Datové produkty analýzy v cloudovém měřítku v Azure
Datové produkty jsou data sloužící jako produkt a počítaná, uložená a obsluhovaná službami polyglot persistence, které mohou být vyžadovány v určitých případech použití. Proces vytváření a poskytování datových produktů může vyžadovat služby a technologie, které nejsou zahrnuté do základních služeb cílové zóny dat . Příkladem může být vykazování s nikem požadavků, jako je dodržování předpisů a daňové hlášení.
Na co dát pozor při navrhování
Datovou cílovou zónu je možné obsluhovat několika datovými produkty vytvořenými ingestováním dat ze stejné cílové zóny dat nebo z více cílových zón dat. To je vidět v následujícím diagramu.
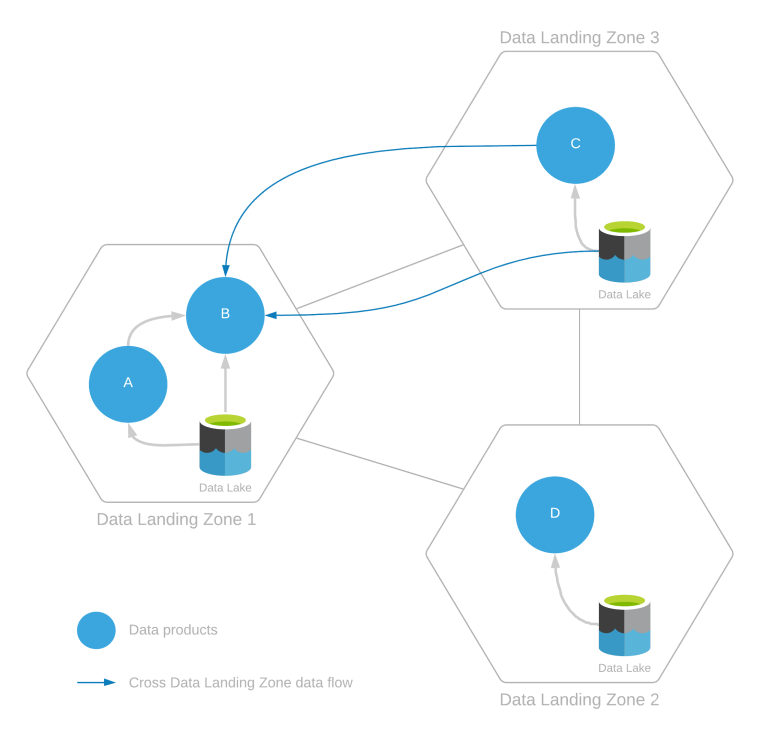
Výše uvedený příklad ukazuje:
- Spotřeba dat uvnitř pásma:
- Datový produkt B využívá data z datového produktu A a dalších dat nebo datových produktů existujících v datovém jezeře v rámci vlastní cílové zóny.
- Datové produkty C a D využívají data pouze z vlastních cílových datových zón.
- Spotřeba dat mezi zónami:
- Datový produkt B také využívá data z datového produktu C a z dat z datového jezera cílové zóny 3.
Důležité
V případě mezizónové spotřeby dat, protože datový produkt B je vytvořen čtením z cílové zóny dat 3, vyžaduje tento přístup pro čtení schválení týmy operací cílové zóny dat a operací integrace v datové cílové zóně 3.
Důležité
Datový produkt B využívá data z datových produktů A a C. Než k tomu dojde, musí datový produkt B zaregistrovat svou spotřebu datových produktů prostřednictvím smluv o sdílení dat. Tato smlouva o sdílení dat by měla aktualizovat rodokmen dat z datového produktu A na datový produkt B a z datového produktu C na datový produkt B.
Skupina prostředků datového produktu zahrnuje všechny služby potřebné k jeho vytvoření a údržbě. Tuto skupinu prostředků můžeme volat datovou aplikaci. Mezi služby, které můžou být součástí datové aplikace, patří Azure Functions, Azure App Service, Logic Apps, Azure Analysis Services, Azure Cognitive Services, Azure Machine Learning, Azure SQL Database Azure Database for MySQLa Azure Cosmos DB. Další informace najdete v ukázkách datových aplikací.
Datové produkty obsahují data ze zdrojů dat READ , u kterých se použily některé transformace dat. Příkladem může být nově kurátorovaná datová sada nebo sestava BI.
Doporučení k návrhu
Vytvářejte datové produkty v rámci cílové zóny dat dodržováním principů návrhu, které umožňují škálování pomocí zásad správného řízení dat. Následující části obsahují doporučení návrhu, která vám pomůžou při plánování ekosystému datových aplikací.
Nasazení více skupin prostředků
Každá datová aplikace je skupina prostředků. Vzhledem k tomu, že datové aplikace jsou výpočetní služby, služby polyglotní trvalosti nebo obojí, mohou být vyžadovány pouze v závislosti na určitých případech použití. Proto se považují za volitelnou komponentu cílové zóny dat. V případě, že potřebujete datové aplikace, vytvořte několik skupin prostředků podle datové aplikace, jak je znázorněno na následujícím diagramu.

Nastavit mantinely
Azure Policy řídí výchozí konfiguraci služeb v rámci cílové zóny dat. Provozní analýzy si můžete představit jako několik skupin prostředků, které si váš datový produktový tým může vyžádat ze standardního katalogu služeb. Pomocí Azure Policy můžete nakonfigurovat hranici zabezpečení a požadovanou sadu funkcí.
Důležité
Pokud chcete zajistit konzistenci, nakonfigurujte jednu Azure Policy pro každou datovou aplikaci.
Využívání dat z více míst
Datové aplikace spravují, uspořádají a vycítají smysl dat z více datových prostředků a prezentují všechny získané poznatky. Datový produkt je výsledkem dat z jedné nebo více datových aplikací v rámci cílových zón dat. V případě potřeby povolte datovým aplikacím přístup k datům z různých zdrojů.
Škálování podle potřeby
Služby, které tvoří datové aplikace, jsou přírůstková nasazení do cílové zóny dat. Škálujte datové aplikace podle potřeby.
Povolení zjišťování dat
Automaticky zaregistrujte datové produkty v katalogu dat, jako je Azure Purview , abyste umožnili kontrolu dat.
Identifikace datových produktů
Při plánování cílové zóny dat identifikujte podle potřeby tolik datových produktů (a datových aplikací, které je vysílají a udržují), které vám pomůžou řídit architekturu datových produktů. Největší roli ve vašich rozhodnutích by měla hrát shoda s implementovanými zásadami správného řízení platformy.
Zaměřte se na to, jak jsou vaše datové aplikace producenty a příjemci dat pro ostatní. Předpokládejme například, že jste identifikovali sadu datových produktů (A, B, C a D), které se vytvářejí a využívají data. Vyžadujete datové produkty A a D jako zdroje dat v datové aplikaci B pro datový produkt B. Datový produkt B se vytvoří z dat, která datová aplikace B využívá z datových produktů A a D. Datová aplikace B funguje jako samotný producent dat a také vytváří data pro datový produkt C.
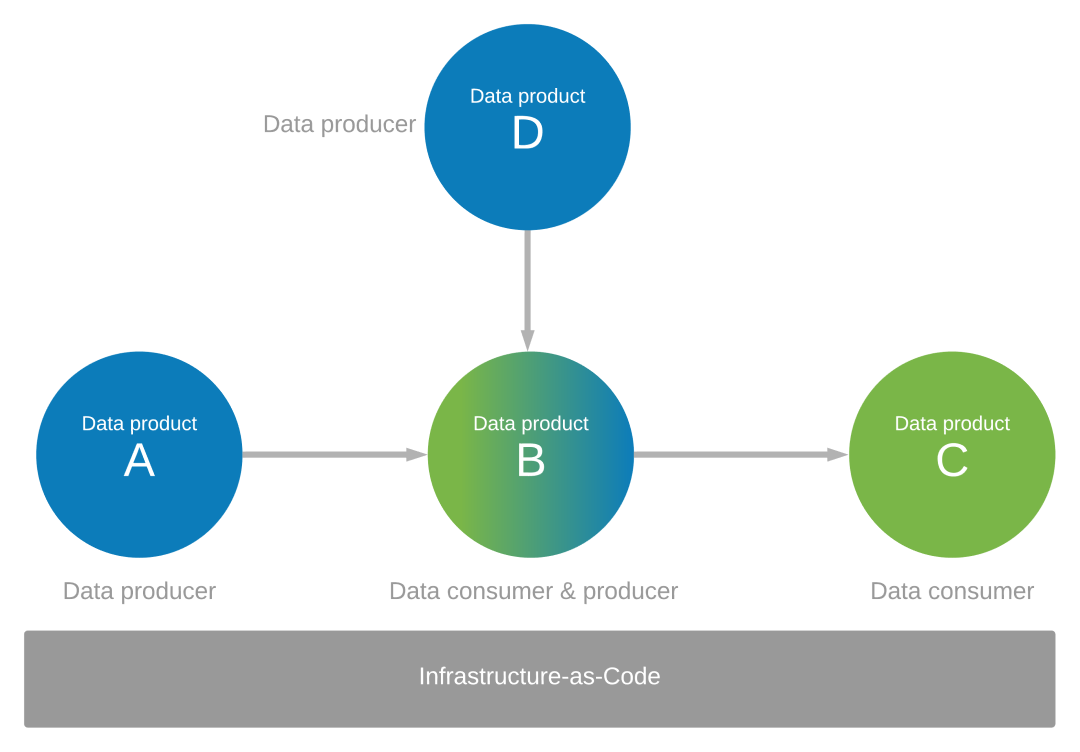
Řízení prostředí datových aplikací pomocí infrastruktury jako kódu
Zásady správného řízení a infrastruktura jako kód by měly řídit prostředí datových aplikací v ekosystému datových produktů, jak je znázorněno v předchozím diagramu.
Publikování datových modelů
Týmy vašich datových produktů by měly své datové modely publikovat v úložišti modelování.
Nastavení očekávání pro uživatele datových produktů
Aktualizujte své smlouvy o sdílení dat pomocí smluv o úrovni služeb a certifikací pro vaše datové produkty, abyste potenciálním uživatelům datového produktu mohli sdělit přesná očekávání.
Rodokmen záznamu
Pokud je datový produkt B vytvořen z dat pocházejících z datových produktů A a D, musí být zaznamenán rodokmen dat z A a D do B. Pro datový produkt C by měl být zaznamenán také další rodokmen, protože se vytváří pomocí dat z datového produktu B. Aktualizovaný rodokmen dat by měl být zachycen v aplikaci rodokmenu dat před každým vydáním datového produktu.
Poznámka
Azure Pipelines umožňuje vytvářet schvalovací brány a vyvolávat funkce, které zajistí registraci metadat, rodokmenu a smluv SLA ve správné službě zásad správného řízení.
Definování architektury datových aplikací
Pro každý datový produkt musíte vytvořit podrobnou architekturu, která plně definuje jeho vztah k jiným datovým produktům, jejich závislostem a požadavkům na přístup.
Ukázkový scénář návrhu
Pokud chcete porozumět procesu definice architektury, prozkoumejte následující příklad finanční instituce a jejího produktu pro monitorování úvěru.
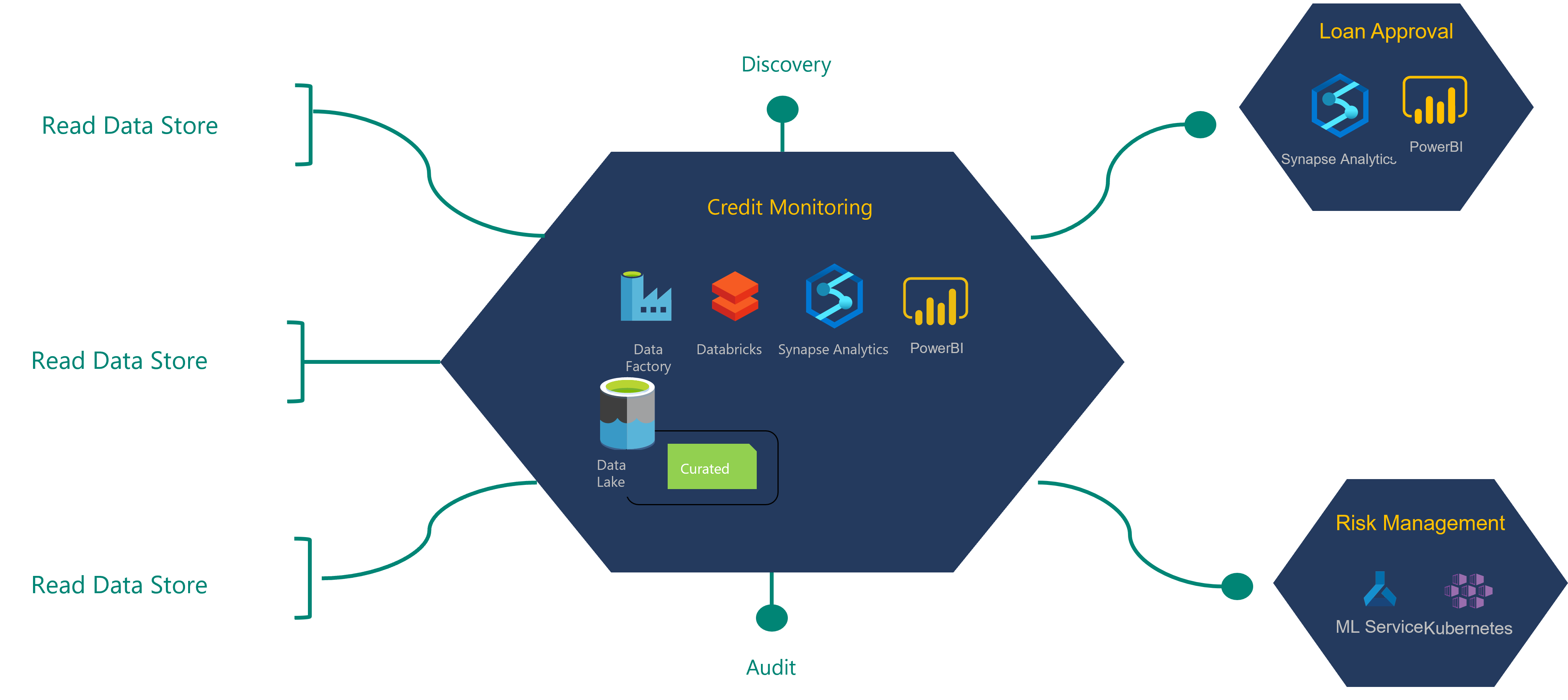
Produkt dat monitorování úvěru zobrazený v tomto diagramu využívá data z úložiště dat pro čtení , které bylo ingestováno týmem operací integrace. Vytváří datové produkty, které také využívají dva další datové produkty.
Poznámka
Přečtený zdroj dat nebo úložiště se označuje také jako zlatý zdroj záznamů. Tyto zdroje dat byly vyčištěny, ale nebyly u nich použity žádné transformace.
Produktový tým pro monitorování úvěrového kreditu požaduje přístup pro čtení úložišť dat, která potřebují k vytvoření datového produktu. Jejich žádosti se směrují vlastníkům dat ke schválení. Jakmile produktový tým obdrží schválení, může začít vytvářet datovou aplikaci.
Data ze přečteného zdroje dat se transformují do produktů s daty monitorování úvěru. Všechny nové datové produkty se ukládají do kurátorované vrstvy data lake. Tyto nové datové produkty a nový rodokmen dat by se měly zaregistrovat jako součást procesu nasazení DevOps. Funkce může zkontrolovat registrovaná metadata s fyzickou strukturou datového assetu. Měla by registrovat závislost na datových prostředcích a datových produktech pro čtení zdrojů dat.
Produktový tým pro data schvalování půjček je závislý na některých produktech s daty monitorování úvěru. Tým pro schvalování půjček může požádat o přístup pro čtení k datovým produktům monitorování úvěru, které vyžadují pro své datové produkty. Jakmile uvolní datový produkt schválení půjčky a jeho datovou aplikaci, měly by být všechny datové prostředky, rodokmen a modely datových produktů registrovány v příslušných službách zásad správného řízení.
Ukázkové datové aplikace
Následující části obsahují ukázkové datové aplikace, které podrobněji ilustrují scénáře datových aplikací.
Datová aplikace pro analýzu dat a datové vědy
Aplikace pro analýzu dat a datové vědy může obsahovat služby uvedené v ukázkové datové aplikaci product-analytics-rg.

Poznámka
Výše uvedená datová aplikace je k dispozici jako šablona, která nasadí sadu služeb, které můžete použít pro analýzu dat a datové vědy. Stejně jako všechny naše šablony je i tato šablona datového produktu podrobným plánem, který můžete použít k rychlému vytvoření prostředí pro týmy s různými funkcemi. Všechny služby, které nepotřebujete, musí být explicitně zakázané.
Šablona Analýzy datového produktu obsahuje všechny šablony pro nasazení datového produktu pro účely analýz a datových věd v cílové zóně dat ve scénáři analýzy na úrovni cloudu.
Artefakty nasazení a kódu zahrnují následující služby:
- Machine Learning
- Key Vault
- Application Insights
- Storage
- Container Registry
- Cognitive Services (volitelné)
- Data Factory (vyberte mezi službami Data Factory a Synapse)
- Pracovní prostor Synapse (vyberte mezi službou Data Factory a Synapse)
- Azure Search (volitelné)
- Fond SQL (volitelné)
- Fond BigData (volitelné)
Aplikace Batch Data
Šablona aplikace Batch Data obsahuje všechny šablony pro nasazení datového produktu pro dávkové zpracování dat v cílové zóně dat scénáře analýzy škálování cloudu.
Artefakty nasazení a kódu zahrnují následující služby:

- Key Vault
- Data Factory (vyberte mezi službami Data Factory a Synapse)
- Azure Cosmos DB (volitelné)
- Pracovní prostor Synapse (vyberte mezi službou Data Factory a Synapse)
- Databáze MySQL (volitelné)
- Azure SQL Databáze (volitelné)
- Databáze PostgreSQL (volitelné)
- Databáze MariaDB (volitelné)
- Fond SQL (volitelné)
- SQL Server (volitelné)
- Elastický fond SQL (volitelné)
- Fond BigData
Aplikace streamování dat
Šablona Aplikace streamovaných dat obsahuje všechny šablony pro nasazení datového produktu pro zpracování dat v reálném čase v cílové zóně dat ve scénáři cloudové analýzy.
Artefakty nasazení a kódu zahrnují následující služby:

- Key Vault
- Event Hubs
- IoT Hub
- Stream Analytics (volitelné)
- Azure Cosmos DB (volitelné)
- Pracovní prostor Synapse
- Azure SQL Databáze (volitelné)
- Fond SQL (volitelné)
- SQL Server (volitelné)
- Elastický fond SQL (volitelné)
- Fond BigData
- Data Explorer (volitelné)
Pokud chcete najít úložiště obsahující výše uvedené šablony nasazení, projděte si šablony nasazení pro analýzy škálování cloudu.