Přehled elastických fondů Hyperscale ve službě Azure SQL Database
Platí pro:![]() Azure SQL Database
Azure SQL Database
Tento článek obsahuje přehled elastických fondů Hyperscale ve službě Azure SQL Database.
Elastický fond Azure SQL Database umožňuje vývojářům saaS (software jako služba) optimalizovat poměr ceny a výkonu pro skupinu databází v rámci předepsaného rozpočtu a zároveň zajistit elasticitu výkonu pro každou databázi. Elastické fondy Azure SQL Database Hyperscale zavádí model sdílených prostředků pro databáze Hyperscale.
Příklady vytvoření, škálování nebo přesunutí databází do elastického fondu Hyperscale pomocí Azure CLI nebo PowerShellu najdete v tématu Práce s elastickými fondy Hyperscale pomocí nástrojů příkazového řádku.
Poznámka:
Elastické fondy pro Hyperscale jsou aktuálně ve verzi Preview.
Přehled
Nasaďte databázi Hyperscale do elastického fondu , abyste mohli sdílet prostředky mezi databázemi v rámci fondu a optimalizovat náklady na více databází s různými vzory využití.
Scénáře použití elastického fondu s databázemi Hyperscale:
- Pokud potřebujete škálovat výpočetní prostředky přidělené elastickému fondu v předvídatelné době nahoru nebo dolů, nezávisle na množství přiděleného úložiště.
- Pokud chcete škálovat výpočetní prostředky přidělené elastickému fondu přidáním jedné nebo více replik pro čtení.
- Pokud chcete použít vysokou propustnost transakčních protokolů pro úlohy náročné na zápis, a to i s nižšími výpočetními prostředky.
Migrace databází jiných než Hyperscale do elastického fondu Hyperscale upgraduje databáze na úroveň služby Hyperscale.
Architektura
Architektura samostatné databáze Hyperscale se tradičně skládá ze tří hlavních nezávislých komponent: Compute, Storage (stránkové servery) a protokolu (Log Service). Když pro databáze Hyperscale vytvoříte elastický fond, budou databáze v rámci fondu sdílet výpočetní prostředky a prostředky protokolu. Pokud se navíc rozhodnete nakonfigurovat vysokou dostupnost, vytvoří se každý fond s vysokou dostupností s ekvivalentní a nezávislou sadou výpočetních prostředků a prostředků protokolu.
Následující část popisuje architekturu elastického fondu pro databáze Hyperscale:
- Elastický fond Hyperscale se skládá z primárního fondu, který hostuje primární databáze Hyperscale, a pokud je nakonfigurovaný, až čtyři další fondy s vysokou dostupností.
- Primární databáze Hyperscale hostované v primárním elastickém fondu sdílejí výpočetní proces, virtuální jádra, paměť a mezipaměť SSD databázového stroje SQL Serveru (sqlservr.exe).
- Konfigurace vysoké dostupnosti pro primární fond vytvoří další fondy s vysokou dostupností, které obsahují repliky databáze jen pro čtení pro databáze v primárním fondu. Každý primární fond může mít maximálně čtyři fondy replik s vysokou dostupností. Každý fond s vysokou dostupností sdílí výpočetní prostředky, mezipaměť SSD a prostředky paměti pro všechny sekundární databáze jen pro čtení ve fondu.
- Databáze Hyperscale v primárním elastickém fondu sdílejí stejnou službu protokolů. Vzhledem k tomu, že databáze ve fondech s vysokou dostupností nemají úlohu zápisu, nevyužívají službu protokolu.
- Každá databáze Hyperscale má svou vlastní sadu stránkových serverů a tyto stránkovací servery se sdílejí mezi primární databází v primárním fondu a všemi databázemi sekundárních replik ve fondu s vysokou dostupností.
- Geograficky replikované sekundární databáze Hyperscale je možné umístit do jiného elastického fondu.
ApplicationIntent=ReadOnlyZadáním v databázi připojovací řetězec vás směruje do databáze repliky jen pro čtení v jednom z fondů s vysokou dostupností.
Následující diagram znázorňuje architekturu elastického fondu pro databáze Hyperscale:
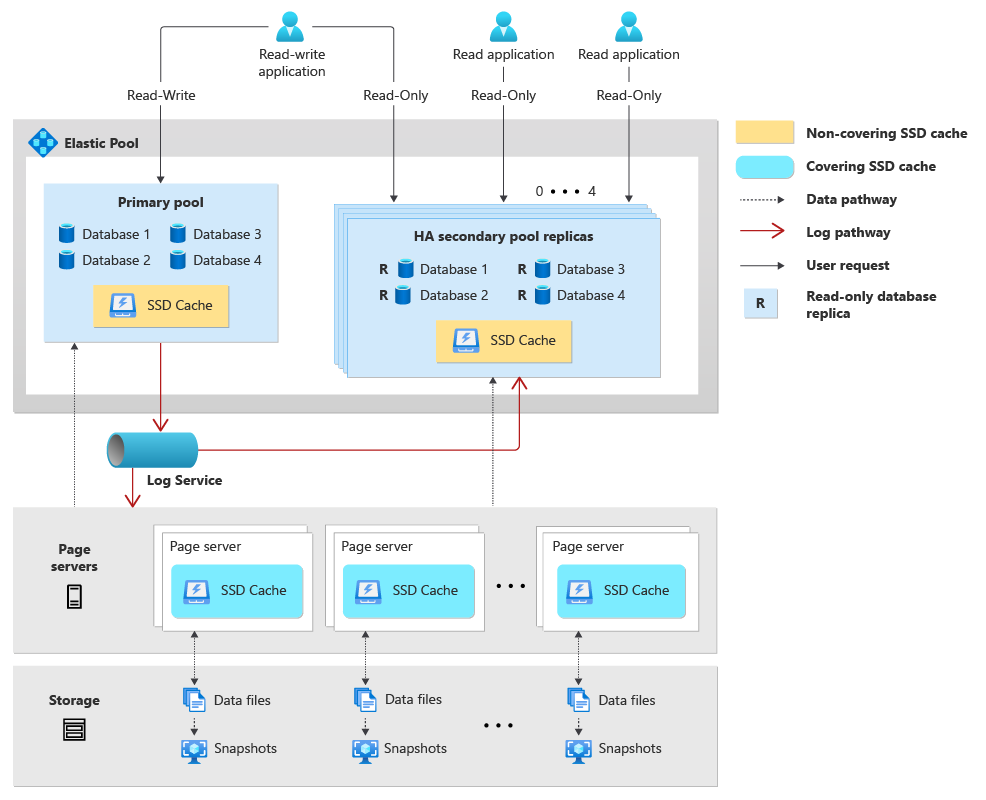
Správa databází elastického fondu Hyperscale
Stejné příkazy můžete použít ke správě databází Hyperscale ve fondu jako databáze ve fondu v jiných úrovních služby. Při vytváření elastického fondu Hyperscale nezapomeňte zadat Hyperscale edici.
Jediným rozdílem je možnost upravit počet replik s vysokou dostupností (H/A) pro stávající elastický fond Hyperscale. Postup:
HighAvailabilityReplicaCountPoužijte parametr příkazu Azure PowerShell Set-AzSqlElasticPool.--ha-replicasPoužijte parametr azure CLI az sql elastic-pool update command.
Ke správě databází Hyperscale v elastickém fondu můžete použít následující klientské nástroje:
- Azure PowerShell: Az.Sql.3.11.0 nebo vyšší. PowerShell AzureRM.Sql se nepodporuje.
- Azure CLI: Az verze 2.40.0 nebo vyšší.
- Transact-SQL (T-SQL) počínaje: SQL Server Management Studio (SSMS) v18.12.1 nebo Azure Data Studio v1.39.1.
Migrace databází bez hyperškálování do elastických fondů Hyperscale
Při migraci databáze do Hyperscale můžete databázi přidat do existujícího elastického fondu Hyperscale. Pro tyto migrace musí elastický fond Hyperscale existovat na stejném logickém serveru jako zdrojová databáze.
Při migraci databází do elastických fondů Hyperscale mějte na paměti maximální počet databází na elastický fond Hyperscale.
Migrace databází bez hyperškálování do elastických fondů Hyperscale pomocí T-SQL
Pomocí příkazů T-SQL můžete migrovat více databází pro obecné účely a přidat je do existujícího elastického fondu Hyperscale s názvem hsep1:
ALTER DATABASE gpepdb1 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb2 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb3 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb4 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
V tomto příkladu implicitně požadujete migraci z úrovně Pro obecné účely na Hyperscale tím, že určíte, že cílem SERVICE_OBJECTIVE je elastický fond Hyperscale. Každý z výše uvedených příkazů začne migrovat příslušnou databázi pro obecné účely do Hyperscale. Tyto ALTER DATABASE příkazy se vrátí rychle a nečeká na dokončení migrace. V uvedeném příkladu byste měli čtyři takové migrace z úrovně Pro obecné účely na Hyperscale spuštěné paralelně.
Můžete se dotazovat sys.dm_operation_status zobrazení dynamické správy a monitorovat stav těchto operací migrace na pozadí.
Migrace databází bez hyperškálování do elastických fondů Hyperscale pomocí PowerShellu
Pomocí příkazů PowerShellu můžete migrovat více databází pro obecné účely a přidat je do existujícího elastického fondu Hyperscale s názvem hsep1. Například následující ukázkový skript provede následující kroky:
- Pomocí rutiny Get-AzSqlElasticPoolDatabase zobrazíte seznam všech databází v elastickém fondu pro obecné účely s názvem
gpep1. - Rutina
Where-Objectfiltruje seznam pouze na názvy databází začínající nagpepdb. - Pro každou databázi spustí rutina Set-AzSqlDatabase migraci. V tomto případě implicitně požadujete migraci na úroveň služby Hyperscale zadáním cílového elastického fondu Hyperscale s názvem
hsep1.- Tento
-AsJobparametr umožňuje, aby se všechnySet-AzSqlDatabasepožadavky spouštěly paralelně. Pokud chcete spustit migrace 1:1, můžete parametr odebrat-AsJob.
- Tento
$dbs = Get-AzSqlElasticPoolDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -ElasticPoolName "gpep1"
$dbs | Where-Object { $_.DatabaseName -like "gpepdb*" } | % { Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -DatabaseName ($_.DatabaseName) -ElasticPoolName "hsep1" -AsJob }
Kromě zobrazení dynamické správy sys.dm_operation_status můžete pomocí rutiny PowerShellu Get-AzSqlDatabaseActivity monitorovat stav těchto operací migrace na pozadí.
Omezení prostředků
Následující seznam uvádí podporované limity pro práci s databázemi Hyperscale v rámci elastických fondů:
- Podporovaná generace hardwaru: Optimalizováno pro paměť řady Standard (Gen5), Premium-series a premium-series.
- Maximální počet virtuálních jader na fond: 80 nebo 128 virtuálních jader v závislosti na cíli na úrovni služby.
- Maximální podporovaná velikost dat na databázi: 100 TB.
- Maximální podporovaná celková velikost dat napříč databázemi ve fondu: 100 TB.
- Maximální podporovaná propustnost transakčního protokolu na databázi: 100 MB.
- Maximální podporovaná celková propustnost transakčního protokolu napříč databázemi ve fondu: 131,25 MB/s.
- Každý elastický fond Hyperscale může mít až 25 databází.
Podrobnější informace najdete v limitech prostředků elastických fondů Hyperscale pro paměť optimalizovanou pro řadu Standard, Premium-series a Premium-Series.
Poznámka:
Profily výkonu, podporované možnosti a publikované limity se můžou změnit, když je tato funkce ve verzi Preview. Proto je nejlepší ověřit váš případ použití pomocí pravidelného funkčního, výkonu a škálování testování úloh.
Omezení
Berte v úvahu následující omezení:
- Změna existujícího elastického fondu bez hyperškálování na edici Hyperscale se nepodporuje. Část migrace obsahuje některé alternativy, které můžete použít.
- Změna edice elastického fondu Hyperscale na edici bez hyperškálování se nepodporuje.
- Aby bylo možné provést zpětnou migraci oprávněné databáze, která je v elastickém fondu Hyperscale, musí být nejprve odebrána z elastického fondu Hyperscale. Samostatná databáze Hyperscale se pak dá vrátit zpět do samostatné databáze pro obecné účely.
- Pro úroveň služby Hyperscale je možné podporu redundance zón zadat pouze během vytváření databáze nebo elastického fondu a po zřízení prostředku není možné ji změnit. Další informace najdete v tématu Migrace služby Azure SQL Database do podpory zóny dostupnosti.
- Přidání pojmenované repliky do elastického fondu Hyperscale se nepodporuje. Při pokusu o přidání pojmenované repliky databáze Hyperscale do elastického fondu Hyperscale dojde k
UnsupportedReplicationOperationchybě. Místo toho vytvořte pojmenovanou repliku jako jednu databázi Hyperscale.
Aspekty zónově redundantních elastických fondů
U zónově redundantních elastických fondů zvažte následující:
Poznámka:
Elastické fondy Hyperscale s redundancí zón jsou aktuálně dostupné ve verzi Preview. Další informace najdete v blogovém příspěvku: Elastické fondy Hyperscale s redundancí zón.
- Do elastických fondů Hyperscale s redundancí zónově redundantního úložiště (ZRS nebo GZRS) je možné přidat pouze databáze s redundancí zón.
- Aby bylo možné databázi hyperškálování přidat do zónově redundantního elastického fondu, musí se vytvořit samostatná databáze Hyperscale s redundancí zón a zónově redundantním úložištěm zálohování (ZRS nebo GZRS). U databází Hyperscale bez redundance zón proveďte přenos dat do nové databáze Hyperscale s povolenou možností redundance zóny. Klon se musí vytvořit pomocí kopírování databáze, obnovení k určitému bodu v čase nebo geografické repliky. Další informace najdete v tématu Opětovné nasazení (Hyperscale).
- Pokud chcete přesunout databázi Hyperscale z jednoho elastického fondu do jiného, musí se nastavení zónově redundantního úložiště zálohování shodovat.
- Migrace databáze z jiné úrovně služby mimo Hyperscale do elastického fondu Hyperscale s redundancí zóny:
- Na webu Azure Portal nejprve povolte redundanci zón i zónově redundantní úložiště zálohování (ZRS). Pak můžete databázi přidat do zónově redundantního elastického fondu Hyperscale.
- Prostřednictvím PowerShellu nejprve povolte redundanci zón. Potom pomocí Set-AzSqlDatabase zajistěte, aby
-BackupStorageRedundancyse parametr použil k určení zónově redundantního úložiště zálohování (ZRS nebo GZRS).
Známé problémy
| Problém | Doporučení |
|---|---|
Ve výjimečných případech se může zobrazit chyba 45122 - This Hyperscale database cannot be added into an elastic pool at this time. In case of any questions, please contact Microsoft supportpři pokusu o přesunutí nebo obnovení nebo zkopírování databáze Hyperscale do elastického fondu. |
Toto omezení je způsobeno podrobnostmi specifickými pro implementaci. Pokud vás tato chyba blokuje, vytvořte incident podpory a požádejte o pomoc. |
Související obsah
- Práce s elastickými fondy Hyperscale pomocí nástrojů příkazového řádku
- Ceny elastických fondů
- Škálování prostředků elastického fondu ve službě Azure SQL Database
- Použití PowerShellu k monitorování a škálování elastického fondu ve službě Azure SQL Database
- Vzory tenantů víceklientské databáze SaaS
- Úvod do víceklientské aplikace SaaS, která používá model databáze na tenanta se službou Azure SQL Database
- Správa prostředků v hustých elastických fondech
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro