Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento kurz vás provede vytvořením a spuštěním kanálu služby Azure Data Factory, který spouští úlohu Azure Batch. Skript Pythonu běží na uzlech Batch, který získá vstup hodnot oddělených čárkami (CSV) z kontejneru služby Azure Blob Storage, manipuluje s daty a zapíše výstup do jiného kontejneru úložiště. ** Pomocí Batch Exploreru vytvoříte fond Batch a uzly, a pomocí Průzkumník služby Azure Storageu můžete pracovat s úložištními kontejnery a soubory.
V tomto kurzu se naučíte:
- Pomocí Batch Exploreru vytvořte fond Batch a uzly.
- Pomocí Průzkumník služby Storage můžete vytvářet kontejnery úložiště a nahrávat vstupní soubory.
- Vyvíjejte skript Pythonu pro manipulaci se vstupními daty a vytváření výstupu.
- Vytvořte pipelinu služby Data Factory, která spouští dávkovou úlohu.
- Pomocí Batch Exploreru se podívejte na výstupní soubory protokolu.
Požadavky
- Účet Azure s aktivním předplatným. Pokud žádné nemáte, vytvořte si bezplatný účet.
- Účet Batch s propojeným účtem Azure Storage. Účty můžete vytvořit pomocí některé z následujících metod: Azure portal | Azure CLI | Bicep | ARM šablona | Terraform.
- Instanci služby Data Factory. Pokud chcete vytvořit datovou továrnu, postupujte podle pokynů v tématu Vytvoření datové továrny.
- Batch Explorer byl stažen a nainstalován.
- Průzkumník služby Storage byl stažen a nainstalován.
-
Python 3.8 nebo novější s balíčkem azure-storage-blob nainstalovaným pomocí
pip. - Vstupní datová sada iris.csv stažená z GitHubu.
Vytvoření fondu a uzlů služby Batch pomocí Batch Exploreru
Pomocí Batch Exploreru vytvořte fond výpočetních uzlů pro spuštění úlohy.
Přihlaste se k Batch Exploreru pomocí svých přihlašovacích údajů Azure.
Vyberte svůj účet Batch.
Na levém bočním panelu vyberte Pooly a pak zvolte ikonu + pro přidání poolu.
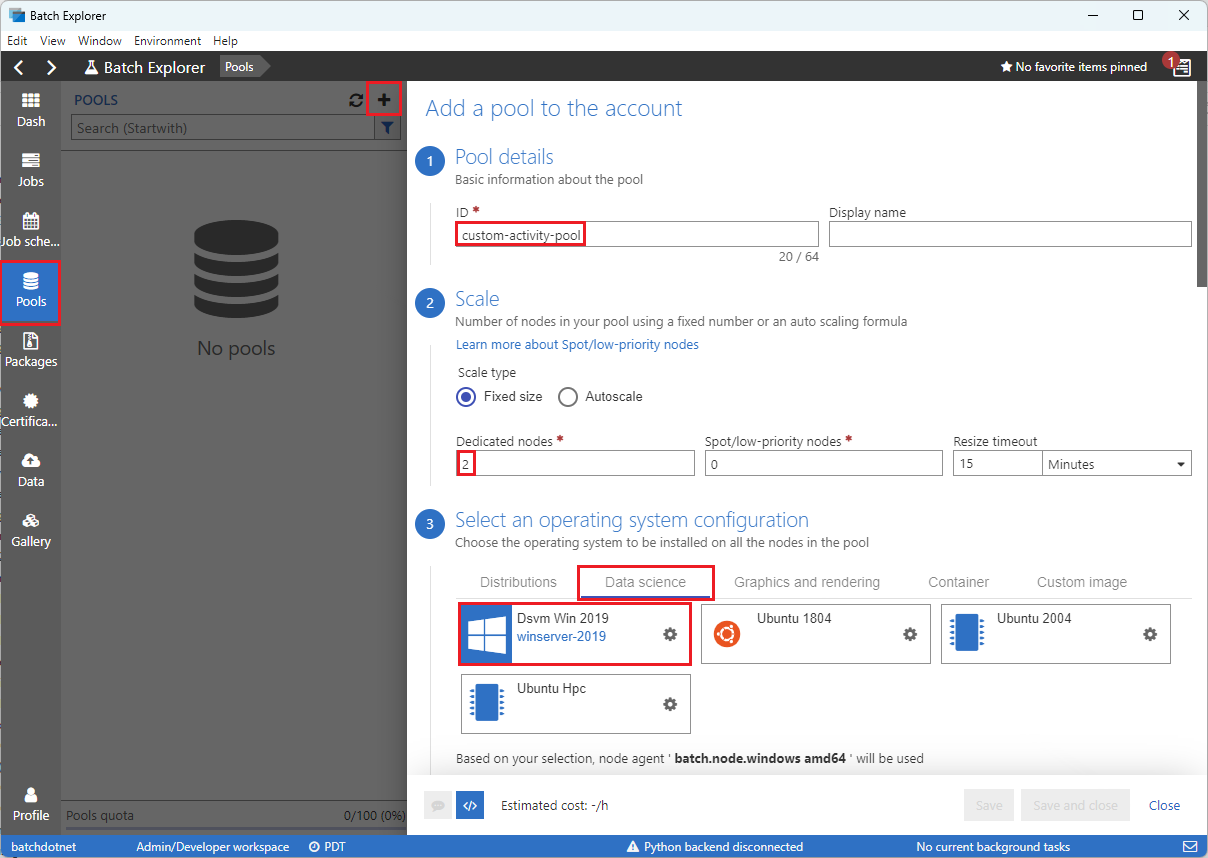
Vyplňte formulář Přidat fond na účet následujícím způsobem:
- V části ID zadejte vlastní fond aktivit.
- V části Vyhrazené uzly zadejte 2.
- Pro vybrání konfigurace operačního systému vyberte kartu Datové vědy a pak zvolte Dsvm Win 2019.
- V části Zvolit velikost virtuálního počítače vyberte Standard_F2s_v2.
- U úkolu zahájení vyberte Přidat úkol zahájení.
Na obrazovce startu úkolu v části Příkazový řádek zadejte
cmd /c "pip install azure-storage-blob pandas"a pak vyberte Vybrat. Tento příkaz nainstalujeazure-storage-blobbalíček na každý uzel při spuštění.
Zvolte Uložit a zavřít.

Použijte Průzkumník služby Storage k vytvoření kontejnerů objektů blob
Použijte Průzkumníka úložiště k vytvoření kontejnerů blobů pro ukládání vstupních a výstupních souborů a poté nahrajte vaše vstupní soubory.
- Přihlaste se do průzkumníku služby Storage pomocí svých přihlašovacích údajů Azure.
- Na levém bočním panelu vyhledejte a rozbalte účet úložiště, který je propojený s vaším účtem Batch.
- Klikněte pravým tlačítkem na Kontejnery objektů blob a vyberte Vytvořit kontejner objektů blob nebo v části Akce v dolní části bočního panelu vyberte Vytvořit kontejnerobjektů blob.
- Do pole pro zadání zadejte vstup .
- Vytvořte další kontejner objektů blob s názvem výstup.
- Vyberte vstupní kontejner a v pravém podokně vyberte Nahrát>soubory.
- Na obrazovce Nahrát soubory v části Vybrané soubory vyberte tři tečky ... vedle pole pro zadání.
- Přejděte do umístění staženého souboru iris.csv , vyberte Otevřít a pak vyberte Nahrát.

Vývoj skriptu Pythonu
Následující skript Pythonu načte soubor datové sady iris.csv z vašeho vstupního kontejneru Průzkumník služby Storage, manipuluje s daty a uloží výsledky do výstupního kontejneru.
Skript musí použít připojovací řetězec pro účet Azure Storage, který je propojený s vaším účtem Batch. Získání připojovacího řetězce:
- Na webu Azure Portal vyhledejte a vyberte název účtu úložiště, který je propojený s vaším účtem Batch.
- Na stránce účtu úložiště vyberte v části Zabezpečení a sítě přístupové klíče z levého navigačního panelu.
- V části key1 vyberte Zobrazit vedle připojovacího řetězce a pak výběrem ikony Kopírovat zkopírujte připojovací řetězec.
Vložte připojovací řetězec do následujícího skriptu a zástupný symbol nahraďte<storage-account-connection-string>. Uložte skript jako soubor s názvem main.py.
Důležité
Zveřejnění klíčů účtu ve zdroji aplikace se nedoporučuje pro produkční využití. Měli byste omezit přístup k přihlašovacím údajům a odkazovat na ně v kódu pomocí proměnných nebo konfiguračního souboru. Nejlepší je ukládat klíče účtu Batch a Storage ve službě Azure Key Vault.
# Load libraries
# from azure.storage.blob import BlobClient
from azure.storage.blob import BlobServiceClient
import pandas as pd
import io
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Initialize the BlobServiceClient (This initializes a connection to the Azure Blob Storage, downloads the content of the 'iris.csv' file, and then loads it into a Pandas DataFrame for further processing.)
blob_service_client = BlobServiceClient.from_connection_string(conn_str=connectionString)
blob_client = blob_service_client.get_blob_client(container_name=containerName, blob_name=outputBlobName)
# Download the blob content
blob_data = blob_client.download_blob().readall()
# Load iris dataset from the task node
# df = pd.read_csv("iris.csv")
df = pd.read_csv(io.BytesIO(blob_data))
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
Další informace o práci se službou Azure Blob Storage najdete v dokumentaci ke službě Azure Blob Storage.
Spuštěním skriptu místně otestujte a ověřte funkčnost.
python main.py
Skript by měl vytvořit výstupní soubor s názvem iris_setosa.csv , který obsahuje pouze datové záznamy, které mají Species = setosa. Jakmile ověříte, že funguje správně, nahrajte soubor skriptu main.py do vstupního kontejneru Průzkumník služby Storage.
Nastavte datový tok služby Data Factory
Vytvořte a ověřte kanál služby Data Factory, který používá váš skript Pythonu.
Získání informací o účtu
Kanál služby Data Factory používá názvy účtů Batch a Storage, hodnoty klíčů účtů a koncový bod účtu Batch. Pokud chcete získat tyto informace z webu Azure Portal:
Na panelu Azure Search vyhledejte a vyberte název účtu Batch.
Na stránce účtu Batch vyberte z levého navigačního panelu Klíče.
Na stránce Klíče zkopírujte následující hodnoty:
- Účet „Batch“
- Koncový bod účtu
- Primární přístupový klíč
- Název účtu úložiště
- Klíč1
Vytvoření a spuštění potrubí
Pokud azure Data Factory Studio ještě není spuštěný, na stránce Data Factory na webu Azure Portal vyberte Spustit studio .
V nástroji Data Factory Studio vyberte v levém navigačním panelu ikonu tužky pro autory .
V části Prostředky továrny vyberte + ikonu a pak vyberte Pipeline.
V podokně Vlastnosti na pravé straně změňte název kanálu na Spustit Python.
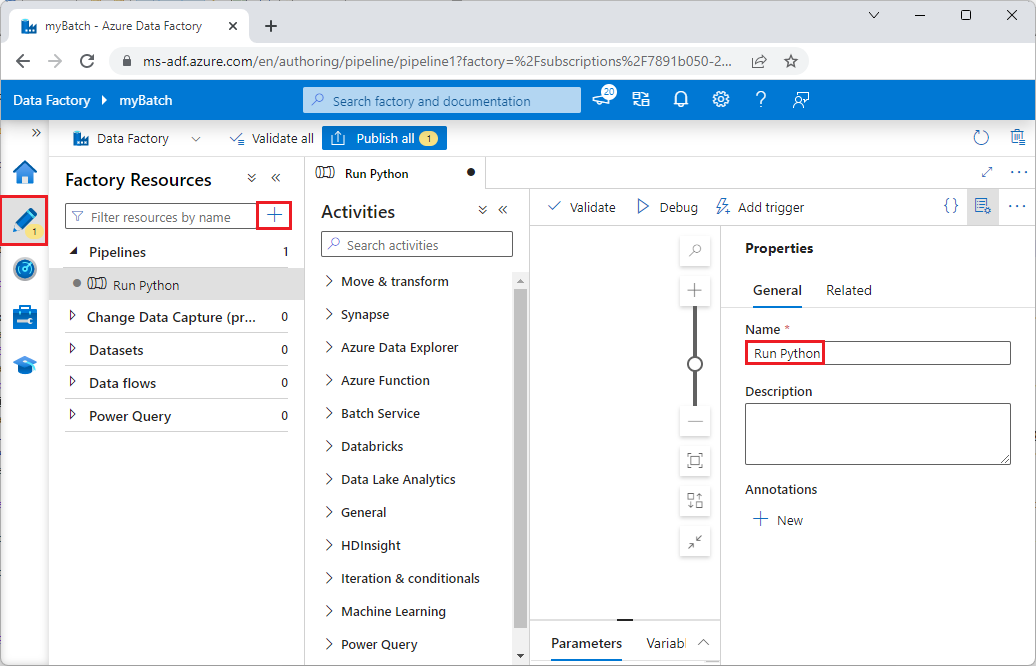
V podokně Aktivity rozbalte Batch Service a přetáhněte aktivitu Custom na plochu návrháře kanálu.
Pod plátnem návrháře, na kartě Obecné, zadejte testPipeline do pole Název.
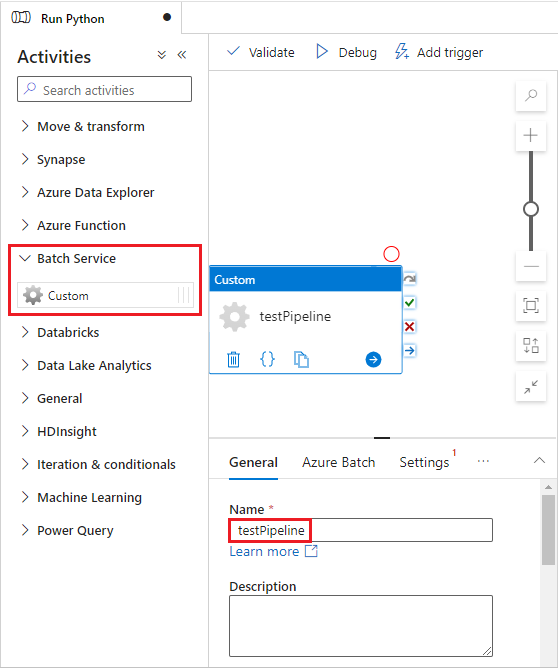
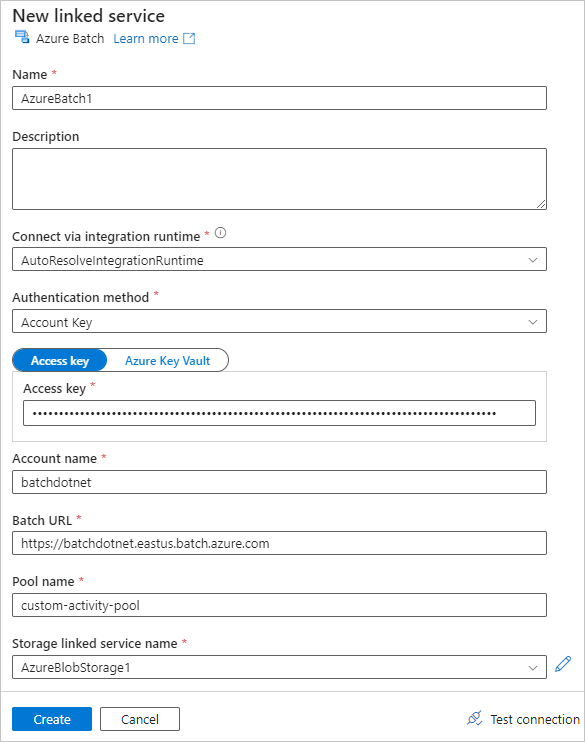
Vyberte kartu Azure Batch a pak vyberte Nový.
Vyplňte formulář Nová propojená služba následujícím způsobem:
- Název: Zadejte název propojené služby, například AzureBatch1.
- Přístupový klíč: Zadejte primární přístupový klíč, který jste zkopírovali ze svého účtu Batch.
- Název účtu: Zadejte název účtu Batch.
-
Adresa URL služby Batch: Zadejte koncový bod účtu, který jste zkopírovali ze svého účtu Batch, například
https://batchdotnet.eastus.batch.azure.com. - Název fondu: Zadejte custom-activity-pool, fond, který jste vytvořili v Batch Exploreru.
- Název propojeného účtu služby úložiště: Vyberte Nový. Na další obrazovce zadejte název propojené služby úložiště, například AzureBlobStorage1, vyberte své předplatné Azure a propojený účet úložiště a pak vyberte Vytvořit.
Na dolní části obrazovky Batch New linked service vyberte Test připojení. Po úspěšném připojení vyberte Vytvořit.
Vyberte kartu Nastavení a zadejte nebo vyberte následující nastavení:
-
Příkaz: Enter
cmd /C python main.py. - Propojená služba prostředků: Vyberte propojenou službu úložiště, kterou jste vytvořili, například AzureBlobStorage1, a otestujte připojení, abyste měli jistotu, že je úspěšná.
- Cesta ke složce: Vyberte ikonu složky a pak vyberte vstupní kontejner a vyberte OK. Soubory z této složky se před spuštěním skriptu Pythonu stáhnou z kontejneru do uzlů fondu.

-
Příkaz: Enter
Vyberte Ověřit na panelu nástrojů potrubí a ověřte potrubí.
Vyberte Ladit pro otestování potrubí a zajištění jeho správné funkčnosti.
Vyberte Publikovat vše pro publikování procesu.
Vyberte Přidat trigger a pak vyberte Aktivovat , aby se kanál spustil, nebo Nový nebo Upravit a naplánujte ho.

Zobrazení souborů protokolu pomocí Batch Exploreru
Pokud spuštění kanálu generuje upozornění nebo chyby, můžete se pomocí Batch Exploreru podívat na stdout.txt a stderr.txt výstupní soubory, kde najdete další informace.
- V Batch Exploreru vyberte úlohy na levém bočním panelu.
- Vyberte úlohu adfv2-custom-activity-pool.
- Vyberte úlohu, která měla výstupní kód selhání.
- Prohlédněte si soubory stdout.txt a stderr.txt a prozkoumejte a diagnostikujte váš problém.
Uvolnění zdrojů
Účty Batch, úlohy a úkoly jsou bezplatné, ale za výpočetní uzly se účtují poplatky i tehdy, když na nich neběží úlohy. Pooly uzlů je nejlepší přidělovat podle potřeby, a až s jejich používáním skončíte, odstraňte je. Odstraněním fondů se odstraní všechny výstupy úkolů na uzlech i samotné uzly.
Vstupní a výstupní soubory zůstanou v účtu úložiště a mohou vzniknout poplatky. Pokud už soubory nepotřebujete, můžete soubory nebo kontejnery odstranit. Pokud už účet Batch nebo propojený účet úložiště nepotřebujete, můžete je odstranit.
Další kroky
V tomto tutoriálu jste se naučili používat skrypt Pythonu s Batch Explorerem, Průzkumník služby Storageem a Data Factory ke spuštění úlohy Batch. Další informace o službě Data Factory najdete v tématu Co je Azure Data Factory?