Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Apache Spark je jednotný analytický modul pro zpracování velkých objemů dat. Azure Data Explorer je rychlá, plně spravovaná služba analýzy dat pro analýzy velkých objemů dat v reálném čase.
Konektor Kusto pro Spark je opensourcový projekt , který se dá spustit v jakémkoli clusteru Spark. Implementuje zdroj dat a jímku dat pro přesun dat mezi Azure Data Explorerem a clustery Spark. Pomocí Azure Data Exploreru a Apache Sparku můžete vytvářet rychlé a škálovatelné aplikace zaměřené na scénáře řízené daty. Například strojové učení (ML), extrakce-transformace-načítání (ETL) a Log Analytics. S konektorem se Azure Data Explorer stane platným úložištěm dat pro standardní operace zdroje Sparku a jímky, například write, reada writeStream.
Do Azure Data Exploreru můžete zapisovat prostřednictvím frontovaného příjmu nebo streamovaného příjmu. Čtení z Azure Data Exploreru podporuje pruning sloupců a predikátové zpracování, což filtruje data v Azure Data Exploreru a snižuje objem přenášených dat.
Tento článek popisuje, jak nainstalovat a nakonfigurovat konektor Spark Azure Data Exploreru a přesouvat data mezi Azure Data Explorerem a clustery Apache Spark.
Poznámka:
I když některé z příkladů v tomto článku odkazují na cluster Azure Databricks Spark, konektor Spark v Azure Data Exploreru nepřebírají přímé závislosti na Databricks ani v žádné jiné distribuci Sparku.
Požadavky
- Předplatné Azure. Vytvořte bezplatný účet Azure.
- Cluster a databáze Azure Data Exploreru. Vytvořte cluster a databázi.
- Cluster Spark
- Instalace knihovny konektorů:
- Předem připravené knihovny pro Spark 2.4+Scala 2.11 nebo Spark 3+scala 2.12
- Úložiště Maven
- Nainstalovaný Maven 3.x
Tip
Podporují se také verze Sparku 2.3.x, ale možná budete muset změnit některé závislosti v pom.xml.
Postup sestavení konektoru Spark
Počínaje verzí 2.3.0 zavádíme nové ID artefaktů, které nahrazují spark-kusto-connector: kusto-spark_3.0_2.12 , které cílí na Spark 3.x a Scala 2.12.
Poznámka:
Verze starší než 2.5.1 už nefungují pro příjem do existující tabulky, aktualizujte prosím na novější verzi. Tento krok je nepovinný. Pokud používáte například předpřipravené knihovny, podívejte se na nastavení clusteru Spark.
Předpoklady pro sestavení
Informace o vytvoření konektoru Spark najdete v tomto zdroji .
V případě aplikací Scala/Java využívajících definice projektu Maven propojte aplikaci s nejnovějším artefaktem. Najděte nejnovější artefakt v Centru Mavenu.
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).Pokud nepoužíváte předem připravené knihovny, musíte nainstalovat knihovny uvedené v závislostech , včetně následujících knihoven sady Kusto Java SDK . Správnou verzi, která se má nainstalovat, najdete v pom příslušné verze:
Sestavení jar a spuštění všech testů:
mvn clean package -DskipTestsPokud chcete sestavit soubor JAR, spusťte všechny testy a nainstalujte soubor JAR do místního úložiště Maven:
mvn clean install -DskipTests
Další informace najdete v tématu Využití konektoru.
Nastavení clusteru Spark
Poznámka:
Při provádění následujících kroků doporučujeme použít nejnovější verzi konektoru Kusto Spark.
Nakonfigurujte následující nastavení clusteru Spark na základě clusteru Azure Databricks Spark 3.0.1 a Scala 2.12:
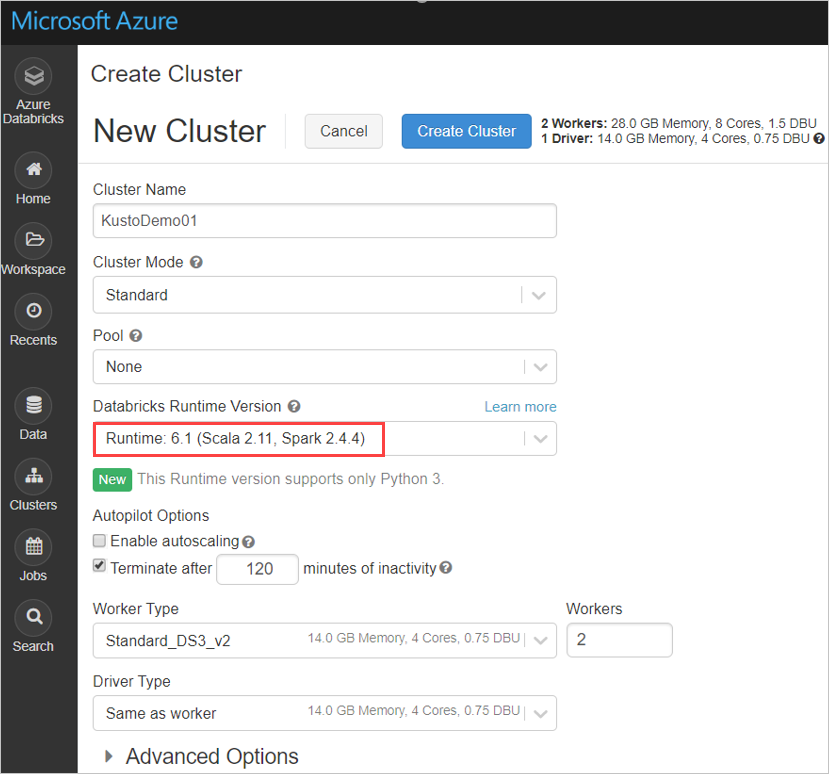
Nainstalujte nejnovější knihovnu spark-kusto-connector z Mavenu:
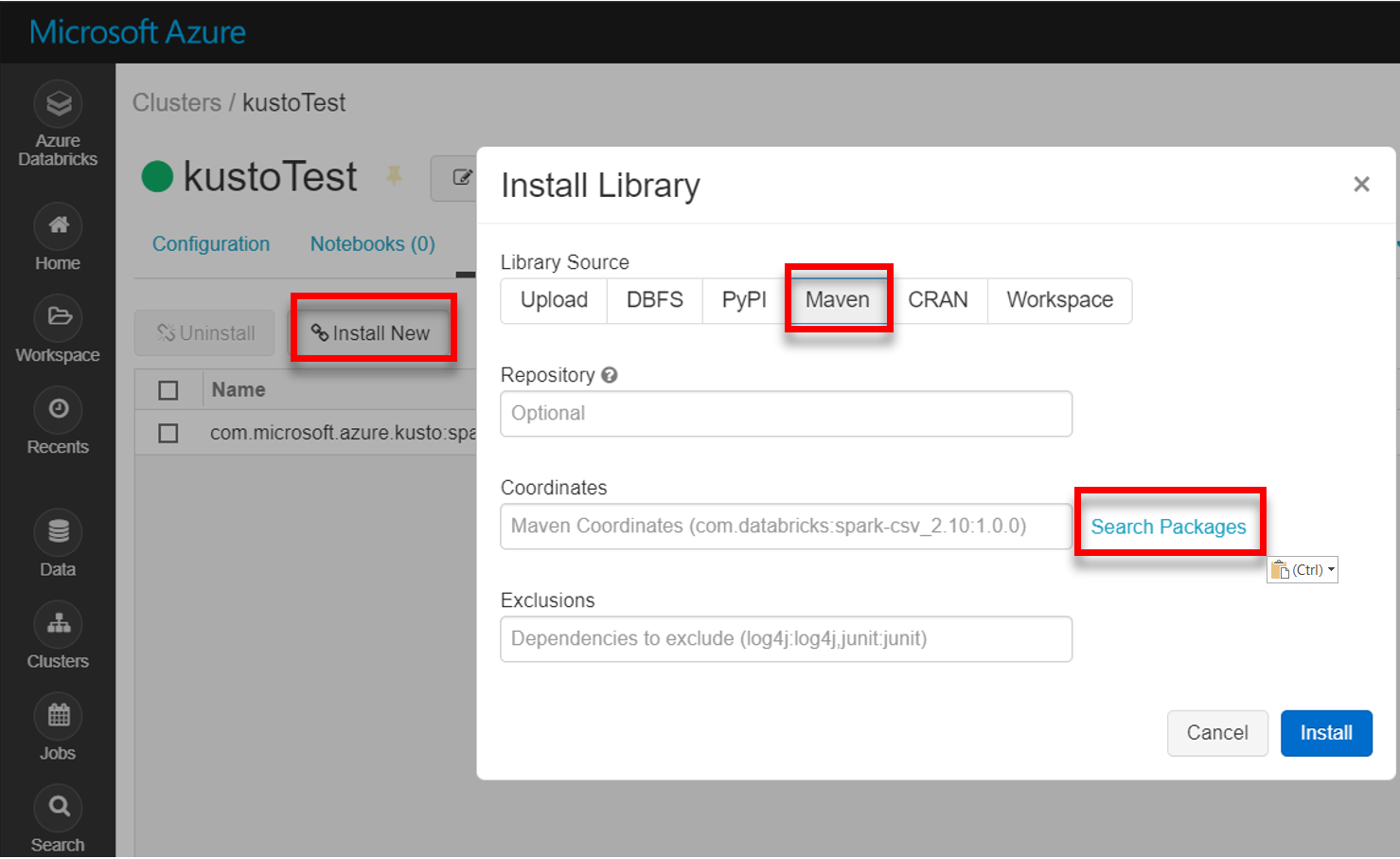
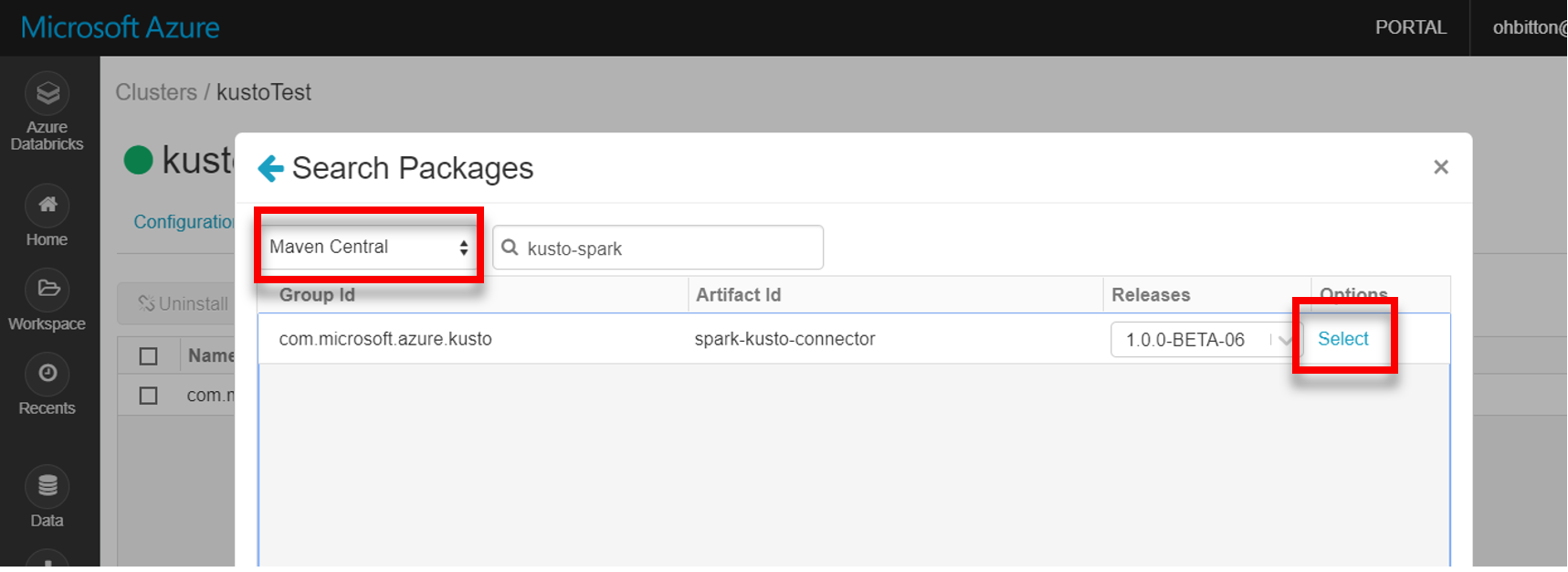
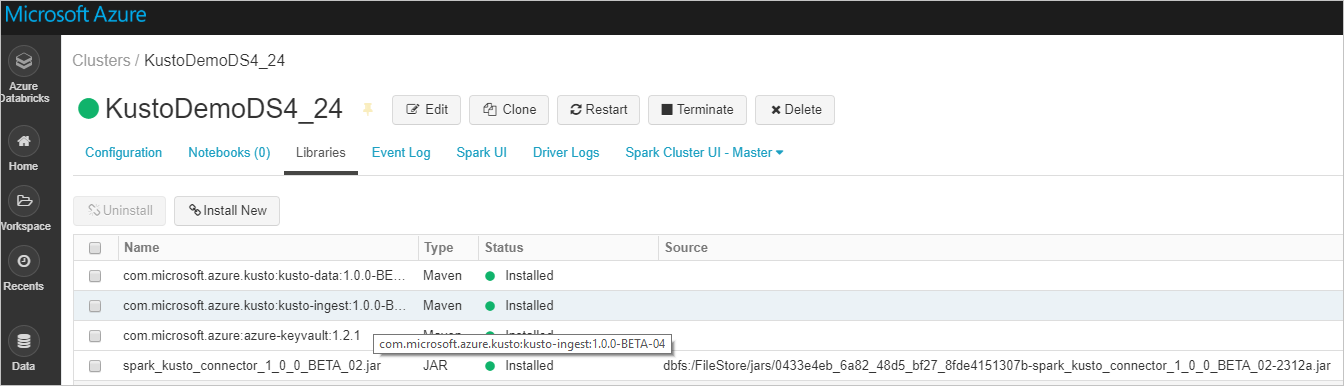
Ověřte, že jsou nainstalované všechny požadované knihovny:
V případě instalace pomocí souboru JAR ověřte, že byly nainstalovány další závislosti:
Ověřování
Konektor Kusto Spark umožňuje ověřování pomocí ID Microsoft Entra pomocí jedné z následujících metod:
- Aplikace Microsoft Entra
- Přístupový token Microsoft Entra
- Ověřování zařízení (pro neprodukční scénáře)
- Azure Key Vault pro přístup k prostředku služby Key Vault, nainstalujte balíček azure-keyvault a zadejte přihlašovací údaje aplikace.
Ověřování aplikací Microsoft Entra
Ověřování aplikací Microsoft Entra je nejjednodušší a nejběžnější metodou ověřování a doporučuje se pro konektor Kusto Spark.
Přihlaste se ke svému předplatnému Azure prostřednictvím Azure CLI. Pak se ověřte v prohlížeči.
az loginZvolte předplatné pro hostování hlavního objektu zabezpečení. Tento krok je potřeba v případě, že máte více předplatných.
az account set --subscription YOUR_SUBSCRIPTION_GUIDVytvořte objekt služby. V tomto příkladu se instanční objekt nazývá
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Z vrácených dat JSON zkopírujte
appId,passwordatenantpro budoucí použití.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Vytvořili jste aplikaci Microsoft Entra a služebního principála.
Konektor Spark používá k ověřování následující vlastnosti aplikace Entra:
| Vlastnosti | Řetězec možnosti | Popis |
|---|---|---|
| KUSTO_AAD_APP_ID | KustoAadAppId | Identifikátor aplikace Microsoft Entra (klient). |
| KUSTO_AAD_AUTHORITY_ID | KustoAadAuthorityID | Ověřovací autorita Microsoft Entra. ID adresáře Microsoft Entra (tenanta). Volitelné – výchozí hodnota je microsoft.com. Další informace naleznete v tématu Microsoft Entra authority. |
| KUSTO_AAD_APP_SECRET | KustoAadAppSecret | Klíč aplikace Microsoft Entra pro klienta |
| KUSTO_ACCESS_TOKEN | KustoAccessToken | Pokud již máte accessToken, který byl vytvořen s přístupem k Kusto, můžete jej také použít pro autentizaci v konektoru. |
Poznámka:
Starší verze rozhraní API (méně než 2.0.0) mají následující názvy: kustoAADClientID, kustoClientAADClientPassword, KustoAADAuthorityID.
Oprávnění Kusto
Na straně Kusto udělte následující oprávnění podle operace Spark, kterou chcete provést.
| Operace Spark | Oprávnění |
|---|---|
| Čtení – jeden režim | Čtenář |
| Čtení – nucený distribuovaný režim | Čtenář |
| Zápis – frontový režim s volbou vytvoření tabulky CreateTableIfNotExist | Správce |
| Zápis – režim Queue s možností vytvoření tabulky s volbou FailIfNotExist | Ingestor |
| Zápis – Transakční režim | Správce |
Další informace o hlavních rolích najdete v tématu Řízení přístupu na základě role. Informace o správě rolí zabezpečení najdete v tématu Správa rolí zabezpečení.
Výstupní kanál Sparku: zápis do Kusto
Nastavení parametrů jímky:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Zapište datový rámec Sparku do clusteru Kusto jako dávkový proces:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Nebo použijte zjednodušenou syntaxi:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ // Optional, for any extra options: val conf: Map[String, String] = Map() val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Zápis streamovaných dat:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // As an alternative to adding .option by .option, you can provide a map: val conf: Map[String, String] = Map( KustoSinkOptions.KUSTO_CLUSTER -> cluster, KustoSinkOptions.KUSTO_TABLE -> table, KustoSinkOptions.KUSTO_DATABASE -> database, KustoSourceOptions.KUSTO_ACCESS_TOKEN -> accessToken) // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Zdroj Sparku: čtení z Kusto
Při čtení malých objemů dat definujte datový dotaz:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Volitelné: Pokud poskytnete přechodné úložiště objektů blob (a ne Kusto), objekty blob se vytvoří v rámci odpovědnosti volajícího. To zahrnuje zřízení úložiště, obměnu přístupových klíčů a odstranění přechodných artefaktů. Modul KustoBlobStorageUtils obsahuje pomocné funkce pro odstraňování objektů blob na základě souřadnic účtu a kontejneru a přihlašovacích údajů účtu nebo úplné adresy URL SAS s oprávněními k zápisu, čtení a seznamu. Pokud už odpovídající RDD není potřeba, každá transakce ukládá dočasné artefakty blobů do samostatného adresáře. Tento adresář se zaznamenává jako součást protokolů informací o transakcích pro čtení hlášených v uzlu ovladače Sparku.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")V předchozím příkladu není služba Key Vault přístupná pomocí rozhraní konektoru; Používá se jednodušší metoda použití tajných kódů Databricks.
Přečtěte si z Kusto.
Pokud poskytnete přechodné úložiště objektů blob, načtěte z Kusto následujícím způsobem:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Pokud Kusto poskytuje přechodné úložiště objektů blob, načtěte z Kusto následujícím způsobem:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)