Extrakce, transformace a načítání (ETL)
Běžným problémem, kterému organizace čelí, je způsob shromažďování dat z více zdrojů ve více formátech. Pak byste ho museli přesunout do jednoho nebo více úložišť dat. Cílem nemusí být stejný typ úložiště dat jako zdroj. Formát se často liší nebo je potřeba data před načtením do konečného cíle tvarovat nebo vyčistit.
V průběhu let byly vyvinuty různé nástroje, služby a procesy, které pomáhají tyto výzvy řešit. Bez ohledu na použitý proces je potřeba koordinaci práce a použití určité úrovně transformace dat v rámci datového kanálu. Následující části zvýrazňují běžné metody používané k provádění těchto úloh.
Extrakce, transformace, načítání (ETL)
extrakce, transformace, načítání (ETL) je datový kanál, který slouží ke shromažďování dat z různých zdrojů. Pak transformuje data podle obchodních pravidel a načte data do cílového úložiště dat. Práce transformace v ETL probíhá ve specializovaném modulu a často zahrnuje použití pracovních tabulek k dočasnému uložení dat při jejich transformaci a nakonec načtení do cíle.
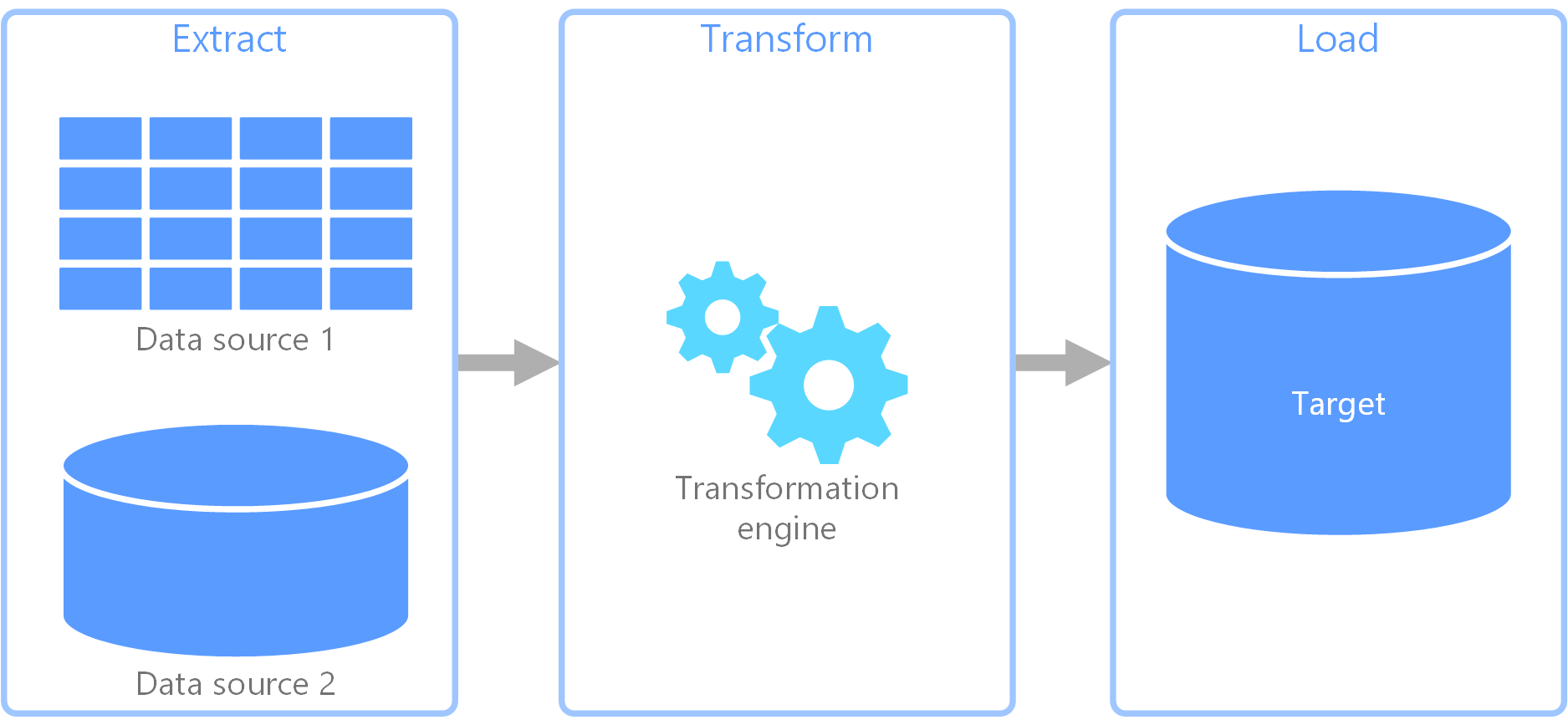
Transformace dat, která probíhá, obvykle zahrnuje různé operace, jako je filtrování, řazení, agregace, spojování dat, čištění dat, odstranění duplicitních dat a ověřování dat.
Tři fáze ETL se často spouští paralelně, aby se ušetřil čas. Například když se data extrahují, proces transformace může pracovat na datech, která jsou už přijatá, a připravit je na načtení a proces načítání může začít pracovat na připravených datech, a nečekal na dokončení celého procesu extrakce.
Relevantní služba Azure:
Další nástroje:
Extrakce, načtení, transformace (ELT)
Extrakce, načtení, transformace (ELT) se liší od ETL pouze v místě, kde probíhá transformace. V kanálu ELT probíhá transformace v cílovém úložišti dat. Místo použití samostatného transformačního modulu se možnosti zpracování cílového úložiště dat používají k transformaci dat. Tím se architektura zjednodušuje odebráním transformačního modulu z kanálu. Další výhodou tohoto přístupu je, že škálování cílového úložiště dat také škáluje výkon kanálu ELT. ELT ale funguje dobře jenom v případě, že je cílový systém dostatečně výkonný, aby efektivně transformoval data.
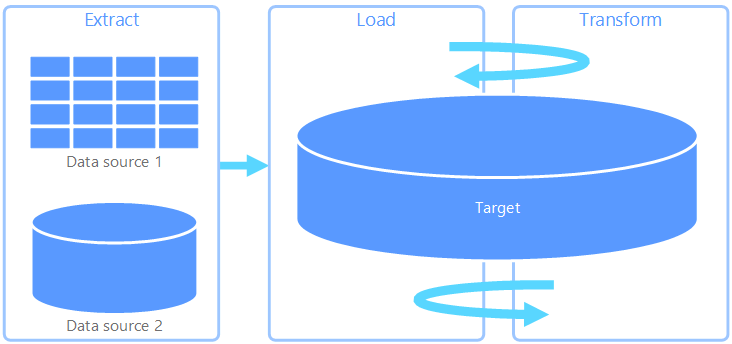
Typické případy použití ELT spadají do sféry velkých objemů dat. Můžete například začít extrahováním všech zdrojových dat do plochých souborů ve škálovatelném úložišti, jako je hadoop Distributed File System, úložiště objektů blob Azure nebo Azure Data Lake Gen2 (nebo kombinace). Technologie, jako je Spark, Hive nebo PolyBase, se pak dají použít k dotazování zdrojových dat. Klíčovým bodem elT je, že úložiště dat použité k provedení transformace je stejné úložiště dat, ve kterém se data nakonec spotřebovávají. Toto úložiště dat čte přímo ze škálovatelného úložiště místo načítání dat do vlastního proprietárního úložiště. Tento přístup přeskočí krok kopírování dat, který se nachází v ETL, což často může být časově náročná operace pro velké datové sady.
V praxi je cílové úložiště dat datový sklad pomocí clusteru Hadoop (pomocí Hive nebo Sparku) nebo vyhrazeného fondu SQL ve službě Azure Synapse Analytics. Obecně platí, že schéma se překryje na plochá data souboru v době dotazu a uloží se jako tabulka, což umožňuje dotazování dat jako jakékoli jiné tabulky v úložišti dat. Tyto tabulky se označují jako externí tabulky, protože data nejsou uložená v úložišti spravovaném samotným úložištěm dat, ale v některých externích škálovatelných úložištích, jako je Azure Data Lake Store nebo Azure Blob Storage.
Úložiště dat spravuje pouze schéma dat a použije schéma při čtení. Například cluster Hadoop používající Hive by popsal tabulku Hive, ve které je zdrojem dat efektivně cesta k sadě souborů v HDFS. Ve službě Azure Synapse může PolyBase dosáhnout stejného výsledku – vytvoření tabulky s daty uloženými externě do samotné databáze. Po načtení zdrojových dat je možné data v externích tabulkách zpracovat pomocí funkcí úložiště dat. Ve scénářích s velkými objemy dat to znamená, že úložiště dat musí být schopné masivně paralelního zpracování (MPP), které rozdělí data do menších bloků dat a rozdělí zpracování bloků dat paralelně mezi několik uzlů.
Poslední fází kanálu ELT je obvykle transformace zdrojových dat do konečného formátu, který je efektivnější pro typy dotazů, které je potřeba podporovat. Data mohou být například rozdělena na oddíly. ELT může také používat optimalizované formáty úložiště, jako je Parquet, které ukládají data zaměřená na řádky sloupcovým způsobem a poskytuje optimalizované indexování.
Relevantní služba Azure:
- Vyhrazené fondy SQL ve službě Azure Synapse Analytics
- Bezserverové fondy SQL ve službě Azure Synapse Analytics
- HDInsight s Hivem
- Azure Data Factory
- Datové diagramy v Power BI
Další nástroje:
Tok dat a tok řízení
V kontextu datových kanálů tok řízení zajišťuje uspořádané zpracování sady úloh. K vynucení správného pořadí zpracování těchto úloh se použijí omezení priority. Tato omezení si můžete představit jako spojnice v diagramu pracovního postupu, jak je znázorněno na obrázku níže. Každý úkol má výsledek, například úspěch, selhání nebo dokončení. Jakýkoli následný úkol neskončuje zpracování, dokud se jeho předchůdce nedokončil s jedním z těchto výsledků.
Toky řízení spouštějí toky dat jako úkol. V úloze toku dat se data extrahují ze zdroje, transformují nebo načítají do úložiště dat. Výstupem jedné úlohy toku dat může být vstup do další úlohy toku dat a toky dat se můžou spouštět paralelně. Na rozdíl od řídicích toků nemůžete mezi úkoly v toku dat přidávat omezení. Můžete ale přidat prohlížeč dat, který bude sledovat data při jejich zpracování jednotlivými úlohami.
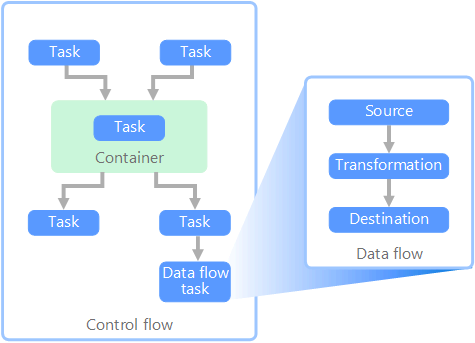
Ve výše uvedeném diagramu je v toku řízení několik úloh, z nichž jedním je úloha toku dat. Jeden z úkolů je vnořený do kontejneru. Kontejnery lze použít k poskytování struktury úkolů a poskytování jednotky práce. Jedním z takových příkladů je opakování prvků v kolekci, jako jsou soubory ve složce nebo příkazy databáze.
Relevantní služba Azure:
Další nástroje:
Technologické volby
- Úložiště dat OLTP (Online Transaction Processing)
- Úložiště dat OLAP (Online Analytical Processing)
- Datové sklady
- Orchestrace kanálů
Další kroky
- Integrace dat se službou Azure Data Factory nebo kanálem Azure Synapse
- Úvod do Azure Synapse Analytics
- Orchestrace přesunu a transformace dat ve službě Azure Data Factory nebo kanálu Azure Synapse
Související prostředky
Následující referenční architektury ukazují kompletní kanály ELT v Azure: