Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
APPLIES TO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory v Microsoft Fabric je nová generace Azure Data Factory s jednodušší architekturou, integrovanou AI a novými funkcemi. Pokud s integrací dat začínáte, začněte Fabric Data Factory. Stávající úlohy ADF lze upgradovat na Fabric pro přístup k novým funkcím v oblastech datové vědy, analýz v reálném čase a vytváření sestav.
Azure Data Factory je Microsoft služba Integrace dat a ETL v cloudu. Tento dokument obsahuje pokyny pro DataOps v datové továrně. Nejedná se o úplný kurz ci/CD, Gitu nebo DevOps. Místo toho najdete pokyny týmu datové továrny pro dosažení DataOps ve službě s odkazy na podrobné odkazy na implementaci osvědčených postupů pro nasazení datové továrny, správu továrny a zásady správného řízení. Na konci tohoto dokumentu je oddíl zdrojů s odkazy na kurzy.
Co je DataOps?
DataOps je proces, který organizace dat procvičují při správě dat založených na spolupráci, aby poskytovaly rychlejší hodnotu pro pracovníky s rozhodovací pravomocí.
Gartner poskytuje tuto jasnou definici DataOps:
DataOps je postup správy dat založený na spolupráci zaměřený na zlepšení komunikace, integrace a automatizace toků dat mezi správci dat a spotřebiteli dat v rámci organizace. Cílem DataOps je zajistit hodnotu rychleji vytvořením předvídatelného doručování a správy změn dat, datových modelů a souvisejících artefaktů. DataOps využívá technologii k automatizaci návrhu, nasazení a správy doručování dat s odpovídající úrovní zásad správného řízení a používá metadata ke zlepšení použitelnosti a hodnoty dat v dynamickém prostředí.
Jak dosáhnete DataOps v Azure Data Factory?
Azure Data Factory poskytuje datovým inženýrům vizuální paradigma datového kanálu pro snadné vytváření cloudových integrací dat a projektů ETL. Datová továrna spoléhá na nativní integraci s vyspělými nástroji pro správu verzí, jako jsou GitHub a Azure DevOps a širší ekosystém Azure, a poskytuje mnoho integrovaných funkcí, které usnadňují Práci s daty, které zahrnují bohatou spolupráci, zásady správného řízení a vztahy artefaktů.
Konkrétně když do datové továrny přinesete vlastní GitHub nebo Azure DevOps úložiště, služba poskytuje intuitivní integrované možnosti uživatelského rozhraní pro běžné příkazy, jako jsou potvrzení, ukládání artefaktů a správa verzí. Tato služba také poskytuje možnost uplatňovat osvědčené postupy CI/CD a pro přihlašování změn kódu, aby byla chráněna integrita a zdraví vašeho produkčního prostředí.
Kód v Azure Data Factory
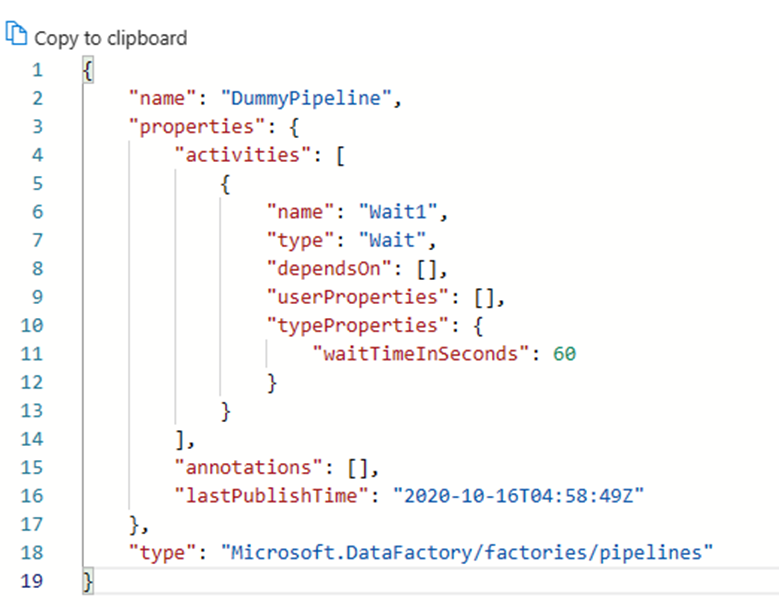
Všechny artefakty v Azure Data Factory, ať už jde o kanály, propojené služby, triggery atd. mají odpovídající reprezentaci kódu ve formátu JSON za integrací vizuálního uživatelského rozhraní. Tyto artefakty fungují v souladu se standardy Azure Resource Manager. Kód najdete kliknutím na ikonu závorky v pravém horním rohu plátna. Ukázkový kód JSON by vypadal takto:
Živý režim a správa verzí Gitu
Každá továrna má jeden jediný zdroj pravdy: kanály, propojené služby a definice triggerů uložené ve službě. Tento zdroj pravdy je to, co spouští běhy pipelin a co určuje chování spouštěčů. Pokud jste v živém režimu, pokaždé, když publikujete, přímo upravíte jediný zdroj pravdy. Následující obrázek ukazuje, jak vypadá tlačítko Publikovat vše v živém režimu.

Živý režim může být vhodný pro jednoho člověka pracujícího na vedlejších projektech, protože vývojářům umožňuje vidět okamžité účinky změn kódu. Ale nedoporučuje se, aby tým vývojářů pracoval na pracovních projektech na úrovni produkce. K nebezpečím patří tukové prsty, náhodné odstranění kritických prostředků, publikování neotestovaných kódů atd., jen pro pojmenování několika. Při práci na důležitých projektech a platformách zvažte přenesení úložiště Git a použití režimu Git v datové továrně ke zjednodušení procesu vývoje. Kontrola verzí a řízené odevzdání režimu Git pomáhají zabránit většině, ne-li všem, nehodám spojeným s přímým zásahem do živého režimu.
Poznámka
V režimu Gitu se tlačítko Publikovat nebo Publikovat vše nahradí tlačítkem Uložit nebo Uložit vše a vaše změny se potvrdí ve vlastních větvích (ne přímo změny živých základů kódu).
Nastavení integrace GitHub a Azure DevOps
V Azure Data Factory se důrazně doporučuje ukládat úložiště do GitHub nebo Azure DevOps. Služba plně podporuje obě metody i výběr úložiště, které se má použít, závisí na vašich individuálních organizačních standardech. Existují dvě metody nastavení nového úložiště nebo připojení k existujícímu úložišti: pomocí portálu Azure nebo vytvoření z uživatelského rozhraní Azure Data Factory Studio.
vytváření Azure portálu
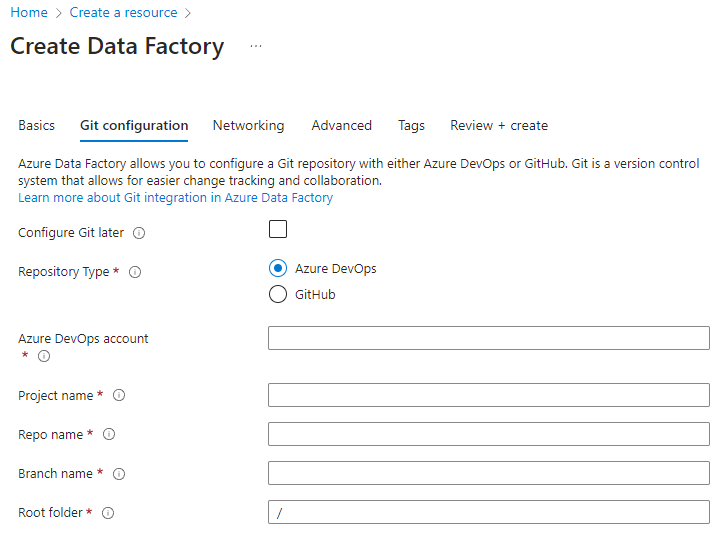
Když vytvoříte novou datovou továrnu z portálu Azure, výchozí úložiště Git je Azure DevOps. Můžete také vybrat GitHub jako úložiště a nakonfigurovat nastavení úložiště.
Na portálu Azure vyberte typ úložiště a zadejte názvy úložišť a větví, abyste vytvořili novou továrnu, která je nativně integrovaná s Gitem.
Vynucování použití Gitu s Azure Policy ve vaší organizaci
Použití Gitu ve vašich projektech Azure Data Factory je osvědčeným postupem. I když neimplementujete kompletní proces CI/CD, integrace Gitu s ADF umožňuje ukládání artefaktů vašich prostředků ve vašem vlastním sandboxovém prostředí (větvi Gitu), kde můžete testovat změny nezávisle na ostatních větvích. Můžete použít Azure Policy k prosazení používání Git ve vaší organizaci.
Azure Data Factory Studio
Po vytvoření datové továrny se můžete k úložišti připojit také přes Azure Data Factory Studio. Na kartě Správa uvidíte možnost konfigurovat úložiště a jeho nastavení.

Prostřednictvím řízeného procesu vás provede řada kroků, které vám pomůžou snadno nakonfigurovat a připojit se k zvolenému úložišti. Po úplném nastavení můžete začít spolupracovat a ukládat prostředky do úložiště.
Kontinuální integrace a kontinuální doručování (CI/CD)
CI/CD je paradigma vývoje kódu, kde se změny kontrolují a testují při procházení různých fází – vývoj, testování, příprava atd. Po kontrole a otestování v jednotlivých fázích se nakonec publikují do živých základů kódu v produkčním prostředí.
Kontinuální integrace (CI) je postup automatického testování a ověřování pokaždé, když vývojář provede změnu základu kódu. Průběžné doručování (CD) znamená, že po úspěšném testování kontinuální integrace se změny přenesou do další fáze.
Jak jsme už stručně probírali, "kód" v Azure Data Factory má formu Azure Resource Manager šablony JSON. Změny procházející procesem kontinuální integrace a doručování (CI/CD) proto zahrnují přidání, odstranění a úpravy objektů blob JSON.
Spuštění kanálu v Azure Data Factory
Než začneme mluvit o CI/CD v Azure Data Factory, musíme nejprve mluvit o tom, jak služba spouští datový tok. Než datová továrna spustí pipeline, provede následující akce:
- Načte nejnovější publikovanou definici kanálu a související prostředky, jako jsou datové sady, propojené služby atd.
- Zkompiluje ho na akce; Pokud ji datová továrna nedávno spustila, načte akce z kompilací uložených v mezipaměti.
- Spustí kanál.
Spuštění pipeline zahrnuje následující kroky:
- Služba pořídí snímek definice pipeline v určitém časovém okamžiku.
- Během trvání pracovního postupu se definice nemění.
- I když vaše kanály běží dlouhou dobu, nebudou ovlivněné následnými změnami provedenými po jejich spuštění. Pokud během spuštění publikujete změny propojené služby, datových toků atd., nebudou mít vliv na aktuálně probíhající úlohy.
- Když publikujete změny, další spuštění po publikování použije aktualizované definice.
Publikování v Azure Data Factory
Bez ohledu na to, jestli nasazujete pipelines pomocí Azure Release Pipeline pro automatizaci publikování, nebo pomocí manuálního nasazení šablon Resource Manager, v backendu je publikování řadou operací vytvoření/aktualizace na datasetech, službách propojování, pipeliny a triggery pro každý z artefaktů. Efekt je stejný jako přímé volání základního rozhraní REST API.
Z těchto kroků vzniká několik věcí:
- Všechna tato volání rozhraní API jsou synchronní, což znamená, že volání se vrátí pouze v případě, že publikování proběhne úspěšně nebo selže. U artefaktu nebude žádný stav částečného nasazení.
- Volání rozhraní API jsou do značné míry sekvenční. Snažíme se paralelizovat volání a současně udržovat referenční závislosti artefaktů. Pořadí nasazení je propojená služba -> datová sada/prostředí Integration Runtime -> kanál -> trigger. Toto pořadí zajišťuje, aby závislé artefakty mohly správně odkazovat na své závislosti. Například pipeliny závisejí na datových sadách, a proto je datová továrna nasadí až po datových sadách.
- Nasazení propojených služeb, datových sad atd. je nezávislé na potrubích. Existují situace, kdy datová továrna aktualizuje propojené služby dříve, než se potrubí aktualizuje. O této situaci si řekneme v části Kdy zastavit spoušť.
- Nasazení neodstraní artefakty z továren. Abyste mohli vyčistit továrnu, musíte explicitně volat rozhraní API pro odstranění jednotlivých typů artefaktů (kanál, datovou sadu, propojenou službu atd.). Podívejte se například na ukázkový skript po nasazení z Azure Data Factory.
- I když jste se nedotkli kanálu, datové sady nebo propojené služby, stále vyvolá rychlé volání rozhraní API pro aktualizaci do továrny.
Spouštěče publikování
- Triggery mají stavy: spuštěno nebo zastaveno.
- V režimu spuštění nemůžete provádět změny triggeru. Před publikováním jakýchkoli změn musíte trigger zastavit.
-
Rozhraní API pro vytvoření nebo aktualizaci triggeru můžete vyvolat u triggeru v režimu spuštěno.
- Pokud se změní užitečné zatížení, rozhraní API selže.
- Pokud datová část zůstane nezměněná, rozhraní API je úspěšné.
- Toto chování má zásadní dopad na to, kdy zastavit spouštěč.
Kdy zastavit spouštěč
Pokud jde o nasazení do produkční datové továrny, s aktivními spouštěči, které neustále spouští kanály, nastává otázka: "Měli bychom je zastavit?"
Stručná odpověď je, že v následujících několika scénářích byste měli zvážit zastavení triggeru:
- Pokud aktualizujete definice spouště, včetně polí, jako je koncové datum, frekvence a propojení s pipeline, musíte spoušť zastavit.
- Pokud aktualizujete datové sady nebo propojené služby odkazované v živém datovém toku, doporučujeme trigger zastavit. Pokud například provádíte rotaci přihlašovacích údajů pro SQL Server.
- Pokud přidružený kanál vyvolává chyby a zatěžuje vaše servery, můžete se rozhodnout, že trigger zastavíte.
Zde je několik bodů k zvážení ohledně zastavení triggerů:
- Jak je vysvětleno v části Pipeline Spuštění v Azure Data Factory, když trigger spustí spuštění kanálu, pořídí snímek kanálu, datové sady, prostředí Integration Runtime a definic propojené služby. Pokud se pipeline spustí před tím, než se změny naplní do back-endu, spouštěč zahájí běh se starou verzí. Ve většině případů by to mělo být v pořádku.
- Jak je vysvětleno v části Triggery publikování. Když je trigger spuštěný , nejde ho aktualizovat. Proto pokud potřebujete změnit podrobnosti o definici triggeru, před publikováním změn zastavte trigger.
- Jak je vysvětleno v části Publishing v Azure Data Factory, úpravy datových sad nebo propojených služeb se publikují před změnami v datovém kanálu. Pokud chcete zajistit, aby pipeline používala správné přihlašovací údaje a komunikovala se správnými servery, doporučujeme také zastavit přidružený spouštěč.
Příprava změn kódu
Doporučujeme postupovat podle těchto osvědčených postupů pro pull requesty.
- Každý vývojář by měl pracovat na vlastních větvích a na konci dne vytvářet pull requesty do hlavní větve repozitáře. Podívejte se na kurzy týkající se žádostí o přijetí změn v GitHub a DevOps.
- Když správci brány schvalují žádosti o přijetí změn a sloučí změny do hlavní větve, proces CI/CD může začít. Existují dvě navrhované metody pro zvýšení úrovně změn v různých prostředích: automatizované a ruční.
- Jakmile budete připraveni spustit CI/CD pipeline, můžete to obecně udělat pomocí nástroje Azure Pipeline Release nebo nasazovat konkrétní jednotlivé pipeline pomocí této open-source utility od Azure Player.
Automatizované nasazení změn
Pokud chcete pomoct s automatizovanými nasazeními, doporučujeme použít balíček npm nástrojů Azure Data Factory. Použití balíčku npm napomáhá ověření všech prostředků v pipeline a generovat ARM šablony pro uživatele.
Pokud chcete začít s balíčkem npm nástrojů Azure Data Factory, přečtěte si informace o Automatizované publikování pro kontinuální integraci a doručování.
Ruční nasazení změn
Po sloučení větve zpět do hlavní větve pro spolupráci v úložišti Git můžete změny publikovat ručně do živé Azure Data Factory služby. Služba poskytuje uživatelské rozhraní pro kontrolu nad publikováním z nevývojových továren pomocí možnosti Zakázat publikování (v ADF Studiu).
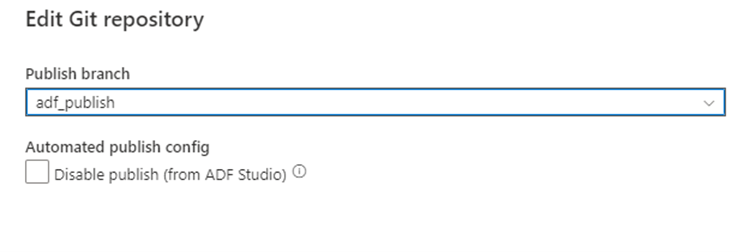
Selektivní nasazení
Selektivní nasazení spoléhá na funkci GitHubu a Azure DevOps, která se označuje jako cherry picking. Tato funkce umožňuje nasadit jenom určité změny, ale ne jiné. Například jeden vývojář provedl změny v několika kanálech, ale pro dnešní nasazení můžeme chtít změny nasadit jenom do jednoho.
Postupujte podle návodů z Azure DevOps a GitHub a vyberte commity, které jsou relevantní pro požadovanou pipelinu. Ujistěte se, že byly implementovány všechny změny, včetně relevantních změn triggerů, propojených služeb a závislostí přidružených k pipeline.
Jakmile vyberete změny metodou výběru a sloučíte je s hlavní větví pro spolupráci, můžete spustit proces CI/CD pro navrhované změny. Další informace o tom, jak aplikovat hotfix, cherry-pick nebo využít externí frameworky pro selektivní nasazení, jak je popsáno v části automatizovaného testování tohoto článku.
Testování jednotek
Jednotkové testování je důležitou součástí procesu vývoje nových potrubí nebo úprav existujících artefaktů datové továrny a zaměřuje se na testování komponentů kódu. Data Factory umožňuje testování jednotlivých jednotek jak na úrovni artefaktů datového kanálu, tak i toku dat pomocí kanálové funkce ladění.

Při vývoji toků dat budete moct získat přehled o jednotlivých transformacích a změnách kódu pomocí funkce náhledu dat , abyste před nasazením změn do produkčního prostředí dosáhli testování jednotek.

Služba poskytuje živou a interaktivní zpětnou vazbu o aktivitách kanálu v uživatelském rozhraní při ladění a testování jednotek v Azure Data Factory.
Automatické testování
K dispozici je několik nástrojů pro automatizované testování, které můžete použít s Azure Data Factory. Vzhledem k tomu, že služba ukládá objekty ve službě jako entity JSON, může být vhodné použít opensourcovou architekturu testování jednotek .NET NUnit s Visual Studio. Projděte si tento příspěvek Nastavení automatizovaného testování pro Azure Data Factory, které poskytuje podrobné vysvětlení nastavení automatizovaného testovacího prostředí jednotek pro vaši továrnu. (Zvláštní díky Richard Swinbank za svolení používat tento blog.)
Zákazníci můžou také spouštět kanály TEST pomocí PowerShellu nebo AZ CLI jako součást procesu CI/CD pro kroky před a po nasazení.
Klíčovou silou datové továrny je její parametrizace datových sad. Tato funkce umožňuje zákazníkům spouštět stejné kanály s různými sadami dat, aby zajistili, že jejich nový vývoj splňuje všechny požadavky na zdroj a cíl.
Další architektury CI/CD pro Azure Data Factory
Jak jsme popsali dříve, integrovaná integrace Gitu je nativně dostupná prostřednictvím uživatelského rozhraní Azure Data Factory, včetně sloučení, větvení, porovnání a publikování. Existují však další užitečné architektury CI/CD, které jsou oblíbené v komunitě Azure, které poskytují alternativní mechanismy pro poskytování podobných funkcí. Metodologie Azure Data Factory Gitu je založená na šablonách ARM, zatímco architektury jako ADFTools od Kamil Nowinski používají jiný přístup tím, že se místo toho spoléhají na jednotlivé artefakty JSON z vaší továrny. Datoví inženýři, kteří jsou zkušení v Azure DevOps a dávají přednost práci v tomto prostředí (na rozdíl od přístupu založeného na uživatelském rozhraní ARM, který služba nabízí) můžou zjistit, že tato architektura pro ně funguje dobře, a pro běžné scénáře, jako jsou částečná nasazení. Tato architektura může také zjednodušit zpracování aktivačních událostí při nasazování do prostředí se spuštěnými stavy triggerů.
Zásady správného řízení dat v Azure Data Factory
Důležitým aspektem efektivního DataOps je zásady správného řízení dat. V případě nástrojů ETL pro integraci dat poskytuje rodokmen dat a vztahy artefaktů důležité informace pro datového inženýra, aby porozuměl dopadu podřízených změn. Datová továrna poskytuje integrované pohledy na související artefakty, které tvoří vaši implementaci továrny.
Nativní integrace s Microsoft Purview dále poskytuje rodokmen, analýzu dopadu a katalogy dat.
Microsoft Purview poskytuje jednotné řešení zásad správného řízení dat, které pomáhá spravovat a řídit místní, multicloudová a softwarová data jako služba (SaaS). Umožňuje snadno vytvořit ucelenou aktuální mapu dat s automatizovaným zjišťováním dat, klasifikací citlivých dat a kompletní sledovatelností dat. Tyto funkce umožňují uživatelům dat přistupovat k cenné a důvěryhodné správě dat.
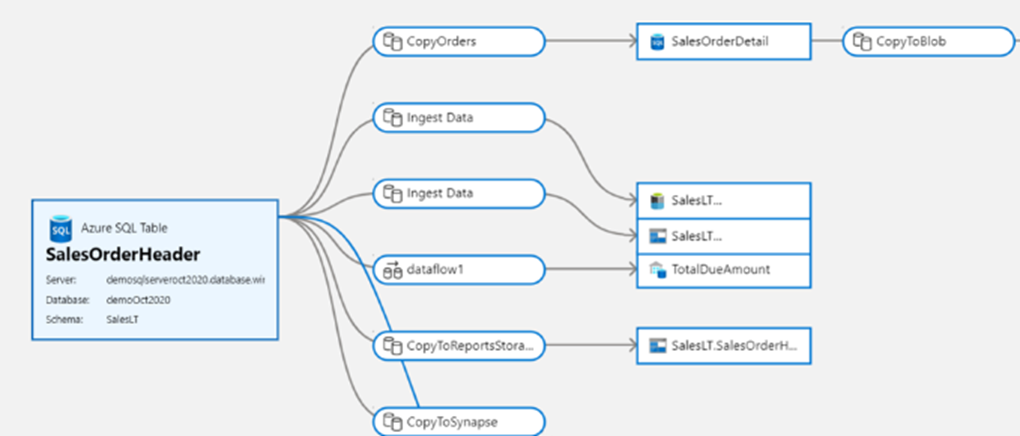
S nativní integrací s vaším Purview Data Catalog vaše Data Factory umožňuje snadné vyhledávání a objevování datových prostředků pro použití v pipelinech integrace dat napříč celkovým datovým majetkem vaší organizace.

K vyhledání datových prostředků v katalogu Purview můžete použít hlavní panel hledání ze sady Azure Data Factory Studio.

Související obsah
- Automatizované publikování pro CI/CD v Azure Data Factory
- ovládací prvek Source v Azure Data Factory
- Azure Data Factory knihovna videí s užitečnými videi o používání CI/CD v datové továrně
- Továrna na data pro hotfixy v Gitu