Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: ![]() NoSQL
NoSQL
Důležité
Tipy k výkonu v tomto článku jsou určené jenom pro sadu Java SDK služby Azure Cosmos DB verze 4. Prohlédněte si poznámky k verzi sady Azure Cosmos DB Java SDK v4, úložiště Maven a průvodce odstraňováním potíží sady Azure Cosmos DB Java SDK v4 pro více informací. Pokud aktuálně používáte starší verzi než v4, nápovědu k upgradu na verzi 4 najdete v průvodci migrací do sady Java SDK služby Azure Cosmos DB verze 4.
Azure Cosmos DB je rychlá a flexibilní distribuovaná databáze, která se bezproblémově škáluje s garantovanou latencí a propustností. Nemusíte provádět významné změny architektury ani psát složitý kód pro škálování databáze pomocí služby Azure Cosmos DB. Vertikální navýšení a snížení kapacity je stejně snadné jako vytvoření jediného volání rozhraní API nebo volání metody sady SDK. Vzhledem k tomu, že je služba Azure Cosmos DB přístupná prostřednictvím síťových volání, existují optimalizace na straně klienta, které můžete provést, abyste dosáhli maximálního výkonu při použití sady Azure Cosmos DB Java SDK v4.
Pokud se tedy ptáte, jak můžu zlepšit výkon databáze? zvažte následující možnosti:
Sítě
Sloučit klienty ve stejné oblasti Azure pro zajištění výkonu
Pokud je to možné, umístěte všechny aplikace, které volají službu Azure Cosmos DB, do stejné oblasti jako databáze Azure Cosmos DB. Pro přibližné porovnání se volání služby Azure Cosmos DB ve stejné oblasti dokončí do 1 až 2 ms, ale latence mezi pobřežím USA – západ a východ je >50 ms. Tato latence se může pravděpodobně lišit od požadavku na požadavek v závislosti na trase, kterou žádost vzala při průchodu z klienta do hranice datacentra Azure. Nejnižší možné latence se dosahuje tím, že se volající aplikace nachází ve stejné oblasti Azure jako zřízený koncový bod služby Azure Cosmos DB. Seznam dostupných oblastí najdete v tématu Oblasti Azure.
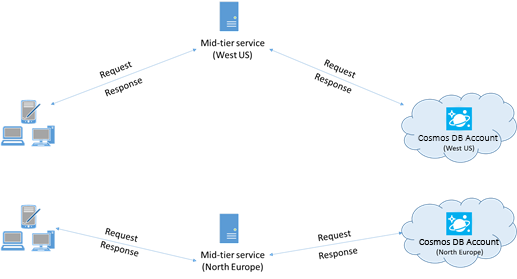
Aplikace, která komunikuje s účtem Azure Cosmos DB ve více oblastech, musí nakonfigurovat upřednostňovaná umístění , aby se zajistilo, že požadavky přejdou do kompletované oblasti.
Povolení akcelerovaných síťových služeb za účelem snížení latence a zpoždění procesoru
Důrazně doporučujeme postupovat podle pokynů, abyste ve Windows povolili akcelerované síťové služby (vyberte pokyny) nebo Linux (vyberte pokyny), aby se virtuální počítač Azure maximalizoval tím, že sníží latenci a zpoždění procesoru.
Bez akcelerovaných síťových operací se vstupně-výstupní operace mezi vaším virtuálním počítačem Azure a dalšími prostředky Azure můžou směrovat přes hostitele a virtuální přepínač umístěný mezi virtuálním počítačem a jeho síťovou kartou. Když se hostitel a virtuální přepínač nachází přímo v datové cestě, nejen zvyšuje latenci a chvění v komunikačním kanálu, ale také odebírá cykly CPU virtuálnímu počítači. Díky akcelerovaným síťovým rozhraním se virtuální počítače přímo se síťovým rozhraním bez zprostředkovatelů. Všechny podrobnosti o zásadách sítě se zpracovávají v hardwaru síťové karty a obcházejí hostitele a virtuální přepínač. Obecně můžete očekávat nižší latenci a vyšší propustnost, stejně jako konzistentnější latenci a snížení využití procesoru, když povolíte akcelerované síťové služby.
Omezení: Akcelerované síťové služby musí být podporovány v operačním systému virtuálního počítače a dají se povolit jenom v případě, že je virtuální počítač zastavený a uvolněný. Virtuální počítač nejde nasadit pomocí Azure Resource Manageru. Služba App Service nemá povolenou akcelerovanou síť.
Další informace najdete v pokynech pro Windows a Linux .
Vysoká dostupnost
Obecné pokyny ke konfiguraci vysoké dostupnosti ve službě Azure Cosmos DB najdete v tématu Vysoká dostupnost ve službě Azure Cosmos DB.
Kromě dobrého základního nastavení v databázové platformě existují specifické techniky, které je možné implementovat v samotné sadě Java SDK, což může pomoct ve scénářích výpadků. Dvě velmi vhodné strategie jsou strategie dostupnosti založená na prahové hodnotě a jistič na úrovni oddílů.
Tyto techniky poskytují pokročilé mechanismy pro řešení konkrétních problémů s latencí a dostupností, které jsou nad rámec možností opakování napříč oblastmi, které jsou ve výchozím nastavení integrované do sady SDK. Díky proaktivní správě potenciálních problémů na úrovni požadavků a oddílů můžou tyto strategie výrazně zvýšit odolnost a výkon vaší aplikace, zejména za vysoce zatížených nebo snížených podmínek.
Strategie dostupnosti založená na prahových hodnotách
Strategie dostupnosti založená na prahových hodnotách může zlepšit koncovou latenci a dostupnost odesláním paralelních žádostí o čtení do sekundárních oblastí (jak je definováno preferredRegions) a přijetím nejrychlejší odpovědi. Tento přístup může výrazně snížit dopad regionálních výpadků nebo podmínek s vysokou latencí na výkon aplikace. Kromě toho je možné proaktivní správu připojení využít k dalšímu zvýšení výkonu tím, že zahřejete připojení a mezipaměti v aktuální oblasti čtení i upřednostňovaných vzdálených oblastech.
Příklad konfigurace:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("East US", "East US 2", "West US"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
Jak to funguje:
Počáteční požadavek: V době T1 se požadavek na čtení provede v primární oblasti (například USA – východ). Sada SDK čeká na odpověď až na 500 milisekund (
thresholdhodnota).Druhý požadavek: Pokud primární oblast neobsahuje odpověď v rozsahu 500 milisekund, odešle se paralelní požadavek do další upřednostňované oblasti (například USA – východ 2).
Třetí žádost: Pokud primární ani sekundární oblast nereaguje do 600 milisekund (500 ms + 100 ms, hodnota),
thresholdStepsada SDK odešle další paralelní požadavek do třetí upřednostňované oblasti (například USA – západ).Nejrychlejší odpověď wins: Která oblast odpoví jako první, tato odpověď se přijme a ostatní paralelní požadavky se ignorují.
Proaktivní správa připojení pomáhá zahříváním připojení a mezipamětí pro kontejnery v upřednostňovaných oblastech, což snižuje latenci studeného spuštění pro scénáře převzetí služeb při selhání nebo zápisy v nastaveních s více oblastmi.
Tato strategie může výrazně zlepšit latenci ve scénářích, kdy je určitá oblast pomalá nebo dočasně nedostupná, ale pokud jsou vyžadovány paralelní požadavky napříč oblastmi, může to vyžadovat vyšší náklady z hlediska jednotek žádostí.
Poznámka:
Pokud první upřednostňovaná oblast vrátí ne přechodný stavový kód chyby (např. dokument nebyl nalezen, chyba autorizace, konflikt atd.), samotná operace selže rychle, protože strategie dostupnosti v tomto scénáři nebude mít žádnou výhodu.
Jistič na úrovni oddílů
Jistič na úrovni oddílu vylepšuje koncovou latenci a dostupnost zápisu sledováním a zkratováním požadavků na fyzické oddíly, které nejsou v pořádku. Zlepšuje výkon tím, že se vyhne problémovým oddílům a přesměruje požadavky do zdravějších regionů.
Příklad konfigurace:
Povolit jistič na úrovni partice:
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
Nastavení frekvence procesu na pozadí pro kontrolu nedostupných oblastí:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
Nastavte dobu, po kterou může oddíl zůstat nedostupný:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
Jak to funguje:
Sledování selhání: SDK sleduje konečná selhání (například 503, 500, vypršení časového limitu) pro jednotlivé oddíly v konkrétních regionech.
Označení jako nedostupné: Pokud partition v oblasti překročí nakonfigurovanou prahovou hodnotu selhání, označí se jako nedostupný. Následné požadavky na tento partition jsou přerušené a přesměrované do jiných zdravějších oblastech.
Automatizované obnovení: Vlákno na pozadí pravidelně kontroluje nedostupné oddíly. Po určité době jsou tyto oddíly dočasně označeny jako "HealthyTentative" a předloženy k testovacím požadavkům na ověření obnovy.
Povýšení nebo snížení úrovně stavu: Na základě úspěchu nebo selhání těchto testovacích požadavků se stav oddílu buď zvýší na hodnotu V pořádku, nebo se opět sníží na Nedostupný.
Tento mechanismus pomáhá nepřetržitě monitorovat stav oddílů a zajišťuje, že jsou požadavky obsluhovány s minimální latencí a maximální dostupností, aniž by byly brzděny problematickými oddíly.
Poznámka:
Jistič se vztahuje pouze na účty s možností zápisu do více oblastí, stejně jako když je oddíl označen jako Unavailable, přesunou se čtení i zápisy do další preferované oblasti. Tím zabráníte tomu, aby se čtení a zápisy z různých oblastí obsluhovaly ze stejné instance klienta, protože by to byl nevhodný vzor.
Důležité
Abyste mohli aktivovat jistič na úrovni oddílů, musíte používat verzi Java SDK 4.63.0 nebo vyšší.
Porovnání optimalizací dostupnosti
Strategie dostupnosti založená na prahových hodnotách:
- Výhoda: Snižuje zpoždění na konci spojení odesíláním paralelních žádostí o čtení do sekundárních oblastí a zlepšuje dostupnost předcházením požadavkům, které vedou k vypršení časového limitu sítě.
- Kompromis: Ve srovnání s jističem vznikají dodatečné náklady na jednotky žádostí (RU) kvůli dalším paralelním požadavkům napříč regiony (ale pouze během období, kdy jsou překročeny prahové hodnoty).
- Případ užití: Optimální pro úlohy náročné na čtení, kde je kritická potřeba snížení latence a některé dodatečné náklady (z hlediska poplatků za RU i zatížení procesoru klienta) jsou přijatelné. Operace zápisu mohou mít také přínos, pokud se přihlásíte k zásadě opakování zápisů bez neidempotentního zápisu a účet má zápisy ve více oblastech.
Jistič na úrovni části:
- Výhoda: Zlepšuje dostupnost a odezvu tím, že se vyhnete nezdravým partitionům a zajišťuje směrování požadavků do zdravějších oblastí.
- Kompromis: Nepřináší další náklady na RU, ale u požadavků, které budou mít za následek vypršení časového limitu sítě, stále může dojít k určité počáteční ztrátě dostupnosti.
- Příklad použití: Ideální pro úlohy náročné na zápis nebo smíšené úlohy, kde je nezbytný konzistentní výkon, zejména při práci s oddíly, které můžou občas být nezdravé.
Obě strategie je možné použít společně k vylepšení dostupnosti čtení a zápisu a snížení koncové latence. Jistič na úrovni oddílů může zpracovávat různé přechodné scénáře selhání, včetně těch, které mohou vést k pomalu pracujícím replikám, aniž by bylo nutné provádět paralelní požadavky. Přidání strategie dostupnosti založené na prahových hodnotách navíc dále minimalizuje koncovou latenci a eliminuje ztrátu dostupnosti, pokud jsou přijatelné další náklady na RU.
Díky implementaci těchto strategií můžou vývojáři zajistit, aby jejich aplikace zůstaly odolné, udržovaly vysoký výkon a poskytovaly lepší uživatelské prostředí i během regionálních výpadků nebo podmínek s vysokou latencí.
Konzistence relací s vymezeným oborem oblastí
Přehled
Další informace o nastavení konzistence obecně najdete v tématu Úrovně konzistence ve službě Azure Cosmos DB. Java SDK poskytuje optimalizaci konzistence relací pro účty pro zápis do více oblastí tím, že ji umožňuje vázat na oblast. To zvyšuje výkon tím, že snižuje latenci replikace mezi oblastmi prostřednictvím minimalizace opakování na straně klienta. Toho dosáhnete tak, že spravujete tokeny relací na úrovni oblasti místo globálně. Pokud vaše aplikace potřebuje jen konzistenci v několika oblastech, použití konzistence relací omezené na oblast může zlepšit výkon a spolehlivost pro čtení a zápis v účtech povolujících více zápisů tím, že sníží zpoždění replikace mezi oblastmi a opakování.
Zaměstnanecké výhody
- Nižší latence: Lokalizací ověřování tokenu relace na úrovni oblasti se sníží pravděpodobnost nákladných opakovaných pokusů napříč oblastmi.
- Vylepšený výkon: Minimalizuje dopad regionálního přepnutí při selhání a prodlevy replikace, poskytuje vyšší konzistenci čtení a zápisu a nižší využití procesoru.
- Optimalizované využití prostředků: Snižuje zatížení procesoru a sítě u klientských aplikací omezením potřeby opakovaných pokusů a volání mezi oblastmi, čímž optimalizuje využití prostředků.
- Vysoká dostupnost: Udržováním tokenů relací pro jednotlivé oblasti můžou aplikace nadále fungovat hladce, i když některé oblasti trpí vyšší latencí nebo dočasnými selháními.
- Záruky konzistence: Zajišťuje, aby byly záruky konzistence relace (přečtení vašeho zápisu, monotónní čtení) spolehlivěji splněny bez zbytečných opakování.
- Efektivita nákladů: Snižuje počet volání mezi oblastmi, což potenciálně snižuje náklady spojené s přenosy dat mezi oblastmi.
- Škálovatelnost: Umožňuje aplikacím efektivněji škálovat snížením konkurence a režie spojené s údržbou globálního tokenu relace, zejména při nasazení ve více regionech.
Kompromisy
- Zvýšené využití paměti: Filtr bloom a úložiště tokenů relací specifické pro oblast vyžadují více paměti, což může být důležité pro aplikace s omezenými prostředky.
- Složitost konfigurace: Vyladění očekávaného počtu vložení a falešně pozitivní míry pro filtr květu přidá do procesu konfigurace vrstvu složitosti.
- Potenciál falešně pozitivních výsledků: I když Bloomův filtr minimalizuje opakovaná volání mezi regiony, stále existuje mírná šance, že falešně pozitivní výsledky ovlivní ověření tokenu relace, ačkoli míru lze kontrolovat. Falešný pozitiv znamená, že se vyřeší token globální relace, čímž se zvýší pravděpodobnost opakování mezi regiony, pokud se místní region ještě nesynchronizoval s touto globální relací. Záruky relací jsou splněny i v přítomnosti falešně pozitivních výsledků.
- Použitelnost: Tato funkce je nejužitevější pro aplikace s vysokou kardinalitou logických oddílů a pravidelným restartováním. U aplikací s menším počtem logických oddílů nebo s méně častými restarty se nemusí projevit významné přínosy.
Jak to funguje
Nastavení tokenu relace
- Dokončení požadavku: Po dokončení požadavku sada SDK zachytí token relace a přidruží ho k oblasti a klíči oddílu.
-
Úložiště na úrovni oblasti: Tokeny relace se ukládají do vnořeného
ConcurrentHashMapobjektu, který udržuje mapování mezi rozsahy klíčů oddílů a průběhem na úrovni oblasti. - Bloom Filter: Bloom filtr sleduje, které regiony byly přístupovány jednotlivými logickými partiemi, což pomáhá lokalizovat ověřování tokenu relace.
Řešení tokenu relace
- Inicializace požadavku: Před odesláním požadavku se SDK pokusí vyřešit token relace pro příslušnou oblast.
- Kontrola tokenu: Token se kontroluje na základě dat specifických pro danou oblast, aby se zajistilo, že se požadavek směruje na nejaktuálnější repliku.
- Logika opakování: Pokud se token relace neověří v rámci aktuální oblasti, sada SDK opakuje pokusy s jinými oblastmi, ale vzhledem k lokalizovaným úložištím je to méně časté.
Použití sady SDK
Zde je způsob, jak inicializovat CosmosClient s regionální konzistencí relací:
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
Povolit konzistenci relací v rámci oblasti
Pokud chcete povolit zachytávání relací na úrovni oblasti ve vaší aplikaci, nastavte následující systémovou vlastnost:
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
Nakonfigurujte filtr typu bloom
Vylaďte výkon konfigurací očekávanému počtu vložení a míry falešně pozitivních pro Bloomův filtr.
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
Důsledky pro paměť
Níže je zachovaná velikost (velikost objektu a všeho, co na něm závisí) interního kontejneru relace (spravovaného sadou SDK) s různým očekávaným počtem vložení do bloom filtru.
| Očekávaná vložení | Míra falešně pozitivních nálezů | Zachovaná velikost |
|---|---|---|
| 10, 000 | 0,001 | 21 kB |
| 100, 000 | 0,001 | 183 kB |
| 1 milion | 0,001 | 1,8 MB |
| 10 milionů | 0,001 | 17,9 MB |
| 100 milionů | 0,001 | 179 MB |
| 1 miliarda | 0,001 | 1,8 GB |
Důležité
Abyste mohli aktivovat konzistenci relací v rozsahu oblastí, musíte používat verzi 4.60.0 sady Java SDK nebo vyšší.
Vyloučené oblasti
Funkce vyloučených oblastí umožňuje jemně odstupňovanou kontrolu nad směrováním požadavků tím, že umožňuje vyloučit konkrétní oblasti z upřednostňovaných umístění na základě jednotlivých požadavků. Tato funkce je dostupná v sadě Azure Cosmos DB Java SDK verze 4.47.0 a vyšší.
Klíčové výhody:
- Zpracování omezování rychlosti: Při výskytu odpovědí 429 (příliš mnoho požadavků) automaticky směrujte požadavky do alternativních oblastí s dostupnou propustností.
- Cílené směrování: Zajištění obsluhy požadavků z konkrétních oblastí vyloučením všech ostatních
- Vynechat upřednostňované pořadí: Přepsat výchozí seznam upřednostňovaných oblastí pro jednotlivé požadavky bez nutnosti vytvářet samostatné klienty
Configuration:
Vyloučené oblasti je možné nakonfigurovat na úrovni klienta i na úrovni požadavku:
CosmosExcludedRegions excludedRegions = new CosmosExcludedRegions(Set.of("East US"));
// Using AtomicReference to simulate dynamic changes to excluded regions. Excluded regions can be set at the
// client level
AtomicReference<CosmosExcludedRegions> excludedRegionsAtomicReference = new AtomicReference<>(excludedRegions);
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint("")
.key("")
.preferredRegions(List.of(new String[]{"West US", "East US"}))
.excludedRegionsSupplier(excludedRegionsAtomicReference::get)
.buildAsyncClient();
CosmosAsyncDatabase cosmosAsyncDatabase = client.getDatabase("Test");
CosmosAsyncContainer cosmosAsyncContainer = cosmosAsyncDatabase.getContainer("TestItems");
// Excluded regions can also be set at the request level
CosmosItemRequestOptions cosmosItemRequestOptions = new CosmosItemRequestOptions().setExcludedRegions(List.of("East US"));
TestObject testItem = TestObject.create("mypkValue");
cosmosAsyncContainer.createItem(testItem, cosmosItemRequestOptions).block();
Vyladění konzistence oproti dostupnosti
Funkce vyloučených oblastí poskytuje dodatečný mechanismus pro vyvažování kompromisů mezi konzistencí a dostupností ve vaší aplikaci. Tato funkce je cenná v dynamických scénářích, kdy se požadavky můžou posunout na základě provozních podmínek:
Dynamické zpracování výpadku: Pokud dojde k výpadku primární oblasti a prahové hodnoty jističe na úrovni oddílů nejsou dostatečné, vyloučené oblasti umožňují okamžité převzetí služeb při selhání bez změn kódu nebo restartování aplikace. To poskytuje rychlejší reakci na regionální problémy v porovnání s čekáním na automatickou aktivaci jističe.
Předvolby podmíněné konzistence: Aplikace můžou implementovat různé strategie konzistence na základě provozního stavu:
- Stabilní stav: Stanovení priority konzistentních čtení vyloučením všech oblastí kromě primárního, zajištění konzistence dat za potenciálních nákladů na dostupnost
- Scénáře výpadku: Upřednostnění dostupnosti před striktní konzistencí tím, že umožňuje směrování mezi oblastmi a přijímá potenciální prodlevu dat výměnou za trvalou dostupnost služby
Tento přístup umožňuje externím mechanismům (například správcům provozu nebo nástrojům pro vyrovnávání zatížení) orchestrovat rozhodování o převzetí služeb při selhání, zatímco aplikace udržuje kontrolu nad požadavky na konzistenci prostřednictvím vzorců vyloučení oblastí.
Pokud jsou vyloučeny všechny oblasti, požadavky se směrují do primární nebo centrální oblasti. Tato funkce pracuje se všemi typy požadavků, včetně dotazů, a je užitečná pro udržování instancí klientů typu singleton při dosažení flexibilního chování směrování.
Ladění nastavení přímého a branového připojení
Informace o optimalizaci konfigurací připojení v přímém a bránovém režimu najdete v tématu ladění konfigurací připojení pro sadu Java SDK v4.
Využití sady SDK
- Instalace nejnovější sady SDK
Sady SDK služby Azure Cosmos DB se neustále vylepšují, aby poskytovaly nejlepší výkon. Pokud chcete zjistit nejnovější vylepšení sady SDK, navštivte sadu SDK služby Azure Cosmos DB.
Každá instance klienta Azure Cosmos DB je bezpečná pro přístup z více vláken a provádí efektivní správu připojení a ukládání adres do mezipaměti. Pokud chcete klientům Služby Azure Cosmos DB umožnit efektivní správu připojení a vyšší výkon, důrazně doporučujeme po celou dobu životnosti aplikace používat jednu instanci klienta Služby Azure Cosmos DB.
Když vytvoříte CosmosClient, použije se výchozí konzistence, pokud není explicitně nastavená, a to relace. Pokud konzistence relace není vyžadována logikou vaší aplikace, nastavte konzistenci na Eventuální. Poznámka: Doporučuje se používat alespoň konzistenci relace v aplikacích, které využívají procesor kanálu změn služby Azure Cosmos DB.
- Použití asynchronního rozhraní API k dosažení maximální zřízené propustnosti
Sada Azure Cosmos DB Java SDK v4 má dvě rozhraní API, synchronní a asynchronní. Zhruba řečeno, asynchronní API implementuje funkčnost sady SDK, zatímco synchronní API je tenký obal, který blokuje volání asynchronního API. Na rozdíl od starší verze Azure Cosmos DB Async Java SDK v2, která byla pouze Async-only, a starší verze Azure Cosmos DB Sync Java SDK v2, která byla pouze Sync-only a měla samostatnou implementaci.
Volba rozhraní API je určena během inicializace klienta; CosmosAsyncClient podporuje asynchronní rozhraní API, zatímco CosmosClient podporuje synchronizační rozhraní API.
Asynchronní rozhraní API implementuje neblokující vstupně-výstupní operace a je optimální volbou v případě, že vaším cílem je dosáhnout maximální propustnosti při vydávání požadavků do služby Azure Cosmos DB.
Použití synchronizačního rozhraní API může být správnou volbou, pokud chcete nebo potřebujete rozhraní API, které blokuje odpověď na jednotlivé požadavky nebo pokud je synchronní operace dominantním paradigmatem vaší aplikace. Například můžete chtít rozhraní API pro synchronizaci, když ukládáte data do služby Azure Cosmos DB v aplikaci založené na mikroslužbách, pokud není propustnost kritická.
Všimněte si snížení propustnosti rozhraní API synchronizace s rostoucí dobou odezvy požadavků, zatímco asynchronní rozhraní API může saturovat možnosti plné šířky pásma vašeho hardwaru.
Geografická kolkace vám může poskytnout vyšší a konzistentnější propustnost při použití rozhraní SYNC API (viz Kolacete klienty ve stejné oblasti Azure kvůli výkonu), ale stále se neočekává, že by překročila dosažitelnou propustnost asynchronního rozhraní API.
Někteří uživatelé mohou být také neznalí Project Reactor, což je rozhraní Reactive Streams použité pro implementaci asynchronního rozhraní API sady Java SDK verze 4 pro Azure Cosmos DB. Pokud vás to znepokojuje, doporučujeme přečíst si úvodní Průvodce vzorem Reactor a poté si prohlédnout Úvod do reaktivního programování, abyste se s tím seznámili. Pokud jste už službu Azure Cosmos DB používali s asynchronním rozhraním a sadou SDK, kterou jste použili, byla sada Azure Cosmos DB Async Java SDK v2, možná znáte ReactiveX/RxJava, ale nejste si jistí, co se změnilo v projektu Reactor. V takovém případě se podívejte na naši příručku Reactor vs. RxJava, abyste se seznámili.
Následující fragmenty kódu ukazují, jak inicializovat klienta Azure Cosmos DB pro asynchronní nebo synchronní rozhraní API:
Rozhraní Async API sady Java SDK V4 (Maven com.azure::azure-cosmos)
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- Škálujte klientskou zátěž
Pokud testujete na vysokých úrovních propustnosti, může se klientská aplikace stát kritickým bodem kvůli omezování využití procesoru nebo sítě. Pokud se k tomuto bodu dostanete, můžete pokračovat v rozšiřování účtu Azure Cosmos DB tím, že budete škálovat své klientské aplikace na více serverů.
Dobrým pravidlem je nepřesáhlo >50% využití procesoru na jakémkoli daném serveru, aby byla latence nízká.
- Použití vhodného plánovače (vyhněte se krádeži vláken IO Netty smyčky událostí)
Asynchronní funkce sady Azure Cosmos DB Java SDK je založená na neblokujících vstupně-výstupních operacích netty . SDK používá pevný počet vláken smyčky událostí IO Netty pro výkon vstupně-výstupních operací, podle počtu procesorových jader vašeho počítače. Tok vrácený rozhraním API vygeneruje výsledek na jednom ze sdílených vláken Netty smyčky událostí vstupně-výstupních událostí. Proto je důležité neblokovat sdílená vlákna smyčky událostí Netty (I/O operace). Provádění operací náročných na CPU nebo blokování ve vlákně Netty smyčky událostí pro vstupně-výstupní operace může způsobit zablokování nebo výrazně snížit propustnost SDK.
Například následující kód provede náročnou práci na procesor na vlákně smyčky událostí Netty IO:
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
Po přijetí výsledku byste se měli vyhnout jakékoli práci náročné na procesor na vláknu událostní smyčky IO Netty. Místo toho můžete zadat vlastní plánovač, který vám poskytne vlastní vlákno pro spuštění práce, jak je znázorněno níže (vyžaduje import reactor.core.scheduler.Schedulers).
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
Na základě typu práce byste měli pro svou práci použít odpovídající existující plánovač reactor. Přečtěte si zde Schedulers.
Pokud chcete lépe porozumět modelu vláken a plánování projektu Reactor, přečtěte si tento blogový příspěvek od Project Reactor.
Další informace o sadě Azure Cosmos DB Java SDK v4 najdete v adresáři Azure Cosmos DB monorepo sady Azure SDK pro Javu na GitHubu.
- Optimalizace nastavení protokolování v aplikaci
Z různýchdůvodůch Pokud vaším cílem je plně saturovat zřízenou propustnost kontejneru požadavky vygenerovanými tímto vláknem, optimalizace protokolování můžou výrazně zlepšit výkon.
- Konfigurace asynchronního protokolovacího nástroje
Latence synchronního protokolovacího nástroje nutně ovlivňuje celkový výpočet latence vlákna generujícího požadavek. Asynchronní protokolovací nástroj, jako je log4j2 , se doporučuje oddělit režijní náklady na protokolování od vysoce výkonných vláken aplikace.
- Zakázání protokolování netty
Protokolování knihovny Netty je chatty a je potřeba ho vypnout (potlačení přihlášení nemusí stačit), aby se zabránilo dalším nákladům na procesor. Pokud nejste v režimu ladění, zakažte protokolování Netty úplně. Pokud používáte Log4j ke snížení dodatečných nákladů na procesor vzniklých z práce s knihovnou Netty, přidejte následující řádek do svého kódu:
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- Limit prostředků o otevření souborů operačního systému
Některé systémy Linux (například Red Hat) mají horní limit počtu otevřených souborů, takže celkový počet připojení. Spuštěním následujícího příkazu zobrazte aktuální limity:
ulimit -a
Počet otevřených souborů (nofile) musí být dostatečně velký, aby měl dostatek místa pro nakonfigurovanou velikost fondu připojení a další otevřené soubory operačního systému. Lze upravit tak, aby umožňoval větší velikost připojovacího fondu.
Otevřete soubor limits.conf:
vim /etc/security/limits.conf
Přidejte nebo upravte následující řádky:
* - nofile 100000
- Uveďte klíč oddílu pro jednotlivé zápisy
Pokud chcete zvýšit výkon zápisů bodů, zadejte klíč oddílu položky ve volání rozhraní API pro zápis bodu, jak je znázorněno níže:
Rozhraní Async API sady Java SDK V4 (Maven com::azure-cosmos)
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
Místo poskytnutí pouze instance položky, jak je znázorněno níže:
Rozhraní Async API pro Java SDK V4 (Maven com.azure::azure-cosmos)
asyncContainer.createItem(item).block();
Druhá možnost je podporovaná, ale do vaší aplikace přidá latenci; sada SDK musí analyzovat položku a extrahovat klíč oddílu.
Operace dotazů
Pro operace s dotazy se podívejte na tipy k výkonu dotazů.
Zásady indexování
- Vyloučení nepoužívaných cest z indexování za účelem zrychlení zápisu
Zásady indexování služby Azure Cosmos DB umožňují určit, které cesty k dokumentu se mají zahrnout nebo vyloučit z indexování pomocí cest indexování (setIncludedPaths a setExcludedPaths). Použití cest indexování může nabídnout lepší výkon zápisu a nižší úložiště indexů pro scénáře, ve kterých jsou vzory dotazů známé předem, protože náklady na indexování přímo korelují s počtem indexovaných jedinečných cest. Následující kód například ukazuje, jak zahrnout a vyloučit celé části dokumentů (označované také jako podstrom) z indexování pomocí zástupného znaku "*".
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
Další informace najdete v tématu Zásady indexování služby Azure Cosmos DB.
Propustnost
- Měřte a optimalizujte pro snížení využití jednotek žádostí za sekundu
Azure Cosmos DB nabízí bohatou sadu databázových operací, včetně relačních a hierarchických dotazů s uživatelsky definovanými funkcemi, uloženými procedurami a triggery – všechny tyto operace s dokumenty v rámci databázové kolekce. Náklady spojené s jednotlivými operacemi se liší v závislosti na procesoru, V/V a paměti, které jsou potřeba k dokončení operace. Místo toho, abyste přemýšleli o hardwarových prostředcích a správě hardwarových prostředků, si můžete představit jednotku žádostí (RU) jako jednu míru pro prostředky potřebné k provádění různých databázových operací a žádosti o aplikaci.
Propustnost se zřizuje na základě počtu požadovaných jednotek nastavených pro každý kontejner. Spotřeba jednotek žádosti se vyhodnocuje jako sazba za sekundu. Aplikace, které překročí přidělenou jednotkovou sazbu požadavků pro svůj kontejner, jsou omezeny, dokud rychlost neklesne pod přidělenou úroveň kontejneru. Pokud vaše aplikace vyžaduje vyšší úroveň propustnosti, můžete zvýšit propustnost zřízením dalších jednotek žádostí.
Složitost dotazu má vliv na počet jednotek žádostí spotřebovaných pro operaci. Počet predikátů, povaha predikátů, počet uživatelem definovaných funkcí a velikost sady zdrojových dat ovlivňují náklady na operace dotazu.
Pokud chcete změřit režii jakékoli operace (vytvoření, aktualizace nebo odstranění), zkontrolujte hlavičku x-ms-request-charge a změřte počet jednotek žádostí spotřebovaných těmito operacemi. Můžete se také podívat na ekvivalentní vlastnost RequestCharge v ResourceResponse<T> nebo FeedResponse<T>.
Rozhraní Async API sady Java SDK V4 (Maven com::azure-cosmos)
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
Poplatek za požadavek uvedený v této hlavičce je zlomkem vaší vyhrazené propustnosti. Pokud máte například zřízeno 2000 RU/s a pokud předchozí dotaz vrátí 1 000 dokumentů o velikosti 1 kB, náklady na operaci jsou 1 000. V rámci jedné sekundy server respektuje pouze dva takové požadavky před omezováním rychlosti následných požadavků. Další informace najdete v tématu Jednotky žádostí a kalkulačce jednotek žádostí.
- Řešení omezení rychlosti / příliš velká rychlost požadavků
Když se klient pokusí překročit rezervovanou propustnost pro účet, nedojde na serveru ke snížení výkonu a k žádnému využití kapacity propustnosti nad rámec rezervované úrovně. Server předem ukončí požadavek pomocí requestRateTooLarge (stavový kód HTTP 429) a vrátí hlavičku x-ms-retry-after-ms označující dobu v milisekundách, že uživatel musí před opětovným spuštěním požadavku počkat.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Všechny SDK implicitně zachytí tuto odpověď, respektují serverem zadanou hlavičku 'retry-after' a opakují požadavek. Pokud k vašemu účtu současně nepřistupuje více klientů, bude další opakování úspěšné.
Pokud máte více než jeden klient, který konzistentně pracuje nad rychlostí požadavků, nemusí být výchozí počet opakování aktuálně nastaven na 9 interně klientem; v tomto případě klient vyvolá výjimku CosmosClientException se stavovým kódem 429 pro aplikaci. Výchozí počet opakování lze změnit pomocí setMaxRetryAttemptsOnThrottledRequests()ThrottlingRetryOptions instance. Ve výchozím nastavení se výjimka CosmosClientException se stavovým kódem 429 vrátí po kumulativní době čekání 30 sekund, pokud požadavek nadále funguje nad rychlostí požadavků. K tomu dochází i v případě, že je aktuální počet opakování menší než maximální počet opakování, jedná se o výchozí hodnotu 9 nebo uživatelem definovanou hodnotu.
I když automatizované chování opakování pomáhá zlepšit odolnost a použitelnost pro většinu aplikací, může při provádění srovnávacích testů výkonu přicházet k pravděpodobnosti, zejména při měření latence. Latence pozorovaná klientem se zvýší, pokud experiment dosáhne omezení serveru a způsobí tiché opakování klientské sady SDK. Abyste se vyhnuli špičkám latence během experimentů s výkonem, změřte poplatky vrácené jednotlivými operacemi a zajistěte, aby požadavky fungovaly pod rezervovanou rychlostí požadavků. Další informace najdete v tématu Požadované jednotky.
- Návrh menších dokumentů pro vyšší propustnost
Poplatek za žádost (náklady na zpracování požadavku) dané operace přímo koreluje s velikostí dokumentu. Operace s velkými dokumenty stojí více než operace u malých dokumentů. V ideálním případě můžete aplikaci a pracovní postupy navrhovat tak, aby velikost položky byla ~1 kB nebo podobná. U aplikací citlivých na latenci byste se měli vyhnout velkým položkám – dokumenty s více MB zpomalují vaši aplikaci.
Další kroky
Další informace o návrhu aplikace pro škálování a vysoký výkon najdete v tématu Dělení a škálování ve službě Azure Cosmos DB.
Pokoušíte se naplánovat kapacitu migrace do služby Azure Cosmos DB? Informace o stávajícím databázovém clusteru můžete použít k plánování kapacity.
- Pokud víte pouze počet virtuálních jader a serverů ve vaši stávající databázové skupině, přečtěte si informace o odhadu jednotek žádostí pomocí virtuálních jader nebo virtuálních procesorů.
- Pokud znáte typické sazby požadavků pro vaši aktuální úlohu databáze, přečtěte si informace o odhadu jednotek žádostí pomocí plánovače kapacity služby Azure Cosmos DB.