إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
في هذا البرنامج التعليمي، ستتعلم كيفية استخدام Jupyter Notebook لإنشاء تطبيق التعلم الآلي من Apache Spark ل Azure HDInsight.
MLlib هي مكتبة التعلم الآلي القابلة للتكيف في Spark التي تتكون من خوارزميات التعلم الشائعة والأدوات المساعدة. (التصنيف، الانحدار، التجميع، التصفية التعاونية، تقليل الأبعاد. أيضاً، العناصر الأساسية للتحسين الأساسي.)
في هذا البرنامج التعليمي، تتعلم كيفية:
- تطوير تطبيق التعلم الآلي Apache Spark
المتطلبات الأساسية
مجموعة Apache Spark على HDInsight. راجع إنشاء مجموعة Apache Spark .
الإلمام باستخدام Jupyter Notebooks مع Spark على HDInsight. لمزيد من المعلومات، راجع تحميل البيانات وتشغيل الاستعلامات باستخدام Apache Spark على HDInsight.
فهم مجموعة البيانات
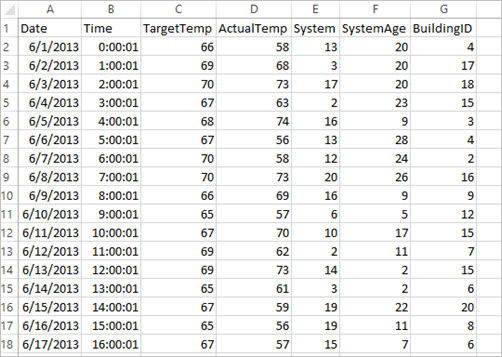
يستخدم التطبيق نموذج بيانات HVAC.csv المتوفرة على جميع المجموعات بشكل افتراضي. الملف موجود في \HdiSamples\HdiSamples\SensorSampleData\hvac. توضح البيانات درجة الحرارة المستهدفة، ودرجة الحرارة الفعلية لبعض المباني التي تحتوي على أنظمة HVAC مثبتة. يمثل عمود النظام معرف النظام ويمثل عمود SystemAge عدد السنوات التي كان فيها نظام HVAC في المبنى. يمكنك توقع ما إذا كان المبنى سيكون أكثر سخونة أو برودة بناءً على درجة الحرارة المستهدفة، ومعرف النظام، وعمر النظام.
قم بتطوير تطبيق Spark للتعلم الآلي باستخدام Spark MLlib
يستخدم هذا التطبيق مسار Spark ML للقيام بتصنيف مستند. توفر خطوط البنية الأساسية للتعلم الآلي مجموعة موحدة من واجهات برمجة التطبيقات عالية المستوى المبنية فوق إطارات البيانات. تساعد إطارات البيانات المستخدمين على إنشاء وضبط البنية الأساسية للتعلم الآلي العملية. في البنية الأساسية، تقوم بتقسيم المستند إلى كلمات، وتحويل الكلمات إلى متجه ميزة رقمية، وأخيرًا تقوم ببناء نموذج تنبؤ باستخدام متجهات السمات والتسميات. قم بالخطوات التالية لإنشاء التطبيق.
قم بإنشاء دفتر ملاحظات Jupyter باستخدام PySpark kernel. للحصول على الإرشادات، راجع إنشاء ملف دفتر ملاحظات Jupyter.
قم باستيراد الأنواع المطلوبة لهذا السيناريو. الصق القصاصة البرمجية التالية في خلية فارغة، ثم اضغط على SHIFT + ENTER.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayقم بتحميل البيانات (hvac.csv) وقم بتحليلها، واستخدمها لتدريب النموذج.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()في القصاصة البرمجية، تقوم بتعريف وظيفة تقارن درجة الحرارة الفعلية بدرجة الحرارة المستهدفة. إذا كانت درجة الحرارة الفعلية أكبر، يكون المبنى ساخنا، ويدل على ذلك بالقيمة 1.0. وإلا فإن المبنى بارد، ويدل على القيمة 0.0.
تكوين مسار التعلم الآلي Spark الذي يتكون من ثلاث مراحل:
tokenizerوhashingTFوlr.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])لمزيد من المعلومات حول البنية الأساسية لبرنامج ربط العمليات التجارية وكيفية عملها، راجع البنية الأساسية لبرنامج ربط العمليات التجارية للتعلم الآلي من Apache Spark.
قم بملاءمة البنية الأساسية في وثيقة التدريب.
model = pipeline.fit(training)تحقق من وثيقة التدريب للتحقق من تقدمك في التطبيق.
training.show()يتشابه الإخراج مع:
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+مقارنة المخرجات بملف CSV الخام. على سبيل المثال، يحتوي الصف الأول من ملف CSV على هذه البيانات:

لاحظ كيف أن درجة الحرارة الفعلية أقل من درجة الحرارة المستهدفة مما يشير إلى أن المبنى بارد. قيمة التسمية في الصف الأول هي 0.0، مما يعني أن المبنى ليس ساخنا.
قم بإعداد مجموعة بيانات لتشغيل النموذج المدرب مقابلها. للقيام بذلك، يمكنك تمرير معرف النظام وعمر النظام (يسمى SystemInfo في إخراج التدريب). يتنبأ النموذج بما إذا كان المبنى الذي يحتوي على معرّف النظام وعمر النظام سيكون أكثر سخونة (يُشار إليه بـ 1.0) أو أكثر برودة (يُشار إليه بـ 0.0).
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()أخيرًا، قم بعمل تنبؤات على بيانات الاختبار.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)يتشابه الإخراج مع:
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))لاحظ الصف الأول في التنبؤ. بالنسبة لنظام HVAC مع المعرف 20 وعمر النظام 25 عاما، يكون المبنى ساخنا (prediction=1.0). تتوافق القيمة الأولى لـ DenseVector (0.49999) مع التنبؤ 0.0 والقيمة الثانية (0.5001) تتوافق مع التنبؤ 1.0. في الإخراج، على الرغم من أن القيمة الثانية أعلى بشكل هامشي فقط، يظهر النموذج prediction=1.0.
إيقاف تشغيل دفتر الملاحظات لتحرير الموارد. للقيام بذلك، من قائمة ملف في دفتر الملاحظات، حدد إغلاق وإيقاف. يتم إغلاق هذا الإجراء، وإغلاق دفتر الملاحظات.
استخدم مكتبة Anaconda scikit-Learn للتعلم الآلي في Spark
تتضمن مجموعات Apache Spark في HDInsight مكتبات Anaconda. كما يتضمن مكتبة scikit-learn للتعلم الآلي. تتضمن المكتبة أيضًا مجموعات بيانات متنوعة يمكنك استخدامها لإنشاء تطبيقات نموذجية مباشرةً من دفتر ملاحظات Jupyter. للحصول على أمثلة حول استخدام مكتبة scikit-learn، راجع https://scikit-learn.org/stable/auto_examples/index.html.
تنظيف الموارد
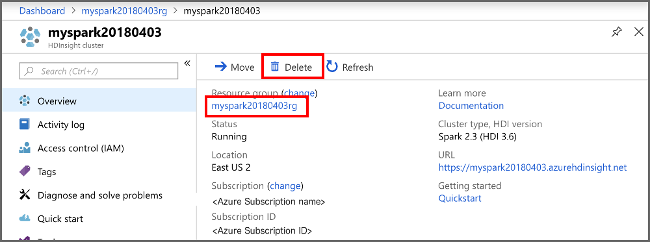
إذا كنت لن تستمر في استخدام هذا التطبيق، فاحذف المجموعة التي قمت بإنشائها عن طريق اتباع الخطوات التالية:
قم بتسجيل الدخول إلى بوابة Azure.
في المربع بحث في الأعلى، اكتب HDInsight.
حدد مجموعات HDInsight ضمن الخدمات.
في قائمة مجموعات HDInsight التي تظهر، حدد ... بجانب المجموعة التي قمت بإنشائها لهذا البرنامج التعليمي.
حدد حذف. حدد نعم.
الخطوات التالية
في هذا البرنامج التعليمي، تعلمت كيفية استخدام Jupyter Notebook لإنشاء تطبيق التعلم الآلي Apache Spark لـ Azure HDInsight. تقدم إلى البرنامج التعليمي التالي لمعرفة كيفية استخدام IntelliJ IDEA لوظائف Spark.