استخدام الحزم الخارجية مع Jupyter Notebooks في مجموعات Apache Spark على HDInsight
تعرف على كيفية تكوين Jupyter Notebook في مجموعة Apache Spark على HDInsight لاستخدام حزم Apache maven الخارجية التي يساهم بها المجتمع والتي لم يتم تضمينها خارج الصندوق في المجموعة.
يمكنك البحث في مستودع Maven عن القائمة الكاملة للحزم المتوفرة. يمكنك أيضاً الحصول على قائمة بالحزم المتاحة من مصادر أخرى. على سبيل المثال، تتوفر قائمة كاملة بالحزم التي يساهم بها المجتمع في Spark Packages.
في هذه المقالة، ستتعرف على كيفية استخدام الحزمة spark-csv مع Jupyter Notebook.
المتطلبات الأساسية
مجموعة Apache Spark على HDInsight. للحصول على إرشادات، يرجى مراجعة إنشاء مجموعات Apache Spark في Azure HDInsight.
الإلمام باستخدام Jupyter Notebooks مع Spark على HDInsight. لمزيد من المعلومات، راجع تحميل البيانات وتشغيل الاستعلامات باستخدام Apache Spark على HDInsight.
مخطط URI للتخزين الأساسي لأنظمة مجموعاتك. سيكون هذا
wasb://لتخزين Azureabfs://لوحدة تخزين Azure Data Lake Gen2 أوadl://لـ Azure Data Lake Storage Gen1. في حال تم تمكين النقل الآمن لـ Azure Storage أو Data Lake Storage Gen2، فسيكون عنوان موقع الويبwasbs://أوabfss://، على التوالي، راجع أيضاً النقل الآمن.
استخدام الحزم الخارجية مع دفاتر ملاحظات Jupyter
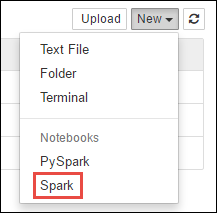
انتقل إلى
https://CLUSTERNAME.azurehdinsight.net/jupyterwhereCLUSTERNAMEهو اسم مجموعة Spark الخاصة بك.قم بإنشاء دفتر ملاحظات جديد. حدد New، ثم حدد Spark.
يتم إنشاء دفتر ملاحظات جديد وفتحه باسم Untitled.pynb. حدد اسم دفتر الملاحظات في الجزء العلوي، وأدخل اسماً مألوفاً.
ستستخدم الحيلة
%%configureلتكوين دفتر الملاحظات لاستخدام حزمة خارجية. في أجهزة الكمبيوتر المحمولة التي تستخدم حزماً خارجية، تأكد من استدعاء الحيلة%%configureفي خلية التعليمات البرمجية الأولى. هذا يضمن أن النواة قد تم تكوينها لاستخدام الحزمة قبل بدء الجلسة.هام
إذا نسيت تكوين النواة في الخلية الأولى، فيمكنك استخدام
%%configureمع المعلمة-f، ولكن هذا سيعيد تشغيل الجلسة وسيتم فقد كل التقدم.نسخة HDInsight الأمر بالنسبة إلى HDInsight 3.5 وHDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}بالنسبة إلى HDInsight 3.3 وHDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }تتوقع القصاصة البرمجية أعلاه إحداثيات المخضرم للحزمة الخارجية في Maven Central Repository. في هذه القصاصة البرمجية، يمثل
com.databricks:spark-csv_2.11:1.5.0إحداثي maven لحزمة spark-csv. إليك كيفية إنشاء إحداثيات الحزمة.أ. حدد موقع الحزمة في Maven Repository. في هذه المقالة، نستخدم spark-csv.
ب. من المستودع، اجمع قيم GroupId وArtifactId وVersion. تأكد من أن القيم التي تجمعها تطابق مجموعتك. في هذه الحالة، نستخدم حزمة Scala 2.11 وSpark 1.5.0، ولكن قد تحتاج إلى تحديد إصدارات مختلفة لإصدار Scala أو Spark المناسب في مجموعتك. يمكنك معرفة إصدار Scala على مجموعتك عن طريق تشغيل
scala.util.Properties.versionStringعلى نواة Spark Jupyter أو إرسال Spark. يمكنك معرفة إصدار Spark على مجموعتك عن طريق تشغيلsc.versionعلى Jupyter Notebooks.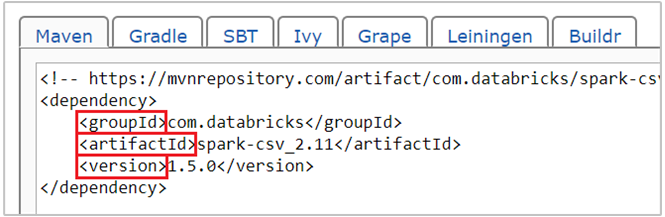
جـ. قم بتسلسل القيم الثلاثة، مفصولة بنقطتين (:).
com.databricks:spark-csv_2.11:1.5.0قم بتشغيل خلية التعليمة البرمجية باستخدام الحيلة
%%configure. يؤدي هذا إلى تكوين جلسة Livy الأساسية لاستخدام الحزمة التي قدمتها. في الخلايا التالية في دفتر الملاحظات، يمكنك الآن استخدام الحزمة، كما هو موضح أدناه.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")بالنسبة لـ HDInsight 3.4 وما دونه، يجب عليك استخدام القصاصة البرمجية التالية.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")يمكنك بعد ذلك تشغيل القصاصات البرمجية، كما هو موضح أدناه، لعرض البيانات من إطار البيانات الذي أنشأته في الخطوة السابقة.
df.show() df.select("Time").count()
(راجع أيضًا )
السيناريوهات
- Apache Spark مع المعلومات المهنية: إجراء تحليل تفاعلي للبيانات باستخدام Spark in HDInsight مع أدوات المعلومات المهنية
- Apache Spark مع التعلم الآلي: استخدام Spark في HDInsight لتحليل درجة حرارة المبنى باستخدام بيانات HVAC
- Apache Spark مع التعلم الآلي: استخدم Spark في HDInsight للتنبؤ بنتائج فحص الأغذية
- تحليل سجل موقع الويب باستخدام Apache Spark في HDInsight
إنشاء التطبيقات وتشغيلها
الأدوات والملحقات
- استخدم حزم Python الخارجية مع Jupyter Notebooks في أنظمة مجموعات Apache Spark على HDInsight Linux
- استخدم HDInsight Tools Plugin لـ IntelliJ IDEA لإنشاء وإرسال تطبيقات Spark Scala
- استخدم HDInsight Tools Plugin لـ IntelliJ IDEA لتصحيح أخطاء تطبيقات Apache Spark عن بُعد
- استخدام دفاتر ملاحظات Apache Zeppelin مع نظام مجموعة Apache Spark على HDInsight
- تتوفر Kernels لـ Jupyter Notebook في مجموعة Apache Spark لـ HDInsight
- تثبيت Jupyter على جهاز الكمبيوتر الخاص بك، والاتصال بنظام مجموعة HDInsight Spark
إدارة الموارد
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ