Instalar y habilitar Desduplicación de datos
En este tema se explica cómo instalar la característica Desduplicación de datos, cómo evaluar las cargas de trabajo para la desduplicación y cómo habilitar Desduplicación de datos en volúmenes específicos.
Nota
Si planea ejecutar la desduplicación de datos en un clúster de conmutación por error, todos los nodos del clúster deben tener instalado el rol de servidor Desduplicación de datos.
Instalación de Desduplicación de datos
Importante
KB4025334 contiene una serie de acumulaciones de correcciones para la desduplicación de datos, incluidas correcciones de confiabilidad importantes, y se recomienda encarecidamente su instalación cuando se utilice la desduplicación de datos con Windows Server 2016.
Instalar Desduplicación de datos mediante el Administrador del servidor
- En el Asistente para agregar roles y características, seleccione Roles de servidor y, después, seleccione Desduplicación de datos.
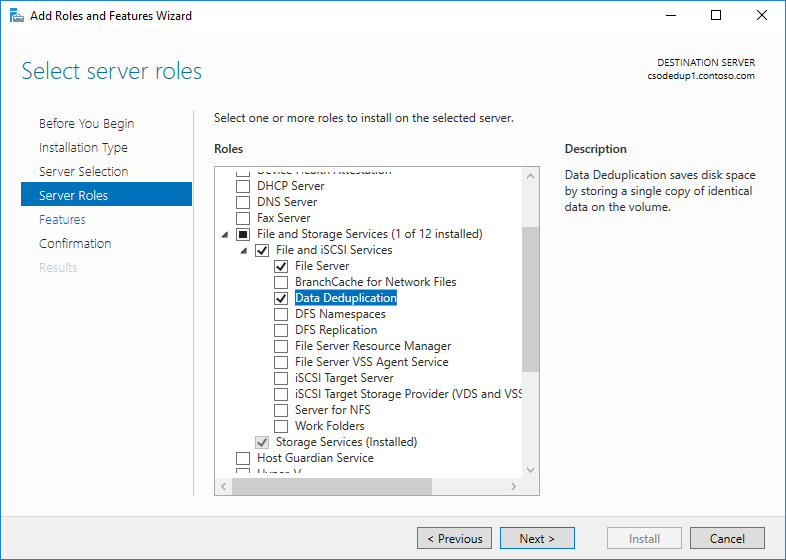
- Haga clic en Siguiente hasta que se active el botón Instalar y, a continuación, haga clic en Instalar.
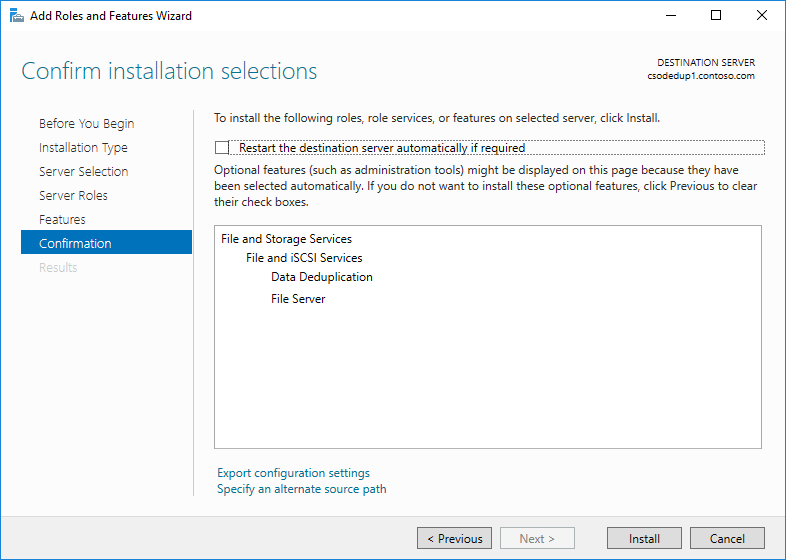
Instalar Desduplicación de datos con PowerShell
Para instalar la desduplicación de datos, ejecute el siguiente comando de PowerShell como administrador:Install-WindowsFeature -Name FS-Data-Deduplication
Para instalar la desduplicación de datos:
Desde un servidor que ejecuta Windows Server 2016, o posterior, o desde un equipo con Windows con lasHerramientas de administración remota del servidor (RSAT) instaladas, instale la desduplicación de datos con una referencia explícita a la instancia de servidor (reemplace "MyServer" por el nombre real de la instancia de servidor):
Install-WindowsFeature -ComputerName <MyServer> -Name FS-Data-DeduplicationOr
Conecte de manera remota con la instancia de servidor con comunicación remota de PowerShell e instale la desduplicación de datos mediante DISM:
Enter-PSSession -ComputerName MyServer dism /online /enable-feature /featurename:dedup-core /all
Habilitación de Desduplicación de datos
Determinación de qué cargas de trabajo son candidatas para Desduplicación de datos
Desduplicación de datos puede reducir de manera eficaz los costos de consumo de datos de la aplicación de servidor, ya que reduce la cantidad de espacio en disco consumido por los datos redundantes. Antes de habilitar la desduplicación, es importante que comprenda las características de su carga de trabajo para asegurarse de que obtiene el máximo rendimiento de su almacenamiento. Hay dos clases de cargas de trabajo a tener en cuenta:
- Cargas de trabajo recomendadas que han demostrado tener tanto conjuntos de datos que se benefician de la desduplicación como patrones de consumo de recursos que son compatibles con el modelo de procesamiento posterior de Desduplicación de datos. Le recomendamos que siempre habilite Desduplicación de datos en estas cargas de trabajo:
- Servidores de archivos de uso general (GPFS) que sirven a recursos compartidos, como recursos compartidos de equipo, carpetas particulares de usuario, carpetas de trabajo y recursos compartidos de desarrollo de software.
- Servidores de infraestructura de escritorio virtualizado (VDI).
- Aplicaciones de copia de seguridad virtualizadas, como Microsoft Data Protection Manager (DPM).
- Cargas de trabajo que podrían beneficiarse de desduplicación, pero no siempre son buenas candidatas para ella. Por ejemplo, las cargas de trabajo siguientes podrían funcionar bien con la desduplicación, pero debe evaluar primero las ventajas de la desduplicación:
- Hosts de Hyper-V de uso general
- Servidores SQL Server
- Servidores de línea de negocio (LOB)
Evaluar las cargas de trabajo para Desduplicación de datos
Importante
Si está ejecutando una carga de trabajo recomendada, puede omitir esta sección e ir a la sección Habilitación de Desduplicación de datos para su carga de trabajo.
Para determinar si una carga de trabajo funciona bien con la desduplicación, responda a las preguntas siguientes. Si no está seguro acerca de una carga de trabajo, considere realizar una implementación piloto de Desduplicación de datos en un conjunto de datos de prueba para la carga de trabajo para ver cómo se desempeña.
¿Mi conjunto de datos de la carga de trabajo tiene suficiente duplicación para beneficiarse de la habilitación de la desduplicación? Antes de habilitar Desduplicación de datos para una carga de trabajo, investigue cuánta duplicación de conjunto de datos de la carga de trabajo tiene mediante la herramienta de evaluación del ahorro de desduplicación de datos o DDPEval. Después de instalar Desduplicación de datos, puede encontrar esta herramienta en
C:\Windows\System32\DDPEval.exe. DDPEval puede evaluar el potencial de optimización en los volúmenes conectados directamente (incluidas unidades locales o volúmenes compartidos de clúster) y recursos compartidos de red asignados o sin asignar.La ejecución de DDPEval.exe devolverá un resultado similar al siguiente:
Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:\Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0¿Qué aspecto tienen mis patrones de E/S de la carga de trabajo con relación a su conjunto de datos? ¿Qué rendimiento obtengo para mi carga de trabajo? Desduplicación de datos realiza la optimización de los archivos como un trabajo periódico, en lugar de cuando el archivo se escribe un el disco. Por lo tanto, es importante examinar los patrones de lectura previstos de la carga de trabajo para el volumen desduplicado. Como Desduplicación de datos mueve el contenido del archivo al almacenamiento de fragmentos e intenta organizar el almacenamiento de fragmentos por archivo siempre que sea posible, las operaciones de lectura se desempeñarán mejor cuando se aplican a intervalos secuenciales de un archivo.
Las cargas de trabajo de tipo base de datos suelen tener patrones de lectura más aleatorios que los patrones de lectura secuenciales, porque las bases de datos no suelen garantizar que el diseño de la base de datos sea óptimo para todas las posibles consultas que se pueden ejecutar. Como las secciones del almacén de fragmentos pueden existir en todo el volumen, el acceso a los intervalos de datos en el almacén de fragmentos para las consultas de base de datos puede introducir latencia adicional. Las cargas de trabajo de alto rendimiento son especialmente sensibles a esta latencia adicional, pero otras cargas de trabajo de tipo base de datos podrían no serlo.
Nota
Estos problemas se aplican principalmente a las cargas de trabajo de almacenamiento en volúmenes formados por medios de almacenamiento rotacionales tradicionales (también conocidos como unidades de disco duro o HDD). La infraestructura de almacenamiento de memoria flash (también conocido como unidades de disco de estado sólido o SSD) se ve menos afectada por los patrones aleatorios de E/S porque una de las propiedades de los medios de memoria flash es el mismo tiempo de acceso a todas las ubicaciones de los medios. Por lo tanto, la desduplicación no presentará la misma cantidad de latencia para las lecturas en conjuntos de datos de la carga de trabajo almacenados en los medios de memoria flash, como ocurre en los medios de almacenamiento rotacionales tradicionales.
¿Cuáles son los requisitos de recursos de mi carga de trabajo en el servidor? Dado que Desduplicación de datos usa un modelo de procesamiento posterior, Desduplicación de datos necesita periódicamente disponer de suficientes recursos del sistema para completar su optimización y otros trabajos. Esto significa que las cargas de trabajo que tienen un determinado tiempo de inactividad, como por la noche o los fines de semana, son idóneas para la desduplicación, mientras que las cargas de trabajo que se ejecutan ininterrumpidamente podrían no serlo. Aun así, las cargas de trabajo sin tiempo de inactividad podrían ser buenas candidatas para la desduplicación si la carga de trabajo no tiene requisitos elevados de recursos en el servidor.
Habilitación de Desduplicación de datos
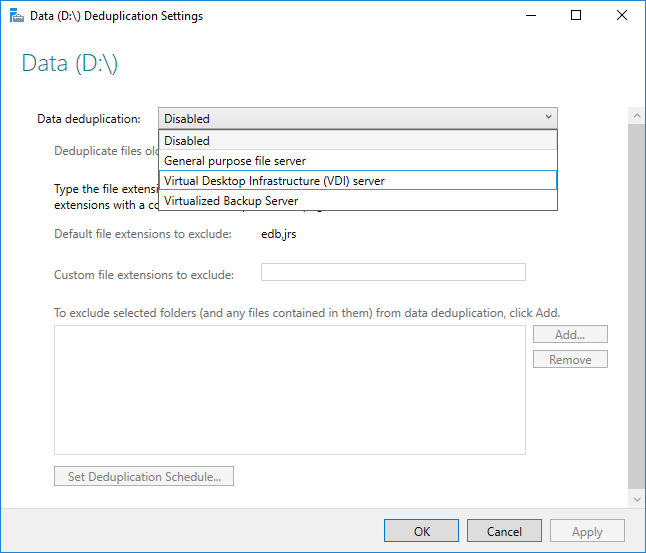
Antes de habilitar Desduplicación de datos, debe elegir el tipo de uso que más se parezca a la carga de trabajo. Hay tres tipos de uso incluidos con Desduplicación de datos.
- Predeterminado: optimizado específicamente para servidores de archivos de uso general.
- Hyper-V: optimizado específicamente para servidores VDI.
- Copia de seguridad: optimizado específicamente para aplicaciones de copia de seguridad virtualizadas, como Microsoft DPM.
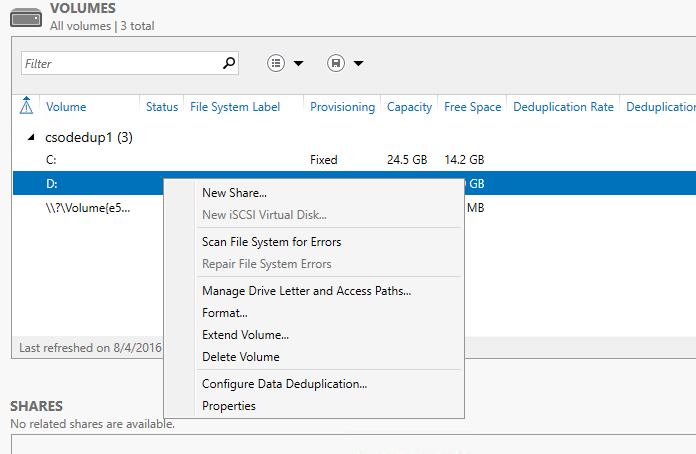
Habilitar Desduplicación de datos mediante el Administrador del servidor
- Seleccione Servicios de archivos y almacenamiento en el Administrador del servidor.
- Seleccione Volúmenes en Servicios de archivos y almacenamiento.
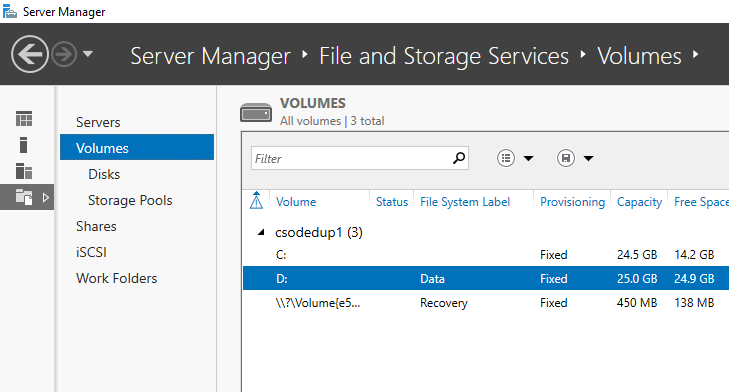
- Haga clic con el botón derecho en el volumen deseado y seleccione Configurar desduplicación de datos.
- Seleccione el Tipo de uso deseado en el cuadro de lista desplegable y seleccione Aceptar.
- Si está ejecutando una carga de trabajo recomendada, ha terminado. Para otras cargas de trabajo, consulte Otras consideraciones.
Nota
Obtenga más información sobre la exclusión de extensiones de archivo o carpetas y la selección de la programación de desduplicación, incluido por qué podría interesarle hacerlo, en la página sobre la configuración de desduplicación de datos.
Habilitar Desduplicación de datos con PowerShell
Con un contexto de administrador, ejecute el siguiente comando de PowerShell:
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Selected-Usage-Type>Si está ejecutando una carga de trabajo recomendada, ha terminado. Para otras cargas de trabajo, consulte Otras consideraciones.
Nota
Los cmdlets de PowerShell de Desduplicación de datos, incluido Enable-DedupVolume, pueden ejecutarse de forma remota si se anexa el parámetro -CimSession con una sesión CIM. Esto es especialmente útil para ejecutar la desduplicación de datos de los cmdlets de PowerShell de forma remota en una instancia de servidor. Para crear una nueva sesión de CIM, ejecute New-CimSession.
Otras consideraciones
Importante
Si está ejecutando una carga de trabajo recomendada, puede omitir esta sección.
- Los tipos de uso de Desduplicación de datos ofrecen valores predeterminados razonables para cargas de trabajo recomendadas, pero también proporcionan un buen punto de partida para todas las cargas de trabajo. Para otras cargas de trabajo que no sean las recomendadas, es posible modificar Configuración avanzada de Desduplicación de datos para mejorar el rendimiento de desduplicación.
- Si la carga de trabajo tiene requisitos elevados de recursos en el servidor, los trabajos de Desduplicación de datos deberían programarse para ejecutarse durante los tiempos de inactividad para esa carga de trabajo. Esto es especialmente importante cuando se ejecuta la desduplicación en un host hiperconvergido, ya que la ejecución de Desduplicación de datos durante las horas de trabajo previstas puede agotar las máquinas virtuales.
- Si la carga de trabajo no tiene requisitos elevados de recursos, o si es más importante que se completen los trabajos de optimización que atender a las solicitudes de carga de trabajo, se pueden ajustar la memoria, la CPU y la prioridad de los trabajos de Desduplicación de datos.
Preguntas más frecuentes
Quiero ejecutar Desduplicación de datos en el conjunto de datos para la carga de trabajo X. ¿Es posible? Aparte de las cargas de trabajo que se sabe que no interoperan con Desduplicación de datos, admitimos completamente la integridad de datos de Desduplicación de datos con cualquier carga de trabajo. Las cargas de trabajo recomendadas son compatibles también con Microsoft por rendimiento. El rendimiento de otras cargas de trabajo depende en gran medida de lo que hacen en el servidor. Debe determinar qué efectos sobre el rendimiento tiene Desduplicación de datos en la carga de trabajo, y si son aceptables para esta carga de trabajo.
¿Cuáles son los requisitos de capacidad del volumen para los volúmenes desduplicados? En Windows Server 2012 y Windows Server 2012 R2, los volúmenes tenían que ajustarse cuidadosamente para asegurarse de que Desduplicación de datos pudiera hacer frente a la renovación en el volumen. Normalmente, esto significaba que el tamaño máximo medio de un volumen desduplicado para una elevada carga de trabajo de renovación era de 1 a 2 TB, y el tamaño máximo absoluto recomendado era de 10 TB. En Windows Server 2016, estas limitaciones se han quitado. Para obtener más información, consulte What's new in Data Deduplication (Novedades de Desduplicación de datos).
¿Es necesario modificar la programación u otros valores de Desduplicación de datos para cargas de trabajo recomendadas? No, los tipos de uso proporcionados se crearon para ofrecer valores predeterminados razonables para cargas de trabajo recomendadas.
¿Cuáles son los requisitos de memoria para Desduplicación de datos?
Como mínimo, Desduplicación de datos debe tener 300 MB + 50 MB por cada TB de datos lógicos. Por ejemplo, si está optimizando un volumen de 10 TB, necesitará un mínimo de 800 MB de memoria asignada para la desduplicación (300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB). Mientras que Desduplicación de datos puede optimizar un volumen con esta baja cantidad de memoria, tener tales recursos restringidos ralentizará trabajos de Desduplicación de datos.
Lo ideal es que Desduplicación de datos tenga 1 GB de memoria por cada 1 TB de datos lógicos. Por ejemplo, si se está optimizando un volumen de 10 TB, lo ideal es necesitar 10 GB de memoria asignada para Desduplicación de datos (1 GB * 10). Esta relación asegurará el máximo rendimiento para los trabajos de Desduplicación de datos.
¿Cuáles son los requisitos de almacenamiento para Desduplicación de datos? En Windows Server 2016, Desduplicación de datos puede admitir tamaños de volúmenes de hasta 64 TB. Para más información, consulte Novedades de desduplicación de datos.