Diagnostika a řešení potíží s výjimkami kvůli příliš vysoké frekvenci požadavků (429) ve službě Azure Cosmos DB
PLATÍ PRO: ![]() NoSQL
NoSQL
Tento článek obsahuje známé příčiny a řešení pro různé chyby stavového kódu 429 pro rozhraní API for NoSQL. Pokud používáte rozhraní API pro MongoDB, přečtěte si článek o ladění stavového kódu 16500 v článku Řešení běžných problémů s rozhraním API for MongoDB .
Výjimka "Příliš velká frekvence požadavků", označovaná také jako kód chyby 429, značí, že vaše požadavky na službu Azure Cosmos DB jsou omezené rychlostí.
Když použijete zřízenou propustnost, nastavíte propustnost měřenou v jednotkách požadavků za sekundu (RU/s) vyžadovanou pro vaši úlohu. Databázové operace se službou, jako jsou čtení, zápisy a dotazy, spotřebovávají určitý počet jednotek žádostí (RU). Přečtěte si další informace o jednotkách žádostí.
Pokud operace spotřebovávají více než zřízené jednotky žádostí, azure Cosmos DB v dané sekundě vrátí výjimku 429. Za každou sekundu se resetuje počet jednotek žádostí, které je možné použít.
Před provedením akce ke změně RU/s je důležité pochopit původní příčinu omezování rychlosti a vyřešit související problém.
Tip
Pokyny v tomto článku platí pro databáze a kontejnery využívající zřízenou propustnost – automatické škálování i ruční propustnost.
Existují různé chybové zprávy, které odpovídají různým typům výjimek 429:
- Frekvence požadavků je příliš vysoká. Může být potřeba více jednotek žádostí, takže nebyly provedeny žádné změny.
- Požadavek se nedokončil kvůli vysokému počtu požadavků na metadata.
- Požadavek se nedokončil kvůli přechodné chybě služby.
Frekvence požadavků je velká.
To je nejčastější scénář. Dochází k tomu, když jednotky žádostí spotřebované operacemi s daty překračují zřízený počet RU/s. Pokud používáte ruční propustnost, dojde k tomu v případě, že jste spotřebovali více RU/s, než je zřízená ruční propustnost. Pokud používáte automatické škálování, dojde k tomu v případě, že jste spotřebovali více než maximální počet zřízených RU/s. Pokud máte například prostředek zřízený s ruční propustností 400 RU/s, uvidíte 429, když během jedné sekundy spotřebujete více než 400 jednotek žádostí. Pokud máte zřízený prostředek s maximálním maximálním limitem RU/s automatického škálování 4000 RU/s (škálování mezi 400 RU/s – 4000 RU/s), uvidíte 429 odpovědí, když spotřebujete více než 4 000 jednotek žádostí za jednu sekundu.
Tip
Všechny operace se účtují na základě počtu prostředků, které spotřebovávají. Tyto poplatky se měří v jednotkách žádostí. Mezi tyto poplatky patří žádosti, které se úspěšně nedokončí kvůli chybám aplikace, jako 400jsou , 412, 449atd. Při pohledu na omezování nebo využití je vhodné zjistit, jestli se ve vašem využití změnil nějaký vzor, což by vedlo ke zvýšení těchto operací. Konkrétně zkontrolujte značky 412 nebo 449 (skutečný konflikt).
Další informace o zřízené propustnosti najdete v tématu Zřízená propustnost ve službě Azure Cosmos DB.
Krok 1: Zkontrolujte metriky a určete procento požadavků s chybou 429.
Zobrazení chybových zpráv 429 nemusí nutně znamenat problém s databází nebo kontejnerem. Malé procento 429 odpovědí je normální bez ohledu na to, jestli používáte propustnost ručního nebo automatického škálování, a je to znamení, že maximalizujete počet zřízených RU/s.
Postup prošetřování
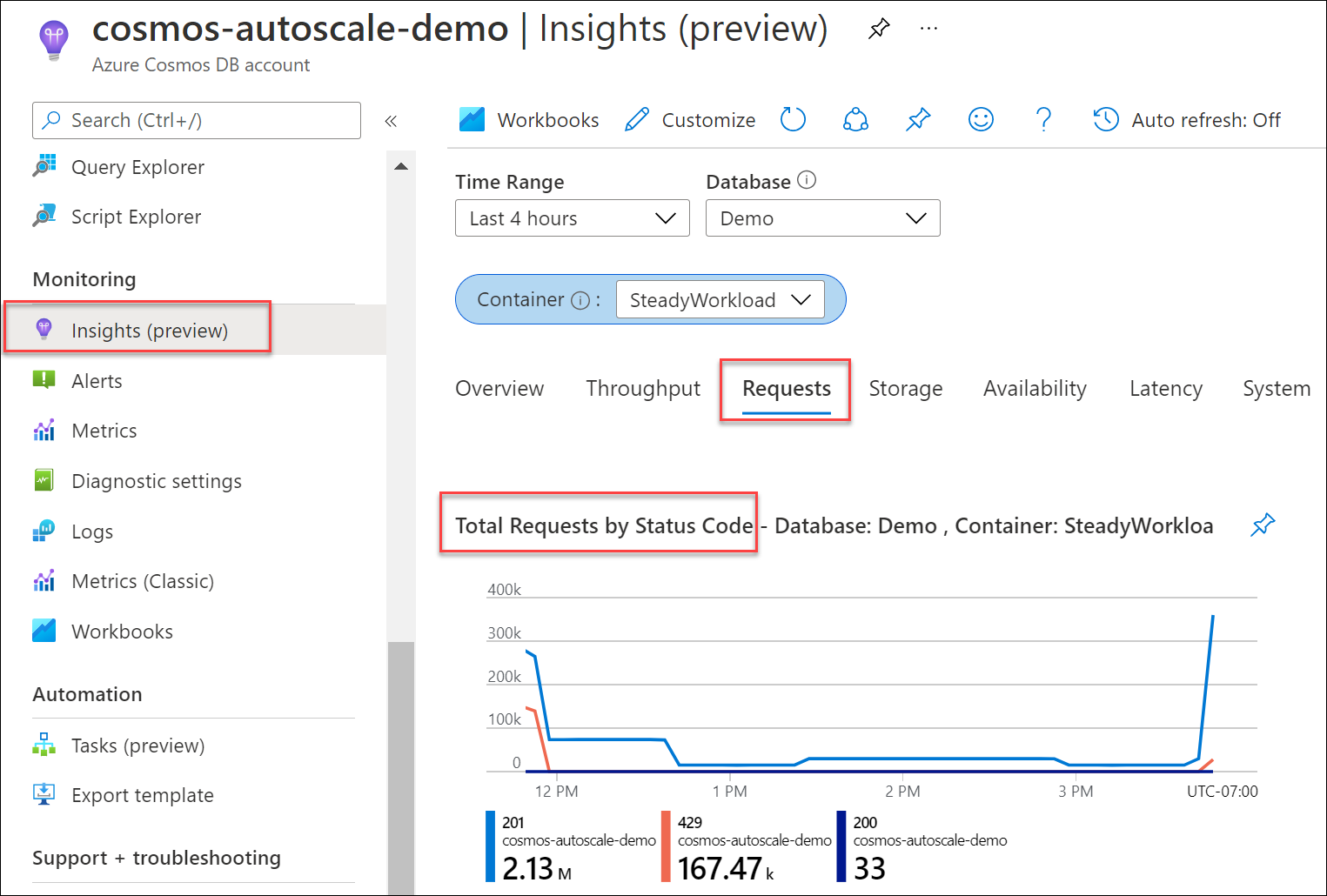
V porovnání s celkovým počtem úspěšných požadavků určete procento vašich požadavků na databázi nebo kontejner, které způsobily 429 odpovědí. Ze svého účtu služby Azure Cosmos DB přejděte do části Žádosti Insights Total Requests by Status Code.< a1/> (Celkový počet žádostí>o přehledy>podle stavového kódu). Vyfiltrujte konkrétní databázi a kontejner.
Klientské sady SDK služby Azure Cosmos DB a nástroje pro import dat, jako je Azure Data Factory a knihovna bulk Executor, ve výchozím nastavení automaticky opakují požadavky na 429. Obvykle se opakují až devětkrát. V důsledku toho se v metrikách může zobrazit 429 odpovědí, ale tyto chyby se nemusí vrátit ani do vaší aplikace.
Doporučené řešení
Obecně platí, že pokud u produkční úlohy dochází mezi 1 až 5 % požadavků s 429 odpověďmi a celková latence je přijatelná, je to signál, že ru/s jsou plně využité. Není vyžadována žádná akce. V opačném případě přejděte k dalším krokům řešení potíží.
Důležité
Tento rozsah 1–5 % předpokládá rovnoměrné rozdělení oddílů vašeho účtu. Pokud vaše oddíly nejsou rovnoměrně distribuované, může váš problémový oddíl vrátit velké množství chyb 429, zatímco celková míra může být nízká.
Pokud používáte automatické škálování, je možné v databázi nebo kontejneru zobrazit 429 odpovědí, a to i v případě, že počet RU/s nebyl škálován na maximální počet RU/s. Vysvětlení najdete v části Frekvence požadavků s automatickým škálováním .
Jednou z běžných otázek, ke kterým dochází, je: "Proč se v metrikách služby Azure Monitor zobrazuje 429 odpovědí, ale žádné ve vlastním monitorování aplikací?" Pokud metriky Služby Azure Monitor ukazují, že máte 429 odpovědí, ale ve své vlastní aplikaci jste žádné neviděli, je to proto, že ve výchozím nastavení se klientské sady SDK automatically retried internally on the 429 responses služby Azure Cosmos DB a požadavek v následných opakováních úspěšně dokončil. V důsledku toho se stavový kód 429 nevrátí do aplikace. V těchto případech je celková míra 429 odpovědí obvykle minimální a dá se bezpečně ignorovat, za předpokladu, že celková míra je mezi 1–5 % a koncovou latencí je pro vaši aplikaci přijatelná.
Krok 2: Určení, jestli existuje horký oddíl
Horký oddíl vznikne, když jeden nebo několik logických klíčů oddílu spotřebovává nepřiměřenou částku celkového počtu RU/s z důvodu vyššího objemu požadavků. Příčinou může být návrh klíče oddílu, který nedistribuuje žádosti rovnoměrně. Výsledkem je, že mnoho požadavků je směrováno na malou podmnožinu logických (což znamená fyzické) oddíly, které se stanou "horkými". Vzhledem k tomu, že všechna data logického oddílu se nacházejí v jednom fyzickém oddílu a celkový počet RU/s je rovnoměrně rozdělený mezi fyzické oddíly, může horký oddíl vést k 429 odpovědím a neefektivnímu využití propustnosti.
Tady je několik příkladů strategií dělení, které vedou k horkým oddílům:
- Máte kontejner, který ukládá data zařízení IoT pro úlohy náročné na zápis, který je rozdělený na oddíly
date. Všechna data pro jedno datum se budou nacházet ve stejném logickém a fyzickém oddílu. Vzhledem k tomu, že všechna data zapsaná každý den mají stejné datum, výsledkem by byl každý den horký oddíl.- Místo toho se v tomto scénáři jedná o klíč oddílu, jako je
ididentifikátor GUID nebo ID zařízení, nebo kombinaci syntetického klíčeidoddílu, kterýdateby přinesl vyšší kardinalitu hodnot a lepší distribuci svazku požadavků.
- Místo toho se v tomto scénáři jedná o klíč oddílu, jako je
- Máte scénář s více tenanty s kontejnerem rozděleným na oddíly
tenantId. Pokud je jeden tenant mnohem aktivnější než druhý, výsledkem je horký oddíl. Pokud má například největší tenant 100 000 uživatelů, ale většina tenantů má méně než 10 uživatelů, při dělení natenantIDoddíly budete mít horký oddíl .- V tomto předchozím scénáři zvažte vytvoření vyhrazeného kontejneru pro největšího tenanta rozděleného podle podrobnější vlastnosti, například
UserId.
- V tomto předchozím scénáři zvažte vytvoření vyhrazeného kontejneru pro největšího tenanta rozděleného podle podrobnější vlastnosti, například
Identifikace horkého oddílu
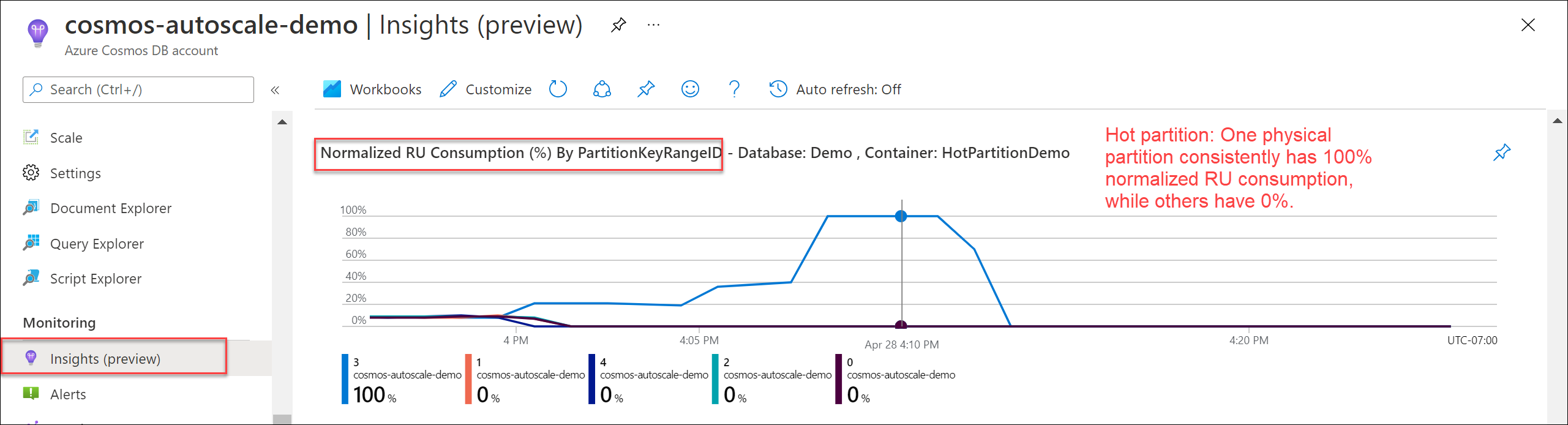
Pokud chcete ověřit, jestli existuje horký oddíl, přejděte do části Insights>Throughput>Normalized RU Consumption (%) Podle PartitionKeyRangeID. Vyfiltrujte konkrétní databázi a kontejner.
Každý PartitionKeyRangeId se mapuje na jeden fyzický oddíl. Pokud existuje jeden PartitionKeyRangeId, který má mnohem vyšší normalizovanou spotřebu RU než ostatní (například jedna je konzistentně na 100 %, ale jiné jsou o 30 % nebo méně), může to být znaménkem horkého oddílu. Přečtěte si další informace o metrikě normalizované spotřeby RU.
Pokud chcete zjistit, které klíče logického oddílu využívají nejvíce RU/s, použijte diagnostické protokoly Azure. Tento ukázkový dotaz sečte celkový počet jednotek žádostí spotřebovaných za sekundu u každého klíče logického oddílu.
Důležité
Povolení diagnostických protokolů nese pro službu Log Analytics samostatné poplatky, které se účtují na základě objemu přijatých dat. Doporučujeme zapnout diagnostické protokoly po omezenou dobu pro ladění a vypnout, pokud už nejsou potřeba. Podrobnosti najdete na stránce s cenami.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= ago(24hour)
| where CollectionName == "CollectionName"
| where isnotempty(PartitionKey)
// Sum total request units consumed by logical partition key for each second
| summarize sum(RequestCharge) by PartitionKey, OperationName, bin(TimeGenerated, 1s)
| order by sum_RequestCharge desc
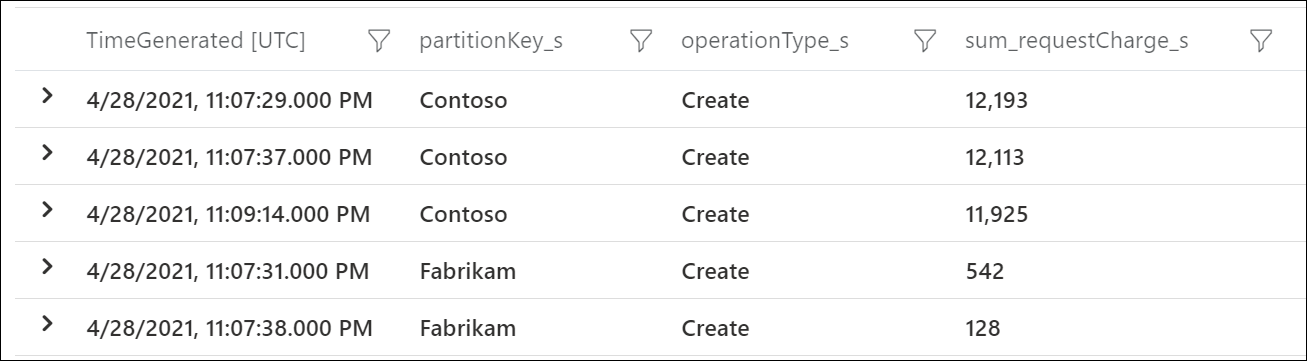
Tento ukázkový výstup ukazuje, že v konkrétní minutě spotřeboval logický klíč oddílu s hodnotou Contoso přibližně 12 000 RU/s, zatímco klíč logického oddílu s hodnotou Fabrikam spotřeboval méně než 600 RU/s. Pokud byl tento model konzistentní během časového období, kdy došlo k omezování rychlosti, znamená to horký oddíl.
Tip
V každé úloze bude mezi logickými oddíly přirozené variace svazku požadavků. Měli byste určit, jestli je horký oddíl způsobený zásadní nerovnoměrnou distribuci kvůli výběru klíče oddílu (který může vyžadovat změnu klíče) nebo dočasné špičky kvůli přirozené variaci ve vzorech úloh.
Doporučené řešení
Projděte si pokyny k výběru vhodného klíče oddílu.
Pokud je vysoké procento omezených požadavků a žádný horký oddíl:
- Počet RU/s v databázi nebo kontejneru můžete zvýšit pomocí klientských sad SDK, webu Azure Portal, PowerShellu, rozhraní příkazového řádku nebo šablony ARM. Postupujte podle osvědčených postupů pro škálování zřízené propustnosti (RU/s) a určete správné RU/s, které chcete nastavit.
Pokud je vysoké procento omezených požadavků a existuje základní horký oddíl:
- Dlouhodobé, z hlediska nejlepších nákladů a výkonu, zvažte změnu klíče oddílu. Klíč oddílu nejde aktualizovat, takže to vyžaduje migraci dat do nového kontejneru s jiným klíčem oddílu. Azure Cosmos DB pro tento účel podporuje nástroj pro migraci dat za provozu.
- Krátkodobě můžete dočasně zvýšit celkový počet RU/s prostředku, abyste umožnili větší propustnost do horkého oddílu. Tato strategie se nedoporučuje jako dlouhodobá strategie, protože vede k nadměrnému zřízení RU/s a vyšších nákladů.
- Krátkodobě můžete k fyzickému oddílu, který je horký, přiřadit více RU/s k fyzickému oddílu, který je horký, můžete použít redistribuci propustnosti mezi oddíly (Preview ). To se doporučuje jenom v případě, že je horký fyzický oddíl předvídatelný a konzistentní.
Tip
Když zvýšíte propustnost, operace vertikálního navýšení kapacity se buď okamžitě dokončí, nebo bude vyžadovat dokončení až 5 až 6 hodin v závislosti na počtu RU/s, na který chcete vertikálně navýšit kapacitu. Pokud chcete znát nejvyšší počet RU/s, který můžete nastavit bez aktivace asynchronní operace vertikálního navýšení kapacity (což vyžaduje, aby služba Azure Cosmos DB zřídila více fyzických oddílů), vynásobte počet jedinečných identifikátorů PartitionKeyRangeId o 10 0000 RU/s. Pokud máte například zřízených 30 000 RU/s a 5 fyzických oddílů (6000 RU/s přidělených na fyzický oddíl), můžete v okamžité operaci vertikálního navýšení kapacity zvýšit na 50 000 RU/s (10 000 RU/s na fyzický oddíl). Zvýšení na >50 000 RU/s by vyžadovalo asynchronní operaci vertikálního navýšení kapacity. Přečtěte si další informace o osvědčených postupech pro škálování zřízené propustnosti (RU/s).
Krok 3: Určení požadavků, které vrací odpovědi 429
Jak prozkoumat požadavky s odpověďmi 429
Pomocí diagnostických protokolů Azure identifikujte, které požadavky vrací 429 odpovědí a kolik RU spotřebovalo. Tento ukázkový dotaz agreguje na úrovni minut.
Důležité
Povolení diagnostických protokolů nese pro službu Log Analytics samostatné poplatky, které se účtují na základě ingestovaného objemu dat. Doporučuje se zapnout diagnostické protokoly po omezenou dobu pro ladění a vypnout, pokud už nejsou potřeba. Podrobnosti najdete na stránce s cenami.
CDBDataPlaneRequests
| where TimeGenerated >= ago(24h)
| summarize throttledOperations = dcountif(ActivityId, StatusCode == 429), totalOperations = dcount(ActivityId), totalConsumedRUPerMinute = sum(RequestCharge) by DatabaseName, CollectionName, OperationName, RequestResourceType, bin(TimeGenerated, 1min)
| extend averageRUPerOperation = 1.0 * totalConsumedRUPerMinute / totalOperations
| extend fractionOf429s = 1.0 * throttledOperations / totalOperations
| order by fractionOf429s desc
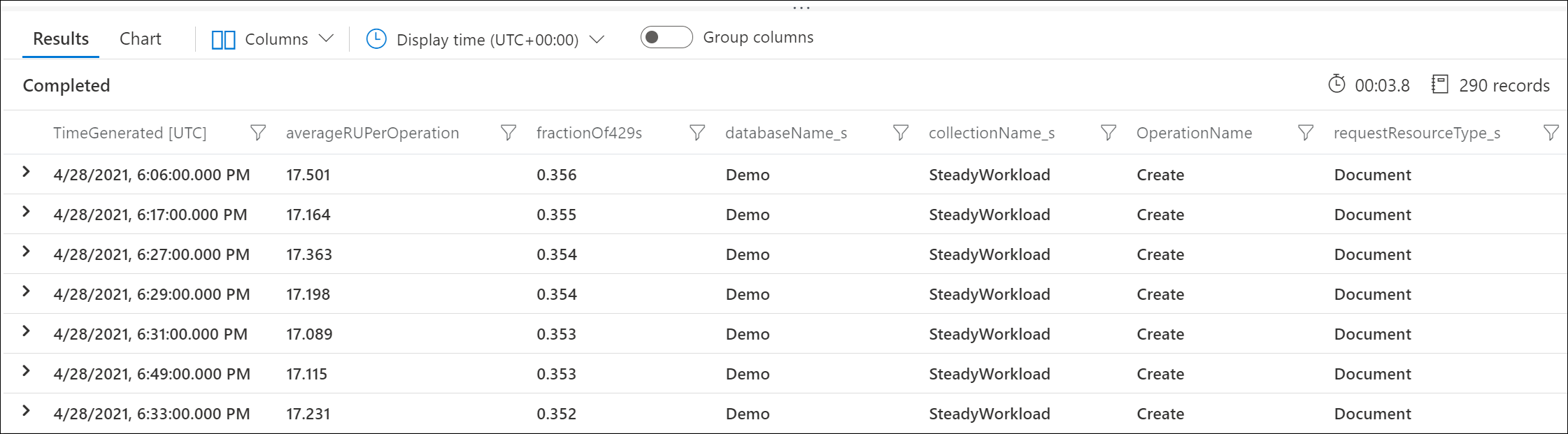
Tento ukázkový výstup například ukazuje, že každou minutu, 30 % požadavků na vytvoření dokumentu bylo omezené, přičemž každý požadavek spotřebovává průměrně 17 RU.
Doporučené řešení
Použití plánovače kapacity služby Azure Cosmos DB
Pomocí Plánovače kapacity služby Azure Cosmos DB můžete zjistit, jaká je nejlepší zřízená propustnost na základě vaší úlohy (objem a typ operací a velikost dokumentů). Další výpočty můžete přizpůsobit tím, že poskytnete ukázková data, abyste získali přesnější odhad.
429 odpovědí na žádosti o vytvoření, nahrazení nebo upsertování dokumentů
- Ve výchozím nastavení se ve výchozím nastavení v rozhraní API for NoSQL indexují všechny vlastnosti. Vylaďte zásadu indexování tak, aby indexovat pouze potřebné vlastnosti. Tím se sníží počet jednotek žádostí požadovaných pro operaci vytvoření dokumentu, což sníží pravděpodobnost zobrazení 429 odpovědí nebo umožní dosáhnout vyšších operací za sekundu pro stejné množství zřízených RU/s.
429 odpovědí na žádosti o dokumenty dotazů
- Při řešení potíží s dotazy s vysokým poplatkem za RU postupujte podle pokynů .
429 odpovědí na provádění uložených procedur
- Uložené procedury jsou určené pro operace, které vyžadují transakce zápisu napříč hodnotou klíče oddílu. Nedoporučuje se používat uložené procedury pro velký počet operací čtení nebo dotazů. Pro zajištění nejlepšího výkonu by se tyto operace čtení nebo dotazování měly provádět na straně klienta pomocí sad SDK služby Azure Cosmos DB.
Frekvence požadavků je velká s automatickým škálováním
Všechny pokyny v tomto článku se týkají propustnosti ručního i automatického škálování.
Při použití automatického škálování je běžnou otázkou: "Je stále možné zobrazit 429 odpovědí s automatickým škálováním?"
Ano. Existují dva hlavní scénáře, kdy k tomu může dojít.
Scénář 1: Pokud celkové spotřebované RU/s překročí maximální počet RU/s databáze nebo kontejneru, služba odpovídajícím způsobem omezí požadavky. To je podobné překročení celkové ručně zřízené propustnosti databáze nebo kontejneru.
Scénář 2: Pokud existuje horký oddíl, to znamená hodnota klíče logického oddílu, která má nepřiměřeně vyšší množství požadavků v porovnání s jinými hodnotami klíče oddílu, je možné, aby základní fyzický oddíl překročil svůj rozpočet RU/s. Pokud se chcete vyhnout horkým oddílům, doporučujeme zvolit vhodný klíč oddílu, který zajistí rovnoměrnou distribuci úložiště a propustnosti. To se podobá tomu, když při použití ruční propustnosti dojde k horkému oddílu.
Pokud například vyberete možnost maximální propustnosti 20 000 RU/s a máte 200 GB úložiště se čtyřmi fyzickými oddíly, může se každé fyzické oddíly automaticky škálovat až na 5 000 RU/s. Pokud u konkrétního klíče logického oddílu došlo k horkému oddílu, uvidíte 429 odpovědí, když je základní fyzický oddíl, ve kterém se nachází, větší než 5 000 RU/s, tj. překročí 100% normalizované využití.
Při ladění těchto scénářů postupujte podle pokynů v kroku 1, kroku 2 a kroku 3 .
Další běžnou otázkou, která nastane, je, proč je normalizovaná spotřeba RU 100 %, ale automatické škálování se neškáli na maximální počet RU/s?
K tomu obvykle dochází u úloh, které mají dočasné nebo občasné špičky využití. Když používáte automatické škálování, Azure Cosmos DB škáluje ru/s pouze na maximální propustnost, pokud je normalizovaná spotřeba RU 100 % pro trvalou nepřetržitou dobu v 5sekundovém intervalu. Tím se zajistí, že logika škálování je pro uživatele nákladově přívětivá, protože zajišťuje, že jednorázové špičky v momentální špičce nevedou k zbytečným škálováním a vyšším nákladům. Pokud dojde k momentální špičce, systém obvykle vertikálně navyšuje kapacitu na vyšší hodnotu, než byla dříve škálovaná na RU/s, ale nižší než maximální počet RU/s. Přečtěte si další informace o tom, jak interpretovat normalizovanou metriku spotřeby RU pomocí automatického škálování.
Omezování rychlosti požadavků na metadata
K omezování rychlosti metadat může dojít při provádění velkého objemu operací metadat s databázemi nebo kontejnery. Mezi operace metadat patří:
- Vytvoření, čtení, aktualizace nebo odstranění kontejneru nebo databáze
- Výpis databází nebo kontejnerů v účtu služby Azure Cosmos DB
- Dotaz na nabídky pro zobrazení aktuální zřízené propustnosti
Pro tyto operace existuje limit rezervovaných jednotek RU rezervovaný systémem, takže zvýšení zřízených RU/s databáze nebo kontejneru nebude mít žádný vliv a nedoporučuje se. Viz Omezení služeb roviny řízení.
Postup prošetřování
Přejděte do >části Požadavky na systémová>metadata podle stavových kódů. V případě potřeby vyfiltrujte konkrétní databázi a kontejner.
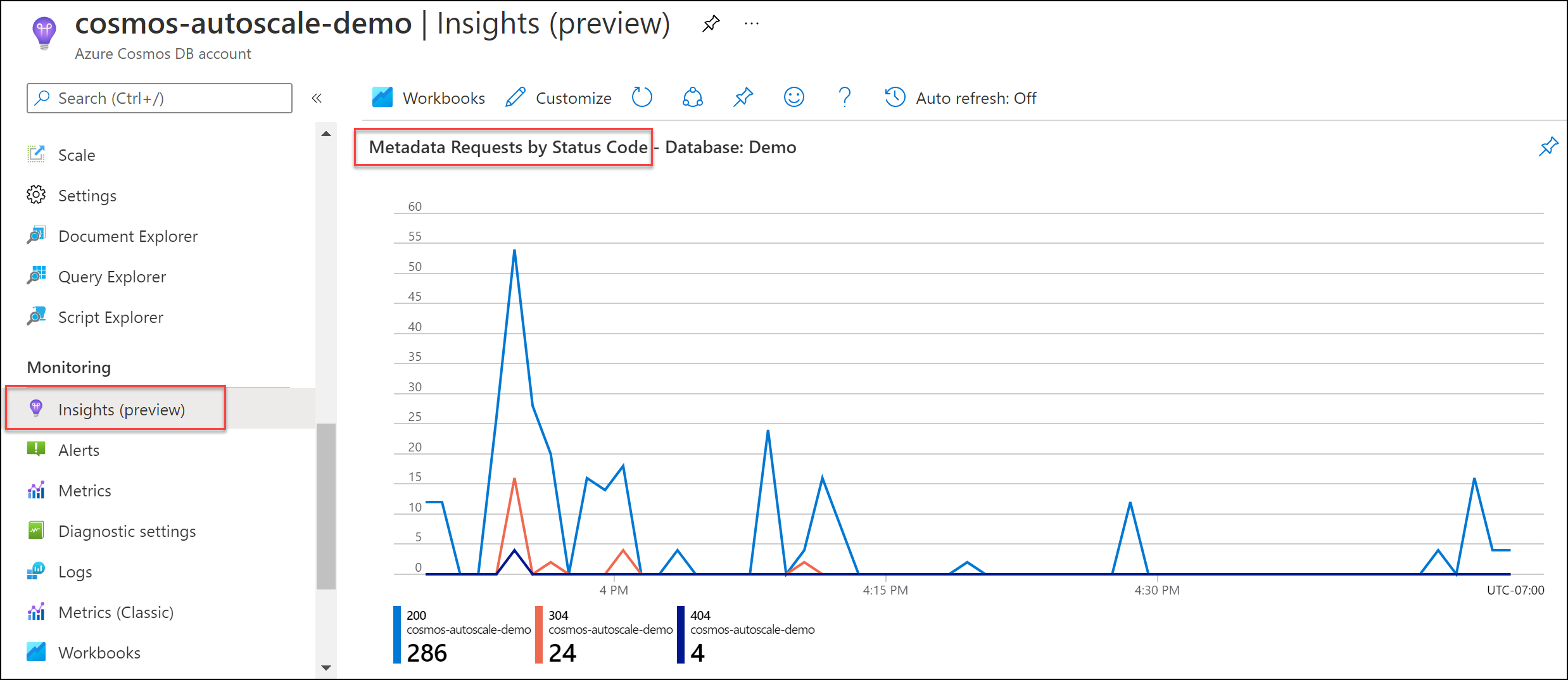
Doporučené řešení
Pokud vaše aplikace potřebuje provádět operace s metadaty, zvažte implementaci zásad zpětného odsílaní těchto požadavků s nižší rychlostí.
Používejte statické instance klienta Azure Cosmos DB. Při inicializaci DocumentClient nebo CosmosClient načte sada SDK služby Azure Cosmos DB metadata o účtu, včetně informací o úrovni konzistence, databázích, kontejnerech, oddílech a nabídkách. Tato inicializace může využívat velké množství RU a měla by se provádět jenom zřídka. Použijte jednu instanci DocumentClient a využijte ji po celou dobu životnosti vaší aplikace.
Ukládat názvy databází a kontejnerů do mezipaměti Načtěte názvy databází a kontejnerů z konfigurace nebo je při spuštění ukážíte do mezipaměti. Volání jako ReadDatabaseAsync/ReadDocumentCollectionAsync nebo CreateDatabaseQuery/CreateDocumentCollectionQuery způsobí volání metadat do služby, která spotřebovávají limit ru rezervovaných systémem. Tyto operace by se měly provádět zřídka.
Omezování rychlosti kvůli přechodné chybě služby
Tato chyba 429 se vrátí, když požadavek narazí na přechodnou chybu služby. Zvýšení počtu RU/s v databázi nebo kontejneru nebude mít žádný vliv a nedoporučuje se.
Doporučené řešení
Zkuste požadavek zopakovat. Pokud chyba trvá několik minut, vytvořte lístek podpory na webu Azure Portal.
Další kroky
- Monitorujte normalizovanou spotřebu RU/s databáze nebo kontejneru.
- Diagnostika a řešení potíží při použití sady .NET SDK služby Azure Cosmos DB
- Přečtěte si informace o pokynech k výkonu pro .NET v3 a .NET v2.
- Diagnostika a řešení potíží při používání sady Azure Cosmos DB Java SDK v4
- Přečtěte si o pokynech k výkonu sady Java SDK v4.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro