Kopírování a transformace dat do a z SQL Serveru pomocí služby Azure Data Factory nebo Azure Synapse Analytics
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak pomocí aktivity kopírování v kanálech Azure Data Factory a Azure Synapse kopírovat data z databáze SQL Serveru a do databáze SQL Serveru a pomocí Tok dat transformovat data v databázi SQL Serveru. Další informace najdete v úvodním článku pro Azure Data Factory nebo Azure Synapse Analytics.
Podporované funkce
Tento konektor SQL Serveru je podporovaný pro následující funkce:
| Podporované funkce | IR |
|---|---|
| aktivita Copy (zdroj/jímka) | (1) (2) |
| Mapování toku dat (zdroj/jímka) | (1) |
| Aktivita Lookup | (1) (2) |
| Aktivita GetMetadata | (1) (2) |
| Aktivita skriptu | (1) (2) |
| Aktivita uložená procedura | (1) (2) |
(1) Prostředí Azure Integration Runtime (2) Místní prostředí Integration Runtime
Seznam úložišť dat podporovaných jako zdroje nebo jímky aktivitou kopírování najdete v tabulce Podporované úložiště dat.
Konkrétně tento konektor SQL Serveru podporuje:
- SQL Server verze 2005 a novější
- Kopírování dat pomocí ověřování SQL nebo Windows
- Jako zdroj načítá data pomocí dotazu SQL nebo uložené procedury. Můžete se také rozhodnout pro paralelní kopírování ze zdroje SQL Serveru. Podrobnosti najdete v části Paralelní kopírování z databáze SQL.
- Jako jímka automaticky vytváří cílovou tabulku, pokud neexistuje na základě zdrojového schématu; připojení dat k tabulce nebo vyvolání uložené procedury s vlastní logikou během kopírování
SQL Server Express LocalDB není podporován.
Důležité
Zdroj dat musí podporovat datový typ NVARCHAR, protože ovlivňuje kódování dat, pokud se na data používá jiné než univerzální kódování.
Požadavky
Pokud se vaše úložiště dat nachází uvnitř místní sítě, virtuální sítě Azure nebo amazonového privátního cloudu, musíte nakonfigurovat místní prostředí Integration Runtime pro připojení k němu.
Pokud je vaše úložiště dat spravovanou cloudovou datovou službou, můžete použít Azure Integration Runtime. Pokud je přístup omezený na IP adresy schválené v pravidlech brány firewall, můžete do seznamu povolených přidat IP adresy prostředí Azure Integration Runtime.
K přístupu k místní síti bez nutnosti instalace a konfigurace místního prostředí Integration Runtime můžete také použít funkci Runtime integrace spravované virtuální sítě ve službě Azure Data Factory.
Další informace o mechanismech zabezpečení sítě a možnostech podporovaných službou Data Factory najdete v tématu Strategie přístupu k datům.
Začínáme
K provedení aktivita Copy s kanálem můžete použít jeden z následujících nástrojů nebo sad SDK:
- Nástroj pro kopírování dat
- Azure Portal
- Sada .NET SDK
- Sada Python SDK
- Azure PowerShell
- Rozhraní REST API
- Šablona Azure Resource Manageru
Vytvoření propojené služby SQL Serveru pomocí uživatelského rozhraní
Pomocí následujícího postupu vytvořte propojenou službu SQL Serveru v uživatelském rozhraní webu Azure Portal.
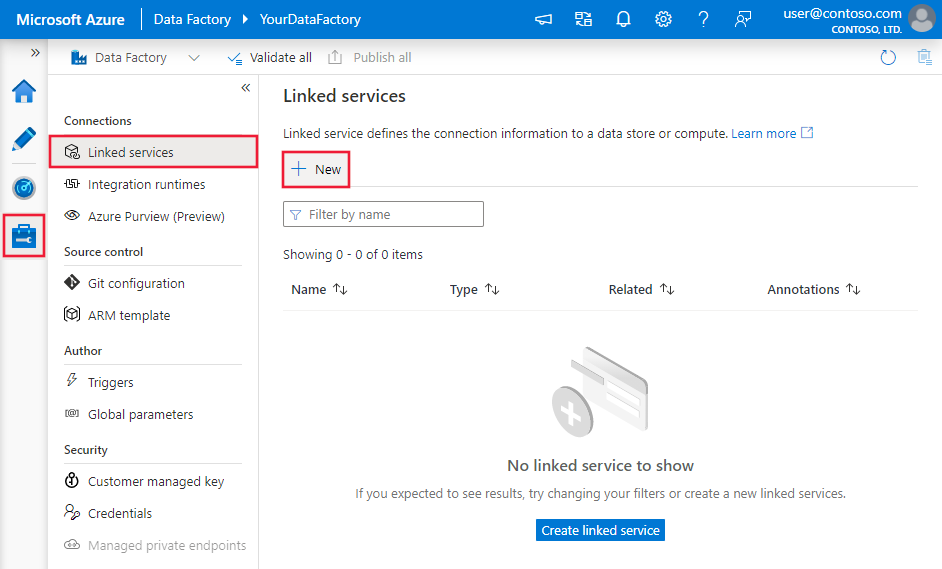
Přejděte na kartu Správa v pracovním prostoru Azure Data Factory nebo Synapse a vyberte Propojené služby a pak klikněte na Nový:
Vyhledejte SQL a vyberte konektor SQL Serveru.

Nakonfigurujte podrobnosti o službě, otestujte připojení a vytvořte novou propojenou službu.
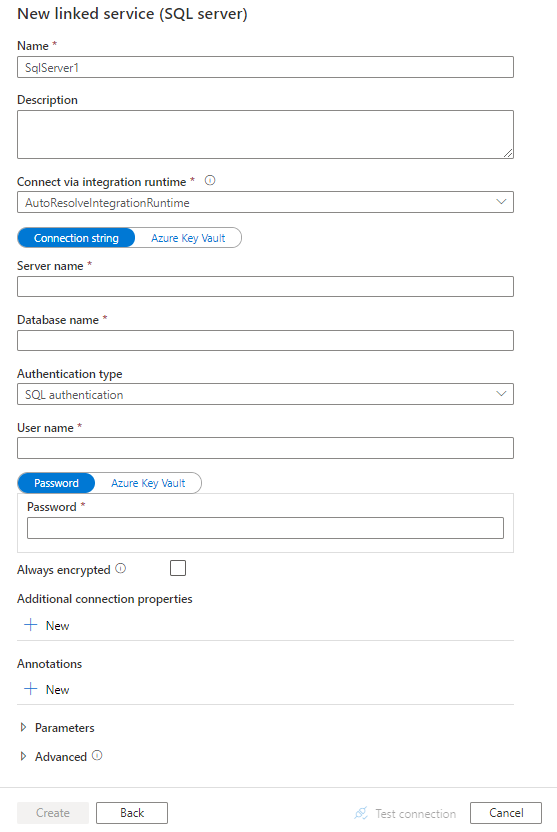
podrobnosti o konfiguraci Připojení oru
Následující části obsahují podrobnosti o vlastnostech, které slouží k definování entit kanálu Data Factory a Synapse specifických pro konektor databáze SQL Serveru.
Vlastnosti propojené služby
Tento konektor SQL Serveru podporuje následující typy ověřování. Podrobnosti najdete v odpovídajících částech.
Tip
Pokud dojde k chybě s kódem chyby UserErrorFailedTo Připojení ToSqlServer a zobrazí se zpráva typu Limit relace pro databázi XXX a bylo dosaženo, přidejte Pooling=false do svého připojovací řetězec a zkuste to znovu.
Ověřování SQL
Pokud chcete použít ověřování SQL, podporují se následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavena na SqlServer. | Ano |
| připojovací řetězec | Zadejte informace o připojovacím řetězce , které jsou potřeba pro připojení k databázi SQL Serveru. Zadejte přihlašovací jméno jako uživatelské jméno a ujistěte se, že databáze, ke které se chcete připojit, je namapovaná na toto přihlášení. Projděte si následující ukázky. | Ano |
| Heslo | Pokud chcete vložit heslo do služby Azure Key Vault, vytáhněte password konfiguraci z připojovací řetězec. Další informace najdete v příkladu JSON, který následuje za tabulkou a přihlašovacími údaji k úložišti ve službě Azure Key Vault. |
No |
| alwaysEncrypted Nastavení | Zadejte informace o alwaysencryptedsettings , které jsou potřeba k povolení funkce Always Encrypted k ochraně citlivých dat uložených na SQL Serveru pomocí spravované identity nebo instančního objektu. Další informace najdete v příkladu JSON podle tabulky a použití oddílu Always Encrypted . Pokud není zadáno, výchozí nastavení always encrypted je zakázané. | No |
| connectVia | Tento modul runtime integrace slouží k připojení k úložišti dat. Další informace najdete v části Požadavky . Pokud není zadaný, použije se výchozí prostředí Azure Integration Runtime. | No |
Příklad: Použití ověřování SQL
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Příklad: Použití ověřování SQL s heslem ve službě Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Příklad: Použití funkce Always Encrypted
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ověřování systému Windows
Pokud chcete použít ověřování systému Windows, podporují se následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavena na SqlServer. | Ano |
| připojovací řetězec | Zadejte informace o připojovacím řetězce , které jsou potřeba pro připojení k databázi SQL Serveru. Projděte si následující ukázky. | |
| userName | Zadejte uživatelské jméno. Příkladem je název_domény\uživatelské_jméno. | Ano |
| Heslo | Zadejte heslo pro uživatelský účet, který jste zadali pro uživatelské jméno. Označte toto pole jako SecureString , abyste ho bezpečně uložili. Nebo můžete odkazovat na tajný klíč uložený ve službě Azure Key Vault. | Ano |
| alwaysEncrypted Nastavení | Zadejte informace o alwaysencryptedsettings , které jsou potřeba k povolení funkce Always Encrypted k ochraně citlivých dat uložených na SQL Serveru pomocí spravované identity nebo instančního objektu. Další informace najdete v části Použití funkce Always Encrypted . Pokud není zadáno, výchozí nastavení always encrypted je zakázané. | No |
| connectVia | Tento modul runtime integrace slouží k připojení k úložišti dat. Další informace najdete v části Požadavky . Pokud není zadaný, použije se výchozí prostředí Azure Integration Runtime. | No |
Poznámka:
Ověřování systému Windows není podporováno v toku dat.
Příklad: Použití ověřování systému Windows
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=True;",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Příklad: Použití ověřování Windows s heslem ve službě Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"annotations": [],
"type": "SqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=True;",
"userName": "<domain\\username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Vlastnosti datové sady
Úplný seznam oddílů a vlastností dostupných pro definování datových sad najdete v článku o datových sadách . Tato část obsahuje seznam vlastností podporovaných datovou sadou SQL Serveru.
Pokud chcete kopírovat data z databáze SQL Serveru a do databáze SQL Serveru, jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavena na SqlServerTable. | Ano |
| schema | Název schématu | Ne pro zdroj, Ano pro jímku |
| table | Název tabulky nebo zobrazení | Ne pro zdroj, Ano pro jímku |
| tableName | Název tabulky nebo zobrazení se schématem Tato vlastnost je podporována pro zpětnou kompatibilitu. Pro nové úlohy použijte schema a table. |
Ne pro zdroj, Ano pro jímku |
Příklad
{
"name": "SQLServerDataset",
"properties":
{
"type": "SqlServerTable",
"linkedServiceName": {
"referenceName": "<SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Vlastnosti aktivity kopírování
Úplný seznam oddílů a vlastností dostupných k definování aktivit najdete v článku Pipelines . Tato část obsahuje seznam vlastností podporovaných zdrojem a jímkou SQL Serveru.
SQL Server jako zdroj
Tip
Pokud chcete efektivně načítat data z SQL Serveru pomocí dělení dat, přečtěte si další informace z paralelní kopie z databáze SQL.
Pokud chcete kopírovat data z SQL Serveru, nastavte typ zdroje v aktivitě kopírování na SqlSource. Ve zdrojové části aktivity kopírování jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavena na SqlSource. | Ano |
| sqlReaderQuery | Ke čtení dat použijte vlastní dotaz SQL. Příklad: select * from MyTable. |
No |
| sqlReaderStoredProcedureName | Tato vlastnost je název uložené procedury, která čte data ze zdrojové tabulky. Poslední příkaz SQL musí být příkaz SELECT v uložené proceduře. | No |
| storedProcedureParameters | Tyto parametry jsou určené pro uloženou proceduru. Povolené hodnoty jsou dvojice názvů nebo hodnot. Názvy a velikost písmen parametrů musí odpovídat názvům a velikostem písmen parametrů uložené procedury. |
No |
| Isolationlevel | Určuje chování uzamčení transakce pro zdroj SQL. Povolené hodnoty jsou: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Pokud není zadáno, použije se výchozí úroveň izolace databáze. Další podrobnosti najdete v tomto dokumentu . | No |
| partitionOptions | Určuje možnosti dělení dat používané k načtení dat z SQL Serveru. Povolené hodnoty jsou: None (výchozí), PhysicalPartitionsOfTable a DynamicRange. Pokud je povolená možnost oddílu (tj. ne None), je stupeň paralelismu souběžného načítání dat z SQL Serveru řízen parallelCopies nastavením aktivity kopírování. |
No |
| oddíl Nastavení | Zadejte skupinu nastavení pro dělení dat. Použít, pokud možnost oddílu není None. |
No |
V části partitionSettings: |
||
| partitionColumnName | Zadejte název zdrojového sloupce v celočíselném čísle nebo typu date/datetime (int, smallint, bigint, smalldatetimedate, , datetime, datetime2nebo datetimeoffset), který bude použit dělením rozsahu pro paralelní kopírování. Pokud není zadaný, index nebo primární klíč tabulky se automaticky rozpozná a použije jako sloupec oddílu.Použít, pokud je DynamicRangemožnost oddílu . Pokud k načtení zdrojových dat použijete dotaz, připojte se ?AdfDynamicRangePartitionCondition do klauzule WHERE. Příklad najdete v části Paralelní kopírování z databáze SQL. |
No |
| partitionUpperBound | Maximální hodnota sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá k rozhodování o kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Použít, pokud je DynamicRangemožnost oddílu . Příklad najdete v části Paralelní kopírování z databáze SQL. |
No |
| partitionLowerBound | Minimální hodnota sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá k rozhodování o kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Použít, pokud je DynamicRangemožnost oddílu . Příklad najdete v části Paralelní kopírování z databáze SQL. |
No |
Je třeba počítat s následujícím:
- Pokud je pro SqlSource zadán sqlReaderQuery, aktivita kopírování spustí tento dotaz na zdroj SQL Serveru pro získání dat. Uloženou proceduru můžete také zadat zadáním sqlReaderStoredProcedureName a storedProcedureParameters , pokud uložená procedura přebírá parametry.
- Při použití uložené procedury ve zdroji k načtení dat si všimněte, že uložená procedura je navržena jako vrácení jiného schématu, pokud je předána jiná hodnota parametru, může dojít k selhání nebo může dojít k neočekávanému výsledku při importu schématu z uživatelského rozhraní nebo při kopírování dat do databáze SQL s automatickým vytvořením tabulky.
Příklad: Použití dotazu SQL
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Příklad: Použití uložené procedury
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Definice uložené procedury
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
SQL Server jako jímka
Tip
Přečtěte si další informace o podporovaných chováních při zápisu, konfiguracích a osvědčených postupech z osvědčených postupů pro načítání dat do SQL Serveru.
Pokud chcete kopírovat data do SQL Serveru, nastavte typ jímky v aktivitě kopírování na SqlSink. V části jímky aktivity kopírování jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu jímky aktivity kopírování musí být nastavena na SqlSink. | Ano |
| preCopyScript | Tato vlastnost určuje dotaz SQL pro aktivitu kopírování, která se má spustit před zápisem dat do SQL Serveru. Vyvolá se pouze jednou za každé spuštění kopírování. Tuto vlastnost můžete použít k vyčištění předem načtených dat. | No |
| tableOption | Určuje, zda se má automaticky vytvořit tabulka jímky, pokud neexistuje na základě zdrojového schématu. Automatické vytváření tabulek není podporováno, pokud jímka určuje uloženou proceduru. Povolené hodnoty jsou: none (výchozí), autoCreate. |
No |
| sqlWriterStoredProcedureName | Název uložené procedury, která definuje, jak použít zdrojová data do cílové tabulky. Tato uložená procedura se vyvolá na dávku. Pro operace, které běží pouze jednou a nemají nic společného se zdrojovými daty, například odstranit nebo zkrátit, použijte preCopyScript vlastnost.Viz příklad volání uložené procedury z jímky SQL. |
No |
| storedProcedureTableTypeParameterName | Název parametru typu tabulky zadaného v uložené proceduře. | No |
| sqlWriterTableType | Název typu tabulky, který se má použít v uložené proceduře. Aktivita kopírování zpřístupní data přesunutá v dočasné tabulce s tímto typem tabulky. Kód uložené procedury pak může sloučit data, která se kopírují s existujícími daty. | No |
| storedProcedureParameters | Parametry uložené procedury. Povolené hodnoty jsou dvojice názvů a hodnot. Názvy a velikost písmen parametrů musí odpovídat názvům a velikostem písmen parametrů uložené procedury. |
No |
| writeBatchSize | Početřádkůch Povolené hodnoty jsou celá čísla pro počet řádků. Ve výchozím nastavení služba dynamicky určuje odpovídající velikost dávky na základě velikosti řádku. |
No |
| writeBatchTimeout | Doba čekání na dokončení operace vložení, upsertu a uložené procedury před vypršením časového limitu. Povolené hodnoty jsou pro časový rozsah. Příkladem je 00:30:00 po dobu 30 minut. Pokud není zadána žádná hodnota, časový limit je výchozí hodnota 00:30:00. |
No |
| maxConcurrent Připojení ions | Horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení. | Ne |
| WriteBehavior | Zadejte chování zápisu aktivity kopírování pro načtení dat do databáze SQL Serveru. Povolená hodnota je Insert a Upsert. Ve výchozím nastavení služba používá k načtení dat vložení. |
No |
| upsert Nastavení | Zadejte skupinu nastavení pro chování zápisu. Použít, pokud je Upsertmožnost WriteBehavior . |
No |
V části upsertSettings: |
||
| useTempDB | Určete, zda se má jako dočasná tabulka pro upsert použít globální dočasná tabulka nebo fyzická tabulka. Ve výchozím nastavení služba používá jako dočasnou tabulku globální dočasnou tabulku. hodnota je true. |
No |
| interimSchemaName | Zadejte dočasné schéma pro vytvoření dočasné tabulky, pokud se použije fyzická tabulka. Poznámka: Uživatel musí mít oprávnění k vytváření a odstraňování tabulek. Ve výchozím nastavení bude dočasná tabulka sdílet stejné schéma jako tabulka jímky. Použít, pokud je Falseparametr useTempDB . |
No |
| keys | Zadejte názvy sloupců pro jedinečnou identifikaci řádků. Můžete použít jeden klíč nebo řadu klíčů. Pokud není zadaný, použije se primární klíč. | No |
Příklad 1: Připojení dat
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
Příklad 2: Vyvolání uložené procedury během kopírování
Další informace najdete v části Volání uložené procedury z jímky SQL.
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
Příklad 3: Upsert data
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
Paralelní kopírování z databáze SQL
Konektor SQL Serveru v aktivitě kopírování poskytuje integrované dělení dat pro paralelní kopírování dat. Možnosti dělení dat najdete na kartě Zdroj aktivity kopírování.
Když povolíte dělené kopírování, aktivita kopírování spouští paralelní dotazy na zdroj SQL Serveru, aby načetla data podle oddílů. Paralelní stupeň se řídí parallelCopies nastavením aktivity kopírování. Pokud například nastavíte parallelCopies hodnotu čtyři, služba souběžně vygeneruje a spouští čtyři dotazy na základě zadané možnosti a nastavení oddílu a každý dotaz načte část dat z SQL Serveru.
Doporučujeme povolit paralelní kopírování s dělením dat, zejména pokud načítáte velké množství dat z SQL Serveru. Následující konfigurace jsou navržené pro různé scénáře. Při kopírování dat do souborového úložiště dat se doporučuje zapisovat do složky jako více souborů (zadat pouze název složky), v takovém případě je výkon lepší než zápis do jednoho souboru.
| Scénář | Navrhovaná nastavení |
|---|---|
| Úplné načtení z velké tabulky s fyzickými oddíly | Možnost oddílu: Fyzické oddíly tabulky. Během provádění služba automaticky rozpozná fyzické oddíly a kopíruje data podle oddílů. Pokud chcete zkontrolovat, jestli tabulka obsahuje fyzický oddíl nebo ne, můžete odkazovat na tento dotaz. |
| Úplné načtení z velké tabulky bez fyzických oddílů, zatímco s celočíselnou nebo datetime sloupcem pro dělení dat. | Možnosti oddílu: Oddíl dynamického rozsahu Sloupec oddílu (volitelné): Zadejte sloupec použitý k dělení dat. Pokud není zadaný, použije se sloupec primárního klíče. Horní mez oddílu a dolní mez oddílu (volitelné): Určete, jestli chcete určit krok oddílu. To není pro filtrování řádků v tabulce, všechny řádky v tabulce budou rozděleny a zkopírovány. Pokud není zadáno, aktivita kopírování automaticky zjistí hodnoty a může trvat dlouhou dobu v závislosti na hodnotách MIN a MAX. Doporučuje se zadat horní mez a dolní mez. Pokud má například sloupec oddílu ID hodnoty od 1 do 100 a dolní mez nastavíte jako 20 a horní mez jako 80, přičemž paralelní kopírování je 4, služba načte data o 4 oddílech – ID v rozsahu <=20, [21, 50], [51, 80] a >=81. |
| Načtěte velké množství dat pomocí vlastního dotazu bez fyzických oddílů, zatímco s celočíselnou nebo datem a datem a časem pro dělení dat. | Možnosti oddílu: Oddíl dynamického rozsahu Dotaz: SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>.Sloupec oddílu: Zadejte sloupec použitý k rozdělení dat. Horní mez oddílu a dolní mez oddílu (volitelné): Určete, jestli chcete určit krok oddílu. To není pro filtrování řádků v tabulce, všechny řádky ve výsledku dotazu budou rozděleny a zkopírovány. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Během provádění služba nahradí ?AdfRangePartitionColumnName skutečný název sloupce a rozsahy hodnot pro každý oddíl a odešle na SQL Server. Pokud má například sloupec oddílu ID hodnoty od 1 do 100 a dolní mez nastavíte jako 20 a horní mez 80, přičemž paralelní kopírování je 4, služba načte data podle 4 oddílů v rozsahu <=20, [21, 50], [51, 80] a >=81. Tady jsou další ukázkové dotazy pro různé scénáře: 1. Dotaz na celou tabulku: SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition2. Dotaz z tabulky s výběrem sloupce a dalšími filtry klauzule where: SELECT <column_list> FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Dotaz s poddotazy: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Dotaz s oddílem v poddotazu: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition) AS T |
Osvědčené postupy pro načtení dat s možností oddílu:
- Zvolte výrazný sloupec jako sloupec oddílu (například primární klíč nebo jedinečný klíč), abyste se vyhnuli nerovnoměrné distribuci dat.
- Pokud tabulka obsahuje předdefinovaný oddíl, použijte možnost oddílu Fyzické oddíly tabulky, abyste dosáhli lepšího výkonu.
- Pokud ke kopírování dat používáte Prostředí Azure Integration Runtime, můžete nastavit větší počet jednotek Integrace Dat (DIU) (>4) a využít tak více výpočetních prostředků. Zkontrolujte tam příslušné scénáře.
- "Stupeň paralelismu kopírování" řídí čísla oddílů, nastavení příliš velkého čísla někdy snižuje výkon, doporučujeme nastavit toto číslo jako (DIU nebo počet uzlů místního prostředí IR) * (2 až 4).
Příklad: Úplné načtení z velké tabulky s fyzickými oddíly
"source": {
"type": "SqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Příklad: Dotaz s oddílem dynamického rozsahu
"source": {
"type": "SqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Ukázkový dotaz pro kontrolu fyzického oddílu
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Pokud tabulka obsahuje fyzický oddíl, zobrazí se "HasPartition" jako "ano", například následující.

Osvědčený postup při načítání dat do SQL Serveru
Při kopírování dat do SQL Serveru můžete vyžadovat jiné chování zápisu:
- Připojení: Zdrojová data mají pouze nové záznamy.
- Upsert: Zdrojová data obsahují vložení i aktualizace.
- Přepsat: Pokaždé chci znovu načíst celou tabulku dimenzí.
- Psaní s vlastní logikou: Potřebuji další zpracování před posledním vložením do cílové tabulky.
Informace o konfiguraci a osvědčených postupech najdete v příslušných částech.
Připojení dat
Připojení dat je výchozím chováním tohoto konektoru jímky SQL Serveru. služba provede hromadné vložení pro efektivní zápis do tabulky. Zdroj a jímku můžete odpovídajícím způsobem nakonfigurovat v aktivitě kopírování.
Upsert dat
aktivita Copy teď podporuje nativní načítání dat do dočasné tabulky databáze a následné aktualizace dat v tabulce jímky, pokud existuje klíč, a jinak vložit nová data. Další informace o nastavení upsertu v aktivitách kopírování najdete v tématu SQL Server jako jímka.
Přepsat celou tabulku
Vlastnost preCopyScript můžete nakonfigurovat v jímce aktivity kopírování. V tomto případě pro každou aktivitu kopírování, která se spouští, služba nejprve spustí skript. Potom spustí kopii pro vložení dat. Pokud chcete například přepsat celou tabulku nejnovějšími daty, zadejte skript, který nejprve odstraní všechny záznamy před hromadným načtením nových dat ze zdroje.
Zápis dat pomocí vlastní logiky
Postup zápisu dat s vlastní logikou je podobný krokům popsaným v části Upsert data . Pokud potřebujete použít dodatečné zpracování před konečným vložením zdrojových dat do cílové tabulky, můžete načíst pracovní tabulku a pak vyvolat aktivitu uložené procedury nebo vyvolat uloženou proceduru v jímce aktivity kopírování, která použije data.
Vyvolání uložené procedury z jímky SQL
Při kopírování dat do databáze SQL Serveru můžete také nakonfigurovat a vyvolat uživatelem zadanou uloženou proceduru s dalšími parametry v každé dávce zdrojové tabulky. Funkce uložené procedury využívá parametry hodnot tabulky. Všimněte si, že služba automaticky zabalí uloženou proceduru do své vlastní transakce, takže jakákoli transakce vytvořená uvnitř uložené procedury se stane vnořenou transakcí a může mít vliv na zpracování výjimek.
Uloženou proceduru můžete použít, když předdefinované mechanismy kopírování neslouží k účelu. Příkladem je, když chcete použít dodatečné zpracování před posledním vložením zdrojových dat do cílové tabulky. Některé další příklady zpracování jsou, když chcete sloučit sloupce, vyhledat další hodnoty a vložit do více než jedné tabulky.
Následující ukázka ukazuje, jak pomocí uložené procedury provést upsert do tabulky v databázi SQL Serveru. Předpokládejme, že vstupní data a tabulka Marketing jímky mají tři sloupce: ProfileID, State a Category. Proveďte upsert založený na sloupci ProfileID a použijte ho pouze pro konkrétní kategorii s názvem ProductA.
V databázi definujte typ tabulky se stejným názvem jako sqlWriterTableType. Schéma typu tabulky je stejné jako schéma vrácené vstupními daty.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )V databázi definujte uloženou proceduru se stejným názvem jako sqlWriterStoredProcedureName. Zpracovává vstupní data ze zadaného zdroje a slučuje se do výstupní tabulky. Název parametru typu tabulky v uložené proceduře je stejný jako tableName definovaný v datové sadě.
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDV aktivitě kopírování definujte oddíl jímky SQL následujícím způsobem:
"sink": { "type": "SqlSink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
Mapování vlastností toku dat
Při transformaci dat při mapování toku dat můžete číst a zapisovat do tabulek z databáze SQL Serveru. Další informace najdete v tématu transformace zdroje a transformace jímky v mapování toků dat.
Poznámka:
Pokud chcete získat přístup k místnímu SQL Serveru, musíte použít spravovanou virtuální síť služby Azure Data Factory nebo Synapse s využitím privátního koncového bodu. Podrobný postup najdete v tomto kurzu .
Transformace zdroje
V následující tabulce jsou uvedeny vlastnosti podporované zdrojem SQL Serveru. Tyto vlastnosti můžete upravit na kartě Možnosti zdroje.
| Název | Popis | Povinní účastníci | Povolené hodnoty | Vlastnost skriptu toku dat |
|---|---|---|---|---|
| Table | Pokud jako vstup vyberete tabulku, tok dat načte všechna data z tabulky zadané v datové sadě. | No | - | - |
| Dotaz | Pokud jako vstup vyberete Dotaz, zadejte dotaz SQL pro načtení dat ze zdroje, který přepíše jakoukoli tabulku, kterou zadáte v datové sadě. Použití dotazů je skvělý způsob, jak snížit počet řádků pro testování nebo vyhledávání. Klauzule Order By není podporovaná, ale můžete nastavit úplný příkaz SELECT FROM. Můžete také použít uživatelem definované funkce tabulek. select * from udfGetData() je UDF v SQL, která vrací tabulku, kterou můžete použít v toku dat. Příklad dotazu: Select * from MyTable where customerId > 1000 and customerId < 2000 |
No | String | query |
| Velikost dávky | Zadejte velikost dávky pro rozdělení velkých dat do čtení. | No | Celé číslo | batchSize |
| Úroveň izolace | Zvolte jednu z následujících úrovní izolace: - Přečteno potvrzeno – Nepotvrzené čtení (výchozí) - Opakovatelné čtení -Serializovatelný – Žádné (ignorovat úroveň izolace) |
No | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZOVATELNÝ ŽÁDNÝ |
Isolationlevel |
| Povolení přírůstkového extrakce | Pomocí této možnosti můžete službě ADF sdělit, aby zpracovával jenom řádky, které se od posledního spuštění kanálu změnily. | No | - | - |
| Přírůstkový sloupec kalendářních dat | Při použití funkce přírůstkového extrakce musíte zvolit sloupec data a času, který chcete použít jako vodoznak ve zdrojové tabulce. | No | - | - |
| Povolení nativního zachytávání dat změn (Preview) | Pomocí této možnosti můžete službě ADF sdělit, aby zpracovávala pouze rozdílová data zachycená technologií zachytávání dat změn SQL od posledního spuštění kanálu. S touto možností se rozdílová data včetně vložení, aktualizace a odstranění načtou automaticky bez nutnosti sloupce přírůstkového data. Před použitím této možnosti v ADF musíte povolit zachytávání dat změn na SQL Serveru. Další informace o této možnosti v ADF najdete v nativním zachytávání dat změn. | No | - | - |
| Začít číst od začátku | Nastavení této možnosti s přírůstkovým extrahováním dá ADF pokyn ke čtení všech řádků při prvním spuštění kanálu se zapnutým přírůstkovým extrahováním. | No | - | - |
Tip
Běžný výraz tabulky (CTE) v SQL není podporován v režimu dotazu mapování toku dat, protože předpokladem použití tohoto režimu je, že dotazy lze použít v klauzuli FROM dotazu SQL, ale CTE to neudělají. Pokud chcete používat CTE, musíte vytvořit uloženou proceduru pomocí následujícího dotazu:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
Pak použijte režim Uložená procedura ve zdrojové transformaci mapování toku dat a nastavte @query podobný příklad with CTE as (select 'test' as a) select * from CTE. Pak můžete použít CTE podle očekávání.
Příklad zdrojového skriptu SQL Serveru
Pokud jako typ zdroje použijete SQL Server, přidružený skript toku dat:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from MYTABLE',
format: 'query') ~> SQLSource
Transformace jímky
Následující tabulka uvádí vlastnosti podporované jímkou SQL Serveru. Tyto vlastnosti můžete upravit na kartě Možnosti jímky.
| Název | Popis | Povinní účastníci | Povolené hodnoty | Vlastnost skriptu toku dat |
|---|---|---|---|---|
| Metoda aktualizace | Určete, jaké operace jsou povolené v cíli databáze. Výchozí hodnota je povolit pouze vkládání. Pokud chcete aktualizovat, upsertovat nebo odstranit řádky, je k označení řádků pro tyto akce potřeba transformace alter řádku. |
Ano | true nebo false |
s možností odsud vložitelné Aktualizovatelné upsertable |
| Klíčové sloupce | U aktualizací, upsertů a odstranění je nutné nastavit klíčové sloupce, aby bylo možné určit, který řádek se má změnit. Název sloupce, který vyberete jako klíč, se použije jako součást následné aktualizace, upsertu a odstranění. Proto je nutné vybrat sloupec, který existuje v mapování jímky. |
No | Pole | keys |
| Přeskočení psaní klíčových sloupců | Pokud chcete hodnotu nezapsat do klíčového sloupce, vyberte Přeskočit psaní klíčových sloupců. | No | true nebo false |
skipKeyWrites |
| Akce tabulky | Určuje, zda se mají před zápisem znovu vytvořit nebo odebrat všechny řádky z cílové tabulky. - Žádné: V tabulce se neprovede žádná akce. - Znovu vytvořte: Tabulka se přehodí a znovu vytvoří. Vyžaduje se při dynamickém vytváření nové tabulky. - Zkrácení: Odeberou se všechny řádky z cílové tabulky. |
No | true nebo false |
Obnovit truncate |
| Velikost dávky | Určete, kolik řádků se zapisuje v každé dávce. Větší velikosti dávek zlepšují kompresi a optimalizaci paměti, ale při ukládání dat do mezipaměti riskují výjimky z paměti. | No | Celé číslo | batchSize |
| Skripty pre a post SQL | Zadejte víceřádkové skripty SQL, které se spustí před (předzpracování) a po (po zpracování) dat zapisují do databáze jímky. | No | String | předsqls postSQLs |
Tip
- Doporučujeme rozdělit jednotlivé dávkové skripty několika příkazy do několika dávek.
- Jako součást dávky je možné spustit pouze příkazy DDL (Data Definition Language) a DML (Data Manipulation Language), které vracejí jednoduchý počet aktualizací. Další informace o provádění dávkových operací
Ukázkový skript jímky SQL Serveru
Při použití SQL Serveru jako typu jímky je přidružený skript toku dat:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SQLSink
Mapování datových typů pro SQL Server
Když kopírujete data z a do SQL Serveru, použijí se následující mapování z datových typů SQL Serveru na dočasné datové typy služby Azure Data Factory. Kanály Synapse, které implementují službu Data Factory, používají stejné mapování. Informace o tom, jak aktivita kopírování mapuje zdrojové schéma a datový typ na jímku, najdete v tématu Mapování schématu a datového typu.
| Datový typ SQL Serveru | Dočasný datový typ služby Data Factory |
|---|---|
| bigint | Int64 |
| binární | Bajt[] |
| bitové | Logická hodnota |
| char | Řetězec, znak[] |
| datum | DateTime |
| Datum a čas | DateTime |
| datetime2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| Desetinné číslo | Desetinné číslo |
| ATRIBUT FILESTREAM (varbinary(max)) | Bajt[] |
| Float | Hodnota s dvojitou přesností |
| image | Bajt[] |
| int | Int32 |
| Peníze | Desetinné číslo |
| Nchar | Řetězec, znak[] |
| Ntext | Řetězec, znak[] |
| numerické | Desetinné číslo |
| Nvarchar | Řetězec, znak[] |
| real | Jeden |
| Rowversion | Bajt[] |
| Smalldatetime | DateTime |
| smallint | Int16 |
| Smallmoney | Desetinné číslo |
| Sql_variant | Object |
| text | Řetězec, znak[] |
| čas | TimeSpan |
| časové razítko | Bajt[] |
| tinyint | Int16 |
| Uniqueidentifier | Guid |
| Varbinary | Bajt[] |
| varchar | Řetězec, znak[] |
| xml | String |
Poznámka:
U datových typů mapovaných na dočasný typ Decimal aktuálně aktivita Copy podporuje přesnost až 28. Pokud máte data, která vyžadují přesnost větší než 28, zvažte převod na řetězec v dotazu SQL.
Při kopírování dat z SQL Serveru pomocí Azure Data Factory se bitový datový typ mapuje na logický dočasný datový typ. Pokud máte data, která je potřeba uchovávat jako datový typ bitu, použijte dotazy s T-SQL CAST nebo CONVERT.
Vlastnosti aktivity vyhledávání
Podrobnosti o vlastnostech najdete v aktivitě Vyhledávání.
Vlastnosti aktivity GetMetadata
Podrobnosti o vlastnostech najdete v aktivitě GetMetadata.
Použití funkce Always Encrypted
Při kopírování dat z nebo do SQL Serveru s funkcí Always Encrypted postupujte následovně:
Uložte hlavní klíč sloupce (CMK) ve službě Azure Key Vault. Další informace o konfiguraci funkce Always Encrypted pomocí služby Azure Key Vault
Nezapomeňte udělit přístup k trezoru klíčů, kde je uložený hlavní klíč sloupce (CMK ). Požadovaná oprávnění najdete v tomto článku .
Vytvořte propojenou službu pro připojení k databázi SQL a povolte funkci Always Encrypted pomocí spravované identity nebo instančního objektu.
Poznámka:
SQL Server Always Encrypted podporuje následující scénáře:
- Úložiště dat zdroje nebo jímky používají spravovanou identitu nebo instanční objekt jako typ ověřování zprostředkovatele klíčů.
- Úložiště dat zdrojového i jímky používají spravovanou identitu jako typ ověřování zprostředkovatele klíče.
- Úložiště dat zdroje i jímky používají stejný instanční objekt jako typ ověřování zprostředkovatele klíčů.
Poznámka:
Sql Server Always Encrypted se v současné době podporuje pouze pro transformaci zdroje při mapování toků dat.
Nativní zachytávání dat změn
Azure Data Factory může podporovat nativní možnosti zachytávání dat změn pro SQL Server, Azure SQL DB a Azure SQL MI. Změněná data, včetně vložení, aktualizace a odstranění řádků v úložištích SQL, je možné automaticky rozpoznat a extrahovat mapováním toku dat ADF. Bez zkušeností s kódem při mapování toku dat můžou uživatelé snadno dosáhnout scénáře replikace dat z úložišť SQL připojením databáze jako cílového úložiště. Kromě toho mohou uživatelé také vytvořit libovolnou logiku transformace dat mezi tím, aby dosáhli scénáře přírůstkového ETL z úložišť SQL.
Ujistěte se, že název kanálu a aktivity zůstane beze změny, aby bylo možné kontrolní bod zaznamenat službou ADF, abyste získali změněná data z posledního spuštění automaticky. Pokud změníte název kanálu nebo název aktivity, kontrolní bod se resetuje, což vás povede k zahájení nebo získání změn odteď v dalším spuštění. Pokud chcete změnit název kanálu nebo název aktivity, ale přesto zachovat kontrolní bod, abyste získali změněná data z posledního spuštění automaticky, použijte k tomu vlastní klíč kontrolního bodu v aktivitě toku dat.
Při ladění kanálu funguje tato funkce stejně. Mějte na paměti, že kontrolní bod se resetuje při aktualizaci prohlížeče během spuštění ladění. Jakmile budete spokojeni s výsledkem kanálu spuštění ladění, můžete pokračovat v publikování a aktivaci kanálu. V okamžiku, kdy poprvé aktivujete publikovaný kanál, se automaticky restartuje od začátku nebo od této chvíle dojde ke změnám.
V části monitorování máte vždy možnost znovu spustit kanál. Když to uděláte, změněná data se vždy zaznamenávají z předchozího kontrolního bodu vybraného kanálu.
Příklad 1:
Když přímo zřetězíte zdrojovou transformaci odkazovanou na datovou sadu s povolenou datovou sadou SQL CDC s transformací jímky odkazovanou na databázi v mapování toku dat, změny provedené ve zdroji SQL se automaticky použijí na cílovou databázi, abyste mohli snadno získat scénář replikace dat mezi databázemi. Metodu aktualizace v transformaci jímky můžete použít k výběru, jestli chcete povolit vložení, povolit aktualizaci nebo povolit odstranění v cílové databázi. Ukázkový skript mapování toku dat je následující.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Příklad 2:
Pokud chcete povolit scénář ETL místo replikace dat mezi databází prostřednictvím SLUŽBY CDC SQL, můžete použít výrazy v mapování toku dat včetně isInsert(1), isUpdate(1) a isDelete(1) k rozlišení řádků s různými typy operací. Následuje jeden z ukázkových skriptů pro mapování toku dat na odvození jednoho sloupce s hodnotou: 1 pro označení vložených řádků, 2 pro označení aktualizovaných řádků a 3 pro označení odstraněných řádků pro podřízené transformace pro zpracování rozdílových dat.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Známé omezení:
- ADF načte pouze čisté změny z SQL CDC prostřednictvím cdc.fn_cdc_get_net_changes_.
Odstraňování potíží s připojením
Nakonfigurujte instanci SQL Serveru tak, aby přijímala vzdálená připojení. Spusťte aplikaci SQL Server Management Studio, klikněte pravým tlačítkem myši na server a vyberte Vlastnosti. V seznamu vyberte Připojení iony a zaškrtněte políčko Povolit vzdálená připojení k tomuto serveru.
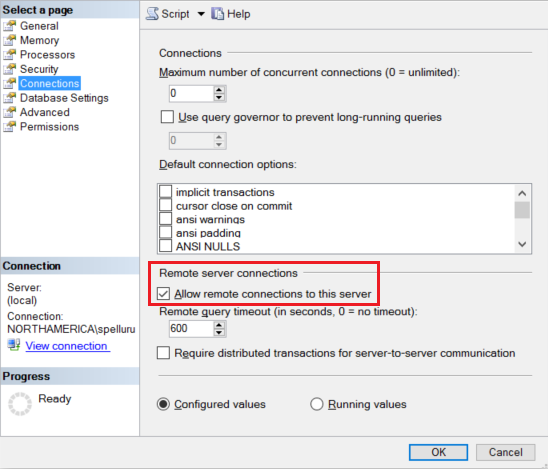
Podrobný postup najdete v tématu Konfigurace možnosti konfigurace serveru vzdáleného přístupu.
Spusťte NÁSTROJ SQL Server Configuration Manager. Rozbalte konfiguraci sítě SQL Serveru pro požadovanou instanci a vyberte Protokoly pro MSSQLSERVER. Protokoly se zobrazí v pravém podokně. Povolte tcp/IP tak, že kliknete pravým tlačítkem na TCP/IP a vyberete Povolit.
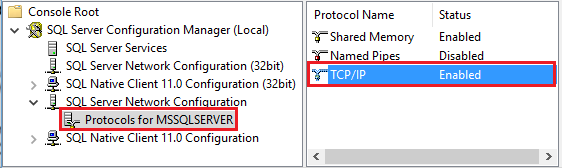
Další informace a alternativní způsoby povolení protokolu TCP/IP naleznete v tématu Povolení nebo zakázání síťového protokolu serveru.
Ve stejném okně poklikejte na tcp/IP a spusťte okno Vlastnosti protokolu TCP/IP.
Přepněte na kartu IP adresy . Posuňte se dolů a zobrazte část IPAll . Zapište port TCP. Výchozí hodnota je 1433.
Vytvořte pravidlo pro bránu Windows Firewall na počítači, které povolí příchozí provoz přes tento port.
Ověření připojení: Pokud se chcete připojit k SQL Serveru pomocí plně kvalifikovaného názvu, použijte SQL Server Management Studio z jiného počítače. Příklad:
"<machine>.<domain>.corp.<company>.com,1433".
Související obsah
Seznam úložišť dat podporovaných jako zdroje a jímky aktivitou kopírování najdete v tématu Podporované úložiště dat.