Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Cassandra
Cassandra
![]() Skřítek
Skřítek
![]() Stůl
Stůl
Tento článek popisuje osvědčené postupy a strategie škálování propustnosti databáze nebo kontejneru (kolekce, tabulky nebo grafu). Tyto koncepty platí, když zvýšíte počet zřízených jednotek ručních žádostí za sekundu (RU/s) nebo maximální počet RU/s libovolného prostředku libovolného prostředku pro rozhraní API služby Azure Cosmos DB.
Požadavky
- Pokud s dělením a škálováním ve službě Azure Cosmos DB začínáte, přečtěte si téma Dělení a horizontální škálování ve službě Azure Cosmos DB.
- Pokud plánujete škálovat ru/s kvůli 429 výjimkám, projděte si pokyny v tématu Diagnostika a řešení potíží s výjimkami typu Příliš vysoká frekvence požadavků (429). Než zvýšíte počet RU/s, identifikujte původní příčinu problému a zjistěte, jestli je správným řešením zvýšení POČTU RU/s.
Pozadí škálování RU/s
Když odešlete požadavek na navýšení počtu RU/s databáze nebo kontejneru v závislosti na požadovaném počtu RU/s a aktuálním rozložení fyzického oddílu, operace vertikálního navýšení kapacity se buď okamžitě nebo asynchronně dokončí (obvykle 4 až 6 hodin).
Okamžité vertikální navýšení kapacity:
- Pokud požadovaná RU/s může být podporována aktuálním rozložením fyzického oddílu, Azure Cosmos DB nemusí rozdělovat ani přidávat nové oddíly.
- V důsledku toho se operace okamžitě dokončí a RU/s jsou k dispozici k použití.
Asynchronní vertikální navýšení kapacity:
- Pokud jsou požadované RU/s vyšší, než je možné v rozložení fyzického oddílu podporovat, Azure Cosmos DB rozdělí existující fyzické oddíly. K tomu dochází, dokud prostředek nebude mít minimální počet oddílů potřebných pro podporu požadované hodnoty RU/s.
- V důsledku toho může dokončení operace nějakou dobu trvat, obvykle 4 až 6 hodin. Každý fyzický oddíl může podporovat maximálně 10 000 RU/s (platí pro všechna rozhraní API) propustnosti a 50 GB úložiště (platí pro všechna rozhraní API s výjimkou Cassandry, která má 30 GB úložiště).
Poznámka:
Pokud provedete operaci zápisu nebopřidáte nebo odeberete novou oblast , zatímco probíhá asynchronní operace vertikálního navýšení kapacity, operace vertikálního navýšení kapacity propustnosti se pozastaví. Po dokončení operace převzetí služeb při selhání nebo přidání nebo odebrání oblasti se obnoví automaticky.
Okamžité vertikální snížení kapacity:
- Pro operaci vertikálního snížení kapacity azure Cosmos DB není potřeba rozdělit ani přidávat nové oddíly.
- V důsledku toho se operace okamžitě dokončí a RU/s jsou k dispozici k použití.
- Klíčovým výsledkem této operace je snížení počtu RU na fyzický oddíl.
Vertikální navýšení kapacity RU/s beze změny rozložení oddílů
Krok 1: Vyhledání aktuálního počtu fyzických oddílů
Přejděte na >>normalizované spotřeby RU (%) podle PartitionKeyRangeID. Spočítejte jedinečný počet PartitionKeyRangeIds.
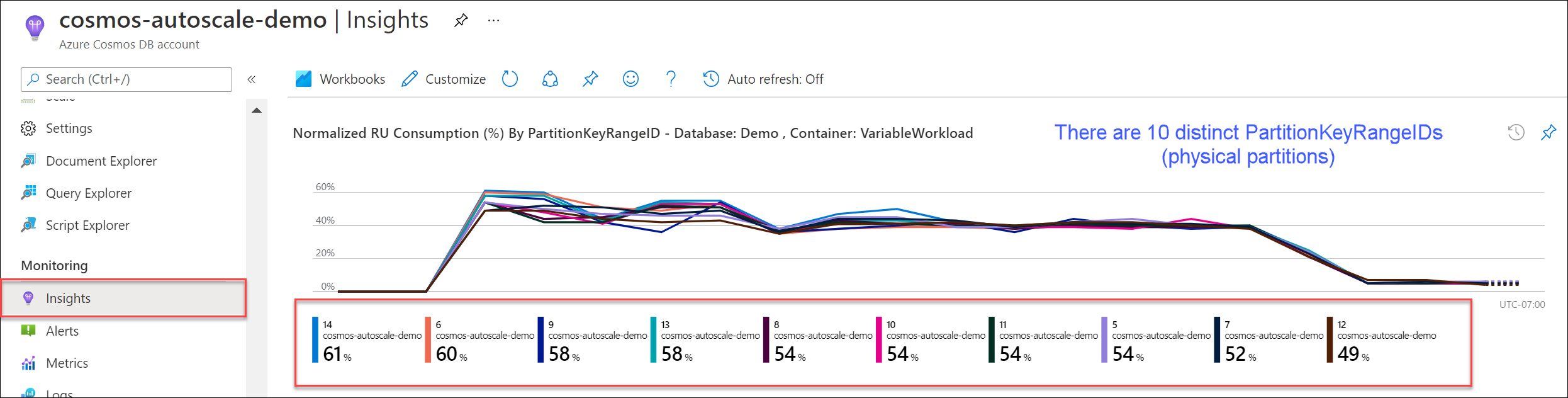
Poznámka:
Graf zobrazuje maximálně 50 PartitionKeyRangeIds. Pokud má váš prostředek více než 50, můžete pomocí rozhraní REST API služby Azure Cosmos DB spočítat celkový počet oddílů.
Každý PartitionKeyRangeId se mapuje na jeden fyzický oddíl a je přiřazen k uložení dat pro rozsah možných hodnot hash.
Azure Cosmos DB distribuuje vaše data napříč logickými a fyzickými oddíly na základě klíče oddílu, aby bylo možné horizontální škálování. Při zápisu dat azure Cosmos DB používá hodnotu hash klíče oddílu k určení logického a fyzického oddílu, ve kterém se data nacházejí.
Krok 2: Výpočet výchozí maximální propustnosti
Nejvyšší počet RU/s, které můžete škálovat bez aktivace služby Azure Cosmos DB pro rozdělení oddílů, se rovná Current number of physical partitions * 10,000 RU/s.
Tuto hodnotu můžete získat od poskytovatele prostředků Azure Cosmos DB. Proveďte požadavek GET na objekty nastavení propustnosti databáze nebo kontejneru a načtěte instantMaximumThroughput vlastnost. Tato hodnota je dostupná také na stránce Škálování a nastavení databáze nebo kontejneru na portálu.
Příklad
Předpokládejme, že máte existující kontejner s pěti fyzickými oddíly a 30 000 RU/s ruční zřízené propustnosti. Počet RU/s 5 * 10,000 RU/s = 50,000 RU/s můžete okamžitě zvýšit. Podobně pokud bychom měli kontejner s maximálním maximálním limitem RU/s automatického škálování 30 000 RU/s (škáluje se mezi 3000 až 30 000 RU/s), mohli bychom naše maximální počet RU/s okamžitě zvýšit na 50 000 RU/s (škáluje se mezi 5000 až 50 000 RU/s).
Tip
Pokud vertikálně navýšíte počet RU/s tak, aby reagoval na příliš velké výjimky (429), doporučujeme nejprve zvýšit počet RU/s na nejvyšší počet RU/s, které jsou podporovány aktuálním rozložením fyzického oddílu, a posoudit, jestli nové RU/s nestačí, a teprve potom zvýšit úroveň.
Jak zajistit rovnoměrnou distribuci dat během asynchronního škálování
Pozadí
Když zvýšíte počet RU/s nad aktuální počet physical partitions * 10,000 RU/soddílů , Azure Cosmos DB rozdělí existující oddíly, dokud nový počet oddílů = ROUNDUP(requested RU/s / 10,000 RU/s). Během rozdělení jsou nadřazené oddíly rozdělené do dvou podřízených oddílů.
Předpokládejme například, že máte kontejner se třemi fyzickými oddíly a 30 000 RU/s ruční zřízené propustnosti. Pokud zvýšíte propustnost na 45 000 RU/s, Azure Cosmos DB rozdělí dva z existujících fyzických oddílů tak, aby celkem existovaly ROUNDUP(45,000 RU/s / 10,000 RU/s) = 5 physical partitions.
Poznámka:
Aplikace můžou během dělení vždy přijímat a dotazovat data. Klientské sady SDK a služba Azure Cosmos DB tento scénář automaticky zpracovávají a zajišťují, aby se požadavky směrovaly do správného fyzického oddílu, takže není nutná žádná jiná akce uživatele.
Pokud máte úlohu, která se rovnoměrně distribuuje s ohledem na svazek úložiště a požadavků – obvykle se provádí dělením podle polí s vysokou kardinalitou, jako /idje – doporučuje se nastavit RU/s tak, aby se všechny oddíly rovnoměrně rozdělily při vertikálním navýšení kapacity.
Podívejme se, proč si ukážeme příklad, kdy máte existující kontejner se dvěma fyzickými oddíly, 20 000 RU/s a 80 GB dat.
Díky výběru vhodného klíče oddílu s vysokou kardinalitou se data zhruba rovnoměrně distribuují v obou fyzických oddílech. Každému fyzickému oddílu je přiřazeno přibližně 50 % prostoru klíčů, který je definován jako celkový rozsah možných hodnot hash.
Kromě toho Azure Cosmos DB distribuuje RU/s rovnoměrně napříč všemi fyzickými oddíly. V důsledku toho má každý fyzický oddíl 10 000 RU/s a 50 % (40 GB) celkových dat. Následující diagram znázorňuje náš aktuální stav.

Předpokládejme, že chcete zvýšit počet RU/s z 20 000 RU/s na 30 000 RU/s.
Pokud jednoduše zvýšíte počet RU/s na 30 000 RU/s, rozdělí se jenom jeden oddíl. Po rozdělení máte:
- Jeden oddíl, který obsahuje 50% dat (tento oddíl nebyl rozdělený).
- Dva oddíly, které obsahují 25% dat každé (jedná se o výsledné podřízené oddíly z nadřazené položky, která byla rozdělena).
Vzhledem k tomu, že Azure Cosmos DB rovnoměrně distribuuje RU/s napříč všemi fyzickými oddíly, každý fyzický oddíl stále získá 10 000 RU/s. Teď ale máte nerovnoměrnou distribuci úložiště a požadavků.
V následujícím diagramu mají oddíly 3 a 4 (podřízené oddíly oddílu 2) 10 000 RU/s, které obsluhují požadavky na 20 GB dat, zatímco Oddíl 1 má 10 000 RU/s, aby mohl obsloužit žádosti o dvojnásobek objemu dat (40 GB).

Pokud chcete zachovat rovnoměrnou distribuci úložiště, můžete nejprve vertikálně navýšit kapacitu RU/s, abyste zajistili rozdělení všech oddílů. Pak můžete snížit počet RU/s zpět do požadovaného stavu.
Pokud tedy začnete se dvěma fyzickými oddíly, abyste zajistili, že oddíly jsou i po rozdělení, musíte nastavit RU/s tak, abyste skončili se čtyřmi fyzickými oddíly. Chcete-li toho dosáhnout, první set RU/s = 4 * 10,000 RU/s per partition = 40,000 RU/s. Po dokončení rozdělení snižte počet RU/s na 30 000 RU/s.
Každý fyzický oddíl tak získá 30,000 RU/s / 4 = 7500 RU/s požadavky na 20 GB dat. Celkově udržujete rovnoměrné úložiště a distribuci požadavků napříč oddíly.
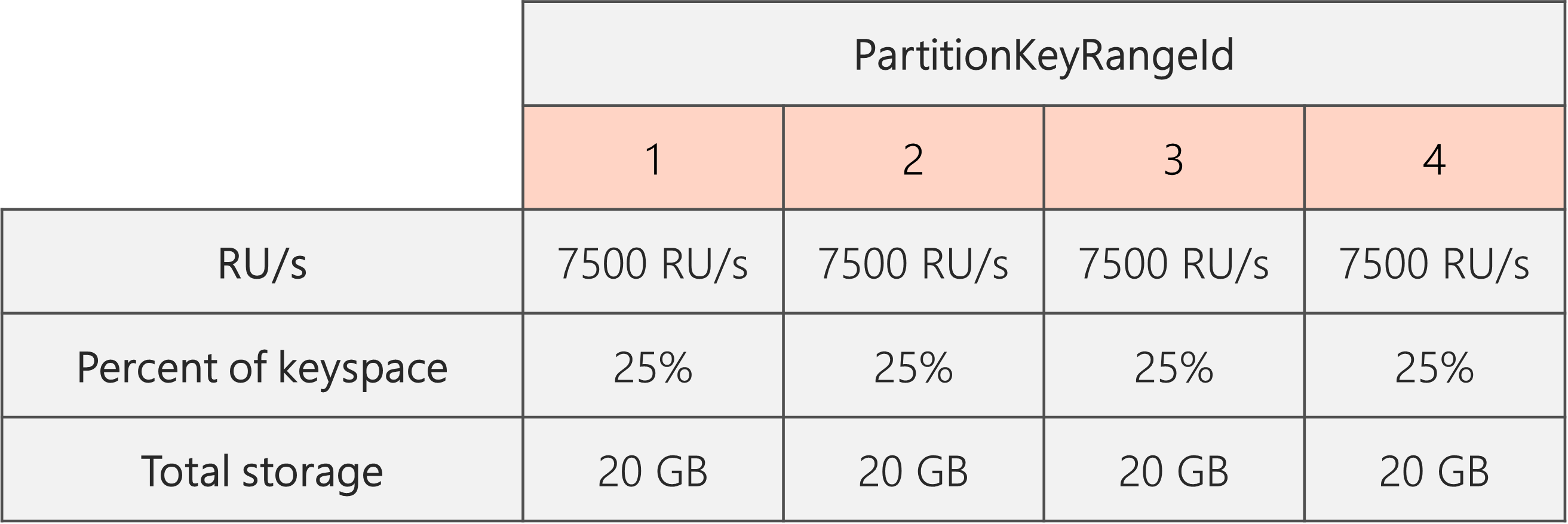
Obecný vzorec
Krok 1: Zvyšte počet RU/s, abyste zajistili rovnoměrné rozdělení všech oddílů
Obecně platí, že pokud máte počáteční počet fyzických oddílů Pa chcete nastavit požadované RU/s S:
Zvyšte počet RU/s na: 10,000 * P * (2 ^ (ROUNDUP(LOG_2 (S/(10,000 * P)))). Tím získáte nejbližší POČET RU/s k požadované hodnotě, která zajistí rovnoměrné rozdělení všech oddílů.
Poznámka:
Když zvýšíte počet RU/s databáze nebo kontejneru, může to mít vliv na minimální počet RU/s, které můžete v budoucnu snížit. Minimální počet RU/s se obvykle rovná MAX(400 RU/s, Current storage in GB * 1 RU/s, Highest RU/s ever provisioned / 100). Pokud je například nejvyšší počet RU/s, na který jste kdy škálovali, 100 000 RU/s, nejnižší POČET RU/s, které můžete nastavit v budoucnu, je 1000 RU/s. Přečtěte si další informace o minimálních RU/s.
Krok 2: Snížení počtu RU/s na požadované RU/s
Předpokládejme například, že máme pět fyzických oddílů, 50 000 RU/s a chceme škálovat na 150 000 RU/s. Nejprve bychom měli nastavit: 10,000 * 5 * (2 ^ (ROUND(LOG_2(150,000/(10,000 * 5)))) = 200,000 RU/sa pak snížit na 150 000 RU/s.
Když jsme vertikálně nastavili kapacitu až 200 000 RU/s, nejnižší ruční POČET RU/s, které teď můžeme nastavit v budoucnu, je 2000 RU/s. Nejnižší maximální počet RU/s automatického škálování, který můžeme nastavit, je 20 000 RU/s (škálování mezi 2000 až 20 000 RU/s). Vzhledem k tomu, že naše cílová RU/s je 150 000 RU/s, nemáme vliv na minimální počet RU/s.
Optimalizace RU/s pro příjem velkých objemů dat
Pokud plánujete migrovat nebo ingestovat velké množství dat do služby Azure Cosmos DB, doporučujeme nastavit RU/s kontejneru tak, aby služba Azure Cosmos DB předem zřídila fyzické oddíly potřebné k uložení celkového množství dat, která plánujete předem ingestovat. V opačném případě může azure Cosmos DB během příjmu dat muset rozdělit oddíly, které přidají více času k příjmu dat.
Můžeme využít skutečnost, že během vytváření kontejneru azure Cosmos DB používá heuristický vzorec spouštění RU/s k výpočtu počtu fyzických oddílů, se kterými se má začít.
Krok 1: Kontrola výběru klíče oddílu
Při výběru klíče oddílu postupujte podle osvědčených postupů , abyste měli jistotu, že máte i distribuci svazku požadavků a úložiště po migraci.
Krok 2: Výpočet počtu fyzických oddílů, které potřebujete
Number of physical partitions = Total data size in GB / Target data per physical partition in GB
Každý fyzický oddíl může obsahovat maximálně 50 GB úložiště (30 GB pro rozhraní API pro Cassandra). Hodnota, kterou byste měli zvolit pro cílová data na fyzický oddíl v GB , závisí na tom, jak mají být fyzické oddíly plně zabalené a kolik očekáváte, že úložiště po migraci poroste.
Pokud například očekáváte, že se úložiště bude dál rozšiřovat, můžete nastavit hodnotu na 30 GB. Za předpokladu, že jste zvolili dobrý klíč oddílu, který rovnoměrně distribuuje úložiště, je každý oddíl přibližně 60% plný (30 GB z 50 GB). Při zápisu budoucích dat je možné je uložit do existující sady fyzických oddílů, aniž by služba vyžadovala okamžité přidání dalších fyzických oddílů.
Pokud se naopak domníváte, že se úložiště po migraci výrazně nezvětší, můžete nastavit vyšší hodnotu, například 45 GB. To znamená, že každý oddíl je přibližně 90% plný (45 GB z 50 GB). Tím se minimalizuje počet fyzických oddílů, mezi kterými jsou vaše data rozložená, což znamená, že každý fyzický oddíl může získat větší část celkového zřízeného POČTU RU/s.
Krok 3: Výpočet počtu RU/s pro všechny oddíly
Starting RU/s for all partitions = Number of physical partitions * Initial throughput per physical partition
Začněme příkladem s libovolným počtem cílových RU/s na fyzický oddíl.
-
Initial throughput per physical partition = 10,000 RU/s per physical partitionpři použití automatického škálování nebo databází se sdílenou propustností -
Initial throughput per physical partition = 6000 RU/s per physical partitionpři použití ruční propustnosti
Příklad
Řekněme, že máte 1 TB (1 000 GB) dat k ingestování a chcete použít ruční propustnost. Každý fyzický oddíl ve službě Azure Cosmos DB má kapacitu 50 GB. Předpokládejme, že se snažíte zabalit oddíly na 80% (40 GB), takže ponecháte prostor pro budoucí růst.
To znamená, že pro 1 TB dat potřebujete 1000 GB / 40 GB = 25 fyzické oddíly. Abyste měli jistotu, že získáte 25 fyzických oddílů pomocí ruční propustnosti, nejprve zřídíte 25 * 6000 RU/s = 150,000 RU/s. Potom po vytvoření kontejneru zvyšte počet RU/s na 250 000 RU/s před zahájením příjmu dat (k ingestování dojde okamžitě, protože už máte 25 fyzických oddílů). Každý oddíl tak získá maximálně 10 000 RU/s.
Pokud používáte propustnost automatického škálování nebo databázi se sdílenou propustností, abyste získali 25 fyzických oddílů, nejprve byste zřídili 25 * 10,000 RU/s = 250,000 RU/s. Protože už máte nejvyšší počet RU/s, které je možné podporovat s 25 fyzickými oddíly, nezvětšíte naše zřízené RU/s před příjmem dat.
Teoreticky, s 250 000 RU/s a 1 TB dat, pokud předpokládáme, že 1kb dokumenty a 10 RU potřebných pro zápis, může příjem dat teoreticky dokončit: 1000 GB * (1,000,000 kb / 1 GB) * (1 document / 1 kb) * (10 RU / document) * (1 sec / 250,000 RU) * (1 hour / 3600 seconds) = 11.1 hours.
Tento výpočet představuje odhad za předpokladu, že klient provádějící příjem dat může plně saturovat propustnost a distribuovat zápisy napříč všemi fyzickými oddíly. Osvědčeným postupem je prohazování dat na straně klienta. Tím se zajistí, že každý druhý klient zapisuje do mnoha různých logických (a tedy fyzických) oddílů.
Po dokončení migrace můžete snížit počet RU/s nebo podle potřeby povolit automatické škálování.