Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Systémové tabulky MLflow jsou ve verzi Public Preview.
mlflow Systémové tabulky zaznamenávají metadata experimentu spravovaná ve službě sledování MLflow. Tyto tabulky umožňují privilegovaným uživatelům využívat nástroje Databricks Lakehouse na jejich datech MLflow napříč všemi pracovními prostory v dané oblasti. Pomocí tabulek můžete vytvářet vlastní řídicí panely AI/BI, nastavovat výstrahy SQL nebo provádět rozsáhlé analytické dotazy.
Prostřednictvím systémových mlflow tabulek můžou uživatelé odpovídat na otázky, jako jsou:
- Které experimenty mají nejnižší spolehlivost?
- Jaké je průměrné využití GPU v různých experimentech?
Poznámka:
Systémové mlflow tabulky začaly zaznamenávat data MLflow ze všech oblastí 2. září 2025. Data před tímto datem nemusí být k dispozici.
Dostupné tabulky
Schéma mlflow obsahuje následující tabulky:
-
system.mlflow.experiments_latest: Zaznamenává názvy experimentů a události obnovitelného odstranění. Tato data jsou podobná stránce experimentů v uživatelském rozhraní MLflow. -
system.mlflow.runs_latest: Zaznamenává informace o životním cyklu spuštění, parametry a značky přidružené k jednotlivým spuštěním a agregované statistiky minimálních, maximálních a nejnovějších hodnot všech metrik. Tato data se podobali spuštění vyhledávání nebo stránce podrobností o spuštění. -
system.mlflow.run_metrics_history: Zaznamenává název, hodnotu, časové razítko a krok všech metrik přihlášených ke spuštěním, které lze použít k vykreslení podrobných časových intervalů ze spuštění. Tato data jsou podobná kartě metrik na stránce podrobností o spuštění.
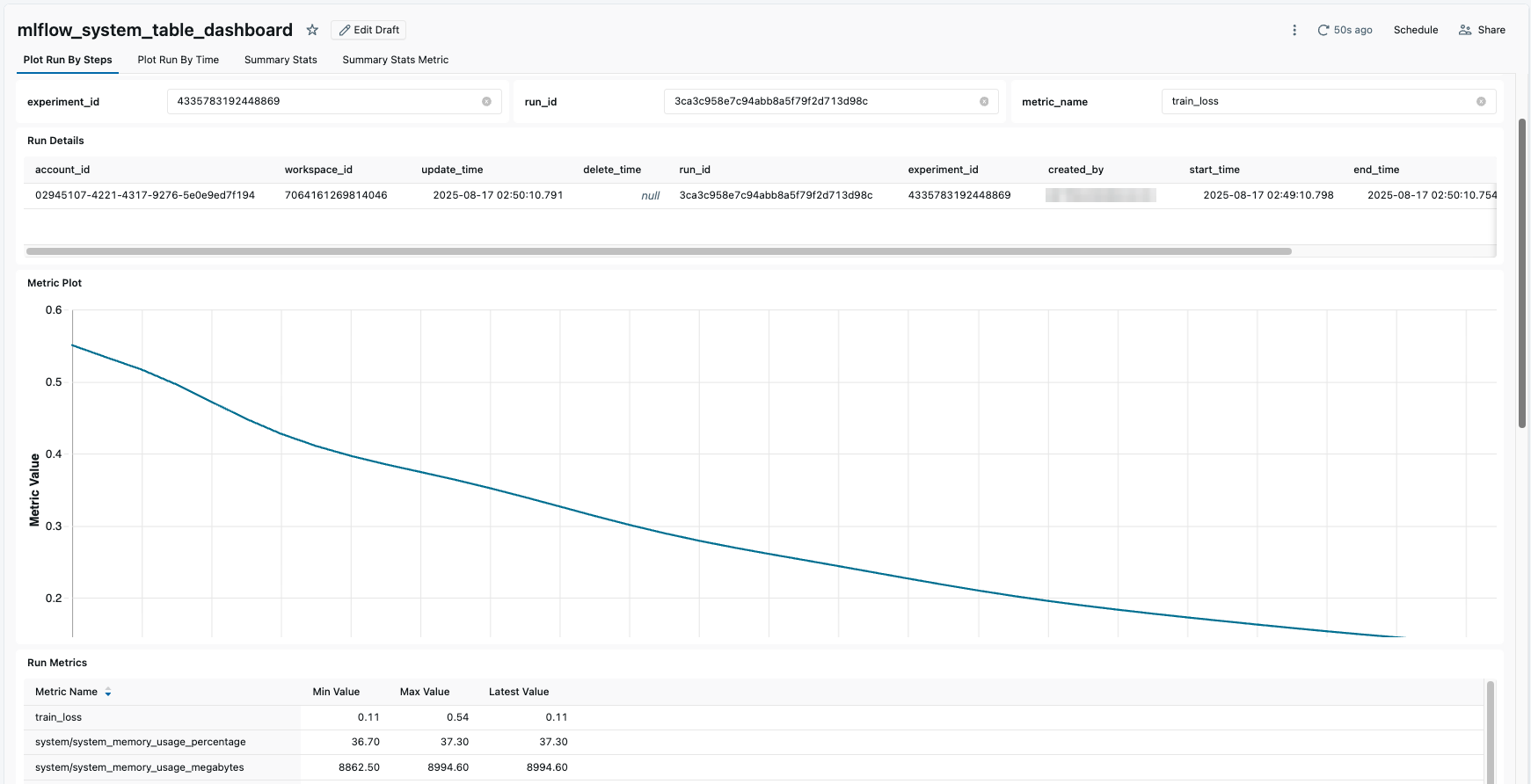
Následuje příklad vykreslení informací o spuštění pomocí řídicího panelu:
Schémata tabulek
Níže jsou uvedena schémata tabulky s popisy a ukázkovými daty.

system.mlflow.experiments_latest
| Název sloupce | Datový typ | Description | Example | Nullovatelný |
|---|---|---|---|---|
account_id |
řetězec | ID účtu obsahujícího experiment MLflow | "bd59efba-4444-4444-443f-44444449203" |
Ne |
update_time |
časové razítko | Systémový čas poslední aktualizace experimentu | 2024-06-27T00:58:57.000+00:00 |
Ne |
delete_time |
časové razítko | Systémový čas při obnovitelném odstranění experimentu MLflow uživatelem | 2024-07-02T12:42:59.000+00:00 |
Ano |
experiment_id |
řetězec | ID experimentu MLflow | "2667956459304720" |
Ne |
workspace_id |
řetězec | ID pracovního prostoru obsahujícího experiment MLflow | "6051921418418893" |
Ne |
name |
řetězec | Uživatelské jméno experimentu | "/Users/first.last@databricks.com/myexperiment" |
Ne |
create_time |
časové razítko | Systémový čas vytvoření experimentu | 2024-06-27T00:58:57.000+00:00 |
Ne |
system.mlflow.runs_latest
| Název sloupce | Datový typ | Description | Example | Nullovatelný |
|---|---|---|---|---|
account_id |
řetězec | ID účtu obsahujícího spuštění MLflow | "bd59efba-4444-4444-443f-44444449203" |
Ne |
update_time |
časové razítko | Systémový čas poslední aktualizace spuštění | 2024-06-27T00:58:57.000+00:00 |
Ne |
delete_time |
časové razítko | Systémový čas při obnovitelném odstranění spuštění MLflow uživatelem | 2024-07-02T12:42:59.000+00:00 |
Ano |
workspace_id |
řetězec | ID pracovního prostoru obsahujícího spuštění MLflow | "6051921418418893" |
Ne |
run_id |
řetězec | ID spuštění MLflow | "7716d750d279487c95f64a75bff2ad56" |
Ne |
experiment_id |
řetězec | ID experimentu MLflow obsahujícího spuštění MLflow | "2667956459304720" |
Ne |
created_by |
řetězec | Název objektu zabezpečení Nebo uživatele Databricks, který vytvořil spuštění MLflow | "<user>@<domain-name>" |
Ano |
start_time |
časové razítko | Čas zadaný uživatelem při spuštění MLflow | 2024-06-27T00:58:57.000+00:00 |
Ne |
end_time |
časové razítko | Uživatelem zadaný čas ukončení spuštění MLflow | 2024-07-02T12:42:59.000+00:00 |
Ano |
run_name |
řetězec | Název spuštění MLflow |
"wistful-deer-932", "my-xgboost-training-run" |
Ne |
status |
řetězec | Stav spuštění MLflow | "FINISHED" |
Ne |
params |
mapovací<řetězec, řetězec> | Parametry klíč-hodnota spuštění MLflow | {"n_layers": "5", "batch_size": "64", "optimizer": "Adam"} |
Ne |
tags |
mapovací<řetězec, řetězec> | Značky klíč-hodnota nastavené při spuštění MLflow | {"ready_for_review": "true"} |
Ne |
aggregated_metrics |
list<struct<string, double, double, double>> | Agregované zobrazení se souhrnem metrik v run_metrics_history | [{"metric_name": "training_accuracy", "latest_value": 0.97, "min_value": 0.8, "max_value": 1.0}, ...] |
Ne |
aggregated_metrics.metric_name |
řetězec | Uživatelem zadaný název metriky | "training_accuracy" |
Ne |
aggregated_metrics.latest_value |
dvojitý | Nejnovější hodnota metric_name v časové řadě této kombinace (spuštění, metric_name) v run_metrics_history | 0.97 |
Ne |
aggregated_metrics.max_value |
dvojitý | Maximální hodnota metric_name v časové řadě této kombinace (spuštění, metric_name) v run_metrics_history. Pokud byla pro metriku zaznamenána nějaká hodnota NaN, bude tato hodnota naN. | 1.0 |
Ne |
aggregated_metrics.min_value |
dvojitý | Minimální hodnota metric_name v časové řadě této kombinace (spuštění, metric_name) v run_metrics_history. Pokud byla pro metriku zaznamenána nějaká hodnota NaN, bude tato hodnota naN. | 0.8 |
Ne |
system.mlflow.run_metrics_history
| Název sloupce | Datový typ | Description | Example | Nullovatelný |
|---|---|---|---|---|
account_id |
řetězec | ID účtu obsahujícího spuštění MLflow, do kterého byla metrika zaznamenána | "bd59efba-4444-4444-443f-44444449203" |
Ne |
insert_time |
časové razítko | Systémový čas při vložení metriky | 2024-06-27T00:58:57.000+00:00 |
Ne |
record_id |
řetězec | Jedinečný identifikátor metriky pro rozlišení mezi identickými hodnotami | "Ae1mDT5gFMSUwb+UUTuXMQ==" |
Ne |
workspace_id |
řetězec | ID pracovního prostoru obsahujícího spuštění MLflow, do kterého byla metrika zaznamenána | "6051921418418893" |
Ne |
experiment_id |
řetězec | ID experimentu MLflow obsahujícího běh MLflow, do kterého byla metrika zaznamenána | "2667956459304720" |
Ne |
run_id |
řetězec | ID spuštění MLflow, do kterého byla metrika zaznamenána | "7716d750d279487c95f64a75bff2ad56" |
Ne |
metric_name |
řetězec | Název metriky | "training_accuracy" |
Ne |
metric_time |
časové razítko | Čas zadaný uživatelem při výpočtu metriky | 2024-06-27T00:55:54.1231+00:00 |
Ne |
metric_step |
bigint | Krok (například epocha) trénování modelu nebo vývoje agenta, ve kterém byla metrika zaznamenána | 10 |
Ne |
metric_value |
dvojitý | Hodnota metriky | 0.97 |
Ne |
Sdílení přístupu s uživateli
Ve výchozím nastavení mají k systémovým schématům přístup jenom správci účtů. Aby měli k tabulkám přístup další uživatelé, musí jim správce účtu udělit oprávnění k použití a SELECT oprávnění ke schématu system.mlflow. . Viz oprávnění katalogu Unity a zabezpečitelné objekty.
Každý uživatel, který má k těmto tabulkám přístup, může zobrazit metadata ve všech experimentech MLflow pro všechny pracovní prostory v účtu. Informace o konfiguraci přístupu k tabulce pro danou skupinu místo jednotlivých uživatelů najdete v doporučených postupech katalogu Unity.
Pokud požadujete jemně odstupňované řízení než udělení přístupu všem uživatelům k tabulce, můžete pomocí dynamických zobrazení s vlastními kritérii udělit skupinám určitý přístup. Můžete například vytvořit zobrazení, které zobrazuje jenom záznamy z konkrétní sady ID experimentů. Po nakonfigurování vlastního zobrazení dejte uživatelům název zobrazení, aby mohli dotazovat dynamické zobrazení místo systémové tabulky přímo.
Poznámka:
Oprávnění experimentu MLflow nelze přímo synchronizovat s oprávněními katalogu Unity.
Příklady případů použití metadat MLflow
V následujících částech najdete příklady použití systémových tabulek MLflow k zodpovězení otázek týkajících se experimentů a spuštění MLflow.
Konfigurace upozornění SQL na nízkou spolehlivost experimentu
Pomocí upozornění SQL Databricks (Public Preview) můžete naplánovat pravidelně opakovaný dotaz a dostávat upozornění, pokud už nejsou splněna určitá omezení.
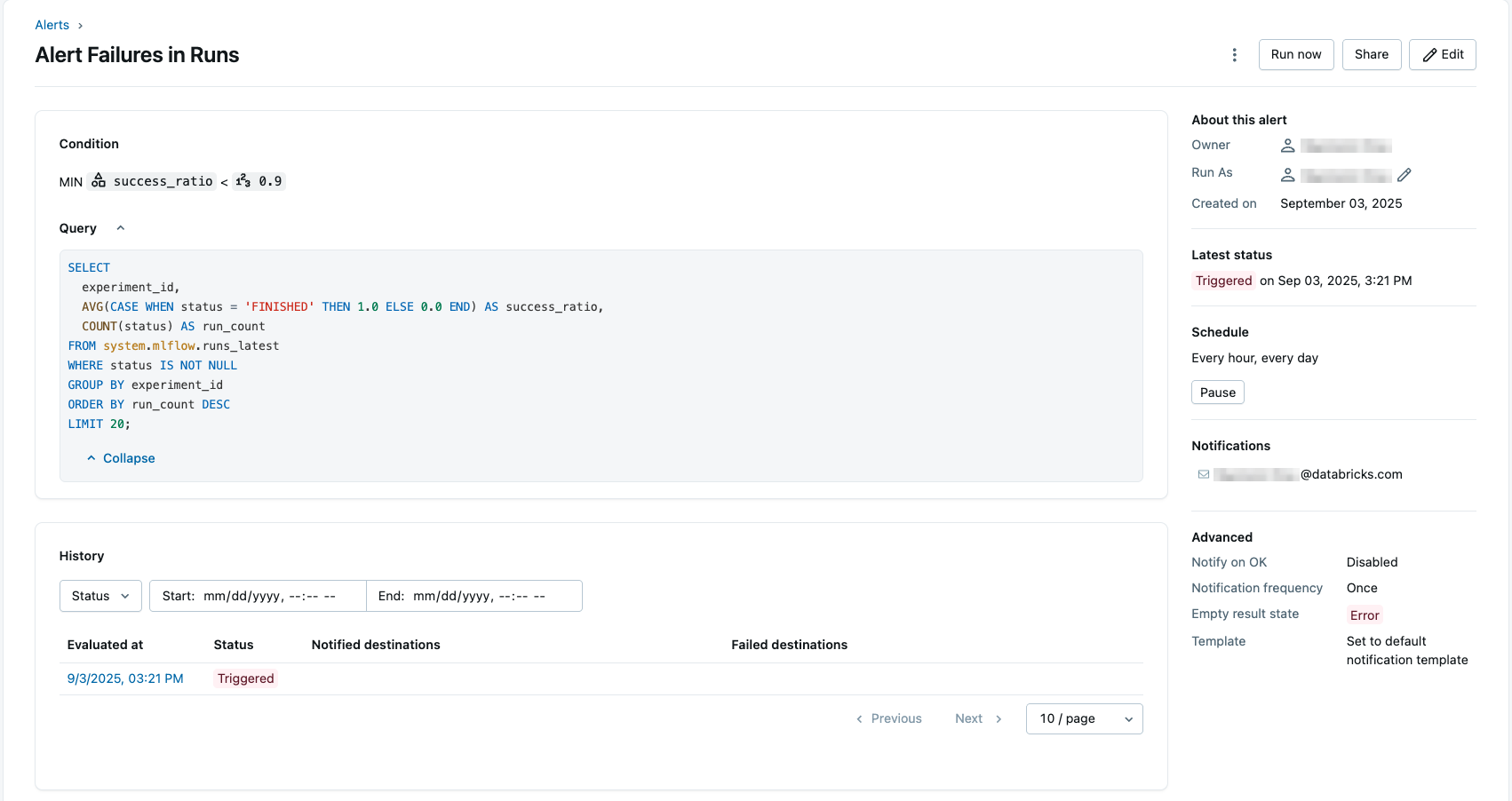
Tento příklad vytvoří výstrahu, která zkoumá nejčastěji spouštěné experimenty v pracovním prostoru a zjišťuje, jestli dochází k nízké spolehlivosti a může vyžadovat zvláštní pozornost. Dotaz používá runs_latest tabulku k výpočtu spuštění na experiment, které jsou označeny jako dokončené, rozdělené celkovým počtem spuštění.
Poznámka:
Funkce Upozornění SQL je aktuálně ve verzi Public Preview a můžete také používat starší upozornění .
Na bočním panelu klikněte na Upozornění na
 a potom klikněte na Vytvořit výstrahu.
a potom klikněte na Vytvořit výstrahu.Zkopírujte a vložte následující dotaz do editoru dotazů.
SELECT experiment_id, AVG(CASE WHEN status = 'FINISHED' THEN 1.0 ELSE 0.0 END) AS success_ratio, COUNT(status) AS run_count FROM system.mlflow.runs_latest WHERE status IS NOT NULL GROUP BY experiment_id ORDER BY run_count DESC LIMIT 20;V poli Podmínka nastavte podmínky na
MIN success_ratio < 0.9. Tím se aktivuje výstraha, pokud některý z prvních 20 experimentů (podle počtu spuštění) má poměr úspěchu menší než 90%.
Kromě toho můžete podmínku otestovat, nastavit plán a nakonfigurovat oznámení. Další informace o konfiguraci výstrahy najdete v tématu Nastavení výstrahy SQL. Níže je příklad konfigurace pomocí dotazu.
Vzorové dotazy
Následující ukázkové dotazy můžete použít k získání informací o aktivitě MLflow ve vašem účtu pomocí Databricks SQL. Pomocí Sparku můžete také využít nástroje, jako jsou poznámkové bloky Pythonu.
Získání informací o spuštění z runs_latest
SELECT
run_name,
date(start_time) AS start_date,
status,
TIMESTAMPDIFF(MINUTE, start_time, end_time) AS run_length_minutes
FROM system.mlflow.runs_latest
WHERE
experiment_id = :experiment_id
AND run_id = :run_id
LIMIT 1
Vrátí informace o daném spuštění:

Získání informací o experimentu a spuštění z experiments_latest a runs_latest
SELECT
runs.run_name,
experiments.name,
date(runs.start_time) AS start_date,
runs.status,
TIMESTAMPDIFF(MINUTE, runs.start_time, runs.end_time) AS run_length_minutes
FROM system.mlflow.runs_latest runs
JOIN system.mlflow.experiments_latest experiments ON runs.experiment_id = experiments.experiment_id
WHERE
runs.experiment_id = :experiment_id
AND runs.run_id = :run_id
LIMIT 1
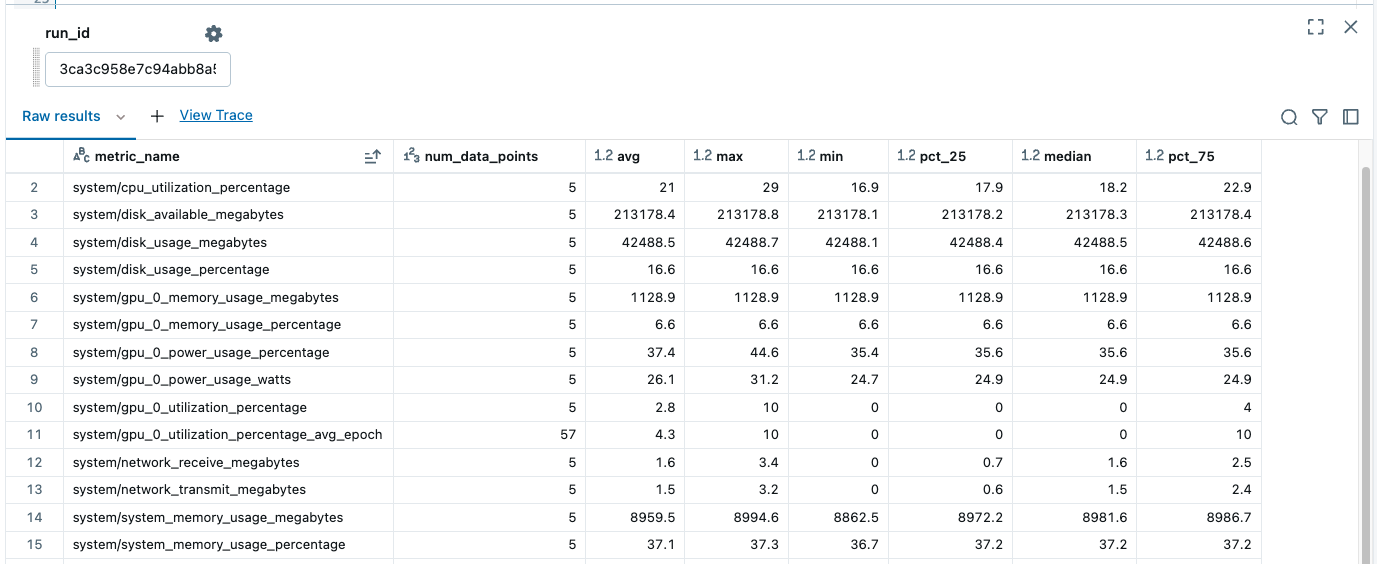
Získání souhrnných statistik pro dané spuštění z run_metrics_history
SELECT
metric_name,
count(metric_time) AS num_data_points,
ROUND(avg(metric_value), 1) AS avg,
ROUND(max(metric_value), 1) AS max,
ROUND(min(metric_value), 1) AS min,
ROUND(PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY metric_value), 1) AS pct_25,
ROUND(PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY metric_value), 1) AS median,
ROUND(PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY metric_value), 1) AS pct_75
FROM
system.mlflow.run_metrics_history
WHERE
run_id = :run_id
GROUP BY
metric_name, run_id
LIMIT 100
Tím se vrátí souhrn metrik pro danou run_idhodnotu:
Řídicí panely pro experimenty a spuštění
Můžete vytvářet řídicí panely nad daty systémových tabulek MLflow a analyzovat experimenty MLflow a spouštět se z celého pracovního prostoru.
Další podrobnosti najdete v tématu Vytváření řídicích panelů s metadaty MLflow v systémových tabulkách.