذلك.
تلميح
إذا قمت بنسخ البيانات من /إلى تنسيق باركيه باستخدام وقت تشغيل التكامل المستضاف ذاتياً وظهرت رسالة خطأ تقول "حدث خطأ عند استدعاء جافا، الرسالة: java.lang.OutOfMemoryError:Java heap space"، يمكنك إضافة متغير بيئة _JAVA_OPTIONS في الجهاز الذي يستضيف وقت تشغيل التكامل المستضاف ذاتياً لضبط الحد الأدنى / الأقصى لحجم كومة الذاكرة المؤقتة لـ JVM لتمكين هذه النسخة، ثم إعادة تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية.
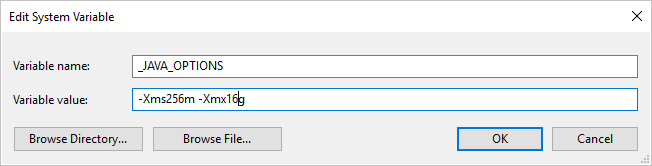
كمثال: تعيين متغير _JAVA_OPTIONS مع قيمة -Xms256m -Xmx16g. تحدد العلامة Xms تجمع تخصيص الذاكرة الأولى لآلة جافا الافتراضية (JVM)، بينما تحدد Xmx مجموعة تخصيص الذاكرة القصوى. هذا يعني أن JVM ستبدأ بمقدار Xms من الذاكرة وستكون قادرة على استخدام الحد الأقصى من الذاكرة بمقدار Xmx. تستخدم الخدمة الحد الأدنى 64 ميجابايت 1 جيجا بايت كحد أقصى، بشكل افتراضي.
تعيين نوع البيانات لملفات باركيه
| نوع بيانات الخدمة المؤقتة | نوع باركيه الأولي | نوع باركيه الأصلي (إلغاء التسلسل) | نوع باركيه الأصلي (التسلسل) |
|---|---|---|---|
| قيمة منطقية | قيمة منطقية | غير متوفر | غير متوفر |
| SByte | Int32 | Int8 | Int8 |
| بايت | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/ثنائي | UInt64 | عدد عشري |
| فردي | Float | غير متوفر | غير متوفر |
| مزدوج | مزدوج | غير متوفر | غير متوفر |
| عدد عشري | ثنائي | عدد عشري | عدد عشري |
| السلسلة | ثنائي | Utf8 | Utf8 |
| DateTime | Int96 | غير متوفر | غير متوفر |
| TimeSpan | Int96 | غير متوفر | غير متوفر |
| DateTimeOffset | Int96 | غير متوفر | غير متوفر |
| ByteArray | ثنائي | غير متوفر | غير متوفر |
| Guid | ثنائي | Utf8 | Utf8 |
| Char | ثنائي | Utf8 | Utf8 |
| CharArray | غير مدعوم | غير متوفر | غير متوفر |
تنسيق ORC (قديم)
إشعار
تعرف على النموذج الجديد من مقالة تنسيق ORC. التكوينات التالية فيما يتعلق بمجموعة بيانات مخزن البيانات القائم على الملفات لا تزال معتمدة كما هي للتوافق مع الإصدارات السابقة. يُقترح عليك استخدام النموذج الجديد من الآن فصاعداً.
إذا كنت ترغب في تحليل ملفات ORC أو كتابة البيانات بتنسيق ORC، فعيّن خاصية formattype على تنسيق Orc. فأنت لا تحتاج إلى تحديد أي خصائص في قسم التنسيق ضمن قسم typeProperties. مثال:
"format":
{
"type": "OrcFormat"
}
لاحظ النقاط التالية:
- أنواع البيانات المعقدة غير معتمدة (STRUCT، MAP، LIST، UNION).
- المسافة البيضاء في اسم العمود غير مدعومة.
- يحتوي ملف ORC على ثلاثة خيارات متعلقة بالضغط: NONE وZLIB وSNAPPY. تدعم الخدمة قراءة البيانات من ملف ORC في أي من هذه التنسيقات المضغوطة. يستخدم برنامج ترميز الضغط الموجود في بيانات التعريف لقراءة البيانات. ومع ذلك، عند الكتابة إلى ملف ORC، تختار الخدمة ZLIB، وهو الافتراضي لملفات ORC. حالياً، لا يوجد خيار لتجاوز هذا السلوك.
هام
بالنسبة للنسخة المُمكّنة بواسطة وقت تشغيل التكامل المستضاف ذاتياً، على سبيل المثال: بين مخازن البيانات المحلية والسحابية، إذا كنت لا تنسخ ملفات ORC كما هي، فأنت بحاجة إلى تثبيت 64 بت JRE 8 (Java Runtime Environment) أو OpenJDK على جهاز IR الخاص بك. اطلع على الفقرة التالية مع مزيد من التفاصيل.
بالنسبة للنسخة التي تعمل على وقت تشغيل التكامل المستضاف ذاتياً مع تسلسل/إلغاء تسلسل ملف ORC، تحدد الخدمة وقت تشغيل Java عن طريق التحقق أولاً من السجل (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) لـ JRE، إذا لم يتم العثور عليه، وثانياً تتحقق من متغير النظام JAVA_HOME لـ OpenJDK.
- لاستخدام JRE: يتطلب IR 64 بت JRE 64 بت. يمكنك العثور عليه من هنا.
- لاستخدام OpenJDK: معتمد منذ إصدار IR 3.13. جمّع jvm.dll مع كل التجميعات الأخرى المطلوبة من OpenJDK في جهاز وقت تشغيل التكامل المستضاف ذاتياً، وعيّن متغير بيئة النظام JAVA_HOME وفقاً لذلك.
تعيين نوع البيانات لملفات ORC
| نوع بيانات الخدمة المؤقتة | أنواع ORC |
|---|---|
| قيمة منطقية | قيمة منطقية |
| SByte | بايت |
| بايت | قصير |
| Int16 | قصير |
| UInt16 | Int |
| Int32 | Int |
| UInt32 | طويل |
| Int64 | طويل |
| UInt64 | السلسلة |
| فردي | Float |
| مزدوج | مزدوج |
| عدد عشري | عدد عشري |
| السلسلة | السلسلة |
| DateTime | طابع زمني |
| DateTimeOffset | طابع زمني |
| TimeSpan | طابع زمني |
| ByteArray | ثنائي |
| Guid | السلسلة |
| Char | Char(1) |
تنسيق AVRO (قديم)
إشعار
تعرف على النموذج الجديد من مقالة تنسيق Avro. التكوينات التالية فيما يتعلق بمجموعة بيانات مخزن البيانات القائم على الملفات لا تزال معتمدة كما هي للتوافق مع الإصدارات السابقة. يُقترح عليك استخدام النموذج الجديد من الآن فصاعداً.
إذا كنت ترغب في تحليل ملفات Avro أو كتابة البيانات بتنسيق Avro، فعيّن خاصية formattype على تنسيق Avro. فأنت لا تحتاج إلى تحديد أي خصائص في قسم التنسيق ضمن قسم typeProperties. مثال:
"format":
{
"type": "AvroFormat",
}
لاستخدام تنسيق Avro في جدول Apache Hive، يمكنك الاطلاع على البرنامج التعليمي لـ Apache Hive.
لاحظ النقاط التالية:
- أنواع البيانات المعقدة غير معتمدة (سجلات، وقوائم التعدادات، والصفائف، والمخططات، والاتحادات، والقيم الثابتة).
دعم الضغط (قديم)
تدعم الخدمة بيانات عمليات الضغط/إلغاء الضغط أثناء النسخ. عند تحديدك لخاصية خاصية compression في مجموعة بيانات الإدخال، يقرأ نشاط النسخ البيانات المضغوطة من المصدر ويفك الضغط عنها؛ وعندما تحدد الخاصية في مجموعة بيانات الإخراج، يضغط نشاط النسخ البيانات ثم يكتبها إلى المتلقي. فيما يلي بعض نماذج السيناريوهات:
- يمكنك قراءة بيانات GZIP المضغوطة من Azure blob، وفك ضغطها، ثم كتابة بيانات النتائج إلى قاعدة بيانات Azure SQL. يمكنك تعريف مجموعة بيانات الإدخال Azure Blob بالخاصية
compressiontypeعلى شكل GZIP. - يمكنك قراءة البيانات من ملف نص عادي من نظام الملفات المحلي، ثم ضغطه باستخدام تنسيق GZip، وكتابة البيانات المضغوطة إلى كائن ثنائي كبير الحجم في Azure. مجموعة بيانات الإخراج لكائن ثنائي كبير الحجم Azure مع
compressiontypeالخاصية على شكل GZip. - يمكنك قراءة ملف .zip من خادم FTP، وفك الضغط عنه للحصول على الملفات التي بداخله، ثم أنزل تلك الملفات في Azure Data Lake Store. يمكنك تعريف مجموعة بيانات الإدخال FTP مع خاصية
compressiontypeعلى شكل ZipDeflate. - يمكنك قراءة البيانات المضغوطة GZIP من كائن ثنائي كبير الحجم Azure، وفك الضغط عنه، ثم ضغطه باستخدام BZIP2، وكتابة بيانات النتيجة إلى كائن ثنائي كبير الحجم Azure. يمكنك تعريف مجموعة بيانات الإدخال كائن ثنائي كبير الحجم Azure مع خاصية
compressiontypeوتعيينها إلى GZIP وتعريف مجموعة بيانات الإخراج مع خاصيةcompressiontypeوتعيينها إلى BZIP2.
لتحديد الضغط لمجموعة بيانات، يمكنك استخدام خاصية الضغط في مجموعة البيانات JSON كما في المثال التالي:
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
يحتوي قسم الضغط على خاصيتين:
النوع: برنامج ترميز الضغط، والذي يمكن أن يكون GZIPأو Deflateأو BZIP2أو ZipDeflate. ملاحظة عند استخدام نشاط النسخ لإلغاء ضغط ملفات ZipDeflate والكتابة إلى مخزن البيانات المتلقي القائمة على الملف، سَتُستخرج الملفات إلى المجلد:
<path specified in dataset>/<folder named as source zip file>/.مستوى عمليات الضغط: يظهر نسبة عمليات الضغط، والتي يمكن أن تكون الأمثل أو الأسرع.
الأسرع: يجب أن تكتمل عملية الضغط بأسرع وقت ممكن، حتى إذا لم يتم ضغط الملف الناتج بشكل أمثل.
الأمثل : يجب ضغط عملية الضغط على النحو الأمثل، حتى لو استغرقت العملية وقتاً أطول حتى تكتمل.
لمزيد من المعلومات، يمكنك الاطلاع على موضوع مستوى الضغط.
إشعار
إعدادات الضغط غير معتمدة للبيانات في تنسيق Avroأو OrcFormatأو ParquetFormat. تكتشف الخدمة برنامج ترميز الضغط في بيانات التعريف وتستخدمه، عند قراءة الملفات في هذه التنسيقات. تختار الخدمة برنامج ترميز الضغط الافتراضي لهذا التنسيق، عند الكتابة إلى الملفات في هذه التنسيقات. على سبيل المثال، تختار برنامج الترميز ZLIB لتنسيق ORC وبرنامج الترميز SNAPPY لـ ParquetFormat.
أنواع الملفات غير المعتمدة وتنسيقات عمليات الضغط
يمكنك استخدام ميزات قابلية التوسع لتحويل الملفات غير المعتمدة. يتضمن خياري وظائف Azure والمهام المخصصة باستخدام Azure Batch.
يمكنك مشاهدة نموذج يستخدم دالة Azure لاستخراج محتويات ملف tar. للحصول على مزيدٍ من المعلومات، يُرجى الاطلاع على نشاط وظائف Azure.
يمكنك أيضاً إنشاء هذه الوظيفة باستخدام نشاط dotnet المخصص. يمكنك الاطلاع على مزيد من المعلومات المتاحة هنا
المحتوى ذو الصلة
تعرف على أحدث تنسيقات وعمليات ضغط الملفات المدعومة من تنسيقات وعمليات ضغط الملفات المدعومة.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ