Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Important
Tipy pro zvýšení výkonu v tomto článku jsou určené jenom pro sadu Python SDK služby Azure Cosmos DB. Další informace najdete v poznámkách k verzi sady Python SDK pro čtení sady Python SDK služby Azure Cosmos DB, balíčku (PyPI), balíčku (Conda) a průvodci odstraňováním potíží.
Azure Cosmos DB je rychlá a flexibilní distribuovaná databáze, která se bezproblémově škáluje s garantovanou latencí a propustností. Nemusíte provádět významné změny architektury ani psát složitý kód pro škálování databáze pomocí služby Azure Cosmos DB. Vertikální navýšení a snížení kapacity je stejně snadné jako vytvoření jediného volání rozhraní API nebo volání metody sady SDK. Vzhledem k tomu, že je služba Azure Cosmos DB přístupná prostřednictvím síťových volání, existují optimalizace na straně klienta, které můžete provést, abyste dosáhli maximálního výkonu při použití sady Python SDK služby Azure Cosmos DB.
Pokud se tedy ptáte, jak můžu zlepšit výkon databáze? zvažte následující možnosti:
Sítě
- Sloučit klienty ve stejné oblasti Azure pro zajištění výkonu
Pokud je to možné, umístěte všechny aplikace, které volají službu Azure Cosmos DB, do stejné oblasti jako databáze Azure Cosmos DB. Pro přibližné porovnání se volání služby Azure Cosmos DB ve stejné oblasti dokončí do 1 až 2 ms, ale latence mezi pobřežím USA – západ a východ je >50 ms. Tato latence se může pravděpodobně lišit od požadavku na požadavek v závislosti na trase, kterou žádost vzala při průchodu z klienta do hranice datacentra Azure. Nejnižší možné latence se dosahuje tím, že se volající aplikace nachází ve stejné oblasti Azure jako zřízený koncový bod služby Azure Cosmos DB. Seznam dostupných oblastí najdete v tématu Oblasti Azure.
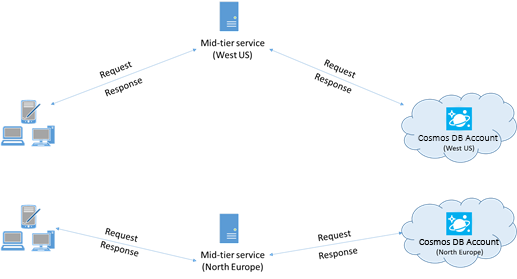
Aplikace, která komunikuje s víceregionálním účtem Azure Cosmos DB, musí nakonfigurovat upřednostňovaná umístění, aby se zajistilo, že požadavky přejdou do přilehlé oblasti.
Povolení akcelerovaných síťových služeb za účelem snížení latence a zpoždění procesoru
Doporučujeme postupovat podle pokynů k povolení akcelerovaných síťových služeb ve Windows (výběrem pokynů) nebo Linuxu (výběrem pokynů) virtuálního počítače Azure za účelem maximalizace výkonu (snížení latence a zpoždění procesoru).
Bez akcelerovaných síťových operací může být vstupně-výstupní operace mezi vaším virtuálním počítačem Azure a dalšími prostředky Azure zbytečně směrována přes hostitele a virtuální přepínač umístěný mezi virtuálním počítačem a jeho síťovou kartou. Když se hostitel a virtuální přepínač nachází přímo v datové cestě, nejen zvyšuje latenci a chvění v komunikačním kanálu, ale také odebírá cykly CPU virtuálnímu počítači. S akcelerovanými síťovými službami rozhraní virtuálních počítačů přímo se síťovým rozhraním bez zprostředkovatelů; veškeré podrobnosti o zásadách sítě, které byly zpracovány hostitelem a virtuálním přepínačem, se nyní zpracovávají v hardwaru síťové karty; hostitel a virtuální přepínač se vynechá. Obecně můžete očekávat nižší latenci a vyšší propustnost, stejně jako konzistentnější latenci a snížení využití procesoru, když povolíte akcelerované síťové služby.
Omezení: Akcelerované síťové služby musí být podporovány v operačním systému virtuálního počítače a dají se povolit jenom v případě, že je virtuální počítač zastavený a uvolněný. Virtuální počítač nejde nasadit pomocí Azure Resource Manageru. Služba App Service nemá povolenou akcelerovanou síť.
Další podrobnosti najdete v pokynech pro Windows a Linux .
Vysoká dostupnost
Obecné pokyny ke konfiguraci vysoké dostupnosti ve službě Azure Cosmos DB najdete v tématu Vysoká dostupnost ve službě Azure Cosmos DB.
Kromě dobrého základního nastavení v databázové platformě je možné jistič na úrovni oddílů implementovat v sadě Python SDK, což může pomoct ve scénářích výpadků. Tato funkce nabízí pokročilé mechanismy pro zajištění dostupnosti, které překračují možnosti opakování mezi regiony, jež jsou ve výchozím nastavení součástí sady SDK. To může výrazně zvýšit odolnost a výkon vaší aplikace, zejména za vysoce zatížených nebo snížených podmínek.
Jistič na úrovni oddílů
Jistič na úrovni oddílů (PPCB) v sadě Python SDK zlepšuje dostupnost a odolnost sledováním stavu jednotlivých fyzických oddílů a směrování požadavků mimo problematické oddíly. Tato funkce je užitečná zejména pro zpracování přechodných a konečných problémů, jako jsou problémy se sítí, upgrady nebo migrace.
PPCB se dá použít v následujících scénářích:
- Jakákoli úroveň konzistence
- Operace s klíčem oddílu (přímé čtení/zápis)
- Účty v jedné oblasti zápisu s několika oblastmi čtení
- Účty pro více regionů zápisu
Jak to funguje
Oddíly procházejí čtyřmi stavy – Zdravý, Nevhodný nezávazně, Nevhodný, a Zdravý nezávazně – na základě úspěchu nebo selhání požadavků:
- Sledování selhání: SDK monitoruje míry chyb (např. 5xx, 408) pro každý oddíl během jedné minuty. SDK sleduje po sobě jdoucí selhání na každý oddíl bez omezení.
- Označení jako nedostupné: Pokud oddíl překročí nakonfigurované prahové hodnoty, označí se jako nezdravý předběžně a vyloučí se ze směrování po dobu 1 minuty.
- Přechod do nepříznivého stavu nebo zotavení: Pokud pokusy o obnovu selžou, oddíl přejde do nefunkčního stavu. Po uplynutí intervalu odstupu se provede sonda zdravotní provizorní s omezeným časovým požadavkem pro určení obnovy.
- Obnova: Pokud průzkumná sonda proběhne úspěšně, oddíl se vrátí do stavu zdravý. Jinak zůstane nezdravý až do další sondy.
Toto převzetí služeb při selhání spravuje sada SDK interně a zajišťuje, aby se požadavky vyhnuly známým problematickým oddílům, dokud se nepotvrdí, že jsou znovu v pořádku.
Konfigurace prostřednictvím proměnných prostředí
Chování PPCB můžete řídit pomocí těchto proměnných prostředí:
| Variable | Description | Výchozí |
|---|---|---|
AZURE_COSMOS_ENABLE_CIRCUIT_BREAKER |
Povolí nebo zakáže PPCB. | false |
AZURE_COSMOS_CONSECUTIVE_ERROR_COUNT_TOLERATED_FOR_READ |
Maximální počet po sobě jdoucích selhání čtení před tím, než je oddíl označen jako nedostupný. | 10 |
AZURE_COSMOS_CONSECUTIVE_ERROR_COUNT_TOLERATED_FOR_WRITE |
Maximální počet po sobě jdoucích selhání zápisu předtím, než je oddíl označen jako nedostupný. | 5 |
AZURE_COSMOS_FAILURE_PERCENTAGE_TOLERATED |
Prahová hodnota procenta selhání před označením oddílu jako nedostupného | 90 |
Tip
Další možnosti konfigurace mohou být zpřístupněny v budoucích verzích, aby bylo možné doladit dobu trvání časového limitu a chování zpětného obnovení.
Vyloučené oblasti
Funkce vyloučených oblastí umožňuje jemně odstupňovanou kontrolu nad směrováním požadavků tím, že umožňuje vyloučit konkrétní oblasti z upřednostňovaných umístění na základě jednotlivých požadavků. Tato funkce je dostupná v sadě Azure Cosmos DB Python SDK verze 4.14.0 a vyšší.
Klíčové výhody:
- Zpracování omezování rychlosti: Při výskytu odpovědí 429 (příliš mnoho požadavků) automaticky směrujte požadavky do alternativních oblastí s dostupnou propustností.
- Cílené směrování: Zajištění obsluhy požadavků z konkrétních oblastí vyloučením všech ostatních
- Vynechat upřednostňované pořadí: Přepsat výchozí seznam upřednostňovaných oblastí pro jednotlivé požadavky bez nutnosti vytvářet samostatné klienty
Configuration:
Vyloučené oblasti je možné nakonfigurovat na úrovni klienta i na úrovni požadavku:
from azure.cosmos import CosmosClient
from azure.cosmos.partition_key import PartitionKey
# Configure preferred locations and excluded locations at client level
preferred_locations = ['West US 3', 'West US', 'East US 2']
excluded_locations_on_client = ['West US 3', 'West US']
client = CosmosClient(
url=HOST,
credential=MASTER_KEY,
preferred_locations=preferred_locations,
excluded_locations=excluded_locations_on_client
)
database = client.create_database('TestDB')
container = database.create_container(
id='TestContainer',
partition_key=PartitionKey(path="/pk")
)
# Create an item (writes ignore excluded_locations in single-region write accounts)
test_item = {
'id': 'Item_1',
'pk': 'PartitionKey_1',
'test_object': True,
'lastName': 'Smith'
}
created_item = container.create_item(test_item)
# Read operations will use preferred_locations minus excluded_locations
# In this example: ['West US 3', 'West US', 'East US 2'] - ['West US 3', 'West US'] = ['East US 2']
item = container.read_item(
item=created_item['id'],
partition_key=created_item['pk']
)
Vyloučené oblasti na úrovni požadavku:
Oblasti vyloučené na úrovni požadavku mají nejvyšší prioritu a přebíjí nastavení na úrovni klienta.
# Excluded locations can be specified per request, overriding client settings
excluded_locations_on_request = ['West US 3']
# Create item with request-level excluded regions
created_item = container.create_item(
test_item,
excluded_locations=excluded_locations_on_request
)
# Read with request-level excluded regions
# This will use: ['West US 3', 'West US', 'East US 2'] - ['West US 3'] = ['West US', 'East US 2']
item = container.read_item(
item=created_item['id'],
partition_key=created_item['pk'],
excluded_locations=excluded_locations_on_request
)
Vyladění konzistence oproti dostupnosti
Funkce vyloučených oblastí poskytuje další mechanismus pro vyvažování kompromisu mezi konzistencí a dostupností ve vaší aplikaci. Tato schopnost je obzvláště cenná v dynamických scénářích, kdy se požadavky můžou posunout na základě provozních podmínek:
Dynamické zpracování výpadku: Pokud dojde k výpadku primární oblasti a prahové hodnoty jističe na úrovni oddílů nejsou dostatečné, vyloučené oblasti umožňují okamžité převzetí služeb při selhání bez změn kódu nebo restartování aplikace. To poskytuje rychlejší reakci na regionální problémy v porovnání s čekáním na automatickou aktivaci jističe.
Předvolby podmíněné konzistence: Aplikace můžou implementovat různé strategie konzistence na základě provozního stavu:
- Stabilní stav: Stanovení priority konzistentních čtení vyloučením všech oblastí kromě primárního, zajištění konzistence dat za potenciálních nákladů na dostupnost
- Scénáře výpadku: Upřednostnění dostupnosti před striktní konzistencí tím, že umožňuje směrování mezi oblastmi a přijímá potenciální prodlevu dat výměnou za trvalou dostupnost služby
Tento přístup umožňuje externím mechanismům (například správcům provozu nebo nástrojům pro vyrovnávání zatížení) orchestrovat rozhodování o převzetí služeb při selhání, zatímco aplikace udržuje kontrolu nad požadavky na konzistenci prostřednictvím vzorců vyloučení oblastí.
Pokud jsou vyloučeny všechny oblasti, budou požadavky směrovány do primární nebo centrální oblasti. Tato funkce funguje se všemi typy požadavků, včetně dotazů, a je zvláště užitečná pro údržbu instancí klienta singleton při dosažení flexibilního chování směrování.
Využití sady SDK
- Instalace nejnovější sady SDK
Sady SDK služby Azure Cosmos DB se neustále vylepšují, aby poskytovaly nejlepší výkon. Podívejte se do poznámek k verzi sady SDK služby Azure Cosmos DB, abyste zjistili nejnovější sadu SDK a zkontrolovali vylepšení.
- Použití jednoúčelového klienta Azure Cosmos DB po celou dobu životnosti vaší aplikace
Každá instance klienta Azure Cosmos DB je bezpečná pro přístup z více vláken a provádí efektivní správu připojení a ukládání adres do mezipaměti. Pokud chcete klientům služby Azure Cosmos DB umožnit efektivní správu připojení a vyšší výkon, doporučujeme po celou dobu životnosti aplikace použít jednu instanci klienta Služby Azure Cosmos DB.
- Doladění konfigurace časového limitu a pokusu o znovu připojení
Konfigurace časového limitu a zásady opakování je možné přizpůsobit na základě potřeb aplikace. Podívejte se do dokumentu o konfiguraci časových limitů a opakování, kde najdete úplný seznam konfigurací, které lze přizpůsobit.
- Použití nejnižší úrovně konzistence vyžadované pro vaši aplikaci
Když vytvoříte CosmosClient, použije se konzistence na úrovni účtu, pokud se při vytváření klienta nezadá žádná. Další informace o úrovních konzistence najdete v dokumentu úrovně konzistence.
- Škálujte klientskou zátěž
Pokud testujete na vysokých úrovních propustnosti, může se klientská aplikace stát kritickým bodem kvůli omezování využití procesoru nebo sítě. Pokud se k tomuto bodu dostanete, můžete pokračovat v rozšiřování účtu Azure Cosmos DB tím, že budete škálovat své klientské aplikace na více serverů.
Dobrým pravidlem je nepřesáhlo >50% využití procesoru na jakémkoli daném serveru, aby byla latence nízká.
- Limit prostředků o otevření souborů operačního systému
Některé systémy Linux (například Red Hat) mají horní limit počtu otevřených souborů, takže celkový počet připojení. Spuštěním následujícího příkazu zobrazte aktuální limity:
ulimit -a
Počet otevřených souborů (nofile) musí být dostatečně velký, aby měl dostatek místa pro nakonfigurovanou velikost fondu připojení a další otevřené soubory operačního systému. Lze upravit tak, aby umožňoval větší velikost připojovacího fondu.
Otevřete soubor limits.conf:
vim /etc/security/limits.conf
Přidejte nebo upravte následující řádky:
* - nofile 100000
Dotazové operace
Operace dotazů najdete v tipech k výkonu dotazů.
Zásady indexování
- Vyloučení nepoužívaných cest z indexování za účelem zrychlení zápisu
Zásady indexování služby Azure Cosmos DB umožňují určit, které cesty k dokumentu se mají zahrnout nebo vyloučit z indexování pomocí cest indexování (setIncludedPaths a setExcludedPaths). Použití cest indexování může nabídnout lepší výkon zápisu a nižší úložiště indexů pro scénáře, ve kterých jsou vzory dotazů známé předem, protože náklady na indexování přímo korelují s počtem indexovaných jedinečných cest. Následující kód například ukazuje, jak zahrnout a vyloučit celé části dokumentů (označované také jako podstrom) z indexování pomocí zástupného znaku "*".
container_id = "excluded_path_container"
indexing_policy = {
"includedPaths" : [ {'path' : "/*"} ],
"excludedPaths" : [ {'path' : "/non_indexed_content/*"} ]
}
db.create_container(
id=container_id,
indexing_policy=indexing_policy,
partition_key=PartitionKey(path="/pk"))
Další informace najdete v tématu Zásady indexování služby Azure Cosmos DB.
Throughput
- Měřte a optimalizujte pro snížení využití jednotek žádostí za sekundu
Azure Cosmos DB nabízí bohatou sadu databázových operací, včetně relačních a hierarchických dotazů s uživatelsky definovanými funkcemi, uloženými procedurami a triggery – všechny tyto operace s dokumenty v rámci databázové kolekce. Náklady spojené s jednotlivými operacemi se liší v závislosti na procesoru, V/V a paměti, které jsou potřeba k dokončení operace. Místo toho, abyste přemýšleli o hardwarových prostředcích a správě hardwarových prostředků, si můžete představit jednotku žádostí (RU) jako jednu míru pro prostředky potřebné k provádění různých databázových operací a žádosti o aplikaci.
Propustnost se zřizuje na základě počtu požadovaných jednotek nastavených pro každý kontejner. Spotřeba jednotek žádosti se vyhodnocuje jako sazba za sekundu. Aplikace, které překročí přidělenou jednotkovou sazbu požadavků pro svůj kontejner, jsou omezeny, dokud rychlost neklesne pod přidělenou úroveň kontejneru. Pokud vaše aplikace vyžaduje vyšší úroveň propustnosti, můžete zvýšit propustnost zřízením dalších jednotek žádostí.
Složitost dotazu má vliv na počet jednotek žádostí spotřebovaných pro operaci. Počet predikátů, povaha predikátů, počet uživatelem definovaných funkcí a velikost sady zdrojových dat ovlivňují náklady na operace dotazu.
Pokud chcete změřit režii jakékoli operace (vytvoření, aktualizace nebo odstranění), zkontrolujte hlavičku x-ms-request-charge a změřte počet jednotek žádostí spotřebovaných těmito operacemi.
document_definition = {
'id': 'document',
'key': 'value',
'pk': 'pk'
}
document = container.create_item(
body=document_definition,
)
print("Request charge is : ", container.client_connection.last_response_headers['x-ms-request-charge'])
Poplatek za požadavek uvedený v této hlavičce je zlomkem vaší vyhrazené propustnosti. Pokud máte například poskytnuto 2000 RU/s a pokud předchozí dotaz vrátí 1000 1kB-dokumentů, operace stojí 1000. V rámci jedné sekundy server respektuje pouze dva takové požadavky před omezováním rychlosti následných požadavků. Další informace najdete v tématu Jednotky žádostí a kalkulačce jednotek žádostí.
- Řešení omezení rychlosti / příliš velká rychlost požadavků
Když se klient pokusí překročit rezervovanou propustnost pro účet, nedojde na serveru ke snížení výkonu a k žádnému využití kapacity propustnosti nad rámec rezervované úrovně. Server předem ukončí požadavek pomocí requestRateTooLarge (stavový kód HTTP 429) a vrátí hlavičku x-ms-retry-after-ms označující dobu v milisekundách, že uživatel musí před opětovným spuštěním požadavku počkat.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Všechny SDK implicitně zachytí tuto odpověď, respektují serverem zadanou hlavičku 'retry-after' a opakují požadavek. Pokud k vašemu účtu současně nepřistupuje více klientů, bude další opakování úspěšné.
Pokud máte více než jeden klient, který konzistentně pracuje nad rychlostí požadavků, nemusí být výchozí počet opakování aktuálně nastaven na 9 interně klientem; v tomto případě klient vyvolá do aplikace chybu CosmosHttpResponseError se stavovým kódem 429. Výchozí počet opakování lze změnit předáním retry_total konfigurace klientovi. Defaultně se CosmosHttpResponseError se stavovým kódem 429 vrátí po kumulativní době čekání 30 sekund, pokud požadavek nadále běží nad povolenou sazbou požadavků. K tomu dochází i v případě, že je aktuální počet opakování menší než maximální počet opakování, jedná se o výchozí hodnotu 9 nebo uživatelem definovanou hodnotu.
I když automatizovaný proces opakování pomáhá zlepšit odolnost a použitelnost pro většinu aplikací, může při provádění srovnávacích testů výkonu narazit na problémy, zejména při měření latence. Latence pozorovaná klientem se zvýší, pokud experiment narazí na omezení serveru a způsobí, že SDK klienta automaticky zopakuje pokus, aniž by si toho uživatel všiml. Abyste se vyhnuli špičkám latence během experimentů s výkonem, změřte poplatky vrácené jednotlivými operacemi a zajistěte, aby požadavky fungovaly pod rezervovanou rychlostí požadavků. Další informace najdete v tématu Požadované jednotky.
- Návrh menších dokumentů pro vyšší propustnost
Poplatek za žádost (náklady na zpracování požadavku) dané operace přímo koreluje s velikostí dokumentu. Operace s velkými dokumenty stojí více než operace u malých dokumentů. V ideálním případě můžete aplikaci a pracovní postupy navrhovat tak, aby velikost položky byla ~1 kB nebo podobná. U aplikací citlivých na latenci byste se měli vyhnout velkým položkám – dokumenty s více MB budou vaši aplikaci zpomalovat.
Další kroky
Další informace o návrhu aplikace pro škálování a vysoký výkon najdete v tématu Dělení a škálování ve službě Azure Cosmos DB.
Pokoušíte se naplánovat kapacitu migrace do služby Azure Cosmos DB? Informace o stávajícím databázovém clusteru můžete použít k plánování kapacity.
- Pokud znáte pouze počet virtuálních jader a serverů ve vašem existujícím databázovém klastru, přečtěte si informace o odhadu jednotek žádostí pomocí virtuálních jader nebo virtuálních procesorů.
- Pokud znáte typické sazby požadavků pro vaši aktuální úlohu databáze, přečtěte si informace o odhadu jednotek žádostí pomocí plánovače kapacity služby Azure Cosmos DB.