Alta disponibilidad (confiabilidad) en el Servidor flexible de Azure Database for PostgreSQL
SE APLICA A:  Azure Database for PostgreSQL con servidor flexible
Azure Database for PostgreSQL con servidor flexible
En este artículo se describe la alta disponibilidad en el Servidor flexible de Azure Database for PostgreSQL, que incluye zonas de disponibilidad y recuperación entre regiones y continuidad empresarial. Para obtener información general más detallada sobre la confiabilidad de Azure, consulte Confiabilidad de Azure.
El Servidor flexible de Azure Database for PostgreSQL ofrece compatibilidad de alta disponibilidad mediante el aprovisionamiento de réplicas principal y en espera físicamente independientes dentro de la misma zona de disponibilidad (zonal) o entre zonas de disponibilidad (con redundancia de zona). Este modelo de alta disponibilidad está diseñado para garantizar que los datos confirmados nunca se pierdan en caso de errores. El modelo también está diseñado para que la base de datos no se convierta en un único punto de error en la arquitectura de software. Para obtener más información sobre la alta disponibilidad y la compatibilidad con zonas de disponibilidad, consulte Compatibilidad con zonas de disponibilidad.
Compatibilidad de zonas de disponibilidad
Las zonas de disponibilidad de Azure son al menos tres grupos de centros de datos físicamente independientes dentro de cada región de Azure. Los centros de datos de cada zona están equipados con infraestructura de alimentación, refrigeración y red independientes. En el caso de un error en la zona local, las zonas de disponibilidad están diseñadas de manera que, si se ve afectada una zona, los servicios, la capacidad y la alta disponibilidad regionales serán proporcionadas por las dos zonas restantes.
Estos errores pueden abarcar desde errores de software y hardware hasta eventos como terremotos, inundaciones e incendios. La tolerancia a los errores se logra con la redundancia y el aislamiento lógico de los servicios de Azure. Para más información sobre las zonas de disponibilidad en Azure, consulte Regiones y zonas de disponibilidad.
Los servicios habilitados para zonas de disponibilidad de Azure están diseñados para proporcionar el nivel adecuado de confiabilidad y flexibilidad. Se pueden configurar de dos maneras. Pueden tener redundancia de zona, con una replicación automática entre zonas o ser zonales, con instancias ancladas a una zona específica. También puede combinar ambos enfoques. Para más información sobre la arquitectura zonal frente a la arquitectura con redundancia de zona, consulte Recomendaciones para el uso de zonas de disponibilidad y regiones.
El Servidor flexible de Azure Database for PostgreSQL admite modelos con redundancia de zona y zonales para configuraciones de alta disponibilidad. Ambas configuraciones de alta disponibilidad permiten la funcionalidad de conmutación automática por error sin pérdida de datos durante eventos planeados y no planeados.
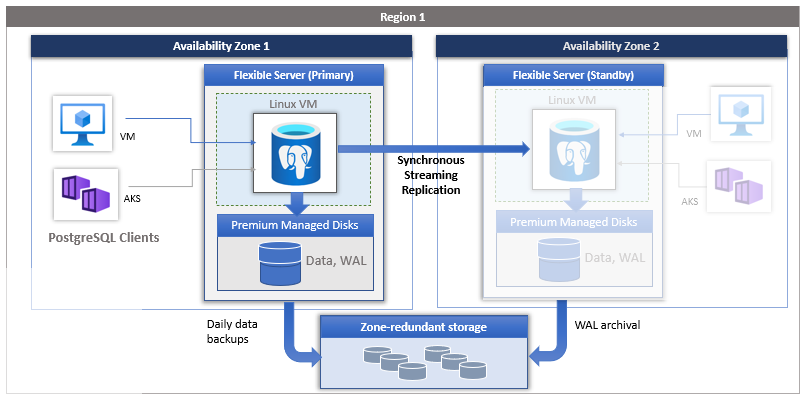
Redundancia de zona. La alta disponibilidad con redundancia de zona implementa una réplica en espera en una zona diferente con la funcionalidad de conmutación automática por error. La redundancia de zona proporciona el máximo nivel de disponibilidad, pero exige configurar la redundancia de las aplicaciones entre zonas. Por ese motivo, elija la redundancia de zona cuando desee protección frente a errores de nivel de zona de disponibilidad y cuando se acepte la latencia entre las zonas de disponibilidad.
Puede elegir la región y las zonas de disponibilidad para los servidores principal y en espera. El servidor de réplica en espera se aprovisiona en la zona de disponibilidad elegida en la misma región con una configuración similar de proceso, almacenamiento y red que la del servidor principal. Los archivos de datos y los archivos de registro de transacciones (registros de escritura previa, también conocidos como WAL) se almacenan en almacenamiento con redundancia local (LRS) dentro de cada zona de disponibilidad, que almacena automáticamente tres copias de datos. Una configuración con redundancia de zona proporciona aislamiento físico de toda la pila entre los servidores principal y en espera.
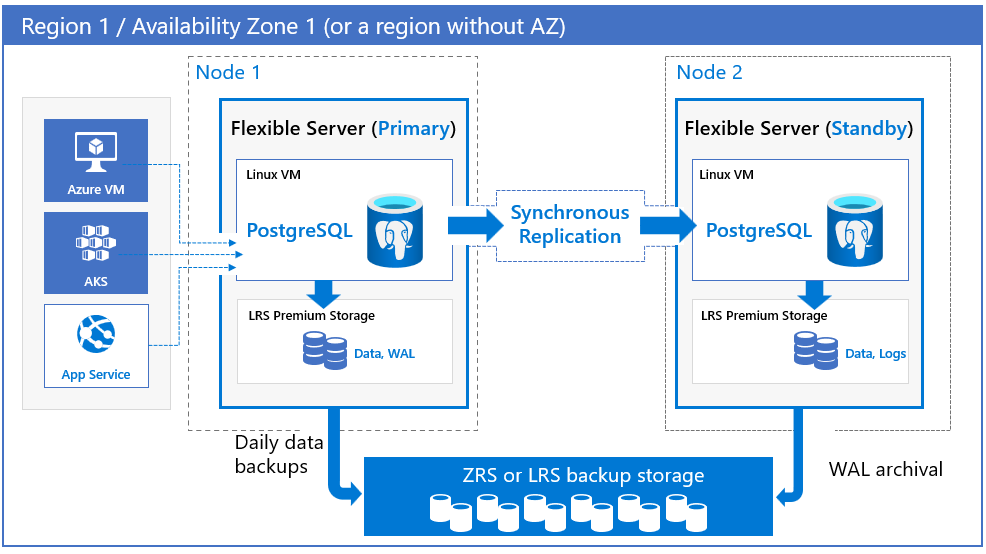
Zonales. Elija una implementación zonal cuando quiera lograr el mayor nivel de disponibilidad dentro de una sola zona de disponibilidad, pero con la latencia de red más baja. Puede elegir la región y la zona de disponibilidad para implementar el servidor de bases de datos principal. Un servidor de réplica en espera se aprovisiona automáticamente y se administra en la misma zona de disponibilidad con una configuración similar de proceso, almacenamiento y red que la del servidor principal. Una configuración zonal protege las bases de datos frente a errores de nivel de nodo y también ayuda a reducir el tiempo de inactividad de la aplicación durante los eventos de tiempo de inactividad planeados y no planeados. Los datos del servidor principal se replican de modo sincrónico en la réplica en espera. En caso de que se produzca una interrupción en el servidor principal, el servidor se conmuta por error automáticamente a la réplica en espera.


Nota:
Los modelos de implementación con redundancia de zona y zonales tienen el mismo comportamiento arquitectónico. Varias discusiones de las secciones siguientes se aplican a ambos, a menos que se indique lo contrario.
Requisitos previos
Redundancia de zona:
La opción de redundancia de zona solo está disponible en regiones que admiten zonas de disponibilidad.
La redundancia de zona no se admite para:
- SKU de Servidor único de Azure Database for PostgreSQL.
- Nivel de proceso ampliable.
- Regiones con disponibilidad de zona única.
Zonal:
- La opción de implementación zonal está disponible en todas las regiones de Azure donde puede implementar el Servidor flexible.
Características de alta disponibilidad
Una réplica en espera se implementa en la misma configuración de máquina virtual, incluidos los núcleos virtuales, el almacenamiento, la configuración de red, que el servidor principal.
Puede agregar compatibilidad con zonas de disponibilidad para un servidor de bases de datos existente.
Puede quitar la réplica en espera si deshabilita la alta disponibilidad.
Puede elegir zonas de disponibilidad para los servidores de base de datos principal y en espera para la disponibilidad con redundancia de zona.
Las operaciones como detener, iniciar y reiniciar se realizan en los servidores de base de datos principal y en espera al mismo tiempo.
En los modelos con redundancia de zona y zonales, las copias de seguridad automáticas se realizan periódicamente desde el servidor de base de datos principal. Al mismo tiempo, los registros de transacciones se archivan continuamente en el almacenamiento de copia de seguridad desde la réplica en espera. Si la región admite zonas de disponibilidad, los datos de copia de seguridad se almacenan en un almacenamiento con redundancia de zona (ZRS). En las regiones que no admiten zonas de disponibilidad, los datos de copia de seguridad se almacenan en un almacenamiento con redundancia local (LRS).
Los clientes siempre se conectan al nombre de host final del servidor de bases de datos principal.
Los cambios en los parámetros del servidor también se aplican a la réplica en espera.
Capacidad de reiniciar el servidor para seleccionar cualquier cambio de parámetro de servidor estático.
Las actividades periódicas de mantenimiento, como las actualizaciones de versión secundarias, se realizan primero en el nodo en espera y, para reducir el tiempo de inactividad, el nodo en espera se convierte en primario para que las cargas de trabajo puedan mantenerse, mientras las tareas de mantenimiento se aplican en el nodo restante.
Supervisar el estado de alta disponibilidad
La supervisión del estado de mantenimiento de alta disponibilidad (HA) en el servidor flexible de Azure Database for PostgreSQL proporciona una visión general continua sobre el estado y la preparación de las instancias habilitadas para HA. Esta característica de supervisión aprovecha el marco de Resource Health Check (RHC) de Azure para detectar y alertar sobre cualquier problema que pueda afectar a la preparación de la conmutación por error de su base de datos o a la disponibilidad general. Al evaluar métricas clave como el estado de conexión, el estado de conmutación por error y el estado de replicación de datos, la supervisión del estado de mantenimiento de alta disponibilidad permite una solución de problemas proactiva y ayuda a mantener el tiempo de actividad y el rendimiento de la base de datos.
Los clientes pueden usar la supervisión del estado de mantenimiento de alta disponibilidad para:
- Obtener información en tiempo real sobre el estado de las réplicas principales y en espera, con indicadores de estado que revelan posibles problemas, como el rendimiento degradado o el bloqueo de red.
- Configurar alertas para notificaciones oportunas sobre los cambios en el estado de alta disponibilidad, lo que garantiza una acción inmediata para abordar posibles interrupciones.
- Optimizar la preparación de la conmutación por error mediante la identificación y la resolución de problemas antes de que afecten a las operaciones de la base de datos.
Para obtener una guía detallada sobre cómo configurar e interpretar los estados de mantenimiento de HA, consulte el artículo principal Supervisión del estado de mantenimiento de alta disponibilidad (HA) para el servidor flexible de Azure Database for PostgreSQL.
Limitaciones de alta disponibilidad
Debido a la replicación sincrónica al servidor en espera, especialmente con una configuración con redundancia de zona, las aplicaciones pueden experimentar una latencia de escritura y confirmación elevadas.
No se puede usar la réplica en espera para las consultas de solo lectura.
Según la carga de trabajo y la actividad en el servidor principal, el proceso de conmutación por error puede tardar más de 120 segundos debido a la recuperación implicada en la réplica en espera antes de que se pueda promover.
El servidor en espera normalmente recupera archivos WAL a 40 MB/s. Si la carga de trabajo supera este límite, puede que detecte más tiempo para que la recuperación se complete durante la conmutación por error o después de establecer un nuevo servidor en espera.
La configuración de zonas de disponibilidad induce cierta latencia a las escrituras y confirmaciones, sin afectar a las consultas de lectura. El impacto en el rendimiento varía en función de la carga de trabajo. Como norma general, el impacto de las escrituras y las confirmaciones puede ser alrededor del 20 o 30 % de impacto.
Al reiniciar el servidor de bases de datos principal también se reinicia la réplica del servidor en espera.
No se admite la configuración de un modo de espera adicional.
La configuración de las tareas de administración iniciadas por el cliente no se puede programar durante la ventana de mantenimiento administrado.
Los eventos planificados, como el escalado de proceso y el escalado de almacenamiento, se producen primero en el servidor en espera y luego en el servidor principal. Actualmente, el servidor no realiza la conmutación por error para estas operaciones planeadas.
Si la descodificación lógica o la replicación lógica están configuradas con un Servidor flexible configurado de alta disponibilidad, en el caso de una conmutación por error al servidor en espera, las ranuras de replicación lógica no se copian en el servidor en espera. Para mantener ranuras de replicación lógica y garantizar la coherencia de los datos después de una conmutación por error, se recomienda usar la extensión PG Failover Slots. Para más información sobre cómo habilitar esta extensión, consulte la documentación.
No se admite la configuración de zonas de disponibilidad entre la red virtual (VNET) y el acceso público con puntos de conexión privados. Debe configurar zonas de disponibilidad dentro de una red virtual (distribuidas entre zonas de disponibilidad dentro de una región) o el acceso público con puntos de conexión privados.
Las zonas de disponibilidad solo se configuran dentro de una sola región. Las zonas de disponibilidad no se pueden configurar entre regiones.
Contrato de nivel de servicio
El modelo Zonal ofrece un Acuerdo de Nivel de Servicio del 99,95 % de tiempo de actividad.
El modelo de Redundancia de zona ofrece un Acuerdo de Nivel de Servicio del 99,99 % de tiempo de actividad.
Creación de una instancia del Servidor flexible de Azure Database for PostgreSQL con la zona de disponibilidad habilitada
Para aprender a crear un Servidor flexible de Azure Database for PostgreSQL para alta disponibilidad con zonas de disponibilidad, consulte Inicio rápido: Creación de un Servidor flexible de Azure Database for PostgreSQL en Azure Portal.
Reimplementación y migración de una zona de disponibilidad
Para obtener información sobre cómo habilitar o deshabilitar la configuración de alta disponibilidad en el servidor flexible en los modelos de implementación con redundancia de zona y zonal, consulte Administración de alta disponibilidad en el Servidor flexible.
Componentes y flujo de trabajo de alta disponibilidad
Finalización de transacciones
Las escrituras y confirmaciones desencadenadas por la transacción de aplicación se registran primero en el WAL del servidor principal. A continuación, se transmite al servidor en espera mediante el protocolo de transmisión de Postgres. Una vez que los registros se conservan en el almacenamiento del servidor en espera, al servidor principal se le confirma la finalización del proceso de escritura. Solo entonces la aplicación confirma la confirmación de su transacción. Este recorrido de ida y vuelta adicional agrega más latencia a la aplicación. El porcentaje de impacto depende de la aplicación. Este proceso de confirmación no espera a que los registros se apliquen al servidor en espera. El servidor en espera está permanentemente en modo de recuperación hasta que se promueve.
Comprobación de estado
El seguimiento de estado del Servidor flexible comprueba periódicamente el estado principal y en espera. Después de varios pings, si el seguimiento de estado detecta que no se puede acceder a un servidor principal, el servicio inicia una conmutación automática por error al servidor en espera. El algoritmo de seguimiento de estado se basa en varios puntos de datos para evitar situaciones de falsos positivos.
Modos de conmutación por error
El Servidor flexible admite dos modos de conmutación por error, Conmutación por error planeada y Conmutación por error no planeada. En ambos modos, una vez que se ha interrumpido la replicación, el servidor en espera ejecuta la recuperación antes de promoverse como principal y se abre para lectura y escritura. Con las entradas DNS automáticas actualizadas con el nuevo punto de conexión de servidor principal, las aplicaciones pueden conectarse al servidor mediante el mismo punto de conexión. Se establece un nuevo servidor en espera en segundo plano para que la aplicación pueda mantener la conectividad.
Estado de disponibilidad alta
El estado de los servidores principales y en espera se supervisa continuamente y se toman las medidas adecuadas para corregir problemas, incluido el desencadenamiento de una conmutación por error en el servidor en espera. En la tabla siguiente se enumeran los posibles estados de alta disponibilidad:
| Estado | Descripción |
|---|---|
| Inicializando | En proceso de crear un servidor en espera. |
| Replicando datos | Una vez que se ha creado el servidor en espera, se pone al día con el servidor principal. |
| Healthy | La replicación está en estado estable y es correcta. |
| Conmutar por error | El servidor de bases de datos está en proceso de conmutar por error al de espera. |
| Quitar servidor en espera | En proceso de eliminar el servidor en espera. |
| Sin habilitar | La alta disponibilidad no está habilitada. |
Nota:
Puede habilitar la alta disponibilidad durante la creación del servidor o también en un momento posterior. Si va a habilitar o deshabilitar la alta disponibilidad durante la fase posterior a la creación, se recomienda realizar la operación cuando la actividad del servidor principal sea baja.
Operaciones de estado estable
Las aplicaciones cliente de PostgreSQL se conectan al servidor principal mediante el nombre del servidor de bases de datos. Las lecturas de la aplicación se sirven directamente desde el servidor principal. Al mismo tiempo, las confirmaciones y escrituras se confirman en la aplicación solo después de que los datos de registro se conserven tanto en el servidor principal como en la réplica en espera. Debido a esta ida y vuelta adicional, las aplicaciones pueden esperar una latencia elevada para las operaciones de escritura y confirmación. Puede supervisar el estado de la alta disponibilidad en el portal.
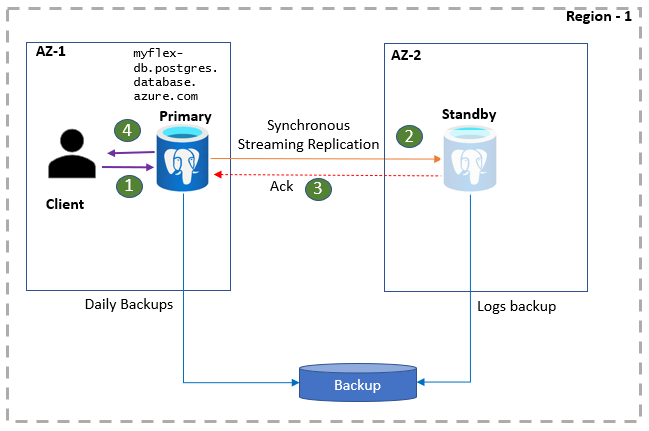
- Los clientes se conectan al servidor flexible y realizan operaciones de escritura.
- Los cambios se replican en el sitio en espera.
- El servidor principal recibe una confirmación.
- Las escrituras o confirmaciones se confirman.
Restauración a un momento dado de servidores de alta disponibilidad
En el caso de los servidores flexibles configurados con alta disponibilidad, los datos de registro se replican en tiempo real en el servidor en espera. Los errores de usuario en el servidor principal, como la eliminación accidental de una tabla o las actualizaciones de datos incorrectas, se replican en la réplica en espera. Por tanto, no puede usar el servidor en espera para recuperarse de estos errores lógicos. Tiene que realizar una restauración a un momento dado de copias de seguridad para recuperarse de estos errores. Con la capacidad de restauración a un momento dado del servidor flexible, puede restaurar hasta el momento antes de que se produjera el error. Un nuevo servidor de bases de datos se restaurará como un servidor flexible de una sola zona con un nuevo nombre proporcionado por el usuario para las bases de datos configuradas con alta disponibilidad. Puede usar el servidor restaurado para algunos casos de uso:
Puede usar el servidor restaurado para producción y, opcionalmente, habilitar la alta disponibilidad con una réplica en espera en la misma zona u otra zona de la misma región.
Si desea restaurar un objeto, expórtelo desde el servidor de bases de datos restaurado e impórtelo al servidor de bases de datos de producción.
Si quiere clonar el servidor de bases de datos con fines de prueba y desarrollo, o bien realizar la restauración para cualquier otro fin, puede realizar una restauración a un momento dado.
Para obtener información sobre cómo realizar una restauración a un momento dado de un servidor flexible, consulte Restauración a un momento dado de un servidor flexible.
Compatibilidad con la conmutación por error
Conmutación por error planeada
Los eventos de tiempo de inactividad planificados incluyen actualizaciones de software frecuentes programadas de Azure y actualizaciones de versiones secundarias. También puede usar una conmutación por error planeada para devolver el servidor principal a una zona de disponibilidad preferida. Cuando se configuran en alta disponibilidad, estas operaciones se aplican en primer lugar a la réplica en espera mientras las aplicaciones continúan accediendo al servidor principal. Una vez que se actualiza la réplica en espera, se purgan las conexiones del servidor principal y se desencadena una conmutación por error que activa la réplica en espera para que sea la principal con el mismo nombre de servidor de bases de datos. Las aplicaciones cliente tienen que volver a conectarse con el mismo nombre de servidor de bases de datos al servidor principal nuevo y pueden reanudar sus operaciones. Se establece un nuevo servidor en espera en la misma zona que el servidor principal anterior.
Para otras operaciones iniciadas por el usuario, como el escalado de proceso o el escalado de almacenamiento, los cambios se aplican en primer lugar en el modo en espera y después en el principal. Actualmente, el servicio no se conmuta por error en el servidor en espera y, por lo tanto, mientras la operación de escalado se lleva a cabo en el servidor principal, las aplicaciones experimentan un breve tiempo de inactividad.
También puede usar esta característica para conmutar por error al servidor en espera con un tiempo de inactividad reducido. Por ejemplo, el servidor principal podría estar en una zona de disponibilidad diferente que la aplicación después de una conmutación por error no planeada. Quiere devolver el servidor principal a la zona anterior para colocarlo con la aplicación.
Al ejecutar esta característica, el servidor en espera se prepara primero para asegurar que se encuentra al día con las transacciones recientes, lo que permite a la aplicación seguir realizando operaciones de lectura y escritura. A continuación, se promueve el servidor en modo de espera y se interrumpen las conexiones al principal. La aplicación puede seguir escribiendo en el servidor principal mientras se establece un nuevo servidor en espera en segundo plano. A continuación se indican los pasos necesarios para la conmutación por error planeada:
| Step | Descripción | ¿Se prevé algún tiempo de inactividad? |
|---|---|---|
| 1 | Espere a que el servidor en espera se haya conectado con el servidor principal. | No |
| 2 | El sistema de supervisión interno inicia el flujo de trabajo de conmutación por error. | No |
| 3 | Las escrituras de aplicaciones se bloquean cuando el servidor en espera está cerca del número de secuencia de registro principal (LSN). | Sí |
| 4 | El servidor en espera se promueve como un servidor independiente. | Sí |
| 5 | El registro DNS se actualiza con la nueva dirección IP del servidor en espera. | Sí |
| 6 | Aplicación para volver a conectarse y reanudar su lectura y escritura con el nuevo servidor principal. | No |
| 7 | Se establece un nuevo servidor en espera en otra zona. | No |
| 8 | El servidor en espera comienza a recuperar los registros (del blob de Azure) que faltó durante su establecimiento. | No |
| 9 | Se establece un estado estable entre el servidor principal y el servidor en espera. | No |
| 10 | Se ha completado el proceso de conmutación por error planeado. | No |
El tiempo de inactividad de la aplicación comienza en el paso 3 y puede reanudar la operación después del paso 5. El resto de los pasos suceden en segundo plano sin afectar a las escrituras y confirmaciones de la aplicación.
Sugerencia
Con el servidor flexible, puede programar actividades de mantenimiento iniciadas por Azure eligiendo una ventana de 60 minutos en un día de su preferencia, donde se espera que las actividades de las bases de datos sean bajas. Las tareas de mantenimiento de Azure, como la revisión o las actualizaciones de versiones secundarias, se producirían durante esa ventana. Si no elige una ventana personalizada, se selecciona una ventana de 1 hora asignada por el sistema entre las 11:00 p.m. a las 7:00 a.m. horas locales para el servidor. Estas actividades de mantenimiento iniciadas por Azure también se realizan en la réplica en espera para servidores flexibles configurados con zonas de disponibilidad.
Para obtener una lista de posibles eventos de tiempo de inactividad planeados, consulte Eventos de tiempo de inactividad planeados.
Conmutación por error no planeada
Se pueden producir tiempos de inactividad no planeados como resultado de interrupciones imprevistas, incluidos errores subyacentes de hardware, problemas de red y errores de software. Si el servidor de bases de datos configurado con una alta disponibilidad deja de funcionar de forma inesperada, la réplica en espera se activa y los clientes pueden reanudar sus operaciones. Si no se ha configurado con alta disponibilidad (HA), si se produce un error en el intento de reinicio, se aprovisiona automáticamente un nuevo servidor de base de datos. Aunque no es posible evitar un tiempo de inactividad no planeado, el servidor flexible lo reduce gracias a las operaciones de recuperación automáticas sin necesidad de intervención humana.
Para obtener información sobre las conmutaciones por error no planeadas y el tiempo de inactividad, incluidos los posibles escenarios, consulte Mitigación de tiempo de inactividad no planeado.
Pruebas de conmutación por error (conmutación por error forzada)
Con una conmutación por error forzada, puede simular un escenario de interrupción no planeado mientras ejecuta la carga de trabajo de producción y observa el tiempo de inactividad de la aplicación. También puede usar una conmutación por error forzada cuando el servidor principal deja de responder.
Una conmutación por error forzada desactiva el servidor principal e inicia el flujo de trabajo de conmutación por error en el que se realiza la operación de promoción en espera. Una vez que el modo de espera completa el proceso de recuperación hasta los últimos datos confirmados, se promueve para que sea el servidor principal. Los registros DNS se actualizan y la aplicación puede conectarse al servidor principal promocionado. La aplicación puede seguir escribiendo en el servidor principal mientras se establece un nuevo servidor en espera en segundo plano, y eso no afecta al tiempo de actividad.
Estos son los pasos durante una conmutación por error forzada:
| Step | Descripción | ¿Se prevé algún tiempo de inactividad? |
|---|---|---|
| 1 | El servidor principal se detiene poco después de recibir la solicitud de conmutación por error. | Sí |
| 2 | La aplicación encuentra tiempo de inactividad cuando el servidor principal está inactivo. | Sí |
| 3 | El sistema de supervisión interno detecta el error e inicia una conmutación por error en el servidor en espera. | Sí |
| 4 | El servidor en espera entra en modo de recuperación antes de promocionarse por completo como un servidor independiente. | Sí |
| 5 | El proceso de conmutación por error espera a que se complete la recuperación en espera. | Sí |
| 6 | Una vez que el servidor está activo, el registro DNS se actualiza con el mismo nombre de host, pero con la dirección IP del servidor en espera. | Sí |
| 7 | La aplicación puede volver a conectarse al nuevo servidor principal y reanudar la operación. | No |
| 8 | Se establece un servidor en espera en la zona preferida. | No |
| 9 | El servidor en espera comienza a recuperar los registros (del blob de Azure) que faltó durante su establecimiento. | No |
| 10 | Se establece un estado estable entre el servidor principal y el servidor en espera. | No |
| 11 | Se ha completado el proceso de conmutación por error forzada. | No |
Se espera que el tiempo de inactividad de la aplicación se inicie el paso 1 y persista hasta que se complete el paso 6. El resto de los pasos suceden en segundo plano sin afectar a las escrituras y confirmaciones de la aplicación.
Importante
El proceso de conmutación por error de un extremo a otro incluye (a) la conmutación por error al servidor en espera después del error del principal y (b) el establecimiento de un nuevo servidor en espera en estado estable. Como la aplicación incurre en tiempo de inactividad hasta que se completa la conmutación por error al servidor en espera, mida el tiempo de inactividad desde la perspectiva de la aplicación o el cliente en lugar del proceso de conmutación por error general de un extremo a otro.
Consideraciones al realizar conmutaciones por error forzadas
El tiempo total de la operación de un extremo a otro se puede considerar como mayor que el tiempo de inactividad real experimentado por la aplicación.
Importante
Observe siempre el tiempo de inactividad desde la perspectiva de la aplicación.
No realice conmutaciones por error inmediatas consecutivas. Espere al menos entre 15 y 20 minutos entre una conmutación por error y otra, lo que permitirá que el nuevo servidor en espera esté totalmente establecido.
Se recomienda realizar una conmutación por error forzada durante un período de baja actividad para reducir el tiempo de inactividad.
Procedimientos recomendados para las estadísticas de PostgreSQL después de la conmutación por error
Después de una conmutación por error de PostgreSQL, el mecanismo principal para mantener un rendimiento óptimo de la base de datos implica comprender los distintos roles de pg_statistic y las tablas pg_stat_*. La tabla pg_statistic alberga las estadísticas del optimizador, que son cruciales para el planificador de consultas. Estas estadísticas incluyen distribuciones de datos dentro de las tablas y permanecen intactas después de una conmutación por error, lo cual garantiza que el planificador de consultas pueda seguir optimizando la ejecución de consultas de forma eficaz en función de la información de distribución de datos histórica precisa.
Por el contrario, las tablas pg_stat_*, que registran estadísticas de actividad como el número de análisis, las tuplas leídas y las actualizaciones, se restablecen tras la conmutación por error. Un ejemplo de este tipo de tabla es pg_stat_user_tables, que realiza un seguimiento de la actividad de las tablas definidas por el usuario. Este restablecimiento está diseñado para reflejar con precisión el estado operativo del nuevo servidor principal, pero también significa la pérdida de métricas de actividad históricas que podían notificar el proceso de vacío automático y otras eficacias operativas.
Dada esta distinción, el procedimiento recomendado después de una conmutación por error de PostgreSQL consiste en ejecutar ANALYZE. Esta acción actualiza las tablas pg_stat_*, como pg_stat_user_tables, con estadísticas de actividad nuevas, lo cual ayuda al proceso de vacío automático y garantiza que el rendimiento de la base de datos sigue siendo óptimo en su nuevo rol. Este paso proactivo supera la brecha entre conservar las estadísticas esenciales del optimizador y actualizar las métricas de actividad para alinearse con el estado actual de la base de datos.
Experiencia de nivel de zona
Zonal: para recuperarse de un error de nivel de zona, puede realizar una restauración a un momento dado mediante la copia de seguridad. Puede elegir un punto de restauración personalizado con la hora más reciente para restaurar los datos más recientes. Un nuevo servidor flexible se implementa en otra zona no afectada. El tiempo necesario para la restauración depende de la copia de seguridad anterior y del volumen de registros de transacciones que se van a recuperar.
Para más información sobre la restauración a un momento dado, consulte Copia de seguridad y restauración en el Servidor flexible de Azure Database for PostgreSQL.
Con redundancia de zona: el servidor flexible se conmuta por error automáticamente al servidor en espera en un plazo entre 60 y 120 s sin pérdida de datos.
Configuraciones sin zonas de disponibilidad
Aunque no se recomienda, puede configurar el servidor flexible sin alta disponibilidad habilitada. Para servidores flexibles configurados sin alta disponibilidad, el servicio proporciona almacenamiento con redundancia local con tres copias de datos, copia de seguridad con redundancia de zona (en regiones donde se admite) y resistencia integrada del servidor para reiniciar automáticamente un servidor bloqueado y reubicar el servidor en otro nodo físico. El Acuerdo de Nivel de Servicio del 99,9 % de tiempo de actividad se ofrece en esta configuración. Durante los eventos de conmutación por error planeados o no planeados, si el servidor deja de funcionar, el servicio mantiene la disponibilidad de los servidores mediante el siguiente procedimiento automático:
- Se aprovisiona una nueva máquina virtual Linux de proceso.
- El almacenamiento con archivos de datos se asigna a la nueva máquina virtual.
- El motor de base de datos PostgreSQL pasa a estar en línea en la nueva máquina virtual.
En la imagen siguiente se muestra la transición entre la máquina virtual y el error de almacenamiento.

Recuperación ante desastres entre regiones y continuidad empresarial
En caso de que se produzca un desastre en toda la región, Azure puede proporcionar protección frente a desastres de geografía regional o a gran escala con recuperación ante desastres mediante el uso de otra región. Para obtener más información sobre la arquitectura de recuperación ante desastres de Azure, consulte Arquitectura de recuperación ante desastres de Azure a Azure.
El servidor flexible proporciona características que protegen los datos y mitigan el tiempo de inactividad para las bases de datos críticas durante eventos de tiempo de inactividad planeados y no planeados. Según la infraestructura de Azure que ofrece una sólida resistencia y disponibilidad, un servidor flexible ofrece características de continuidad empresarial que proporcionan protección ante errores, se ocupan de los requisitos de tiempo de recuperación y reducen el riesgo de pérdida de datos. Al diseñar las aplicaciones, debe tener en cuenta la tolerancia al tiempo de inactividad —el objetivo de tiempo de recuperación (RTO) y el riesgo de pérdida de datos—y el objetivo de punto de recuperación (RPO). Por ejemplo, su base de datos empresarial esencial tiene unos requisitos de tiempo de actividad más estrictos que una base de datos de prueba.
Recuperación ante desastres en la geografía de varias regiones
Copia de seguridad y restauración con redundancia geográfica
La copia de seguridad y restauración con redundancia geográfica proporcionan la capacidad de restaurar el servidor en una región diferente en caso de desastre. Proporciona al menos una durabilidad del 99,99999999999999 % (16 nueves) de los objetos de copia de seguridad durante un año.
La copia de seguridad con redundancia geográfica solo se puede configurar en el momento de la creación del servidor. Cuando el servidor se configura con copia de seguridad con redundancia geográfica, los datos de copia de seguridad y los registros de transacciones se copian en la región emparejada de forma asincrónica mediante la replicación de almacenamiento.
Para más información sobre la copia de seguridad y la restauración con redundancia geográfica, consulte copia de seguridad y restauración con redundancia geográfica.
Réplicas de lectura
Las réplicas de lectura entre regiones se pueden implementar para proteger las bases de datos frente a errores de nivel de región. Las réplicas de lectura se actualizan de manera asincrónica mediante la tecnología de replicación física de PostgreSQL y pueden generar retrasos en la principal. Las réplicas de lectura se admiten en niveles de proceso optimizados para memoria y de uso general.
Para obtener más información sobre las características y consideraciones de réplica de lectura, consulte Réplicas de lectura.
Detección, notificación y administración de interrupciones
Si el servidor está configurado con copia de seguridad con redundancia geográfica, puede realizar la restauración geográfica en la región emparejada. Se aprovisiona un nuevo servidor y se recupera en los últimos datos disponibles que se copiaron en esta región.
También puede usar réplicas de lectura entre regiones. En caso de error de la región, puede realizar una operación de recuperación ante desastres promoviendo la réplica de lectura para que sea un servidor independiente de lectura y escritura. Se espera que el objetivo de punto de recuperación sea de hasta 5 minutos (posible pérdida de datos), excepto en el caso de un error regional grave cuando el RPO puede estar cerca del retraso de replicación en el momento del error.
Para obtener más información sobre la mitigación y recuperación de tiempos de inactividad no planeados después del desastre regional, consulte Mitigación de tiempo de inactividad no planeado.