Conexión y administración de Azure Databricks en Microsoft Purview (versión preliminar)
En este artículo se describe cómo registrar Azure Databricks y cómo autenticar e interactuar con Azure Databricks en Microsoft Purview. Para obtener más información sobre Microsoft Purview, lea el artículo introductorio.
Importante
Esta característica está actualmente en versión preliminar. Los Términos de uso complementarios para las versiones preliminares de Microsoft Azure incluyen términos legales adicionales que se aplican a las características de Azure que están en versión beta, en versión preliminar o que aún no se han publicado en disponibilidad general.
Funciones admitidas
| Extracción de metadatos | Examen completo | Examen incremental | Examen con ámbito | Clasificación | Etiquetar | Directiva de acceso | Linaje | Uso compartido de datos | Vista en vivo |
|---|---|---|---|---|---|---|---|---|---|
| Sí | Sí | No | Sí | No | No | No | Sí | No | No |
Nota:
Este conector trae metadatos del metastore de Hive con ámbito de área de trabajo de Azure Databricks. Para examinar los metadatos en el catálogo de Unity de Azure Databricks, consulte Conector del catálogo de Azure Databricks Unity.
Al examinar el metastore de Hive de Azure Databricks, Microsoft Purview admite:
Extracción de metadatos técnicos, entre los que se incluyen:
- Área de trabajo de Azure Databricks
- Servidor de Hive
- Databases
- Tablas que incluyen las columnas, las claves externas, las restricciones únicas y la descripción del almacenamiento
- Vistas que incluyen las columnas y la descripción del almacenamiento
Captura de la relación entre tablas externas y recursos de Azure Data Lake Storage Gen2/Blob de Azure (ubicaciones externas).
Captura del linaje estático entre tablas y vistas en función de la definición de vista.
Al configurar el examen, puede elegir examinar todo el metastore de Hive o limitar el examen a un subconjunto de esquemas.
Comparación con el examen a través del conector genérico de Metastore de Hive en caso de que lo use para examinar Azure Databricks anteriormente:
- Puede configurar directamente el examen de áreas de trabajo de Azure Databricks sin acceso directo a HMS. Usa el token de acceso personal de Databricks para la autenticación y se conecta a un clúster para realizar el examen.
- Se captura la información del área de trabajo de Databricks.
- Se captura la relación entre tablas y recursos de almacenamiento.
Limitaciones conocidas
Cuando se elimina el objeto del origen de datos, actualmente el examen posterior no quitará automáticamente el recurso correspondiente en Microsoft Purview.
Requisitos previos
Debe tener una cuenta de Azure con una suscripción activa. Cree una cuenta de forma gratuita.
Debe tener una cuenta de Microsoft Purview activa.
Necesita una Key Vault de Azure y conceder permisos de Microsoft Purview para acceder a los secretos.
Necesita permisos de administrador de origen de datos y lector de datos para registrar un origen y administrarlo en el portal de gobernanza de Microsoft Purview. Para obtener más información sobre los permisos, consulte Control de acceso en Microsoft Purview.
Configure el entorno de ejecución de integración autohospedado más reciente. Para obtener más información, consulte Creación y configuración de un entorno de ejecución de integración autohospedado. La versión mínima de Integration Runtime autohospedado compatible es 5.20.8227.2.
Asegúrese de que JDK 11 está instalado en la máquina donde está instalado el entorno de ejecución de integración autohospedado. Reinicie la máquina después de instalar recientemente el JDK para que surta efecto.
Asegúrese de que Visual C++ Redistributable (versión Visual Studio 2012 Update 4 o posterior) esté instalado en la máquina donde se ejecuta el entorno de ejecución de integración autohospedado. Si no tiene instalada esta actualización, descárguela ahora.
En el área de trabajo de Azure Databricks:
Genere un token de acceso personal y almacénelo como secreto en Azure Key Vault.
Cree un clúster. Anote el identificador del clúster: puede encontrarlo en el área de trabajo de Azure Databricks:> Proceso- clúster ->> Etiquetas -> Etiquetas agregadas automáticamente ->
ClusterId.Asegúrese de que el usuario tiene los permisos siguientes para conectarse al clúster de Azure Databricks:
- Se puede asociar al permiso para conectarse al clúster en ejecución.
- Puede reiniciar el permiso para desencadenar automáticamente el clúster para que se inicie si su estado finaliza al conectarse.
Registrarse
En esta sección se describe cómo registrar un área de trabajo de Azure Databricks en Microsoft Purview mediante el portal de gobernanza de Microsoft Purview.
Vaya a su cuenta de Microsoft Purview.
Seleccione Mapa de datos en el panel izquierdo.
Seleccione Registrar.
En Registrar orígenes, seleccione Continuar con Azure Databricks>.
En la pantalla Registrar orígenes (Azure Databricks), haga lo siguiente:
En Nombre, escriba un nombre que Microsoft Purview mostrará como origen de datos.
Para la suscripción de Azure y el nombre del área de trabajo de Databricks, seleccione la suscripción y el área de trabajo que desea examinar en la lista desplegable. La dirección URL del área de trabajo de Databricks se rellena automáticamente.
En Seleccionar una colección, elija una colección de la lista o cree una nueva. Este paso es opcional.
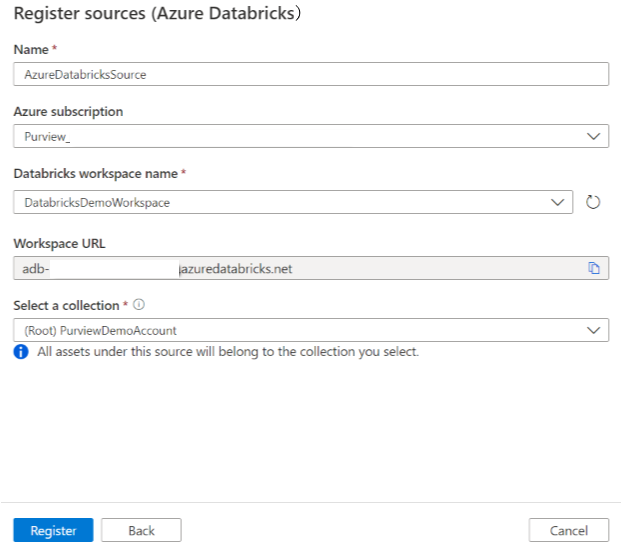
Seleccione Finalizar.
Examinar
Sugerencia
Para solucionar cualquier problema con el examen:
- Confirme que ha seguido todos los requisitos previos.
- Revise nuestra documentación de solución de problemas de examen.
Siga estos pasos para examinar Azure Databricks para identificar automáticamente los recursos. Para obtener más información sobre el examen en general, consulte Exámenes e ingesta en Microsoft Purview.
En el Centro de administración, seleccione Entornos de ejecución de integración. Asegúrese de que está configurado un entorno de ejecución de integración autohospedado. Si no está configurado, siga los pasos descritos en Creación y administración de un entorno de ejecución de integración autohospedado.
Vaya a Orígenes.
Seleccione la instancia de Azure Databricks registrada.
Seleccione + Nuevo examen.
Proporcione los detalles siguientes:
Nombre: escriba un nombre para el examen.
Método de extracción: Indique que se van a extraer metadatos del metastore de Hive o del catálogo de Unity. Seleccione Metastore de Hive.
Conectar a través de Integration Runtime: seleccione el entorno de ejecución de integración autohospedado configurado.
Credencial: seleccione la credencial para conectarse al origen de datos. Asegúrese de:
- Seleccione Autenticación de token de acceso al crear una credencial.
- Proporcione el nombre secreto del token de acceso personal que creó en Requisitos previos en el cuadro adecuado.
Para obtener más información, consulte Credenciales para la autenticación de origen en Microsoft Purview.
Id. de clúster: especifique el identificador de clúster al que Se conecta Microsoft Purview y activa el examen. Puede encontrarlo en el área de trabajo de Azure Databricks :> Proceso -> clúster -> Etiquetas -> Etiquetas agregadas automáticamente ->
ClusterId.Puntos de montaje: proporcione el punto de montaje y la cadena de ubicación de origen de Azure Storage cuando tenga almacenamiento externo montado manualmente en Databricks. Use el formato
/mnt/<path>=abfss://<container>@<adls_gen2_storage_account>.dfs.core.windows.net/;/mnt/<path>=wasbs://<container>@<blob_storage_account>.blob.core.windows.net. Se usa para capturar la relación entre las tablas y los recursos de almacenamiento correspondientes en Microsoft Purview. Esta configuración es opcional, si no se especifica, dicha relación no se recupera.Para obtener la lista de puntos de montaje en el área de trabajo de Databricks, ejecute el siguiente comando de Python en un cuaderno:
dbutils.fs.mounts()Imprime todos los puntos de montaje como se muestra a continuación:
[MountInfo(mountPoint='/databricks-datasets', source='databricks-datasets', encryptionType=''), MountInfo(mountPoint='/mnt/ADLS2', source='abfss://samplelocation1@azurestorage1.dfs.core.windows.net/', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-tracking', source='databricks/mlflow-tracking', encryptionType=''), MountInfo(mountPoint='/mnt/Blob', source='wasbs://samplelocation2@azurestorage2.blob.core.windows.net', encryptionType=''), MountInfo(mountPoint='/databricks-results', source='databricks-results', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-registry', source='databricks/mlflow-registry', encryptionType=''), MountInfo(mountPoint='/', source='DatabricksRoot', encryptionType='')]En este ejemplo, especifique lo siguiente como puntos de montaje:
/mnt/ADLS2=abfss://samplelocation1@azurestorage1.dfs.core.windows.net/;/mnt/Blob=wasbs://samplelocation2@azurestorage2.blob.core.windows.netEsquema: subconjunto de esquemas que se van a importar expresados como una lista de esquemas separados por punto y coma. Por ejemplo,
schema1; schema2. Todos los esquemas de usuario se importan si esa lista está vacía. Todos los esquemas y objetos del sistema se omiten de forma predeterminada.Los patrones de nombres de esquema aceptables que usan la sintaxis de expresiones DE SQL LIKE incluyen el uso de %. Por ejemplo:
A%; %B; %C%; D- Empezar con A o
- Terminar con B o
- Contener C o
- D igual
El uso de NOT y caracteres especiales no es aceptable.
Nota:
Este filtro de esquema se admite en Integration Runtime autohospedado, versión 5.32.8597.1 y posteriores.
Memoria máxima disponible: memoria máxima (en gigabytes) disponible en la máquina del cliente para que se usen los procesos de examen. Este valor depende del tamaño de Azure Databricks que se va a examinar.
Nota:
Como regla general, proporcione 1 GB de memoria por cada 1000 tablas.
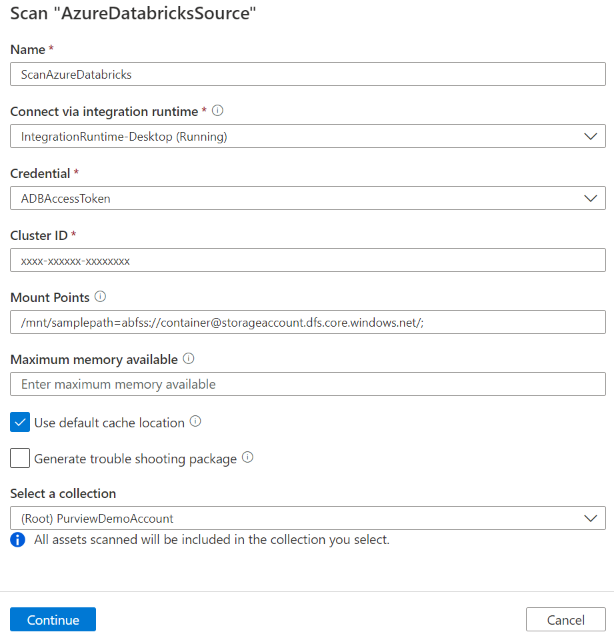
Seleccione Continuar.
En Desencadenador de examen, elija si desea configurar una programación o ejecutar el examen una vez.
Revise el examen y seleccione Guardar y ejecutar.
Una vez que el examen se complete correctamente, consulte cómo examinar y buscar recursos de Azure Databricks.
Visualización de los exámenes y las ejecuciones de examen
Para ver los exámenes existentes:
- Vaya al portal de gobernanza de Microsoft Purview. En el panel izquierdo, seleccione Mapa de datos.
- Seleccione el origen de datos. Puede ver una lista de exámenes existentes en ese origen de datos en Exámenes recientes o puede ver todos los exámenes en la pestaña Exámenes .
- Seleccione el examen que tiene los resultados que desea ver. En el panel se muestran todas las ejecuciones de examen anteriores, junto con el estado y las métricas de cada ejecución de examen.
- Seleccione el identificador de ejecución para comprobar los detalles de la ejecución del examen.
Administrar los exámenes
Para editar, cancelar o eliminar un examen:
Vaya al portal de gobernanza de Microsoft Purview. En el panel izquierdo, seleccione Mapa de datos.
Seleccione el origen de datos. Puede ver una lista de exámenes existentes en ese origen de datos en Exámenes recientes o puede ver todos los exámenes en la pestaña Exámenes .
Seleccione el examen que desea administrar. Después, podrá:
- Edite el examen seleccionando Editar examen.
- Para cancelar un examen en curso, seleccione Cancelar ejecución del examen.
- Para eliminar el examen, seleccione Eliminar examen.
Nota:
- La eliminación del examen no elimina los recursos de catálogo creados a partir de exámenes anteriores.
- El recurso ya no se actualizará con los cambios de esquema si la tabla de origen ha cambiado y vuelve a examinar la tabla de origen después de editar la descripción en la pestaña Esquema de Microsoft Purview.
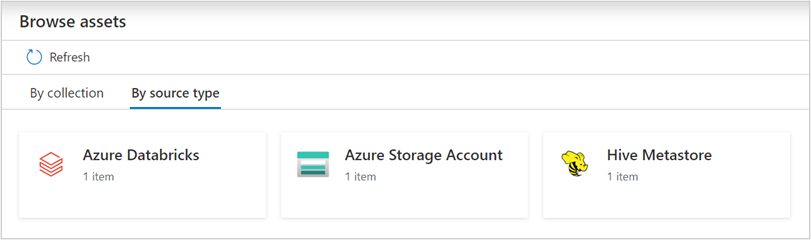
Examinar y buscar recursos
Después de examinar Azure Databricks, puede examinar el catálogo de datos o buscar en el catálogo de datos para ver los detalles del recurso.
En el recurso del área de trabajo de Databricks, puede encontrar el metastore de Hive asociado y las tablas o vistas, que también se aplican invertidas.
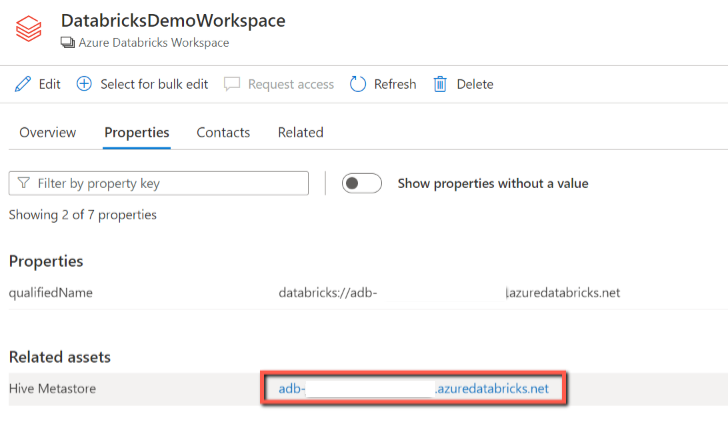
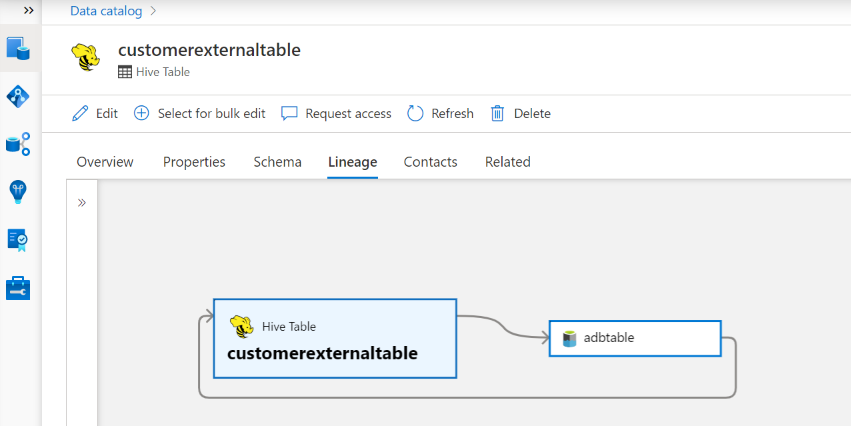
Linaje
Consulte la sección funcionalidades admitidas en los escenarios de Azure Databricks admitidos. Para obtener más información sobre el linaje en general, consulte guía del usuario de linaje y linaje de datos.
Vaya a la pestaña Hive table/view asset - lineage (Recurso de tabla o vista de Hive:> linaje), donde puede ver la relación de recursos cuando corresponda. Para la relación entre los recursos de tabla y almacenamiento externo, verá que el recurso de tabla de Hive y el recurso de almacenamiento están conectados directamente bidireccionalmente, ya que se afectan mutuamente entre sí. Si usa el punto de montaje en la instrucción create table, debe proporcionar la información del punto de montaje en la configuración de examen para extraer dicha relación.
Siguientes pasos
Ahora que ha registrado el origen, use las siguientes guías para obtener más información sobre Microsoft Purview y sus datos:
Comentaris
Properament: al llarg del 2024 eliminarem gradualment GitHub Issues com a mecanisme de retroalimentació del contingut i el substituirem per un nou sistema de retroalimentació. Per obtenir més informació, consulteu: https://aka.ms/ContentUserFeedback.
Envieu i consulteu els comentaris de