مكون Evaluate Model
توضح هذه المقالة مكونا في مصمم التعلم الآلي Azure.
يمكنك استخدام ذلك المكون لقياس دقة نموذج مدرب. يمكنك توفير مجموعة بيانات تحتوي على درجات تم إنشاؤها من نموذج، ويحسب مكون Evaluate Model مجموعة من مقاييس التقييم القياسية للصناعة.
تعتمد المقاييس التي تم إرجاعها بواسطة Evaluate Model على نوع النموذج الذي تقيّمه:
- Classification Models
- Regression Models
- Clustering Models
تلميح
إذا كنت جديدا في مجال تقييم النموذج، نوصي بسلسلة فيديو الدكتور ستيفن إلستون، كجزء من دورة التعلم الآلي من EdX.
كيفية استخدام Evaluate Model
قم بتوصيل إخراج مجموعة البيانات المسجلة لـ Score Model أو إخراج مجموعة بيانات النتيجة الخاصة بـ Assign Data لـ مجموعات أجهزة الكمبيوتر بمنفذ الإدخال الأيسر الخاص بـ Evaluate Model.
إشعار
إذا كنت تستخدم مكونات مثل «Select Columns» في مجموعة البيانات لتحديد جزء من مجموعة بيانات الإدخال، فالرجاء التأكد من وجود عمود التسمية الفعلية (المستخدم في التدريب) وعمود «Scored Probabilities» وعمود «Scored Labels» لحساب مقاييس مثل AUC والدقة للتصنيف الثنائي/الكشف عن الحالات الخارجة عن المألوف. يوجد عمود وعمود «Scored Labels» لحساب المقاييس للتصنيف/الانحدار متعدد الفئات. عمود «Assignments» والأعمدة 'DistancesToClusterCenter no. X' (X هو فهرس مركزي، يتراوح بين 0، ...، عدد centroids-1) موجود لحساب تكوين أنظمة المجموعات.
هام
- لتقييم النتائج، يجب احتواء مجموعة بيانات الإخراج على أسماء أعمدة نقاط محددة، والتي تفي بمتطلبات مكون Evaluate Model.
Labelsسيتم اعتبار العمود كتسميات فعلية.- بالنسبة لمهمة التراجع يجب أن تحتوي مجموعة البيانات المراد تقييمها على عمود واحد، يسمى
Regression Scored Labels، والذي يمثل التسميات المسجلة. - ولمهمة التصنيف الثنائي، يجب أن تحتوي مجموعة البيانات المراد تقييمها على عمودين، يطلق عليهما
Binary Class Scored Labels، وBinary Class Scored Probabilitiesيمثلان التسميات المسجلة، والاحتمالات على الترتيب. - ولمهمة التصنيف المتعدد، يجب أن تحتوي مجموعة البيانات المراد تقييمها على عمود واحد، يسمى
Multi Class Scored Labelsوالذي يمثل التسميات المسجلة. إذا لم تكن مخرجات المكون المصدر تحتوي على تلك الأعمدة، فستحتاج إلى التعديل وفقا للمتطلبات أعلاه.
[اختياري] قم بتوصيل إخراج مجموعة البيانات المسجلة لـ Score Model أو إخراج مجموعة بيانات النتيجة الخاصة بـ Assign Data لـ مجموعات أجهزة الكمبيوتر بمنفذ الإدخال الأيمن الخاص بـ Evaluate Model. يمكنك مقارنة النتائج من نموذجين مختلفين على نفس البيانات بسهولة. يجب أن تكون خوارزميات الإدخال من نفس نوع الخوارزمية. أو، يمكنك مقارنة الدرجات من عمليتين تشغيل مختلفتين عبر نفس البيانات بمعلمات مختلفة.
إشعار
يشير نوع الخوارزمية إلى «التصنيف من فئتين»، و«التصنيف متعدد الفئات»، و«التراجع»، و«التجميع» ضمن «خوارزميات التعلم الآلي».
إرسال البنية الأساسية لبرنامج ربط العمليات التجارية لإنشاء النتائج الخاصة بالتقييم.
النتائج
بعد تشغيلك لـ Evaluate Model، حدد المكون لفتح لوحة تنقل Evaluate Model على اليمين. ثم، اختر علامة التبويب Outputs + Logs، وفي علامة التبويب هذه، يحتوي قسم Data Outputs على عدة أيقونات. تحتوي أيقونة Visualize على أيقونة رسم بياني شريطي، وهي طريقة أولى لرؤية النتائج.
بالنسبة للتصنيف الثنائي، بعد النقر فوق أيقونة Visualize، يمكنك عرض مصفوفة الخلط الثنائي. بالنسبة للتصنيف المتعدد، يمكنك العثور على ملف مخطط مصفوفة الخلط ضمن علامة التبويب Outputs + Logs كما يلي:
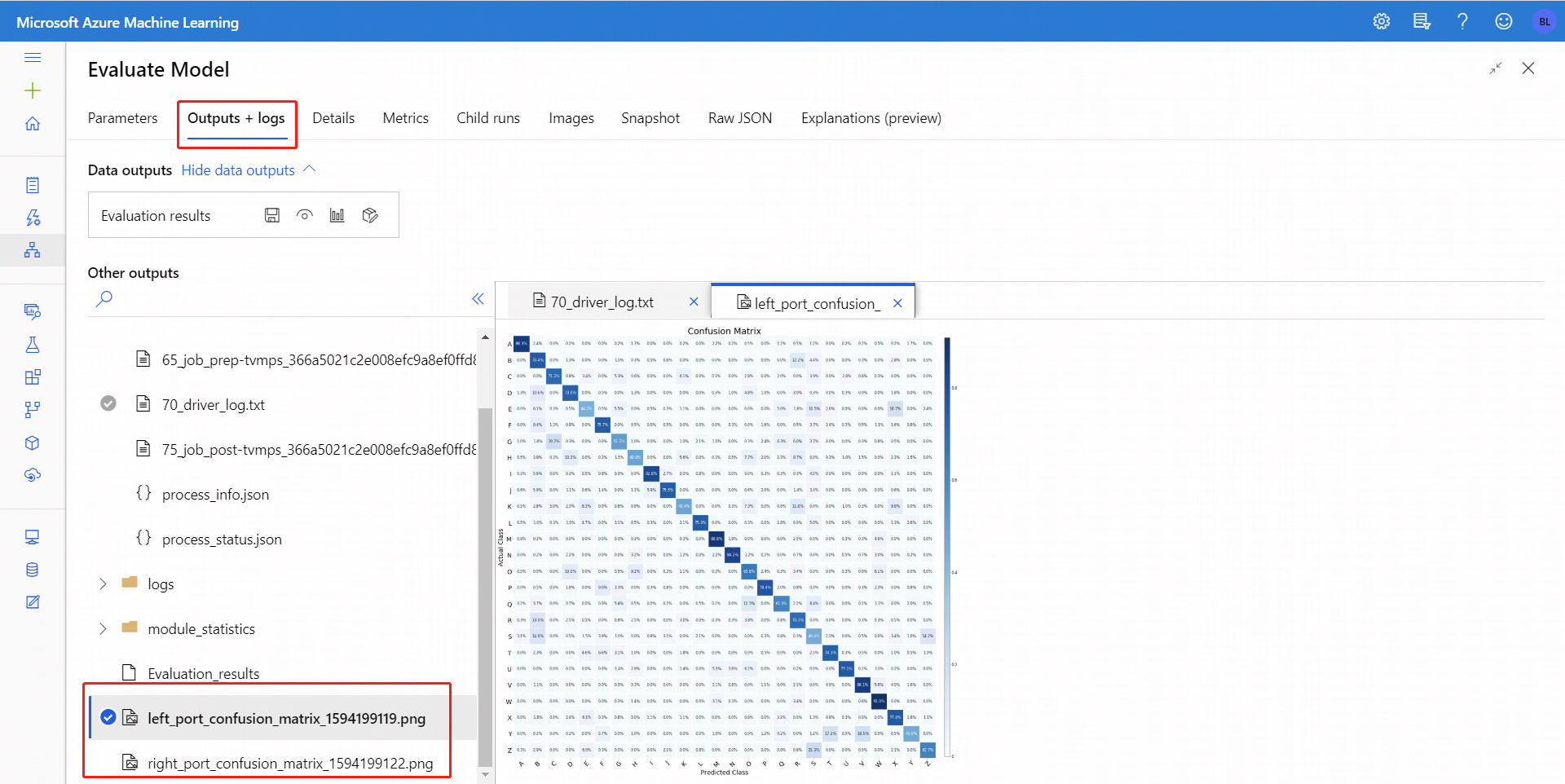
إذا قمت بتوصيل مجموعات البيانات بكل من إدخالات Evaluate Model، فستحتوي النتائج على مقاييس لكل من مجموعة البيانات أو كلا النموذجين. يتم تقديم النموذج أو البيانات المرفقة بالمنفذ الأيسر والموضحة في التقرير أولا، متبوعة بمقاييس مجموعة البيانات، أو النموذج المرفق بالمنفذ الأيمن.
على سبيل المثال، تمثل الصورة التالية مقارنة بين النتائج من نموذجي تكوين أنظمة المجموعات تم إنشاؤهما على نفس البيانات، ولكن مع معلمات مختلفة.
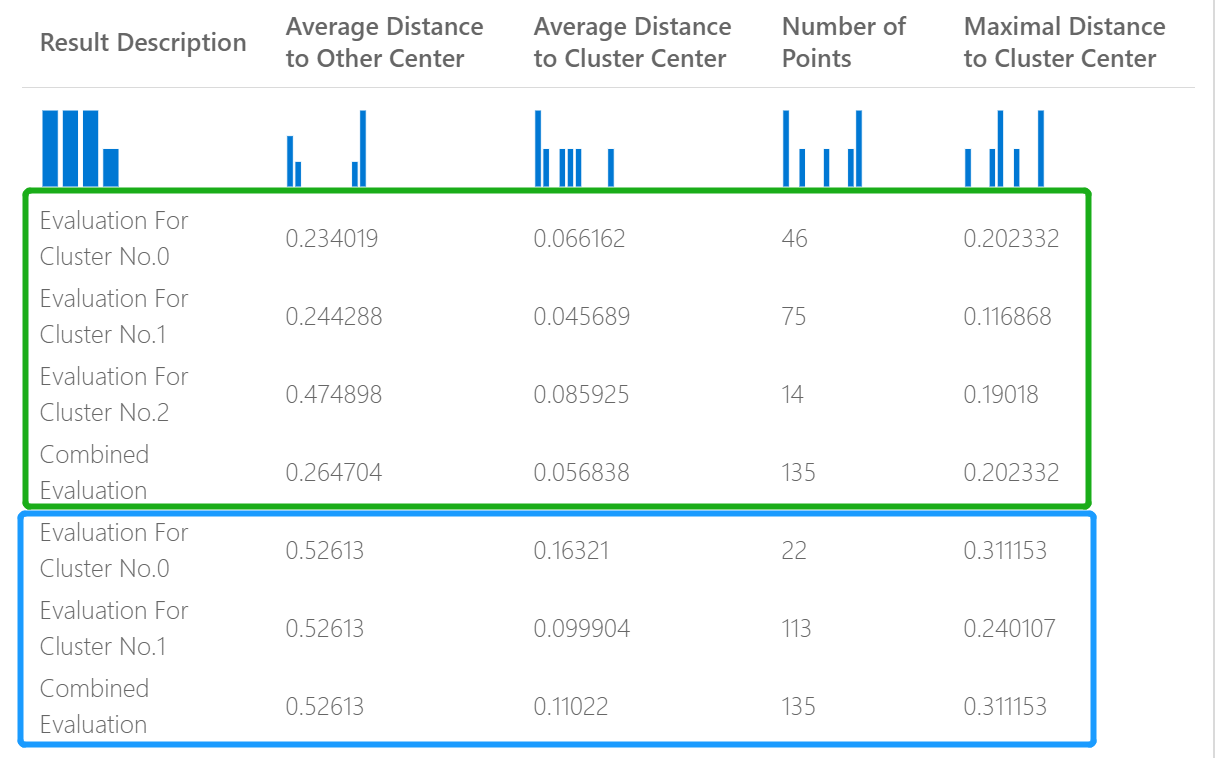
نظرا لأن هذا نموذج تكوين أنظمة المجموعات، فإن تختلف التقييم عما إذا قمت بمقارنة الدرجات من نموذجي تراجع أو مقارنة نموذجين للتصنيف. بالرغم من ذلك، فإن العرض التقديمي الكلي هو نفسه.
المقاييس
يصف هذا القسم المقاييس التي تم إرجاعها لأنواع محددة من النماذج المدعومة للاستخدام مع Evaluate Model:
مقاييس نماذج التصنيف
يتم الإبلاغ عن المقاييس التالية أثناء تقييم نماذج التصنيف الثنائي.
تقيس الدقة مدى جودة نموذج التصنيف كنسبة من النتائج الحقيقية إلى إجمالي الحالات.
الدقة هي نسبة النتائج الحقيقية إلى النتائج الإيجابية. الدقة = TP/(TP+FP)
الاسترجاع هو جزء من المبلغ الإجمالي للمثيلات ذات الصلة التي تم استردادها فعليا. الاسترجاع = TP/(TP+FN)
مقياس f هو مقياس محوسب كمتوسط مرجح للدقة والاسترجاع بين 0 و 1 حيث تكون قيمة مقياس f المثالية هي 1.
يقيس AUC المنطقة تحت المنحنى المرسوم مع الإيجابيات الحقيقية على المحور ص والإيجابيات الكاذبة على المحور س. هذا المقياس مفيد إذ يوفر رقما واحدا يتيح لك مقارنة نماذج من أنواع مختلفة. AUC هو ثابت حد التصنيف. وهو يقيس جودة تنبؤات النموذج بصرف النظر عن حد التصنيف الذي يتم اختياره.
مقاييس نماذج التراجع
صُممت المقاييس التي تم إرجاعها لنماذج التراجع لتقدير مقدار الخطأ. يعتبر النموذج مناسبا للبيانات بشكل جيد إن كان الفرق بين القيم الملاحظة والقيم المتوقعة صغيرا. ومع ذلك، يمكن أن يخبرك النظر إلى نمط القيم المتبقية (الفرق بين أي نقطة متوقعة وقيمتها الفعلية المقابلة) بالكثير عن العرض المحتمل في النموذج.
يتم الإبلاغ عن المقاييس التالية لتقييم نماذج الانحدار الخطي. قد تحتوي نماذج الانحدار الأخرى مثل الانحدار الكمي السريع للغابة على مقاييس مختلفة.
يقيس متوسط الخطأ المطلق (MAE) مدى قرب التنبؤات من النتائج الفعلية؛ وبالتالي، تكون الدرجة أقل أفضل.
ينشئ الخطأ التربيعي الوسط الجذر (RMSE) قيمة واحدة تلخص الخطأ في النموذج. من خلال تربيع الفرق، يتجاهل المقياس الفرق بين التنبؤ المفرط والتنبؤ الناقص.
الخطأ المطلق النسبي (RAE) هو الفرق المطلق النسبي بين القيم المتوقعة والفعلية؛ نسبي لأن فرق الوسط مقسوم على الوسط الحسابي.
الخطأ التربيعي النسبي (RSE) يعمل على تسوية الخطأ التربيعي الإجمالي بالقسمة على إجمالي الخطأ التربيعي للقيم المتوقعة.
يمثل معامل التحديد، الذي يشار إليه غالبا باسم R2، القوة التنبؤية للنموذج كقيمة بين 0 و1. ويعني الصفر أن النموذج عشوائي (لا يفسر شيئا)؛ بينما يعني 1 وجود ملاءمة مثالية. ومع ذلك، يجب توخي الحذر في تفسير قيم R2، حيث يمكن أن تكون القيم المنخفضة عادية تماما كما يمكن أن تكون القيم العالية مشتبها فيها.
مقاييس نماذج تكوين أنظمة المجموعات
نظرا لأن نماذج تكوين أنظمة المجموعات تختلف بكثيرا عن نماذج التصنيف والتراجع في العديد من النواحي، فإن Evaluate Model يرجع أيضا مجموعة مختلفة من الإحصائيات لنماذج تكوين أنظمة المجموعات.
تصف الإحصائيات التي تم إرجاعها لنموذج نظام تكوين أنظمة المجموعات عدد نقاط البيانات التي تم تعيينها لكل نظام مجموعة أجهزة كمبيوتر، ومقدار الفصل بين مجموعات أجهزة الكمبيوتر ومدى إحكام تجميع نقاط البيانات داخل كل مجموعة.
يتم حساب متوسط إحصائيات نموذج التجميع عبر مجموعة البيانات بأكملها، مع صفوف إضافية تحتوي على الإحصائيات لكل نظام مجموعة أجهزة كمبيوتر.
يتم الإبلاغ عن المقاييس التالية لتقييم نماذج تكوين أنظمة المجموعات.
توضح الدرجات في العمود Average Distance to Other Center مدى قرب متوسط كل نقطة في مجموعة أجهزة كمبيوتر إلى النقاط المركزية لجميع مجموعات أجهزة كمبيوتر.
توضح الدرجات في العمود Average Distance to Other Center مدى قرب جميع النقاط في مجموعة أجهزة كمبيوتر إلى النقاط المركزية لمجموعة أجهزة كمبيوتر.
يوضح عمود Number of Points عدد نقاط البيانات التي تم تعيينها لكل نظام مجموعة أجهزة كمبيوتر، بالإضافة إلى العدد الإجمالي لنقاط البيانات في أي نظام مجموعة.
إذا كان عدد نقاط البيانات المعينة لمجموعات أجهزة الكمبيوتر أقل من العدد الإجمالي لنقاط البيانات المتوفرة، فهذا يعني أنه لا يمكن تعيين نقاط البيانات إلى نظام مجموعة أجهزة الكمبيوتر.
تمثل الدرجات في Maximal Distance to Cluster Center أقصى المسافة بين كل نقطة والنقاط المركزية لمجموعة تلك النقط.
إذا كان لك الرقم مرتفعا، فقد يعني ذلك أن نظام المجموعة مشتت على نطاق واسع. يجب عليك مراجعة تلك الإحصائية مع Average Distance to Cluster Center لتحديد انتشار نظام المجموعة.
تسرد درجة Combined Evaluation في أسفل كل قسم من قائمة النتائج الدرجات المتوسطة للمجموعات التي تم إنشاؤها في هذا النموذج المحدد.
الخطوات التالية
راجع مجموعة المكونات المتوفرة للتعلم الآلي من Azure.