Tento ukázkový scénář ukazuje, jak se dají data ingestovat do cloudového prostředí z místního datového skladu a pak obsluhovat pomocí modelu business intelligence (BI). Tento přístup může být konečným cílem nebo prvním krokem k úplné modernizaci s cloudovými komponentami.
Následující kroky vycházejí z kompletního scénáře Azure Synapse Analytics. Používá Azure Pipelines k ingestování dat z databáze SQL do fondů Azure Synapse SQL a pak transformuje data pro účely analýzy.
Architektura

Stáhněte si soubor aplikace Visio s touto architekturou.
Workflow
Zdroj dat
- Zdrojová data se nacházejí v databázi SQL Serveru v Azure. Pro simulaci místního prostředí zřizují skripty nasazení pro tento scénář databázi Azure SQL. Ukázková databáze AdventureWorks se používá jako schéma zdrojových dat a ukázková data. Informace o kopírování dat z místní databáze najdete v tématu kopírování a transformace dat do a z SQL Serveru.
Příjem dat a úložiště dat
Azure Data Lake Gen2 se během příjmu dat používá jako dočasná pracovní oblast. PolyBase pak můžete použít ke kopírování dat do vyhrazeného fondu SQL Azure Synapse.
Azure Synapse Analytics je distribuovaný systém navržený k provádění analýz velkých objemů dat. Podporuje výkonné paralelní zpracování umožňující provádět vysoce výkonné analýzy. Vyhrazený fond SQL Azure Synapse je cílem průběžného příjmu dat z místního prostředí. Dá se použít k dalšímu zpracování a k poskytování dat pro Power BI prostřednictvím DirectQuery.
Azure Pipelines se používá k orchestraci příjmu a transformace dat v rámci pracovního prostoru Azure Synapse.
Analýza a vytváření sestav
- Přístup k modelování dat v tomto scénáři je prezentován kombinací podnikového modelu a sémantického modelu BI. Podnikový model je uložený ve vyhrazeném fondu SQL Azure Synapse a sémantický model BI je uložený v kapacitách Power BI Premium. Power BI přistupuje k datům prostřednictvím DirectQuery.
Komponenty
Tento scénář používá následující komponenty:
Zjednodušená architektura
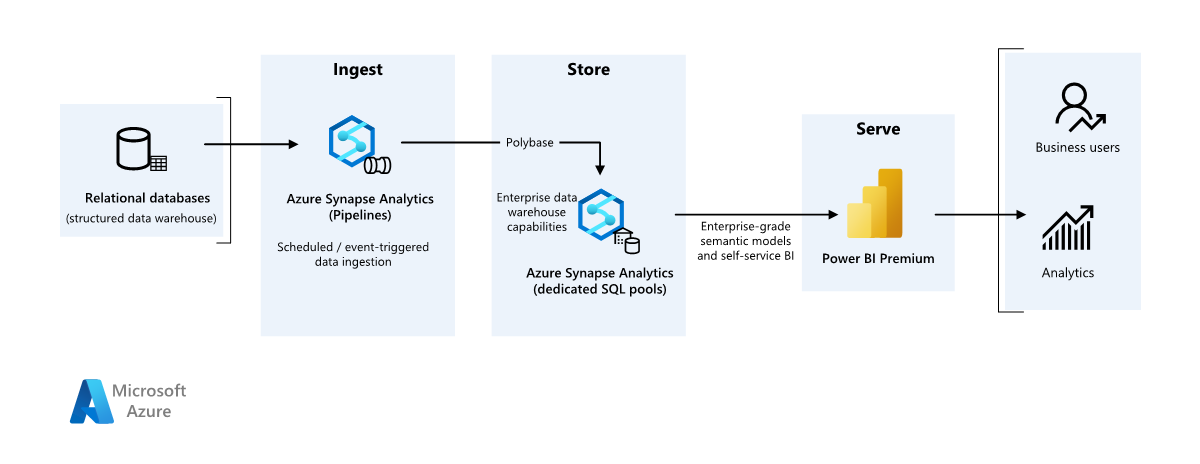
Podrobnosti scénáře
Organizace má velký místní datový sklad uložený v databázi SQL. Organizace chce k provádění analýzy použít Azure Synapse a pak tyto přehledy obsluhovat pomocí Power BI.
Ověřování
Microsoft Entra ověřuje uživatele, kteří se připojují k řídicím panelům a aplikacím Power BI. Jednotné přihlašování se používá k připojení ke zdroji dat ve zřízeném fondu Azure Synapse. Autorizace probíhá ve zdroji.
Přírůstkové načítání
Při spuštění automatizovaného procesu extrakce, transformace, načítání (ETL) nebo extrakce, načítání, transformace (ELT) je nejúčinnější načíst pouze data, která se změnila od předchozího spuštění. Označuje se jako přírůstkové načtení, na rozdíl od úplného načtení, které načte všechna data. Pokud chcete provést přírůstkové načítání, potřebujete způsob, jak zjistit, která data se změnila. Nejběžnějším přístupem je použití hodnoty horní značky, která sleduje nejnovější hodnotu některého sloupce ve zdrojové tabulce, a to buď sloupec datetime, nebo jedinečný celočíselnou sloupec.
Od SQL Serveru 2016 můžete použít dočasné tabulky, což jsou tabulky se systémovou verzí, které udržují úplnou historii změn dat. Databázový stroj automaticky zaznamenává historii každé změny v samostatné tabulce historie. Historická data můžete dotazovat přidáním FOR SYSTEM_TIME klauzule do dotazu. Databázový stroj interně dotazuje tabulku historie, ale pro aplikaci je transparentní.
Poznámka:
Pro starší verze SQL Serveru můžete použít funkci change data capture (CDC). Tento přístup je méně pohodlný než dočasné tabulky, protože musíte dotazovat samostatnou tabulku změn a změny se sledují pořadovým číslem protokolu, nikoli časovým razítkem.
Dočasné tabulky jsou užitečné pro data dimenzí, která se můžou v průběhu času měnit. Tabulky faktů obvykle představují neměnnou transakci, jako je prodej, v takovém případě zachování historie systémových verzí nedává smysl. Místo toho transakce obvykle mají sloupec, který představuje datum transakce, které lze použít jako hodnotu meze. Například v datovém skladu SalesLT.* AdventureWorks mají LastModified tabulky pole.
Tady je obecný tok kanálu ELT:
Pro každou tabulku ve zdrojové databázi sledujte čas ukončení poslední úlohy ELT. Tyto informace uložte do datového skladu. Při počátečním nastavení jsou všechny časy nastaveny na
1-1-1900.Během kroku exportu dat se jako parametr předává sada uložených procedur ve zdrojové databázi jako parametr. Tyto uložené procedury se dotazují na všechny záznamy, které byly změněny nebo vytvořeny po době odříznutí. Pro všechny tabulky v příkladu můžete použít
ModifiedDatesloupec.Po dokončení migrace dat aktualizujte tabulku, ve které jsou uloženy časy ukončení.
Datový kanál
Tento scénář používá ukázkovou databázi AdventureWorks jako zdroj dat. Model přírůstkového načítání dat se implementuje, abychom zajistili, že načítáme jenom data upravená nebo přidaná po posledním spuštění kanálu.
Nástroj pro kopírování řízený metadaty
Integrovaný nástroj pro kopírování řízený metadaty ve službě Azure Pipelines přírůstkově načte všechny tabulky obsažené v naší relační databázi. Procházením prostředí založeného na průvodci můžete nástroj pro kopírování dat připojit ke zdrojové databázi a nakonfigurovat přírůstkové nebo úplné načítání pro každou tabulku. Nástroj Pro kopírování dat pak vytvoří kanály i skripty SQL, které vygenerují řídicí tabulku potřebnou k ukládání dat pro proces přírůstkového načítání – například hodnota a sloupec s vysokým vodoznakem pro každou tabulku. Po spuštění těchto skriptů je kanál připravený načíst všechny tabulky ve zdrojovém datovém skladu do vyhrazeného fondu Synapse.
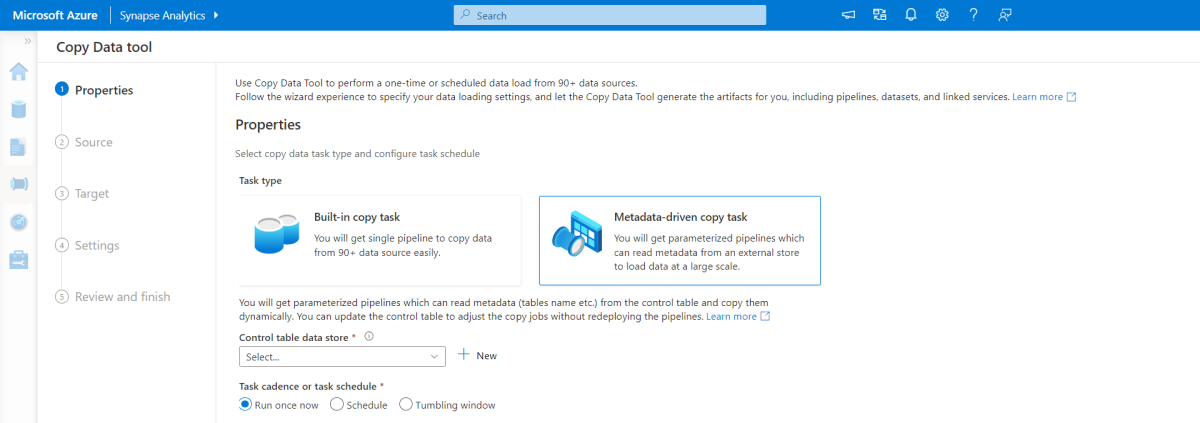
Nástroj vytvoří tři kanály, které před načtením dat iterují všechny tabulky v databázi.
Kanály vygenerované tímto nástrojem:
- Spočítejte počet objektů, jako jsou tabulky, které se mají zkopírovat do spuštění kanálu.
- Iterujte přes každý objekt, který se má načíst nebo zkopírovat, a pak:
- Zkontrolujte, zda je vyžadováno rozdílové zatížení; v opačném případě dokončete normální úplné zatížení.
- Načtěte hodnotu horní meze z řídicí tabulky.
- Zkopírujte data ze zdrojových tabulek do přípravného účtu v ADLS Gen2.
- Načtěte data do vyhrazeného fondu SQL prostřednictvím vybrané metody kopírování – například Příkaz Polybase, Copy.
- Aktualizujte hodnotu horní meze v řídicí tabulce.
Načtení dat do fondu Azure Synapse SQL
Aktivita kopírování kopíruje data z databáze SQL do fondu Azure Synapse SQL. V tomto příkladu, protože naše databáze SQL je v Azure, používáme prostředí Azure Integration Runtime ke čtení dat z databáze SQL a zápisu dat do zadaného přípravného prostředí.
Příkaz copy se pak použije k načtení dat z přípravného prostředí do vyhrazeného fondu Synapse.
Použití Azure Pipelines
Kanály ve službě Azure Synapse slouží k definování seřazené sady aktivit pro dokončení vzoru přírůstkového zatížení. Triggery se používají ke spuštění kanálu, který se dá aktivovat ručně nebo v zadaném čase.
Transformace dat
Vzhledem k tomu, že ukázková databáze v naší referenční architektuře není velká, vytvořili jsme replikované tabulky bez oddílů. U produkčních úloh bude použití distribuovaných tabulek pravděpodobně zlepšit výkon dotazů. Pokyny k návrhu distribuovaných tabulek v Azure Synapse Ukázkové skripty spouštějí dotazy pomocí třídy statických prostředků.
V produkčním prostředí zvažte vytvoření pracovních tabulek s rozdělením kruhového dotazování. Pak transformujte a přesuňte data do produkčních tabulek s clusterovanými indexy columnstore, které nabízejí nejlepší celkový výkon dotazů. Indexy columnstore jsou optimalizované pro dotazy, které prohledávají mnoho záznamů. Indexy columnstore nefungují stejně jako u jednoúčelových vyhledávání, tj. vyhledávání jednoho řádku. Pokud potřebujete provádět časté vyhledávání s jednímtonem, můžete do tabulky přidat neskupený index. Jednoúčelové vyhledávání může běžet mnohem rychleji pomocí neskupovaného indexu. Jednoúčelové vyhledávání jsou ale obvykle méně časté ve scénářích datového skladu než úlohy OLTP. Další informace najdete v tématu Indexování tabulek v Azure Synapse.
Poznámka:
Clusterované tabulky columnstore nepodporují varchar(max), nvarchar(max)ani varbinary(max) datové typy. V takovém případě zvažte haldu nebo clusterovaný index. Tyto sloupce můžete umístit do samostatné tabulky.
Použití Power BI Premium pro přístup k datům, modelování a vizualizaci dat
Power BI Premium podporuje několik možností připojení ke zdrojům dat v Azure, zejména zřízený fond Azure Synapse:
- Import: Data se naimportují do modelu Power BI.
- DirectQuery: Data se natahují přímo z relačního úložiště.
- Složený model: Kombinování importu pro některé tabulky a DirectQuery pro jiné.
Tento scénář se dodává s řídicím panelem DirectQuery, protože množství využitých dat a složitost modelu nejsou vysoké, takže můžeme zajistit dobré uživatelské prostředí. DirectQuery deleguje dotaz na výkonný výpočetní modul pod ním a využívá rozsáhlé možnosti zabezpečení ve zdroji. Použití DirectQuery také zajišťuje, že výsledky budou vždy konzistentní s nejnovějšími zdrojovými daty.
Režim importu poskytuje nejrychlejší dobu odezvy dotazu a měl by se zvážit, když model zapadá zcela do paměti Power BI, latence dat mezi aktualizacemi může být tolerována a mezi zdrojovým systémem a konečným modelem můžou být některé složité transformace. V tomto případě chtějí koncoví uživatelé úplný přístup k nejnovějším datům bez zpoždění při aktualizaci Power BI a všechna historická data, která jsou větší než to, co může datová sada Power BI zpracovávat – v závislosti na velikosti kapacity 25 až 400 GB. Vzhledem k tomu, že datový model ve vyhrazeném fondu SQL už je ve hvězdicovém schématu a nepotřebuje žádnou transformaci, je DirectQuery vhodnou volbou.
Power BI Premium Gen2 umožňuje zpracovávat velké modely, stránkované sestavy, kanály nasazení a integrovaný koncový bod Analysis Services. Vyhrazenou kapacitu můžete mít také s jedinečnou hodnotou.
Když se model BI zvětšuje nebo zvyšuje složitost řídicího panelu, můžete přepnout na složené modely a začít importovat části vyhledávacích tabulek, prostřednictvím hybridních tabulek a některých předem agregovaných dat. Povolení ukládání dotazů do mezipaměti v Power BI pro importované datové sady je možnost a také využití duálních tabulek pro vlastnost režimu úložiště.
V rámci složeného modelu fungují datové sady jako virtuální průchozí vrstva. Když uživatel pracuje s vizualizacemi, Power BI vygeneruje dotazy SQL do fondů Synapse SQL duální úložiště: v paměti nebo přímém dotazu v závislosti na tom, která z nich je efektivnější. Modul se rozhodne, kdy přepnout z paměti na přímý dotaz a odešle logiku do fondu Synapse SQL. V závislosti na kontextu tabulek dotazů můžou fungovat jako složené modely uložené v mezipaměti (importované) nebo ne. Vyberte a zvolte, která tabulka se má ukládat do mezipaměti, kombinovat data z jednoho nebo více zdrojů DirectQuery a/nebo kombinovat data z kombinace zdrojů DirectQuery a importovaných dat.
Doporučení: Při použití DirectQuery přes zřízený fond Azure Synapse Analytics:
- Ukládání výsledků sady výsledků Azure Synapse do mezipaměti slouží k ukládání výsledků dotazů do mezipaměti v uživatelské databázi pro opakované použití, zlepšení výkonu dotazů až po milisekundy a snížení využití výpočetních prostředků. Dotazy využívající sady výsledků v mezipaměti nepoužívají žádné sloty souběžnosti ve službě Azure Synapse Analytics, a proto se nezapočítávají do stávajících limitů souběžnosti.
- Pomocí materializovaných zobrazení Azure Synapse můžete předpočítat, ukládat a udržovat data stejně jako tabulka. Dotazy, které používají všechna data nebo podmnožinu dat v materializovaných zobrazeních, můžou dosáhnout vyššího výkonu a nemusí přímo odkazovat na definované materializované zobrazení, aby je bylo možné použít.
Důležité informace
Tyto aspekty implementují pilíře dobře architektuře Azure, což je sada hlavních principů, které je možné použít ke zlepšení kvality úlohy. Další informace naleznete v tématu Microsoft Azure Well-Architected Framework.
Zabezpečení
Zabezpečení poskytuje záruky proti záměrným útokům a zneužití cenných dat a systémů. Další informace najdete v tématu Přehled pilíře zabezpečení.
Společnosti, které se zajímají o modernizaci cloudu, znepokojuje spousta věcí, mimo jiné časté titulky o únicích dat, malwarových útocích a injektáži škodlivého kódu. Podnikoví zákazníci potřebují cloudového poskytovatele nebo řešení služeb, které můžou řešit své obavy, protože si nemůžou dovolit, aby se něco pokazilo.
Tento scénář se zabývá nejnáročnějšími aspekty zabezpečení pomocí kombinace vícevrstvých kontrolních mechanismů zabezpečení: sítě, identity, ochrany osobních údajů a autorizace. Hromadná data se ukládají ve zřízeném fondu Azure Synapse s Power BI pomocí DirectQuery prostřednictvím jednotného přihlašování. K ověřování můžete použít ID Microsoft Entra. Existují také rozsáhlé bezpečnostní prvky pro autorizaci dat zřízených fondů.
Mezi běžné otázky týkající se zabezpečení patří:
- Jak budu moct určovat, kdo uvidí jaká data?
- Organizace musí chránit svá data, aby dodržovaly federální, místní a firemní pokyny, aby se zmírnit rizika porušení zabezpečení dat. Azure Synapse nabízí několik možností ochrany dat pro dosažení dodržování předpisů.
- Jaké budu mít možnosti pro ověření identity uživatele?
- Jakou technologii zabezpečení sítě budu moct používat k ochraně integrity, důvěrnosti a přístupu k sítím a datům?
- K zabezpečení Azure Synapse existuje řada možností zabezpečení sítě, které je možné zvážit.
- Které nástroje budou detekovat hrozby a upozorňují mě na ně?
- Azure Synapse nabízí celou řadu možností detekce hrozeb, jako jsou auditování SQL, detekce hrozeb SQL a posouzení ohrožení zabezpečení, které umožňují auditovat, chránit a monitorovat databáze.
- Co můžu udělat pro ochranu dat v účtu úložiště?
Optimalizace nákladů
Optimalizace nákladů se zabývá způsoby, jak snížit zbytečné výdaje a zlepšit efektivitu provozu. Další informace najdete v tématu Přehled pilíře optimalizace nákladů.
Tato část obsahuje informace o cenách různých služeb, které jsou součástí tohoto řešení, a uvádí rozhodnutí učiněná pro tento scénář pomocí ukázkové datové sady.
Azure Synapse
Bezserverová architektura Azure Synapse Analytics umožňuje nezávisle škálovat úrovně výpočetních prostředků a úložiště. Výpočetní prostředky se účtují na základě využití a tyto prostředky můžete škálovat nebo pozastavit na vyžádání. Prostředky úložiště se účtují na terabajt, takže se vaše náklady zvýší, jakmile ingestujete další data.
Azure Pipelines
Podrobnosti o cenách kanálů ve službě Azure Synapse najdete na kartě Integrace Dat na stránce s cenami služby Azure Synapse. Existují tři hlavní komponenty, které ovlivňují cenu kanálu:
- Aktivity datového kanálu a hodiny modulu runtime integrace
- Velikost a spuštění clusteru toků dat
- Poplatky za operaci
Cena se liší v závislosti na komponentách nebo aktivitách, frekvenci a počtu jednotek prostředí Integration Runtime.
Pro ukázkovou datovou sadu se standardní prostředí Integration Runtime hostované v Azure, aktivita kopírování dat pro jádro kanálu aktivuje denním plánem pro všechny entity (tabulky) ve zdrojové databázi. Scénář neobsahuje žádné toky dat. Neexistují žádné provozní náklady, protože každý měsíc existují méně než 1 milion operací s kanály.
Vyhrazený fond a úložiště Azure Synapse
Podrobnosti o cenách vyhrazeného fondu Azure Synapse najdete na kartě Skladování Dat na stránce s cenami služby Azure Synapse. V rámci modelu Dedicated Consumption se zákazníkům účtují jednotky datového skladu (DWU) zřízené za hodinu doby provozu. Dalším faktorem, který přispívá k ukládání dat, jsou náklady na úložiště dat: velikost neaktivních uložených dat + snímky + geografická redundance, pokud existuje.
Pro ukázkovou datovou sadu můžete zřídit 500DWU, což zaručuje dobré prostředí pro analytické zatížení. Můžete udržovat výpočetní prostředky v provozu po celou pracovní dobu vytváření sestav. Při vstupu do produkčního prostředí je rezervovaná kapacita datového skladu atraktivní možností pro správu nákladů. Různé techniky by se měly použít k maximalizaci metrik nákladů a výkonu, které jsou popsány v předchozích částech.
Blob Storage
Pokud chcete snížit náklady na úložiště, zvažte použití funkce rezervované kapacity služby Azure Storage. S tímto modelem získáte slevu, pokud si rezervujete pevnou kapacitu úložiště na jeden nebo tři roky. Další informace najdete v tématu Optimalizace nákladů na úložiště objektů blob s rezervovanou kapacitou.
V tomto scénáři neexistuje žádné trvalé úložiště.
Power BI Premium
Podrobnosti o cenách Power BI Premium najdete na stránce s cenami Power BI.
Tento scénář používá pracovní prostory Power BI Premium s řadou vylepšení výkonu, která jsou integrovaná tak, aby vyhovovala náročným analytickým potřebám.
Provozní dokonalost
Efektivita provozu zahrnuje provozní procesy, které nasazují aplikaci a udržují ji spuštěnou v produkčním prostředí. Další informace najdete v tématu Přehled pilíře efektivity provozu.
Doporučení DevOps
Vytvořte samostatné skupiny prostředků pro produkční, vývojové a testovací prostředí. Samostatné skupiny prostředků usnadňují správu nasazení, odstraňování testovacích nasazení a přiřazování přístupových práv.
Každou úlohu umístěte do samostatné šablony nasazení a uložte prostředky do systémů správy zdrojového kódu. Šablony můžete nasadit společně nebo jednotlivě jako součást procesu kontinuální integrace a průběžného doručování (CI/CD), což usnadňuje proces automatizace. V této architektuře existují čtyři hlavní úlohy:
- Server datového skladu a související prostředky
- Kanály Azure Synapse
- Prostředky Power BI: řídicí panely, aplikace, datové sady
- Scénář simulovaný v místním prostředí do cloudu
Snažte se mít samostatnou šablonu nasazení pro každou úlohu.
Pokud je to praktické, zvažte přípravu úloh. Nasaďte je do různých fází a před přechodem na další fázi spusťte kontroly ověřování v každé fázi. Díky tomu můžete odesílat aktualizace do produkčních prostředí řízeným způsobem a minimalizovat neočekávané problémy s nasazením. Pro aktualizaci živých produkčních prostředí používejte modré a zelené nasazení a strategie kanárských verzí .
Máte dobrou strategii vrácení zpět pro zpracování neúspěšných nasazení. Můžete například automaticky nasadit dřívější úspěšné nasazení z historie nasazení. Podívejte se na
--rollback-on-errorpříznak v Azure CLI.Azure Monitor je doporučená možnost analýzy výkonu datového skladu a celé analytické platformy Azure pro integrované prostředí monitorování. Azure Synapse Analytics poskytuje prostředí pro monitorování na webu Azure Portal, které vám umožní zobrazit přehledy o úloze datového skladu. Azure Portal je doporučeným nástrojem při monitorování datového skladu, protože poskytuje konfigurovatelná období uchovávání, upozornění, doporučení a přizpůsobitelné grafy a řídicí panely pro metriky a protokoly.
Rychlý start
- Portál: Testování konceptu Azure Synapse (POC)
- Azure CLI: Vytvoření pracovního prostoru Azure Synapse pomocí Azure CLI
- Terraform: Moderní datové sklady s Terraformem a Microsoft Azure
Efektivita výkonu
Efektivita výkonu je schopnost úlohy škálovat se tak, aby efektivním způsobem splňovala požadavky, které na ni kladou uživatelé. Další informace najdete v tématu Přehled pilíře efektivity výkonu.
Tato část obsahuje podrobnosti o rozhodnutích o velikosti pro přizpůsobení této datové sady.
Zřízený fond Azure Synapse
Existuje řada konfigurací datového skladu, ze které si můžete vybrat.
| Jednotky datového skladu | Počet výpočetních uzlů | # of distributions per node |
|---|---|---|
| DW100c | 1 | 60 |
-- TO -- |
||
| DW30000c | 60 | 0 |
Pokud chcete zobrazit výhody horizontálního navýšení kapacity výkonu, zejména u větších jednotek datového skladu, použijte aspoň datovou sadu o velikosti 1 TB. Pokud chcete najít nejlepší počet jednotek datového skladu pro vyhrazený fond SQL, zkuste vertikálně navýšit nebo snížit kapacitu. Po načtení dat spusťte několik dotazů s různými čísly jednotek datového skladu. Vzhledem k tomu, že škálování je rychlé, můžete vyzkoušet různé úrovně výkonu za hodinu nebo méně.
Vyhledání nejlepšího počtu jednotek datového skladu
Pro vyhrazený fond SQL ve vývoji začněte výběrem menšího počtu jednotek datového skladu. Dobrým výchozím bodem je DW400c nebo DW200c. Monitorujte výkon aplikace a sledujte počet vybraných jednotek datového skladu v porovnání s výkonem, který sledujete. Předpokládejme lineární měřítko a určete, kolik potřebujete zvýšit nebo snížit jednotky datového skladu. Pokračujte v úpravách, dokud nedosáhnete optimální úrovně výkonu pro vaše obchodní požadavky.
Škálování fondu Synapse SQL
- Škálování výpočetních prostředků pro fond Synapse SQL pomocí webu Azure Portal
- Škálování výpočetních prostředků pro vyhrazený fond SQL pomocí Azure PowerShellu
- Škálování výpočetních prostředků pro vyhrazený fond SQL ve službě Azure Synapse Analytics pomocí T-SQL
- Pozastavení, monitorování a automatizace
Azure Pipelines
Informace o škálovatelnosti a optimalizaci výkonu kanálů v Azure Synapse a použité aktivitě kopírování najdete v průvodci výkonem a škálovatelností aktivita Copy.
Power BI Premium
Tento článek používá Power BI Premium Gen2 k předvedení funkcí BI. Skladové položky kapacity pro Power BI Premium se v současné době liší od P1 (osm virtuálních jader) až po P5 (128 virtuálních jader). Nejlepší způsob, jak vybrat potřebnou kapacitu, je projít vyhodnocením načítání kapacity, nainstalovat aplikaci metrik Gen2 pro průběžné monitorování a zvážit použití automatického škálování s Power BI Premium.
Přispěvatelé
Tento článek spravuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autoři:
- Galina Polyakova | Vedoucí architekt cloudových řešení
- Noah Costar | Architekt cloudového řešení
- George Stevens | Architekt cloudového řešení
Další přispěvatelé:
- Jim McLeod | Architekt cloudového řešení
- Miguel Myers | Vedoucí programový manažer
Pokud chcete zobrazit neveřejné profily LinkedIn, přihlaste se na LinkedIn.
Další kroky
- Co je Power BI Premium?
- Co je MICROSOFT Entra ID?
- Přístup ke službě Azure Data Lake Storage Gen2 a Blob Storage pomocí Azure Databricks
- Co je Azure Synapse Analytics?
- Kanály a aktivity ve službě Azure Data Factory a Azure Synapse Analytics
- Co je Azure SQL?