ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
في هذه المقالة، ستتعلم كيفية تثبيت Jupyter Notebook باستخدام نواة PySpark المخصصة (لـ Python) وApache Spark (لـ Scala) باستخدام Spark magic. ثم تقوم بتوصيل الكمبيوتر الدفتري بمجموعة HDInsight.
هناك أربع خطوات رئيسة متضمنة في تثبيت Jupyter والاتصال بـ Apache Spark على HDInsight.
- تكوين مجموعة Spark.
- قم بتثبيت Jupyter Notebook.
- قم بتثبيت نواة PySpark وSpark باستخدام Spark magic.
- قم بتكوين Spark magic للوصول إلى نظام مجموعة Spark على HDInsight.
لمزيدٍ من المعلومات حول kernels المخصصة وSpark magic، راجع Kernels المتوفرة لأجهزة Jupyter Notebooks مع مجموعات Apache Spark Linux على HDInsight.
المتطلبات الأساسية
مجموعة Apache Spark على HDInsight. للحصول على إرشادات، يرجى مراجعة إنشاء مجموعات Apache Spark في Azure HDInsight. يتصل الكمبيوتر الدفتري المحلي بمجموعة HDInsight.
الإلمام باستخدام Jupyter Notebooks مع Spark على HDInsight.
تثبيت Jupyter Notebook على جهاز الكمبيوتر الخاص بك
قم بتثبيت Python قبل تثبيت Jupyter Notebooks. ستقوم توزيع Anaconda بتثبيت كلٍّ من Python وJupyter Notebook.
قم بتنزيل Anaconda installer للنظام الأساسي الخاص بك وقم بتشغيل برنامج الإعداد. أثناء تشغيل معالج الإعداد، تأكد من تحديد خيار إضافة Anaconda إلى متغير PATH. راجع أيضاً، تثبيت Jupyter باستخدام Anaconda.
تثبيت Spark magic
أدخل الأمر
pip install sparkmagic==0.13.1لتثبيت Spark magic لـ HDInsight clusters الإصدار 3.6 و4.0. راجع أيضاً، وثائق شرارة.تأكد من تثبيت
ipywidgetsبشكل صحيح عن طريق تشغيل الأمر التالي:jupyter nbextension enable --py --sys-prefix widgetsnbextension
قم بتثبيت نواة PySpark وSpark
حدد مكان تثبيت
sparkmagicبإدخال الأمر التالي:pip show sparkmagicثم قم بتغيير دليل العمل الخاص بك إلى location المحدد بالأمر أعلاه.
من دليل العمل الجديد، أدخل واحداً أو أكثر من الأوامر أدناه لتثبيت النواة (النوى) المطلوبة:
Kernel الأمر Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelسبارك jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelاختياري. أدخل الأمر أدناه لتمكين امتداد الخادم:
jupyter serverextension enable --py sparkmagic
تكوين Spark magic للاتصال بمجموعة HDInsight Spark
في هذا القسم، تقوم بتكوين Spark magic الذي قمت بتثبيته مسبقاً للاتصال بمجموعة Apache Spark.
ابدأ قذيفة Python بالأمر التالي:
pythonعادةً ما يتم تخزين معلومات تكوين Jupyter في دليل المستخدم الرئيسي. أدخل الأمر التالي لتحديد الدليل الرئيسي، وإنشاء مجلد يُسمى .sparkmagic. سيتم إخراج المسار الكامل.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()داخل المجلد
.sparkmagic، أنشئ ملفاً يُسمى config.json وأضف قصاص JSON البرمجية التالية بداخله.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }قم بإجراء التعديلات التالية على الملف:
قيمة القالب قيمة جديدة USERNAME تسجيل دخول نظام المجموعة، الافتراضي هو admin.{CLUSTERDNSNAME} اسم شبكة نظام المجموعة {BASE64ENCODEDPASSWORD} كلمة مرور مشفرة base64 لكلمة مرورك الفعلية. يمكنك إنشاء كلمة مرور base64 على https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60استمر في حالة استخدام sparkmagic 0.12.7(clusters v3.5 and v3.6). في حالة استخدامsparkmagic 0.2.3(clusters v3.4)، استبدل بـ"should_heartbeat": true.يمكنك مشاهدة ملف مثال كامل على sample config.json.
تلميح
يتم إرسال دقات القلب لضمان عدم تسريب الجلسات. عندما ينتقل الكمبيوتر إلى وضع السكون أو يتم إغلاقه، لا يتم إرسال نبضات القلب، ما يؤدي إلى تنظيف الجلسة. بالنسبة للكتل v3.4، إذا كنت ترغب في تعطيل هذا السلوك، يمكنك تعيين Livy config
livy.server.interactive.heartbeat.timeoutعلى0من Ambari UI. بالنسبة للكتل v3.5، إذا لم تقم بتعيين التكوين 3.5 أعلاه، فلن يتم حذف الجلسة.ابدأ Jupyter. استخدم الأمر التالي من موجه الأوامر.
jupyter notebookتحقق من أنه يمكنك استخدام Spark magic المتاح مع النواة. أكمل الخطوات التالية.
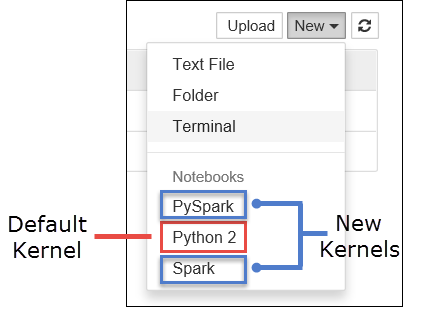
أ. قم بإنشاء دفتر ملاحظات جديد. من الزاوية اليمنى، حدد New. يجب أن تشاهد النواة الافتراضية Python 2 أو Python 3 والنواة التي قمت بتثبيتها. قد تختلف القيم الفعلية حسب اختيارات التثبيت الخاصة بك. حدد PySpark.
هام
بعد تحديد New، راجع مقلتك بحثاً عن أي أخطاء. إذا رأيت الخطأ
TypeError: __init__() got an unexpected keyword argument 'io_loop'، فربما تواجه مشكلة معروفة في إصدارات معينة من Tornado. إذا كان الأمر كذلك، فقم بإيقاف kernel ثم قم بالرجوع إلى إصدار أقدم من تثبيت Tornado باستخدام الأمر التالي:pip install tornado==4.5.3.ب. قم بتشغيل مقتطف التعليمات البرمجية التالي.
%%sql SELECT * FROM hivesampletable LIMIT 5إذا تمكنت من استرداد المخرجات بنجاح، فسيتم اختبار اتصالك بمجموعة HDInsight.
إذا كنت ترغب في تحديث تكوين الكمبيوتر المحمول للاتصال بمجموعة مختلفة، فقم بتحديث config.json بمجموعة القيم الجديدة، كما هو موضح في الخطوة 3 أعلاه.
لماذا يجب علي تثبيت Jupyter على جهاز الكمبيوتر الخاص بي؟
أسباب تثبيت Jupyter على جهاز الكمبيوتر الخاص بك ثم توصيله بمجموعة Apache Spark على HDInsight:
- يوفر لك خيار إنشاء دفاتر الملاحظات محلياً، واختبار تطبيقك مقابل مجموعة قيد التشغيل، ثم تحميل دفاتر الملاحظات إلى المجموعة. لتحميل دفاتر الملاحظات إلى المجموعة، يمكنك إما تحميلها باستخدام Jupyter Notebook قيد التشغيل أو المجموعة، أو حفظها في المجلد
/HdiNotebooksفي حساب التخزين المرتبط بالمجموعة. لمزيدٍ من المعلومات حول كيفية تخزين دفاتر الملاحظات في المجموعة، راجع أين يتم تخزين دفاتر Jupyter Notebook؟ - مع أجهزة الكمبيوتر المحمولة المتوفرة محلياً، يمكنك الاتصال بمجموعات Spark المختلفة بناءً على متطلبات التطبيق الخاص بك.
- يمكنك استخدام GitHub لتنفيذ نظام التحكم بالمصادر والتحكم في إصدار أجهزة الكمبيوتر المحمولة. يمكنك أيضاً الحصول على بيئة تعاونية حيث يمكن لعدة مستخدمين العمل باستخدام نفس دفتر الملاحظات.
- يمكنك العمل مع أجهزة الكمبيوتر المحمولة محلياً دون الحاجة إلى مجموعة. تحتاج فقط إلى مجموعة لاختبار دفاتر الملاحظات لديك، وليس لإدارة دفاتر الملاحظات أو بيئة التطوير يدوياً.
- قد يكون تكوين بيئة التطوير المحلية الخاصة بك أسهل من تكوين تثبيت Jupyter على نظام المجموعة. يمكنك الاستفادة من جميع البرامج التي قمت بتثبيتها محلياً دون تكوين مجموعة أو أكثر من المجموعات البعيدة.
تحذير
مع تثبيت Jupyter على جهاز الكمبيوتر المحلي الخاص بك، يمكن لعدة مستخدمين تشغيل نفس الكمبيوتر الدفتري على نفس مجموعة Spark في نفس الوقت. في مثل هذه الحالة، يتم إنشاء جلسات متعددة لـ Livy. إذا واجهت مشكلة وأردت تصحيحها، فستكون مهمة معقدة لتتبع جلسة Livy التي تنتمي إلى أي مستخدم.