Nerelační databáze je databáze, která nepoužívá tabulkové schéma řádků a sloupců nalezených ve většině tradičních databázových systémů. Nerelační databáze místo toho používají model úložiště, který je optimalizovaný pro konkrétní požadavky typu uložených dat. Například data mohou být uložena jako jednoduché páry klíč/hodnota, jako dokumenty JSON nebo jako graf skládající se z hran a vrcholů.
Všechna tato úložiště dat mají společné je, že nepoužívají relační model. Obvykle jsou také konkrétnější v typu dat, která podporují a jak se dají data dotazovat. Úložiště dat časových řad jsou například optimalizovaná pro dotazy v časových sekvencích dat. Úložiště dat grafu jsou ale optimalizovaná pro zkoumání vážených vztahů mezi entitami. Žádný formát by nebyl dobře zobecněný pro úlohu správy transakčních dat.
Termín NoSQL odkazuje na úložiště dat, která nepoužívají SQL pro dotazy. Úložiště dat místo toho používají k dotazování dat jiné programovací jazyky a konstrukce. V praxi "NoSQL" znamená "nerelační databáze", i když mnoho z těchto databází podporuje dotazy kompatibilní s SQL. Základní strategie provádění dotazů se ale obvykle velmi liší od způsobu, jakým by tradiční systém pro správu relačních databází (RDBMS) spustil stejný dotaz SQL.
Existují varianty implementace a specializace databází NoSQL, jako jsou různé možnosti relačních databází. Tyto varianty poskytují každé implementaci své vlastní primární silné stránky a dodávají se s vlastní křivkou učení a doporučeními k používání. Následující části popisují hlavní kategorie nerelační databáze nebo databáze NoSQL.
Úložiště dat dokumentů
Úložiště dat dokumentu spravuje sadu pojmenovaných polí řetězců a datových hodnot objektů v entitě, která se označuje jako dokument. Tato úložiště dat obvykle ukládají data ve formě dokumentů JSON. Každá hodnota pole může být skalární položka, například číslo nebo složený prvek, například seznam nebo kolekce nadřazený-podřízený. Data v polích dokumentu lze kódovat různými způsoby, včetně XML, YAML, JSON, binárního formátu JSON (BSON) nebo dokonce uloženého jako prostý text. Pole v dokumentech jsou vystavená systému správy úložiště a umožňují aplikaci dotazovat a filtrovat data pomocí hodnot v těchto polích.
Dokument zpravidla obsahuje úplná data entity. To, z jakých položek je entita tvořena, je specifické pro aplikaci. Entita může například obsahovat podrobnosti o zákazníkovi, objednávce nebo kombinaci obojího. Jeden dokument může obsahovat informace, které by byly rozloženy do několika relačních tabulek v systému pro správu relačních databází (RDBMS). Úložiště dokumentů nevyžaduje, aby všechny dokumenty měly stejnou strukturu. Tato volná koncepce zajišťuje značnou flexibilitu. Aplikace můžou například ukládat různá data do dokumentů v reakci na změnu obchodních požadavků.
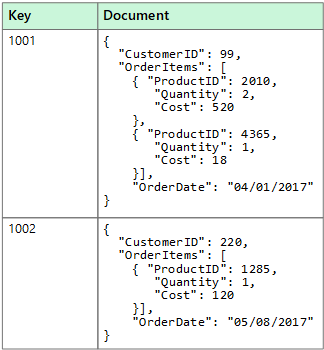
Aplikace může načítat dokumenty pomocí klíče dokumentu. Klíč je jedinečný identifikátor dokumentu, který je často hashován, aby pomohl rovnoměrně distribuovat data. Některé dokumentové databáze vytvářejí klíč dokumentu automaticky. Jiné umožňují určit atribut dokumentu, který se má použít jako klíč. Aplikace může dokumenty dotazovat také na základě hodnoty jednoho nebo více polí. Některé dokumentové databáze podporují indexování, které usnadňuje rychlé vyhledávání dokumentů na základě jednoho nebo více indexovaných polí.
Mnoho databází dokumentů podporuje místní aktualizace, což aplikaci umožní úpravy hodnot konkrétních polí v dokumentu, aniž by se celý dokument přepisoval. Operace čtení a zápisu přes více polí v jednom dokumentu jsou obvykle atomické.
Relevantní služba Azure:
Sloupcová úložiště dat
Sloupcové úložiště dat nebo úložiště dat rodiny sloupců uspořádá data do sloupců a řádků. V nejjednodušší podobě může úložiště dat rodiny sloupců vypadat velmi podobně jako relační databáze, alespoň koncepčně. Skutečná síla databáze rodiny sloupců spočívá v jeho denormalizovaném přístupu k strukturování řídkých dat, která vychází z přístupu orientovaného na sloupce k ukládání dat.
Úložiště dat rodiny sloupců si můžete představit jako ukládání tabulkových dat s řádky a sloupci, ale sloupce jsou rozdělené do skupin označovaných jako rodiny sloupců. Každá řada sloupců obsahuje sadu sloupců, které jsou logicky související a obvykle se načítají nebo manipulují jako jednotka. Další data, ke kterým se přistupuje odděleně, můžou být uložená v samostatných rodinách sloupců. V rámci rodiny sloupců je možné dynamicky přidávat nové sloupce a řádky můžou být řídké (to znamená, že řádek nemusí mít hodnotu pro každý sloupec).
Následující diagram ukazuje příklad se dvěma rodinami sloupců: Identity a Contact Info. Data pro jednu entitu mají stejný klíč řádku v každé skupině sloupců. Tato struktura, ve které se řádky libovolného objektu v řadě sloupců můžou dynamicky lišit, je důležitou výhodou přístupu rodiny sloupců, takže tato forma úložiště dat je vysoce vhodná pro ukládání dat s různými schématy.

Na rozdíl od úložiště klíč/hodnota nebo databáze dokumentů většina databází řady sloupců fyzicky ukládá data v pořadí klíčů, nikoli výpočtem hodnoty hash. Klíč řádku se považuje za primární index a umožňuje přístup na základě klíčů prostřednictvím konkrétního klíče nebo rozsahu klíčů. Některé implementace umožňují vytvořit sekundární indexy nad konkrétními sloupci v rodině sloupců. Sekundární indexy umožňují načíst data podle hodnoty sloupců, nikoli podle klíče řádku.
Na disku jsou všechny sloupce v řadě sloupců uloženy společně ve stejném souboru s určitým počtem řádků v každém souboru. U velkých datových sad tento přístup přináší výhodu výkonu snížením množství dat, která je potřeba načíst z disku, když se současně dotazuje jenom několik sloupců.
Operace čtení a zápisu pro řádek jsou obvykle atomické v rámci jedné řady sloupců, i když některé implementace poskytují atomicitu napříč celým řádkem, které pokrývají více rodin sloupců.
Relevantní služba Azure:
Úložiště dat klíč/hodnota
Úložiště typu klíč/hodnota je v podstatě velká zatřiďovací tabulka. Každou datovou hodnotu přidružíte k jedinečnému klíči a úložiště typu klíč/hodnota použije tento klíč k uložení dat pomocí odpovídající hashovací funkce. Hashovací funkce se vybírá tak, aby se zajistila rovnoměrné rozložení hashovaných klíčů v rámci úložiště dat.
Většina úložišť typu klíč/hodnota podporuje jenom jednoduché operace dotazování, vložení a odstranění. Pokud je třeba hodnotu změnit (ať už částečně, nebo úplně), aplikace musí přepsat stávající data pro celou hodnotu. Ve většině implementací představuje čtení nebo zápis jedné hodnoty atomickou operaci. Pokud je hodnota velká, může zápis chvíli trvat.
Aplikace může jako sadu hodnot uložit libovolná data, i když některá úložiště klíč/hodnota uplatňují omezení na maximální velikost hodnot. Pro software systému úložiště jsou uložené hodnoty neprůhledné. Veškeré informace o schématu musí poskytovat a interpretovat daná aplikace. Hodnoty jsou v podstatě objekty blob a úložiště klíč/hodnota jednoduše načte nebo uloží danou hodnotu podle klíče.
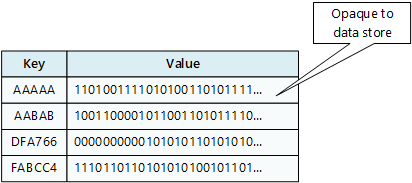
Úložiště klíč/hodnota jsou vysoce optimalizovaná pro aplikace, které provádějí jednoduché vyhledávání pomocí hodnoty klíče nebo rozsahu klíčů, ale jsou méně vhodné pro systémy, které potřebují dotazovat data napříč různými tabulkami klíčů/hodnot, například spojování dat mezi více tabulkami.
Úložiště klíč/hodnota se také neoptimalizuje pro scénáře, kdy je dotazování nebo filtrování podle hodnot bez klíčů důležité, a nikoli vyhledávání založené pouze na klíčích. Například u relační databáze můžete najít záznam pomocí klauzule WHERE k filtrování sloupců, které nejsou klíči, ale úložiště klíč/hodnoty obvykle nemají tento typ vyhledávací funkce pro hodnoty nebo pokud ano, vyžaduje pomalé prohledávání všech hodnot.
Úložiště typu klíč/hodnota může nabízet extrémní škálovatelnost, protože může snadno distribuovat data mezi několik uzlů na samostatných počítačích.
Relevantní služby Azure:
Úložiště dat grafů
Úložiště dat grafu spravuje dva typy informací, uzlů a hran. Uzly představují entity a hrany určují vztahy mezi těmito entitami. Uzly i hrany můžou mít vlastnosti, které poskytují informace o daném uzlu nebo hraně, podobně jako sloupce v tabulce. Hrany můžou mít také směr, který označuje povahu relace.
Účelem úložiště dat grafu je umožnit aplikaci efektivně provádět dotazy procházející sítí uzlů a hran a analyzovat vztahy mezi entitami. Následující diagram znázorňuje data pracovníků organizace strukturovaná jako graf. Entitami jsou zaměstnanci a oddělení a hrany označují vztahy podřízenosti a oddělení, ve kterých zaměstnanci pracují. Šipky na hranách označují v tomto grafu směr relací.
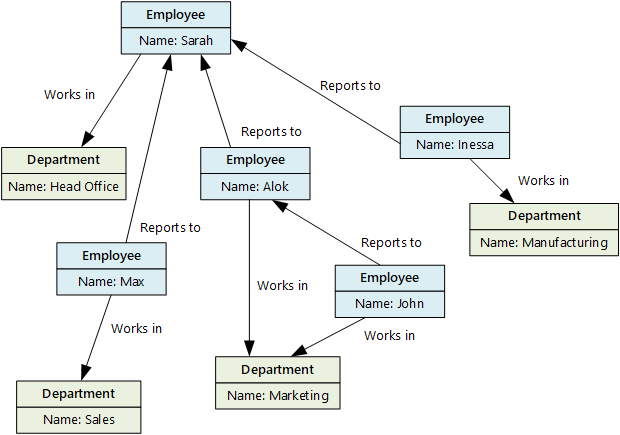
Tato struktura usnadňuje provádění dotazů, jako je například "Najít všechny zaměstnance, kteří přímo nebo nepřímo hlásí Sarah" nebo "Kdo pracuje ve stejném oddělení jako John?". U rozsáhlých grafů s mnoha entitami a relacemi můžete rychle provádět složité analýzy. Mnoho databází grafu poskytuje dotazovací jazyk, který slouží k efektivnímu procházení síťových relací.
Relevantní služba Azure:
Úložiště dat časových řad
Data časových řad jsou sada hodnot uspořádaných podle času a úložiště dat časových řad je optimalizované pro tento typ dat. Úložiště dat časových řad musí podporovat velmi vysoký počet zápisů, protože obvykle shromažďují velké objemy dat v reálném čase z velkého počtu zdrojů. Úložiště dat časových řad jsou optimalizovaná pro ukládání telemetrických dat. Scénáře zahrnují senzory IoT nebo čítače aplikací či systémů. Aktualizace jsou vzácné a odstraňování se často provádí jako hromadná operace.
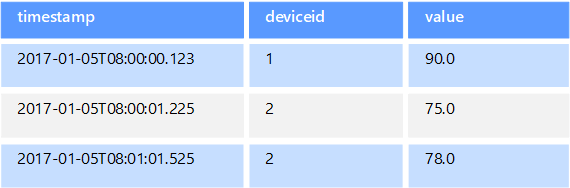
I když jsou záznamy zapisované do databáze s časovou řadou obecně malé, často jde o velký počet záznamů a celková velikost dat může rychle narůst. Úložiště dat časových řad také zpracovávají data mimo pořadí a pozdní příchod dat, automatické indexování datových bodů a optimalizace dotazů popsaných v časových oknech. Tato poslední funkce umožňuje rychle spouštět dotazy napříč miliony datových bodů a více datových proudů, aby podporovaly vizualizace časových řad, což je běžný způsob využívání dat časových řad.
Relevantní služby Azure:
Úložiště dat objektů
Úložiště dat objektů jsou optimalizovaná pro ukládání a načítání velkých binárních objektů nebo objektů blob, jako jsou obrázky, textové soubory, video a zvukové streamy, velké datové objekty aplikací a dokumenty a image disků virtuálního počítače. Objekt se skládá z uložených dat, některých metadat a jedinečného ID pro přístup k objektu. Úložiště objektů jsou navržena tak, aby podporovala soubory, které jsou jednotlivě velmi velké, a poskytují velké objemy celkového úložiště pro správu všech souborů.
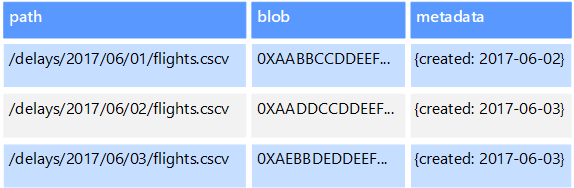
Některá úložiště dat objektů replikují daný objekt blob napříč několika uzly serveru, což umožňuje rychlé paralelní čtení. Tento proces zase umožňuje dotazování na data obsažená ve velkých souborech se škálováním na více instancí, protože více procesů, které obvykle běží na různých serverech, může každý dotazovat velký datový soubor současně.
Jedním ze speciálních případů úložišť dat objektů je síťová sdílená složka. Použití sdílených složek umožňuje přístup k souborům v síti pomocí standardních síťových protokolů, jako je serverový blok zpráv (SMB). Díky příslušným mechanismům zabezpečení a souběžného řízení přístupu může sdílení dat tímto způsobem umožnit distribuovaným službám poskytovat vysoce škálovatelný přístup k datům pro základní operace nízké úrovně, jako jsou jednoduché požadavky na čtení a zápis.
Relevantní služby Azure:
Úložiště dat externího indexu
Úložiště dat externího indexu poskytují možnost vyhledávat informace uložené v jiných úložištích dat a službách. Externí index funguje jako sekundární index pro jakékoli úložiště dat a dá se použít k indexování obrovských objemů dat a poskytnout téměř v reálném čase přístup k těmto indexům.
Můžete mít například textové soubory uložené v systému souborů. Vyhledání souboru cestou k souboru je rychlé, ale vyhledávání na základě obsahu souboru by vyžadovalo prohledávání všech souborů, což je pomalé. Externí index umožňuje vytvořit sekundární indexy vyhledávání a pak rychle najít cestu k souborům, které odpovídají vašim kritériím. Dalším příkladem použití externího indexu je úložiště klíč/hodnota, která indexuje pouze klíč. Můžete vytvořit sekundární index založený na hodnotách v datech a rychle vyhledat klíč, který jednoznačně identifikuje každou shodnou položku.
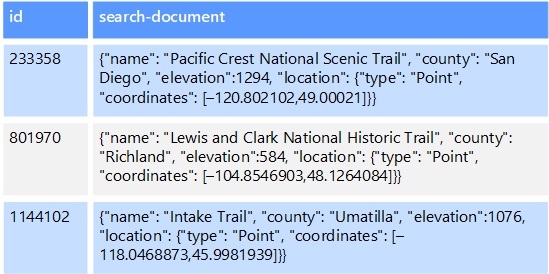
Indexy se vytvářejí spuštěním procesu indexování. To se dá provést pomocí modelu vyžádání obsahu, aktivovaného úložištěm dat nebo pomocí modelu nabízení iniciovaného kódem aplikace. Indexy můžou být multidimenzionální a můžou podporovat vyhledávání volného textu ve velkých objemech textových dat.
Úložiště dat externího indexu se často používají k podpoře fulltextového a webového vyhledávání. V těchto případech může být vyhledávání přesné nebo přibližné. Přibližné vyhledávání vyhledá dokumenty, které splňují sadu podmínek, a vypočítá, jak jsou blízké. Některé externí indexy také podporují lingvistické analýzy, které můžou vracet shody na základě synonym, rozšíření žánrů (například párování "psi" až "domácí zvířata") a ztěžování (například hledání výrazu "run" také odpovídá slovu "run" a "running").
Relevantní služba Azure:
Typické požadavky
Nerelační úložiště dat často používají jinou architekturu úložiště, než kterou používají relační databáze. Konkrétně mají tendenci mít žádné pevné schéma. Také obvykle nepodporují transakce nebo jinak omezují rozsah transakcí a obvykle nezahrnují sekundární indexy z důvodů škálovatelnosti.
V porovnání s mnoha tradičními relačními databázemi nabízejí databáze NoSQL často žádoucí úroveň flexibility schématu a škálovatelnosti platformy, ale někdy tyto výhody mají náklady na slabší konzistenci. I když můžete data flexibilně ukládat, stále potřebujete identifikovat a analyzovat vzory přístupu k datům a pak navrhnout vhodné schéma dat, jinak může databáze NoSQL trpět náročnými úlohami nebo neočekávanými vzory použití.
Následující informace porovnávají požadavky pro každé nerelační úložiště dat:
| Požadavek | Data dokumentu | Data rodiny sloupců | Data klíče a hodnoty | Data grafu |
|---|---|---|---|---|
| Normalizace | Denormalizované | Denormalizované | Denormalizované | Normalizovaný |
| Schéma | Schéma při čtení | Rodiny sloupců definované při zápisu, schéma sloupců při čtení | Schéma při čtení | Schéma při čtení |
| Konzistence (napříč souběžnými transakcemi) | Vyladěná konzistence, záruky na úrovni dokumentu | Záruky na úrovni rodiny sloupců | Záruky na úrovni klíčů | Záruky na úrovni grafu |
| Atomicita (obor transakce) | Kolekce | Table | Table | Graf |
| Strategie uzamykání | Optimistická (bez zámku) | Pesimistické (zámky řádků) | Optimistická (značka entity (ETag)) | |
| Vzor přístupu | Přímý přístup | Agregace na vysokých a širokých datech | Přímý přístup | Přímý přístup |
| Indexování | Primární a sekundární indexy | Primární a sekundární indexy | Pouze primární index | Primární a sekundární indexy |
| Obrazec dat | Dokument | Tabulkové s rodinami sloupců obsahujícími sloupce | Klíč a hodnota | Graf obsahující hrany a vrcholy |
| Řídké | Ano | Ano | Ano | No |
| Široké (velké množství sloupců/atributů) | Ano | Ano | No | Ne |
| Velikost datumu | Malé (KB) až střední (malé MB) | Střední (MB) až Velké (nízké gb) | Malé (KB) | Malé (KB) |
| Celkové maximální měřítko | Velmi velké (databáze) | Velmi velké (databáze) | Velmi velké (databáze) | Velké (TB) |
| Požadavek | Data časových řad | Data objektu | Data externího indexu |
|---|---|---|---|
| Normalizace | Normalizovaný | Denormalizované | Denormalizované |
| Schéma | Schéma při čtení | Schéma při čtení | Schéma při zápisu |
| Konzistence (napříč souběžnými transakcemi) | – | – | N/A |
| Atomicita (obor transakce) | – | Object | – |
| Strategie uzamykání | – | Pesimistické (zámky objektů blob) | – |
| Vzor přístupu | Náhodný přístup a agregace | Sekvenční přístup | Přímý přístup |
| Indexování | Primární a sekundární indexy | Pouze primární index | – |
| Obrazec dat | Tabelární | Objekt blob a metadata | Dokument |
| Řídké | No | – | No |
| Široké (velké množství sloupců/atributů) | No | Ano | Yes |
| Velikost datumu | Malé (KB) | Velké (GB) na velmi velké (TB) | Malé (KB) |
| Celkové maximální měřítko | Velké (nízké počet tb) | Velmi velké (databáze) | Velké (nízké počet tb) |
Přispěvatelé
Tento článek spravuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autor:
- Zoiner Tejada | Generální ředitel a architekt
Další kroky
- Relační vs. data NoSQL
- Principy distribuovaných databází NoSQL
- Základy dat Microsoft Azure: Prozkoumání nerelačních dat v Azure
- Implementace nerelačního datového modelu