تصحيح مهام Apache Spark التي تعمل على Azure HDInsight
في هذه المقالة، تتعلم كيفية تعقب وتصحيح مهام Apache Spark قيد التشغيل على أنظمة مجموعات HDInsight. قم بالتصحيح باستخدام واجهة المستخدم Apache Hadoop YARN، وواجهة المستخدم Spark وخادم محفوظات Spark. يمكنك بدء تشغيل مهمة Spark باستخدام دفتر ملاحظات متوفر مع نظام مجموعة Spark، التعلم الآلي: تحليل تنبؤي على بيانات فحص الأغذية باستخدام MLLib. استخدم الخطوات التالية لتعقب تطبيق قمت بإرساله باستخدام أي نهج آخر أيضاً، على سبيل المثال، إرسال spark.
في حال لم يكن لديك اشتراك Azure، فأنشئ حساباً مجانيّاً قبل البدء.
المتطلبات الأساسية
مجموعة Apache Spark على HDInsight. للحصول على إرشادات، يرجى مراجعة إنشاء مجموعات Apache Spark في Azure HDInsight.
يجب أن تكون قد بدأت تشغيل دفتر الملاحظات، التعلم الآلي: تحليل تنبؤي على بيانات فحص الأغذية باستخدام MLLib. للحصول على إرشادات حول كيفية تشغيل دفتر الملاحظات هذا، اتبع الارتباط.
تعقب تطبيق في واجهة المستخدم YARN
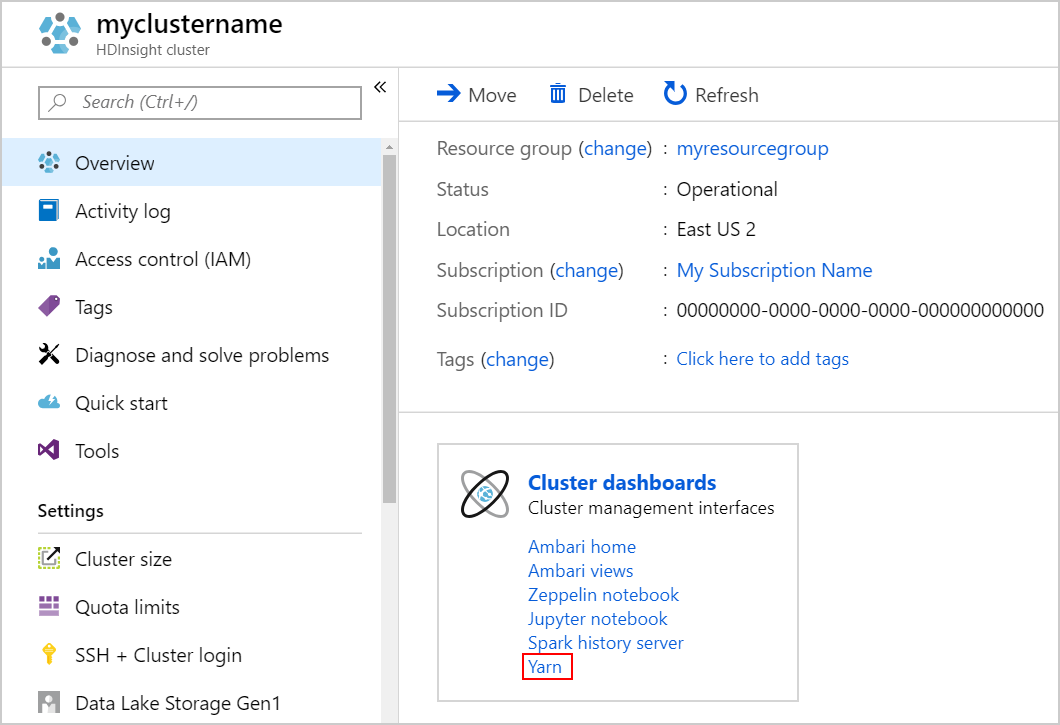
قم بتشغيل واجهة المستخدم YARN. حدد Yarn ضمن Cluster dashboards.
تلميح
بدلاً من ذلك، يمكنك أيضاً تشغيل واجهة المستخدم YARN من واجهة المستخدم Ambari. لتشغيل واجهة المستخدم Ambari، حدد Ambari home ضمن Cluster dashboards. من واجهة المستخدم Ambari، انتقل إلى "YARN>Quick Links> the active Resource Manager >Resource Manager UI".
لأنه تم بدء تشغيل مهمة Spark باستخدام دفاتر الملاحظات Jupyter، يحتوي التطبيق على اسم remotesparkmagics (اسم كافة التطبيقات التي تم تشغيلها من دفاتر الملاحظات). حدد معرف التطبيق مقابل اسم التطبيق للحصول على مزيد من المعلومات حول المهمة. يقوم هذا الإجراء بتشغيل طريقة عرض التطبيق.
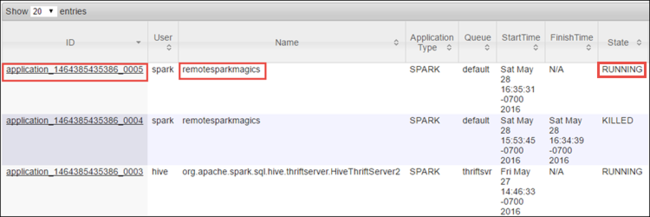
بالنسبة لمثل هذه التطبيقات التي يتم تشغيلها من دفاتر الملاحظات Jupyter، تكون الحالة قيد التشغيل دائماً حتى تقوم بإنهاء دفتر الملاحظات.
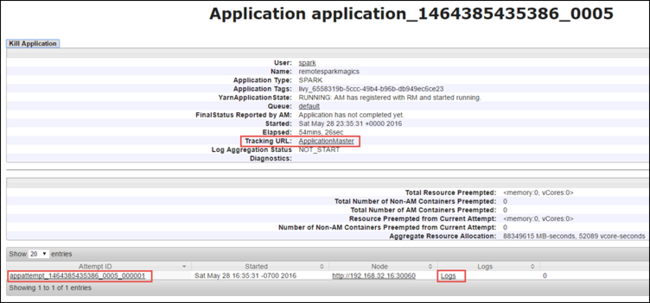
من طريقة عرض التطبيق، يمكنك التنقل لأسفل لمعرفة الحاويات المقترنة بالتطبيق والسجلات (stdout/stderr). يمكنك أيضاً تشغيل واجهة مستخدم Spark بالنقر على الرابط المطابق لـ عنوان URL للتعقب، كما هو موضح أدناه.
تعقب تطبيق في واجهة المستخدم Spark
في واجهة المستخدم Spark، يمكنك التنقل لأسفل إلى مهام Spark التي تم إنتاجها بواسطة التطبيق الذي بدأته سابقاً.
لتشغيل واجهة المستخدم Spark، من طريقة عرض التطبيق، حدد الارتباط مقابل عنوان URL للتعقب، كما هو موضح في لقطة الشاشة أعلاه. يمكنك عرض كافة مهام Spark التي يتم تشغيلها بواسطة التطبيق قيد التشغيل في دفتر ملاحظات Jupyter.
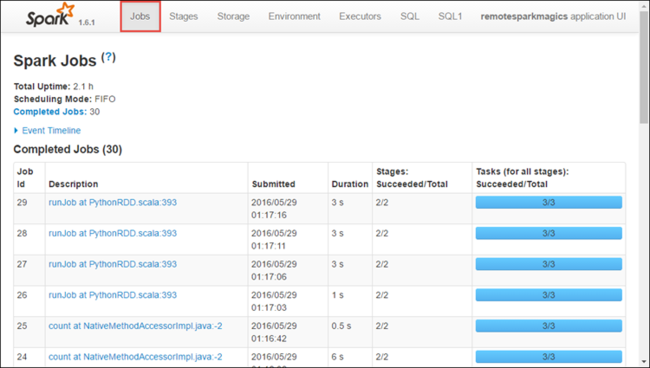
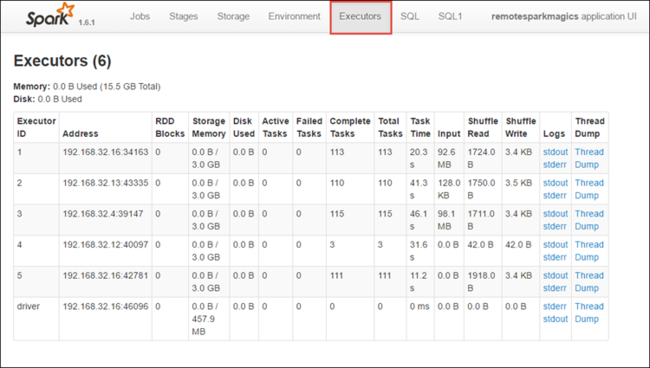
حدد علامة التبويب المنفذين لعرض معلومات المعالجة والتخزين لكل منفذ. يمكنك أيضاً استرداد مكدس الاستدعاءات عن طريق تحديد ارتباط Thread Dump.
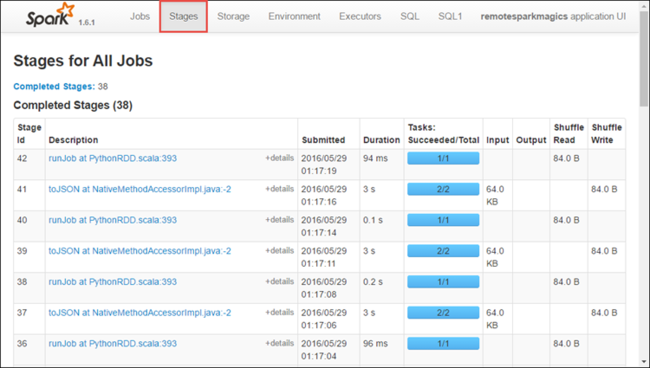
حدد علامة التبويب Stages لعرض المراحل المقترنة بالتطبيق.
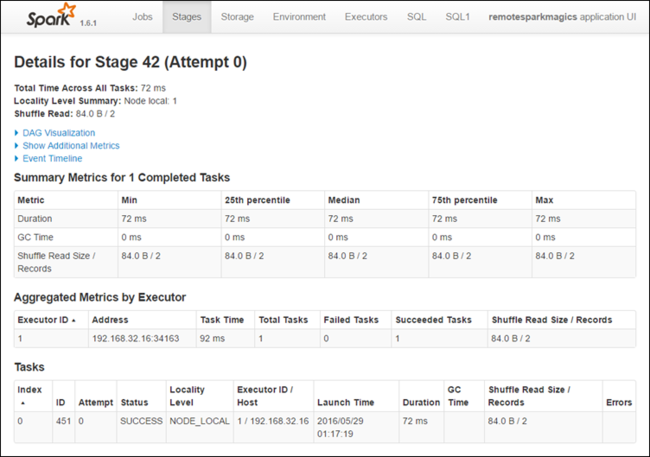
يمكن أن يكون لكل مرحلة مهام متعددة يمكنك عرض إحصائيات التنفيذ لها، كما هو موضح أدناه.
من صفحة تفاصيل المرحلة، يمكنك تشغيل مرئيات DAG. قم بتوسيع ارتباط DAG Visualization في أعلى الصفحة، كما هو موضح أدناه.
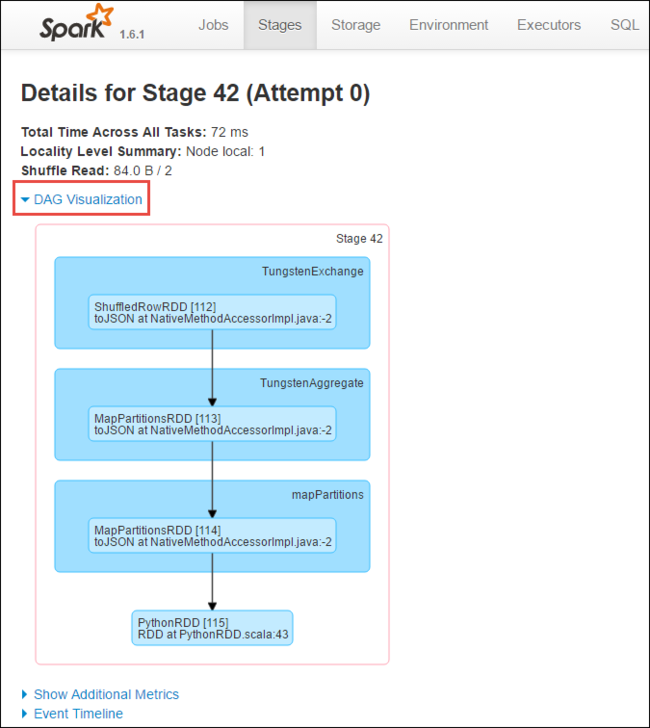
يمثل DAG أو Direct Aclyic Graph المراحل المختلفة في التطبيق. يمثل كل مربع أزرق في الرسم البياني عملية Spark التي تم استدعاؤها من التطبيق.
من صفحة تفاصيل المرحلة، يمكنك أيضاً تشغيل عرض المخطط الزمني للتطبيق. قم بتوسيع ارتباط Event Timeline في أعلى الصفحة، كما هو موضح أدناه.
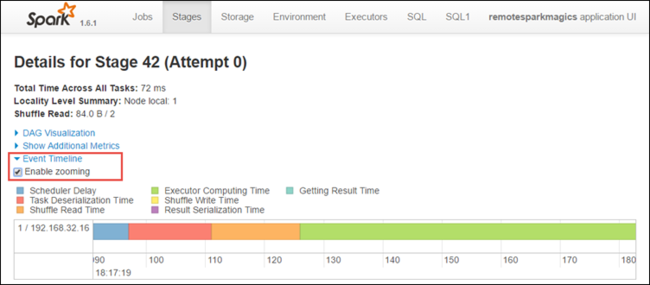
تعرض هذه الصورة أحداث Spark في شكل مخطط زمني. يتوفر عرض المخطط الزمني على ثلاثة مستويات، عبر المهام، ضمن مهمة وضمن مرحلة. تسجل الصورة أعلاه طريقة عرض المخطط الزمني لمرحلة معينة.
تلميح
إذا قمت بتحديد خانة الاختيار Enable zooming، يمكنك التمرير يميناً ويساراً عبر طريقة عرض المخطط الزمني.
توفر علامات التبويب الأخرى في واجهة مستخدم Spark معلومات مفيدة حول مثيل Spark أيضاً.
- علامة تبويب Storage - إذا كان التطبيق الخاص بك ينشئ RDD، يمكنك العثور على معلومات في علامة التبويب Storage.
- علامة التبويب البيئة - توفر علامة التبويب هذه معلومات مفيدة حول مثيل Spark الخاص بك مثل:
- إصدار Scala
- دليل سجل الأحداث المقترن بنظام المجموعة
- عدد الذاكرات الأساسية للمنفذين للتطبيق
البحث عن معلومات حول المهام المكتملة باستخدام خادم محفوظات Spark
بمجرد اكتمال مهمة، يتم استمرار المعلومات حول المهمة في خادم محفوظات Spark.
لتشغيل خادم محفوظات Spark، من صفحة Overview، حدد Spark history server ضمن Cluster dashboards.
تلميح
بدلاً من ذلك، يمكنك أيضاً تشغيل واجهة مستخدم خادم محفوظات Spark من واجهة المستخدم Ambari. لتشغيل واجهة المستخدم Ambari، من جزء Overview، حدد Ambari home ضمن Cluster dashboards. من واجهة المستخدم Ambari، تنقل إلى Spark2>Quick Links>واجهة مستخدم خادم محفوظات Spark2.
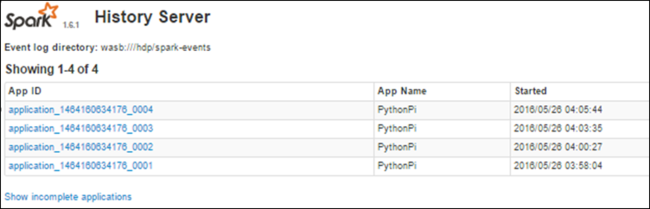
ستتمكن من عرض كافة التطبيقات المكتملة التي تم سردها. حدد معرف تطبيق للتنقل لأسفل أحد التطبيقات للحصول على مزيد من المعلومات.
(راجع أيضًا )
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ