Vytváření clusterů HDInsight s Azure Data Lake Storage Gen1 pomocí Azure Portal
Zjistěte, jak pomocí Azure Portal vytvořit cluster HDInsight s Azure Data Lake Storage Gen1 jako výchozím úložištěm nebo dalším úložištěm. I když je další úložiště pro cluster HDInsight volitelné, doporučuje se ukládat obchodní data v dalších účtech úložiště.
Požadavky
Než začnete, ujistěte se, že splňujete následující požadavky:
- Předplatné Azure. Přejděte na získat bezplatnou zkušební verzi Azure.
- Účet Azure Data Lake Storage Gen1. Postupujte podle pokynů v tématu Začínáme s Azure Data Lake Storage Gen1 pomocí Azure Portal. V účtu musíte také vytvořit kořenovou složku. V tomto článku se používá kořenová složka s názvem /clusters .
- Microsoft Entra instančního objektu. Tento návod obsahuje pokyny k vytvoření instančního objektu v Microsoft Entra ID. Pokud ale chcete vytvořit instanční objekt, musíte být správcem Microsoft Entra. Pokud jste správce, můžete tento požadavek přeskočit a pokračovat.
Poznámka
Instanční objekt můžete vytvořit jenom v případě, že jste správcem Microsoft Entra. Před vytvořením clusteru HDInsight s Data Lake Storage Gen1 musí správce Microsoft Entra vytvořit instanční objekt. Instanční objekt musí být také vytvořen s certifikátem, jak je popsáno v tématu Vytvoření instančního objektu s certifikátem.
Vytvoření clusteru HDInsight
V této části vytvoříte cluster HDInsight s Data Lake Storage Gen1 jako výchozím nebo dodatečným úložištěm. Tento článek se zaměřuje pouze na část konfigurace Data Lake Storage Gen1. Obecné informace o vytváření clusterů a postupy najdete v tématu Vytváření clusterů Hadoop ve službě HDInsight.
Vytvoření clusteru s Data Lake Storage Gen1 jako výchozím úložištěm
Vytvoření clusteru HDInsight s Data Lake Storage Gen1 jako výchozím účtem úložiště:
Přihlaste se k webu Azure Portal.
Obecné informace o vytváření clusterů HDInsight najdete v tématu Vytváření clusterů .
V okně Úložiště v části Typ primárního úložiště vyberte Azure Data Lake Storage Gen1 a zadejte následující informace:
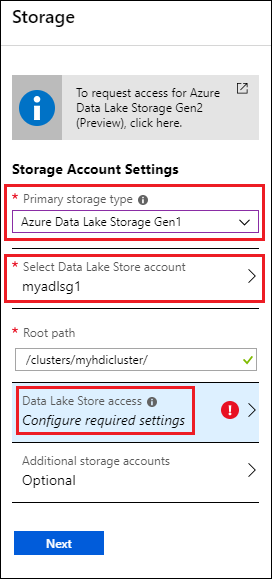
- Vyberte Účet Data Lake Store: Vyberte existující účet Data Lake Storage Gen1. Vyžaduje se existující účet Data Lake Storage Gen1. Viz Požadavky.
- Kořenová cesta: Zadejte cestu, kam se mají ukládat soubory specifické pro cluster. Na snímku obrazovky je to /clusters/myhdiadlcluster/, ve kterém musí existovat složka /clusters a portál vytvoří složku myhdicluster . Myhdicluster je název clusteru.
- Přístup ke službě Data Lake Store: Nakonfigurujte přístup mezi účtem Data Lake Storage Gen1 a clusterem HDInsight. Pokyny najdete v tématu Konfigurace Data Lake Storage Gen1 přístupu.
- Další účty úložiště: Přidejte účty úložiště Azure jako další účty úložiště pro cluster. Přidání dalších Data Lake Storage Gen1 účtů se provádí tak, že clusteru udělíte oprávnění k datům ve více Data Lake Storage Gen1 účtech a současně nakonfigurujete účet Data Lake Storage Gen1 jako primární typ úložiště. Viz Konfigurace Data Lake Storage Gen1 přístupu.
Na stránce Přístup ke službě Data Lake Store klikněte na Vybrat a pokračujte vytvořením clusteru, jak je popsáno v tématu Vytváření clusterů Hadoop ve službě HDInsight.
Vytvoření clusteru s Data Lake Storage Gen1 jako dalším úložištěm
Následující pokyny vytvoří cluster HDInsight s účtem úložiště Objektů blob Azure jako výchozím úložištěm a účtem úložiště s Data Lake Storage Gen1 jako dalším úložištěm.
Vytvoření clusteru HDInsight s Data Lake Storage Gen1 jako dalším účtem úložiště:
Přihlaste se k webu Azure Portal.
Obecné informace o vytváření clusterů HDInsight najdete v tématu Vytváření clusterů .
V okně Úložiště v části Typ primárního úložiště vyberte Azure Storage a zadejte následující informace:
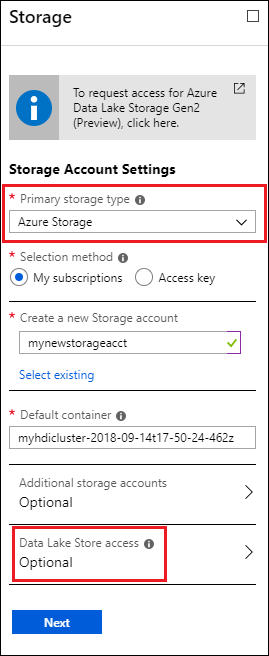
Metoda výběru – Pokud chcete zadat účet úložiště, který je součástí vašeho předplatného Azure, vyberte Moje předplatná a pak vyberte účet úložiště. Pokud chcete zadat účet úložiště, který je mimo vaše předplatné Azure, vyberte Přístupový klíč a pak zadejte informace pro vnější účet úložiště.
Výchozí kontejner – Použijte buď výchozí hodnotu, nebo zadejte vlastní název.
Další účty úložiště – Přidejte další účty úložiště Azure jako další úložiště.
Přístup ke službě Data Lake Store – Nakonfigurujte přístup mezi účtem Data Lake Storage Gen1 a clusterem HDInsight. Pokyny najdete v tématu Konfigurace Data Lake Storage Gen1 přístupu.
Konfigurace Data Lake Storage Gen1 přístupu
V této části nakonfigurujete přístup Data Lake Storage Gen1 z clusterů HDInsight pomocí Microsoft Entra instančního objektu.
Zadání instančního objektu
V Azure Portal můžete buď použít existující instanční objekt, nebo vytvořit nový.
Vytvoření instančního objektu ze Azure Portal:
- Viz Vytvoření instančního objektu a certifikátů pomocí Microsoft Entra ID.
Použití existujícího instančního objektu z Azure Portal:
Instanční objekt by měl mít oprávnění vlastníka účtu úložiště. Viz Nastavení oprávnění instančního objektu jako vlastníka účtu úložiště.
Vyberte Přístup ke službě Data Lake Store.
V okně Data Lake Storage Gen1 přístup vyberte Použít existující.
Vyberte Instanční objekt a pak vyberte instanční objekt.
Nahrajte certifikát (soubor .pfx), který je přidružený k vybranému instančnímu objektu, a zadejte heslo certifikátu.
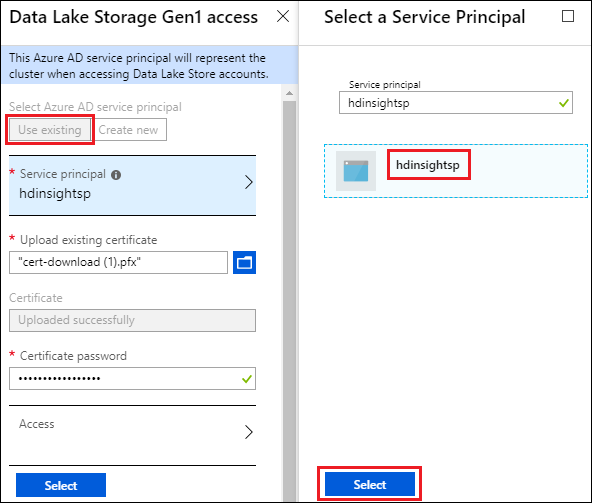
Vyberte Přístup a nakonfigurujte přístup ke složce. Viz Konfigurace oprávnění k souborům.
Nastavení oprávnění instančního objektu jako vlastníka účtu úložiště
- V okně Access Control (IAM) účtu úložiště klikněte na Přidat přiřazení role.
- V okně Přidat přiřazení role vyberte Role jako vlastníka, vyberte hlavní název služby (SPN) a klikněte na Uložit.
Konfigurace oprávnění k souborům
Konfigurace se liší v závislosti na tom, jestli se účet používá jako výchozí úložiště, nebo jako další účet úložiště:
Používá se jako výchozí úložiště.
- oprávnění na kořenové úrovni účtu Data Lake Storage Gen1
- oprávnění na kořenové úrovni úložiště clusteru HDInsight. Například složka /clusters použitá dříve v tomto kurzu.
Použít jako další úložiště
- Oprávnění ve složkách, ke které potřebujete přístup k souborům.
Přiřazení oprávnění k účtu úložiště s Data Lake Storage Gen1 na kořenové úrovni:
V okně Data Lake Storage Gen1 přístup vyberte Přístup. Otevře se okno Vybrat oprávnění k souboru . Obsahuje seznam všech účtů úložiště ve vašem předplatném.
Najeďte myší (neklikejte) na název účtu s Data Lake Storage Gen1, aby se zaškrtávací políčko zobrazilo, a pak políčko zaškrtněte.
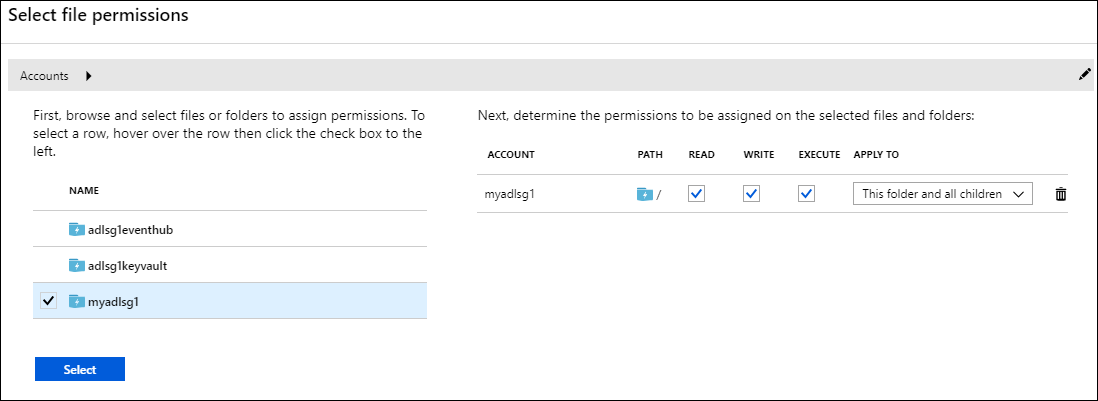
Ve výchozím nastavení jsou vybrány všechny hodnoty READ, WRITE a EXECUTE .
V dolní části stránky klikněte na Vybrat .
Vyberte Spustit a přiřaďte oprávnění.
Vyberte Hotovo.
Přiřazení oprávnění na kořenové úrovni clusteru HDInsight:
- V okně Data Lake Storage Gen1 přístup vyberte Přístup. Otevře se okno Vybrat oprávnění k souboru . Zobrazí seznam všech účtů úložiště s Data Lake Storage Gen1 ve vašem předplatném.
- V okně Vybrat oprávnění k souboru vyberte účet úložiště s Data Lake Storage Gen1 názvem, aby se zobrazil jeho obsah.
- Vyberte kořen úložiště clusteru HDInsight zaškrtnutím políčka na levé straně složky. Podle předchozího snímku obrazovky je kořenem úložiště clusteru složka /clusters, kterou jste zadali při výběru Data Lake Storage Gen1 jako výchozího úložiště.
- Nastavte oprávnění ke složce. Ve výchozím nastavení jsou vybrané všechny funkce číst, zapisovat a spouštět.
- V dolní části stránky klikněte na Vybrat .
- Vyberte Run (Spustit).
- Vyberte Hotovo.
Pokud používáte Data Lake Storage Gen1 jako další úložiště, musíte oprávnění přiřadit jenom složkám, ke kterým chcete přistupovat z clusteru HDInsight. Například na následujícím snímku obrazovky poskytnete přístup jenom ke složce mynewfolder v účtu úložiště s Data Lake Storage Gen1.
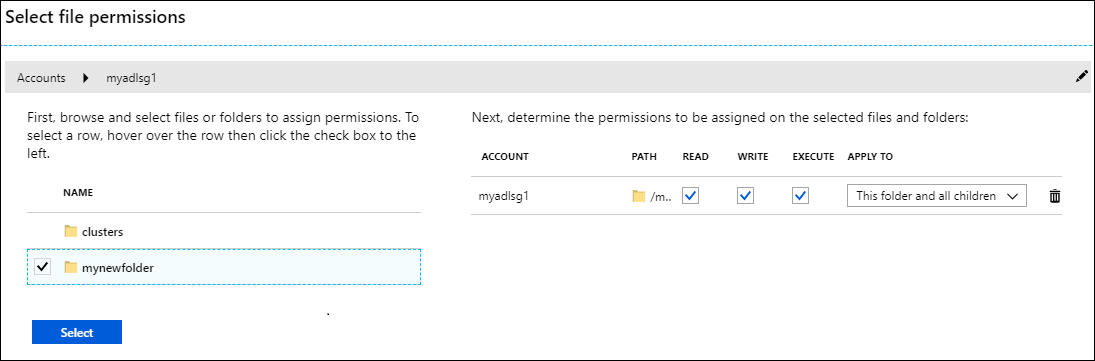
Ověření nastavení clusteru
Po dokončení nastavení clusteru ověřte v okně clusteru výsledky provedením některého nebo obou následujících kroků:
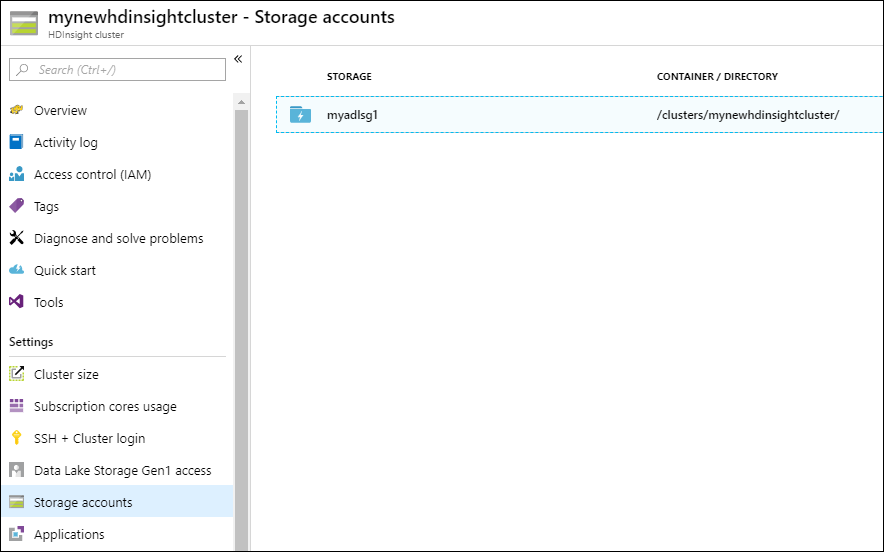
Pokud chcete ověřit, jestli je přidruženým úložištěm clusteru účet s Data Lake Storage Gen1, který jste zadali, vyberte v levém podokně Účty úložiště.
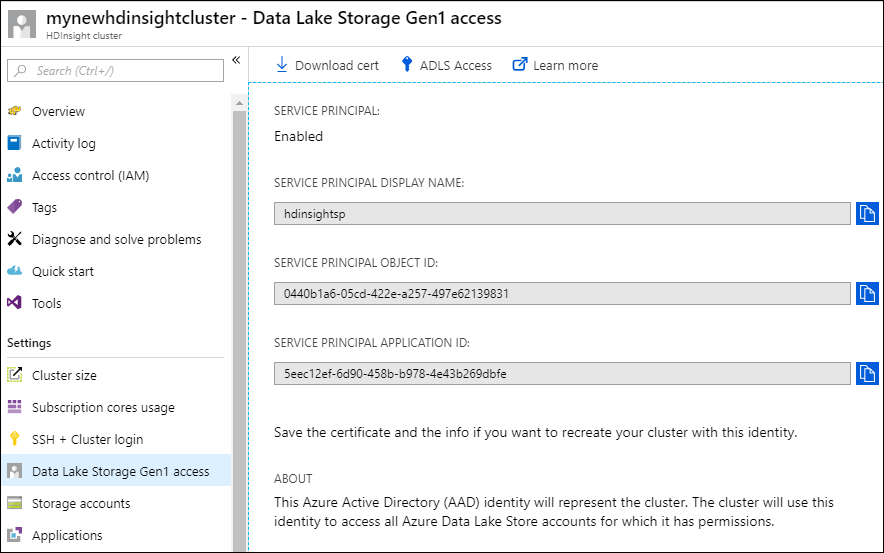
Pokud chcete ověřit, že je instanční objekt správně přidružený ke clusteru HDInsight, vyberte v levém podokně Data Lake Storage Gen1 přístup.
Příklady
Po nastavení clusteru s úložištěm Data Lake Storage Gen1 si projděte tyto příklady použití clusteru HDInsight k analýze dat uložených v Data Lake Storage Gen1.
Spuštění dotazu Hive na data v Data Lake Storage Gen1 (jako primární úložiště)
Pokud chcete spustit dotaz Hive, použijte rozhraní Zobrazení Hive na portálu Ambari. Pokyny k používání zobrazení Hive Ambari najdete v tématu Použití zobrazení Hive s Hadoopem ve službě HDInsight.
Při práci s daty v Data Lake Storage Gen1 je potřeba změnit několik řetězců.
Pokud jako primární úložiště použijete například cluster, který jste vytvořili s Data Lake Storage Gen1, cesta k datům je: adl://< data_lake_storage_gen1_account_name>/azuredatalakestore.net/path/to/file. Dotaz Hive pro vytvoření tabulky z ukázkových dat uložených v Data Lake Storage Gen1 vypadá jako následující příkaz:
CREATE EXTERNAL TABLE websitelog (str string) LOCATION 'adl://hdiadlsg1storage.azuredatalakestore.net/clusters/myhdiadlcluster/HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/'
Popisy:
-
adl://hdiadlsg1storage.azuredatalakestore.net/je kořen účtu s Data Lake Storage Gen1. -
/clusters/myhdiadlclusterje kořen dat clusteru, který jste zadali při vytváření clusteru. -
/HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/je umístění ukázkového souboru, který jste použili v dotazu.
Spuštění dotazu Hive na data v Data Lake Storage Gen1 (jako další úložiště)
Pokud cluster, který jste vytvořili, používá jako výchozí úložiště blob, ukázková data nejsou obsažená v účtu úložiště s Data Lake Storage Gen1, který se používá jako další úložiště. V takovém případě nejprve přeneste data ze služby Blob Storage do účtu úložiště pomocí Data Lake Storage Gen1 a pak spusťte dotazy, jak je znázorněno v předchozím příkladu.
Informace o tom, jak zkopírovat data z úložiště blob do účtu úložiště s Data Lake Storage Gen1, najdete v následujících článcích:
- Použití distcp ke kopírování dat mezi službou Azure Blob Storage a Data Lake Storage Gen1
- Kopírování dat ze služby Azure Blob Storage do Data Lake Storage Gen1 pomocí AdlCopy
Použití Data Lake Storage Gen1 s clusterem Spark
Pomocí clusteru Spark můžete spouštět úlohy Sparku na datech uložených v Data Lake Storage Gen1. Další informace najdete v tématu Použití clusteru HDInsight Spark k analýze dat v Data Lake Storage Gen1.